
























Siempre me intrigan los nuevos enfoques para implementar la Generación Aumentada por Recuperación (RAG) sobre gráficos, a menudo llamados GraphRAG. Sin embargo, parece que todos tienen una implementación diferente en mente cuando escuchan el término GraphRAG. En esta publicación del blog, profundizaremos en el artículo “ De GraphRAG local a global ” y la implementación de los investigadores de Microsoft. Cubriremos la parte de construcción y resumen del gráfico de conocimiento y dejaremos los recuperadores para la próxima publicación del blog. Los investigadores fueron tan amables de proporcionarnos el repositorio de código y también tienen una página de proyecto .
El enfoque adoptado en el artículo mencionado anteriormente es bastante interesante. Hasta donde yo sé, implica el uso de un gráfico de conocimiento como un paso en el proceso de condensación y combinación de información de múltiples fuentes. Extraer entidades y relaciones de un texto no es nada nuevo. Sin embargo, los autores introducen una idea novedosa (al menos para mí) de resumir la estructura y la información condensadas del gráfico como texto en lenguaje natural. El proceso comienza con el texto de entrada de los documentos, que se procesan para generar un gráfico. Luego, el gráfico se convierte nuevamente en texto en lenguaje natural, donde el texto generado contiene información condensada sobre entidades específicas o comunidades de gráficos previamente distribuidas en múltiples documentos.


En un nivel muy alto, la entrada al pipeline de GraphRAG son documentos fuente que contienen información diversa. Los documentos se procesan utilizando un LLM para extraer información estructurada sobre las entidades que aparecen en los artículos junto con sus relaciones. Esta información estructurada extraída se utiliza luego para construir un gráfico de conocimiento.
La ventaja de utilizar una representación de datos mediante un gráfico de conocimiento es que permite combinar de forma rápida y sencilla información de varios documentos o fuentes de datos sobre entidades particulares. Sin embargo, como se mencionó anteriormente, el gráfico de conocimiento no es la única representación de datos. Una vez construido el gráfico de conocimiento, se utiliza una combinación de algoritmos de gráficos y sugerencias LLM para generar resúmenes en lenguaje natural de las comunidades de entidades que se encuentran en el gráfico de conocimiento.
Estos resúmenes contienen entonces información condensada distribuida en múltiples fuentes de datos y documentos para entidades y comunidades específicas.
Para una comprensión más detallada del pipeline, podemos consultar la descripción paso a paso proporcionada en el documento original.


Pasos en el proceso de fabricación — Imagen del artículo de GraphRAG , con licencia CC BY 4.0
A continuación se muestra un resumen de alto nivel del proceso que utilizaremos para reproducir su enfoque utilizando Neo4j y LangChain.
Indexación - Generación de gráficos
- Documentos fuente en fragmentos de texto : los documentos fuente se dividen en fragmentos de texto más pequeños para su procesamiento.
- Fragmentos de texto a instancias de elementos : cada fragmento de texto se analiza para extraer entidades y relaciones, lo que produce una lista de tuplas que representan estos elementos.
- Instancias de elementos a resúmenes de elementos : el LLM resume las entidades y relaciones extraídas en bloques de texto descriptivos para cada elemento.
- Resúmenes de elementos para graficar comunidades : estos resúmenes de entidades forman un gráfico, que luego se divide en comunidades utilizando algoritmos como Leiden para la estructura jerárquica.
- Comunidades gráficas para resúmenes de comunidades : se generan resúmenes de cada comunidad con el LLM para comprender la estructura temática y la semántica global del conjunto de datos.
Recuperación - Respondiendo
- Resúmenes de la comunidad a respuestas globales : los resúmenes de la comunidad se utilizan para responder una consulta de un usuario generando respuestas intermedias, que luego se agregan en una respuesta global final.
Tenga en cuenta que mi implementación se realizó antes de que su código estuviera disponible, por lo que puede haber ligeras diferencias en el enfoque subyacente o en las indicaciones de LLM que se utilizan. Intentaré explicar esas diferencias a medida que avancemos.
El código está disponible en GitHub .
Configuración del entorno Neo4j
Usaremos Neo4j como el almacén de gráficos subyacente. La forma más fácil de comenzar es usar una instancia gratuita de Neo4j Sandbox , que ofrece instancias en la nube de la base de datos Neo4j con el complemento Graph Data Science instalado. Alternativamente, puede configurar una instancia local de la base de datos Neo4j descargando la aplicación Neo4j Desktop y creando una instancia de base de datos local. Si está usando una versión local, asegúrese de instalar los complementos APOC y GDS. Para configuraciones de producción, puede usar la instancia AuraDS (Data Science) administrada y paga, que proporciona el complemento GDS.
Comenzamos creando una instancia de Neo4jGraph , que es el contenedor de conveniencia que agregamos a LangChain:
from langchain_community.graphs import Neo4jGraph os.environ["NEO4J_URI"] = "bolt://44.202.208.177:7687" os.environ["NEO4J_USERNAME"] = "neo4j" os.environ["NEO4J_PASSWORD"] = "mast-codes-trails" graph = Neo4jGraph(refresh_schema=False)Conjunto de datos
Usaremos un conjunto de datos de artículos de noticias que creé hace algún tiempo usando la API de Diffbot. Lo subí a mi GitHub para que sea más fácil reutilizarlo:
news = pd.read_csv( "https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/news_articles.csv" ) news["tokens"] = [ num_tokens_from_string(f"{row['title']} {row['text']}") for i, row in news.iterrows() ] news.head()
Examinemos las primeras filas del conjunto de datos.


Tenemos disponible el título y el texto de los artículos, junto con su fecha de publicación y el recuento de tokens utilizando la biblioteca de tiktoken.
Fragmentación de texto
El paso de fragmentación del texto es crucial y tiene un impacto significativo en los resultados posteriores. Los autores del artículo descubrieron que el uso de fragmentos de texto más pequeños da como resultado la extracción de más entidades en general.


Número de entidades extraídas dado el tamaño de los fragmentos de texto — Imagen del artículo GraphRAG , con licencia CC BY 4.0
Como puede ver, el uso de fragmentos de texto de 2400 tokens da como resultado menos entidades extraídas que cuando se usaron 600 tokens. Además, identificaron que los LLM podrían no extraer todas las entidades en la primera ejecución. En ese caso, introducen una heurística para realizar la extracción varias veces. Hablaremos más sobre eso en la siguiente sección.
Sin embargo, siempre hay pros y contras. El uso de fragmentos de texto más pequeños puede provocar la pérdida del contexto y las correferencias de entidades específicas repartidas en los documentos. Por ejemplo, si un documento menciona a “John” y “he” en oraciones separadas, dividir el texto en fragmentos más pequeños puede hacer que no quede claro que “he” se refiere a John. Algunos de los problemas de correferencia se pueden resolver utilizando una estrategia de superposición de fragmentos de texto, pero no todos.
Examinemos el tamaño de los textos de nuestros artículos:
sns.histplot(news["tokens"], kde=False) plt.title('Distribution of chunk sizes') plt.xlabel('Token count') plt.ylabel('Frequency') plt.show()


La distribución de los recuentos de tokens de artículos es aproximadamente normal, con un pico de alrededor de 400 tokens. La frecuencia de los fragmentos aumenta gradualmente hasta este pico y luego disminuye simétricamente, lo que indica que la mayoría de los fragmentos de texto están cerca de la marca de 400 tokens.
Debido a esta distribución, no realizaremos aquí ninguna fragmentación de texto para evitar problemas de correferencia. De manera predeterminada, el proyecto GraphRAG utiliza tamaños de fragmentos de 300 tokens con 100 tokens de superposición.
Extracción de nodos y relaciones
El siguiente paso es construir conocimiento a partir de fragmentos de texto. Para este caso de uso, utilizamos un LLM para extraer información estructurada en forma de nodos y relaciones del texto. Puedes examinar el mensaje de LLM que utilizaron los autores en el artículo. Tienen mensajes de LLM donde podemos predefinir etiquetas de nodo si es necesario, pero de forma predeterminada, eso es opcional. Además, las relaciones extraídas en la documentación original en realidad no tienen un tipo, solo una descripción. Imagino que la razón detrás de esta elección es permitir que el LLM extraiga y retenga información más rica y matizada como relaciones. Pero es difícil tener un gráfico de conocimiento limpio sin especificaciones de tipo de relación (las descripciones podrían ir en una propiedad).
En nuestra implementación, utilizaremos LLMGraphTransformer , que está disponible en la biblioteca LangChain. En lugar de utilizar ingeniería de indicaciones pura, como lo hace la implementación en el artículo, LLMGraphTransformer utiliza el soporte de llamadas de función integrado para extraer información estructurada (LLM de salida estructurada en LangChain). Puede inspeccionar la indicación del sistema :
from langchain_experimental.graph_transformers import LLMGraphTransformer from langchain_openai import ChatOpenAI llm = ChatOpenAI(temperature=0, model_name="gpt-4o") llm_transformer = LLMGraphTransformer( llm=llm, node_properties=["description"], relationship_properties=["description"] ) def process_text(text: str) -> List[GraphDocument]: doc = Document(page_content=text) return llm_transformer.convert_to_graph_documents([doc])
En este ejemplo, utilizamos GPT-4o para la extracción de gráficos. Los autores instruyen específicamente al LLM para que extraiga entidades y relaciones y sus descripciones . Con la implementación de LangChain, puede utilizar los atributos node_properties y relationship_properties para especificar qué propiedades de nodo o relación desea que el LLM extraiga.
La diferencia con la implementación de LLMGraphTransformer es que todas las propiedades de nodo o relación son opcionales, por lo que no todos los nodos tendrán la propiedad description . Si quisiéramos, podríamos definir una extracción personalizada para que tenga una propiedad description obligatoria, pero lo omitiremos en esta implementación.
Paralelizaremos las solicitudes para que la extracción del gráfico sea más rápida y almacenaremos los resultados en Neo4j:
MAX_WORKERS = 10 NUM_ARTICLES = 2000 graph_documents = [] with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # Submitting all tasks and creating a list of future objects futures = [ executor.submit(process_text, f"{row['title']} {row['text']}") for i, row in news.head(NUM_ARTICLES).iterrows() ] for future in tqdm( as_completed(futures), total=len(futures), desc="Processing documents" ): graph_document = future.result() graph_documents.extend(graph_document) graph.add_graph_documents( graph_documents, baseEntityLabel=True, include_source=True )
En este ejemplo, extraemos información gráfica de 2000 artículos y almacenamos los resultados en Neo4j. Hemos extraído alrededor de 13 000 entidades y 16 000 relaciones. A continuación, se muestra un ejemplo de un documento extraído en el gráfico.


Se necesitan aproximadamente 35 (+/- 5) minutos para completar la extracción y cuesta alrededor de $30 con GPT-4o.
En este paso, los autores introducen heurísticas para decidir si se debe extraer información del gráfico en más de una pasada. Para simplificar, solo haremos una pasada. Sin embargo, si quisiéramos hacer varias pasadas, podríamos poner los primeros resultados de la extracción como historial conversacional y simplemente indicarle al LLM que faltan muchas entidades y que debería extraer más, como lo hacen los autores de GraphRAG.
Anteriormente, mencioné lo importante que es el tamaño de los fragmentos de texto y cómo afecta la cantidad de entidades extraídas. Dado que no realizamos ninguna fragmentación de texto adicional, podemos evaluar la distribución de las entidades extraídas en función del tamaño de los fragmentos de texto:
entity_dist = graph.query( """ MATCH (d:Document) RETURN d.text AS text, count {(d)-[:MENTIONS]->()} AS entity_count """ ) entity_dist_df = pd.DataFrame.from_records(entity_dist) entity_dist_df["token_count"] = [ num_tokens_from_string(str(el)) for el in entity_dist_df["text"] ] # Scatter plot with regression line sns.lmplot( x="token_count", y="entity_count", data=entity_dist_df, line_kws={"color": "red"} ) plt.title("Entity Count vs Token Count Distribution") plt.xlabel("Token Count") plt.ylabel("Entity Count") plt.show()


El diagrama de dispersión muestra que, si bien hay una tendencia positiva, indicada por la línea roja, la relación es sublineal. La mayoría de los puntos de datos se agrupan en cantidades de entidades más bajas, incluso cuando aumentan las cantidades de tokens. Esto indica que la cantidad de entidades extraídas no se escala proporcionalmente con el tamaño de los fragmentos de texto. Aunque existen algunos valores atípicos, el patrón general muestra que cantidades más altas de tokens no conducen de manera constante a cantidades más altas de entidades. Esto valida el hallazgo de los autores de que los tamaños de fragmentos de texto más pequeños extraerán más información.
También pensé que sería interesante inspeccionar las distribuciones de grado de los nodos del gráfico construido. El siguiente código recupera y visualiza las distribuciones de grado de los nodos:
degree_dist = graph.query( """ MATCH (e:__Entity__) RETURN count {(e)-[:!MENTIONS]-()} AS node_degree """ ) degree_dist_df = pd.DataFrame.from_records(degree_dist) # Calculate mean and median mean_degree = np.mean(degree_dist_df['node_degree']) percentiles = np.percentile(degree_dist_df['node_degree'], [25, 50, 75, 90]) # Create a histogram with a logarithmic scale plt.figure(figsize=(12, 6)) sns.histplot(degree_dist_df['node_degree'], bins=50, kde=False, color='blue') # Use a logarithmic scale for the x-axis plt.yscale('log') # Adding labels and title plt.xlabel('Node Degree') plt.ylabel('Count (log scale)') plt.title('Node Degree Distribution') # Add mean, median, and percentile lines plt.axvline(mean_degree, color='red', linestyle='dashed', linewidth=1, label=f'Mean: {mean_degree:.2f}') plt.axvline(percentiles[0], color='purple', linestyle='dashed', linewidth=1, label=f'25th Percentile: {percentiles[0]:.2f}') plt.axvline(percentiles[1], color='orange', linestyle='dashed', linewidth=1, label=f'50th Percentile: {percentiles[1]:.2f}') plt.axvline(percentiles[2], color='yellow', linestyle='dashed', linewidth=1, label=f'75th Percentile: {percentiles[2]:.2f}') plt.axvline(percentiles[3], color='brown', linestyle='dashed', linewidth=1, label=f'90th Percentile: {percentiles[3]:.2f}') # Add legend plt.legend() # Show the plot plt.show()


La distribución de grados de los nodos sigue un patrón de ley de potencia, lo que indica que la mayoría de los nodos tienen muy pocas conexiones, mientras que unos pocos nodos están altamente conectados. El grado medio es 2,45 y la mediana es 1,00, lo que muestra que más de la mitad de los nodos tienen solo una conexión. La mayoría de los nodos (75 por ciento) tienen dos o menos conexiones, y el 90 por ciento tiene cinco o menos. Esta distribución es típica de muchas redes del mundo real, donde una pequeña cantidad de concentradores tienen muchas conexiones y la mayoría de los nodos tienen pocas.
Dado que las descripciones de nodos y relaciones no son propiedades obligatorias, también examinaremos cuántas se extrajeron:
graph.query(""" MATCH (n:`__Entity__`) RETURN "node" AS type, count(*) AS total_count, count(n.description) AS non_null_descriptions UNION ALL MATCH (n)-[r:!MENTIONS]->() RETURN "relationship" AS type, count(*) AS total_count, count(r.description) AS non_null_descriptions """)
Los resultados muestran que 5.926 nodos de 12.994 (45,6 por ciento) tienen la propiedad de descripción. Por otro lado, solo 5.569 relaciones de 15.921 (35 por ciento) tienen dicha propiedad.
Tenga en cuenta que debido a la naturaleza probabilística de los LLM, los números pueden variar en diferentes ejecuciones y diferentes datos de origen, LLM y solicitudes.
Resolución de entidad
La resolución de entidades (desduplicación) es crucial al construir gráficos de conocimiento porque garantiza que cada entidad esté representada de forma única y precisa, lo que evita los duplicados y la fusión de registros que hacen referencia a la misma entidad del mundo real. Este proceso es esencial para mantener la integridad y la coherencia de los datos dentro del gráfico. Sin la resolución de entidades, los gráficos de conocimiento sufrirían de datos fragmentados e inconsistentes, lo que daría lugar a errores y a información poco fiable.


Esta imagen demuestra cómo una sola entidad del mundo real podría aparecer con nombres ligeramente diferentes en distintos documentos y, en consecuencia, en nuestro gráfico.
Además, la escasez de datos se convierte en un problema importante sin una resolución de entidades. Los datos incompletos o parciales de diversas fuentes pueden dar lugar a fragmentos de información dispersos y desconectados, lo que dificulta la formación de una comprensión coherente y completa de las entidades. La resolución precisa de entidades aborda este problema consolidando los datos, completando los vacíos y creando una vista unificada de cada entidad.


Antes y después de utilizar la resolución de entidades Senzing para conectar los datos de filtraciones en alta mar del Consorcio Internacional de Periodistas de Investigación (ICIJ) — Imagen de Paco Nathan
La parte izquierda de la visualización presenta un gráfico disperso y desconectado. Sin embargo, como se muestra en el lado derecho, un gráfico de este tipo puede llegar a estar bien conectado con una resolución de entidades eficiente.
En general, la resolución de entidades mejora la eficiencia de la recuperación e integración de datos, lo que proporciona una vista coherente de la información de distintas fuentes. En última instancia, permite una respuesta más eficaz a las preguntas basándose en un gráfico de conocimiento completo y fiable.
Lamentablemente, los autores del artículo de GraphRAG no incluyeron ningún código de resolución de entidades en su repositorio, aunque lo mencionan en su artículo. Una razón para dejar de lado este código podría ser que es difícil implementar una resolución de entidades sólida y de buen rendimiento para cualquier dominio determinado. Puede implementar heurísticas personalizadas para diferentes nodos cuando se trabaja con tipos de nodos predefinidos (cuando no están predefinidos, no son lo suficientemente consistentes, como empresa, organización, negocio, etc.). Sin embargo, si las etiquetas o los tipos de nodos no se conocen de antemano, como en nuestro caso, esto se convierte en un problema aún más difícil. No obstante, implementaremos una versión de resolución de entidades en nuestro proyecto aquí, combinando incrustaciones de texto y algoritmos de gráficos con distancia entre palabras y LLM.


Nuestro proceso para la resolución de entidades implica los siguientes pasos:
- Entidades en el gráfico : comience con todas las entidades dentro del gráfico.
- Gráfico de k vecinos más cercanos : construya un gráfico de k vecinos más cercanos, conectando entidades similares en función de incrustaciones de texto.
- Componentes débilmente conectados : identifica los componentes débilmente conectados en el gráfico más cercano y agrupa las entidades que probablemente sean similares. Agrega un paso de filtrado de distancia de palabras después de que se hayan identificado estos componentes.
- Evaluación LLM : utilice un LLM para evaluar estos componentes y decidir si las entidades dentro de cada componente deben fusionarse, lo que da como resultado una decisión final sobre la resolución de la entidad (por ejemplo, fusionar 'Silicon Valley Bank' y 'Silicon_Valley_Bank' mientras se rechaza la fusión para diferentes fechas como '16 de septiembre de 2023' y '2 de septiembre de 2023').
Comenzamos calculando las incrustaciones de texto para las propiedades de nombre y descripción de las entidades. Podemos usar el método from_existing_graph en la integración de Neo4jVector en LangChain para lograr esto:
vector = Neo4jVector.from_existing_graph( OpenAIEmbeddings(), node_label='__Entity__', text_node_properties=['id', 'description'], embedding_node_property='embedding' )
Podemos utilizar estas incrustaciones para encontrar candidatos potenciales que sean similares en función de la distancia del coseno de estas incrustaciones. Utilizaremos algoritmos de gráficos disponibles en la biblioteca Graph Data Science (GDS) ; por lo tanto, podemos utilizar el cliente Python de GDS para facilitar su uso de forma Python:
from graphdatascience import GraphDataScience gds = GraphDataScience( os.environ["NEO4J_URI"], auth=(os.environ["NEO4J_USERNAME"], os.environ["NEO4J_PASSWORD"]) )
Si no está familiarizado con la biblioteca GDS, primero tenemos que proyectar un gráfico en memoria antes de poder ejecutar cualquier algoritmo gráfico.


En primer lugar, el gráfico almacenado en Neo4j se proyecta en un gráfico en memoria para un procesamiento y análisis más rápidos. A continuación, se ejecuta un algoritmo gráfico en el gráfico en memoria. Opcionalmente, los resultados del algoritmo se pueden volver a almacenar en la base de datos de Neo4j. Obtenga más información al respecto en la documentación .
Para crear el gráfico de k vecinos más cercanos, proyectaremos todas las entidades junto con sus incrustaciones de texto:
G, result = gds.graph.project( "entities", # Graph name "__Entity__", # Node projection "*", # Relationship projection nodeProperties=["embedding"] # Configuration parameters )
Ahora que el gráfico está proyectado bajo el nombre de entities , podemos ejecutar algoritmos de gráficos. Comenzaremos construyendo un gráfico k-nearest . Los dos parámetros más importantes que influyen en cuán disperso o denso será el gráfico k-nearest son similarityCutoff y topK . El topK es el número de vecinos que se deben encontrar para cada nodo, con un valor mínimo de 1. El similarityCutoff filtra las relaciones con similitud por debajo de este umbral. Aquí, usaremos un topK predeterminado de 10 y un límite de corte de similitud relativamente alto de 0,95. El uso de un límite de corte de similitud alto, como 0,95, garantiza que solo los pares muy similares se consideren coincidencias, lo que minimiza los falsos positivos y mejora la precisión.


Como queremos almacenar los resultados en el gráfico proyectado en memoria en lugar del gráfico de conocimiento, utilizaremos el modo mutate del algoritmo:
similarity_threshold = 0.95 gds.knn.mutate( G, nodeProperties=['embedding'], mutateRelationshipType= 'SIMILAR', mutateProperty= 'score', similarityCutoff=similarity_threshold )
El siguiente paso es identificar grupos de entidades que estén conectadas con las relaciones de similitud recién inferidas. Identificar grupos de nodos conectados es un proceso frecuente en el análisis de redes, a menudo llamado detección de comunidades o agrupamiento , que implica encontrar subgrupos de nodos densamente conectados. En este ejemplo, utilizaremos el algoritmo de componentes débilmente conectados , que nos ayuda a encontrar partes de un gráfico donde todos los nodos están conectados, incluso si ignoramos la dirección de las conexiones.


Utilizamos el modo write del algoritmo para almacenar los resultados en la base de datos (gráfico almacenado):
gds.wcc.write( G, writeProperty="wcc", relationshipTypes=["SIMILAR"] )
La comparación de incrustaciones de texto ayuda a encontrar posibles duplicados, pero es solo una parte del proceso de resolución de entidades. Por ejemplo, Google y Apple están muy cerca en el espacio de incrustaciones (similitud de coseno de 0,96 utilizando el modelo de incrustación ada-002 ). Lo mismo ocurre con BMW y Mercedes Benz (similitud de coseno de 0,97). Una alta similitud de incrustaciones de texto es un buen comienzo, pero podemos mejorarla. Por lo tanto, agregaremos un filtro adicional que permita solo pares de palabras con una distancia de texto de tres o menos (lo que significa que solo se pueden cambiar los caracteres):
word_edit_distance = 3 potential_duplicate_candidates = graph.query( """MATCH (e:`__Entity__`) WHERE size(e.id) > 3 // longer than 3 characters WITH e.wcc AS community, collect(e) AS nodes, count(*) AS count WHERE count > 1 UNWIND nodes AS node // Add text distance WITH distinct [n IN nodes WHERE apoc.text.distance(toLower(node.id), toLower(n.id)) < $distance OR node.id CONTAINS n.id | n.id] AS intermediate_results WHERE size(intermediate_results) > 1 WITH collect(intermediate_results) AS results // combine groups together if they share elements UNWIND range(0, size(results)-1, 1) as index WITH results, index, results[index] as result WITH apoc.coll.sort(reduce(acc = result, index2 IN range(0, size(results)-1, 1) | CASE WHEN index <> index2 AND size(apoc.coll.intersection(acc, results[index2])) > 0 THEN apoc.coll.union(acc, results[index2]) ELSE acc END )) as combinedResult WITH distinct(combinedResult) as combinedResult // extra filtering WITH collect(combinedResult) as allCombinedResults UNWIND range(0, size(allCombinedResults)-1, 1) as combinedResultIndex WITH allCombinedResults[combinedResultIndex] as combinedResult, combinedResultIndex, allCombinedResults WHERE NOT any(x IN range(0,size(allCombinedResults)-1,1) WHERE x <> combinedResultIndex AND apoc.coll.containsAll(allCombinedResults[x], combinedResult) ) RETURN combinedResult """, params={'distance': word_edit_distance})
Esta afirmación de Cypher es un poco más compleja y su interpretación queda fuera del alcance de esta publicación del blog. Siempre puedes pedirle a un LLM que la interprete.


Además, el límite de distancia entre palabras podría ser una función de la longitud de la palabra en lugar de un solo número y la implementación podría ser más escalable.
Lo importante es que genere grupos de entidades potenciales que podríamos querer fusionar. A continuación, se incluye una lista de nodos potenciales para fusionar:
{'combinedResult': ['Sinn Fein', 'Sinn Féin']}, {'combinedResult': ['Government', 'Governments']}, {'combinedResult': ['Unreal Engine', 'Unreal_Engine']}, {'combinedResult': ['March 2016', 'March 2020', 'March 2022', 'March_2023']}, {'combinedResult': ['Humana Inc', 'Humana Inc.']}, {'combinedResult': ['New York Jets', 'New York Mets']}, {'combinedResult': ['Asia Pacific', 'Asia-Pacific', 'Asia_Pacific']}, {'combinedResult': ['Bengaluru', 'Mangaluru']}, {'combinedResult': ['US Securities And Exchange Commission', 'Us Securities And Exchange Commission']}, {'combinedResult': ['Jp Morgan', 'Jpmorgan']}, {'combinedResult': ['Brighton', 'Brixton']},
Como puede ver, nuestro enfoque de resolución funciona mejor para algunos tipos de nodos que para otros. Según un examen rápido, parece funcionar mejor para personas y organizaciones, mientras que es bastante malo para fechas. Si usáramos tipos de nodos predefinidos, podríamos preparar diferentes heurísticas para varios tipos de nodos. En este ejemplo, no tenemos etiquetas de nodos predefinidas, por lo que recurriremos a un LLM para tomar la decisión final sobre si las entidades deben fusionarse o no.
En primer lugar, debemos formular el mensaje del LLM para guiar e informar eficazmente la decisión final con respecto a la fusión de los nodos:
system_prompt = """You are a data processing assistant. Your task is to identify duplicate entities in a list and decide which of them should be merged. The entities might be slightly different in format or content, but essentially refer to the same thing. Use your analytical skills to determine duplicates. Here are the rules for identifying duplicates: 1. Entities with minor typographical differences should be considered duplicates. 2. Entities with different formats but the same content should be considered duplicates. 3. Entities that refer to the same real-world object or concept, even if described differently, should be considered duplicates. 4. If it refers to different numbers, dates, or products, do not merge results """ user_template = """ Here is the list of entities to process: {entities} Please identify duplicates, merge them, and provide the merged list. """
Siempre me gusta usar el método with_structured_output en LangChain cuando espero una salida de datos estructurados para evitar tener que analizar las salidas manualmente.
Aquí, definiremos la salida como una list of lists , donde cada lista interna contiene las entidades que se deben fusionar. Esta estructura se utiliza para manejar escenarios en los que, por ejemplo, la entrada podría ser [Sony, Sony Inc, Google, Google Inc] . En tales casos, querrá fusionar “Sony” y “Sony Inc” por separado de “Google” y “Google Inc”.
class DuplicateEntities(BaseModel): entities: List[str] = Field( description="Entities that represent the same object or real-world entity and should be merged" ) class Disambiguate(BaseModel): merge_entities: Optional[List[DuplicateEntities]] = Field( description="Lists of entities that represent the same object or real-world entity and should be merged" ) extraction_llm = ChatOpenAI(model_name="gpt-4o").with_structured_output( Disambiguate )
A continuación, integramos el mensaje LLM con la salida estructurada para crear una cadena utilizando la sintaxis del lenguaje de expresión LangChain (LCEL) y la encapsulamos dentro de una función disambiguate .
extraction_chain = extraction_prompt | extraction_llm def entity_resolution(entities: List[str]) -> Optional[List[List[str]]]: return [ el.entities for el in extraction_chain.invoke({"entities": entities}).merge_entities ]
Necesitamos ejecutar todos los nodos candidatos potenciales a través de la función entity_resolution para decidir si se deben fusionar. Para acelerar el proceso, paralelizaremos nuevamente las llamadas LLM:
merged_entities = [] with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # Submitting all tasks and creating a list of future objects futures = [ executor.submit(entity_resolution, el['combinedResult']) for el in potential_duplicate_candidates ] for future in tqdm( as_completed(futures), total=len(futures), desc="Processing documents" ): to_merge = future.result() if to_merge: merged_entities.extend(to_merge)
El paso final de la resolución de entidades implica tomar los resultados del LLM entity_resolution y escribirlos nuevamente en la base de datos fusionando los nodos especificados:
graph.query(""" UNWIND $data AS candidates CALL { WITH candidates MATCH (e:__Entity__) WHERE e.id IN candidates RETURN collect(e) AS nodes } CALL apoc.refactor.mergeNodes(nodes, {properties: { description:'combine', `.*`: 'discard' }}) YIELD node RETURN count(*) """, params={"data": merged_entities})
Esta resolución de entidades no es perfecta, pero nos da un punto de partida sobre el cual podemos mejorar. Además, podemos mejorar la lógica para determinar qué entidades deben conservarse.
Resumen de elementos
En el siguiente paso, los autores realizan un paso de resumen de elementos. Básicamente, cada nodo y relación pasa por un mensaje de resumen de entidades . Los autores destacan la novedad y el interés de su enfoque:
“En general, nuestro uso de texto descriptivo enriquecido para nodos homogéneos en una estructura de gráfico potencialmente ruidosa está alineado con las capacidades de los LLM y las necesidades de resumen global centrado en consultas. Estas cualidades también diferencian nuestro índice de gráfico de los gráficos de conocimiento típicos, que se basan en tripletas de conocimiento concisas y consistentes (sujeto, predicado, objeto) para tareas de razonamiento posteriores”.
La idea es interesante. Aún extraemos los identificadores o nombres de sujetos y objetos del texto, lo que nos permite vincular relaciones con las entidades correctas, incluso cuando las entidades aparecen en varios fragmentos de texto. Sin embargo, las relaciones no se reducen a un único tipo. En cambio, el tipo de relación es en realidad un texto de formato libre que nos permite conservar información más rica y con más matices.
Además, la información de la entidad se resume utilizando un LLM, lo que nos permite integrar e indexar esta información y las entidades de manera más eficiente para una recuperación más precisa.
Se podría argumentar que esta información más rica y matizada también se podría conservar añadiendo propiedades de nodo y relación adicionales, posiblemente arbitrarias. Un problema con las propiedades de nodo y relación arbitrarias es que podría resultar difícil extraer la información de manera consistente porque el LLM podría usar diferentes nombres de propiedad o centrarse en distintos detalles en cada ejecución.
Algunos de estos problemas podrían resolverse utilizando nombres de propiedades predefinidos con información adicional sobre el tipo y la descripción. En ese caso, se necesitaría un experto en la materia para ayudar a definir esas propiedades, lo que dejaría poco margen para que un LLM extrajera información vital fuera de las descripciones predefinidas.
Es un enfoque interesante para representar información más rica en un gráfico de conocimiento.
Un problema potencial con el paso de resumen de elementos es que no se escala bien, ya que requiere una llamada LLM para cada entidad y relación en el gráfico. Nuestro gráfico es relativamente pequeño, con 13 000 nodos y 16 000 relaciones. Incluso para un gráfico tan pequeño, necesitaríamos 29 000 llamadas LLM, y cada llamada utilizaría un par de cientos de tokens, lo que lo hace bastante costoso y requiere mucho tiempo. Por lo tanto, evitaremos este paso aquí. Aún podemos usar las propiedades de descripción extraídas durante el procesamiento de texto inicial.
Construyendo y resumiendo comunidades
El paso final en el proceso de construcción e indexación de gráficos implica la identificación de comunidades dentro del gráfico. En este contexto, una comunidad es un grupo de nodos que están conectados entre sí de manera más densa que con el resto del gráfico, lo que indica un mayor nivel de interacción o similitud. La siguiente visualización muestra un ejemplo de los resultados de la detección de comunidades.


Una vez que estas comunidades de entidades se identifican con un algoritmo de agrupamiento, un LLM genera un resumen para cada comunidad, proporcionando información sobre sus características y relaciones individuales.
Nuevamente, utilizamos la biblioteca Graph Data Science. Comenzamos proyectando un gráfico en memoria. Para seguir con precisión el artículo original, proyectaremos el gráfico de entidades como una red ponderada no dirigida, donde la red representa la cantidad de conexiones entre dos entidades:
G, result = gds.graph.project( "communities", # Graph name "__Entity__", # Node projection { "_ALL_": { "type": "*", "orientation": "UNDIRECTED", "properties": {"weight": {"property": "*", "aggregation": "COUNT"}}, } }, )
Los autores emplearon el algoritmo de Leiden , un método de agrupamiento jerárquico, para identificar comunidades dentro del gráfico. Una ventaja de utilizar un algoritmo de detección de comunidades jerárquico es la capacidad de examinar comunidades en múltiples niveles de granularidad. Los autores sugieren resumir todas las comunidades en cada nivel, lo que proporciona una comprensión integral de la estructura del gráfico.
En primer lugar, utilizaremos el algoritmo de componentes débilmente conectados (WCC) para evaluar la conectividad de nuestro gráfico. Este algoritmo identifica secciones aisladas dentro del gráfico, lo que significa que detecta subconjuntos de nodos o componentes que están conectados entre sí pero no con el resto del gráfico. Estos componentes nos ayudan a comprender la fragmentación dentro de la red e identificar grupos de nodos que son independientes de otros. WCC es vital para analizar la estructura general y la conectividad del gráfico.
wcc = gds.wcc.stats(G) print(f"Component count: {wcc['componentCount']}") print(f"Component distribution: {wcc['componentDistribution']}") # Component count: 1119 # Component distribution: { # "min":1, # "p5":1, # "max":9109, # "p999":43, # "p99":19, # "p1":1, # "p10":1, # "p90":7, # "p50":2, # "p25":1, # "p75":4, # "p95":10, # "mean":11.3 }
Los resultados del algoritmo WCC identificaron 1119 componentes distintos. Cabe destacar que el componente más grande comprende 9109 nodos, algo común en las redes del mundo real donde un único supercomponente coexiste con numerosos componentes aislados más pequeños. El componente más pequeño tiene un nodo y el tamaño promedio de los componentes es de aproximadamente 11,3 nodos.
A continuación, ejecutaremos el algoritmo de Leiden, que también está disponible en la biblioteca GDS, y habilitaremos el parámetro includeIntermediateCommunities para devolver y almacenar comunidades en todos los niveles. También hemos incluido un parámetro relationshipWeightProperty para ejecutar la variante ponderada del algoritmo de Leiden. Al utilizar el modo write del algoritmo, se almacenan los resultados como una propiedad de nodo.
gds.leiden.write( G, writeProperty="communities", includeIntermediateCommunities=True, relationshipWeightProperty="weight", )
El algoritmo identificó cinco niveles de comunidades, de los cuales el más alto (el nivel menos granular, donde las comunidades son más numerosas) tiene 1188 comunidades (en comparación con 1119 componentes). Aquí se muestra la visualización de las comunidades en el último nivel utilizando Gephi.


Visualizar más de 1000 comunidades es difícil; incluso elegir los colores para cada una de ellas es prácticamente imposible. Sin embargo, son unas representaciones artísticas muy bonitas.
A partir de esto, crearemos un nodo distinto para cada comunidad y representaremos su estructura jerárquica como un gráfico interconectado. Más adelante, también almacenaremos resúmenes de la comunidad y otros atributos como propiedades de nodo.
graph.query(""" MATCH (e:`__Entity__`) UNWIND range(0, size(e.communities) - 1 , 1) AS index CALL { WITH e, index WITH e, index WHERE index = 0 MERGE (c:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])}) ON CREATE SET c.level = index MERGE (e)-[:IN_COMMUNITY]->(c) RETURN count(*) AS count_0 } CALL { WITH e, index WITH e, index WHERE index > 0 MERGE (current:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])}) ON CREATE SET current.level = index MERGE (previous:`__Community__` {id: toString(index - 1) + '-' + toString(e.communities[index - 1])}) ON CREATE SET previous.level = index - 1 MERGE (previous)-[:IN_COMMUNITY]->(current) RETURN count(*) AS count_1 } RETURN count(*) """)
Los autores también introducen un community rank , que indica el número de fragmentos de texto distintos en los que aparecen las entidades dentro de la comunidad:
graph.query(""" MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(:__Entity__)<-[:MENTIONS]-(d:Document) WITH c, count(distinct d) AS rank SET c.community_rank = rank; """)
Ahora examinemos una estructura jerárquica de muestra con muchas comunidades intermedias que se fusionan en niveles superiores. Las comunidades no se superponen, lo que significa que cada entidad pertenece precisamente a una única comunidad en cada nivel.


La imagen representa una estructura jerárquica resultante del algoritmo de detección de comunidades de Leiden. Los nodos morados representan entidades individuales, mientras que los nodos naranjas representan comunidades jerárquicas.
La jerarquía muestra la organización de estas entidades en varias comunidades, donde las comunidades más pequeñas se fusionan para formar otras más grandes en niveles superiores.
Examinemos ahora cómo las comunidades más pequeñas se fusionan en niveles superiores.

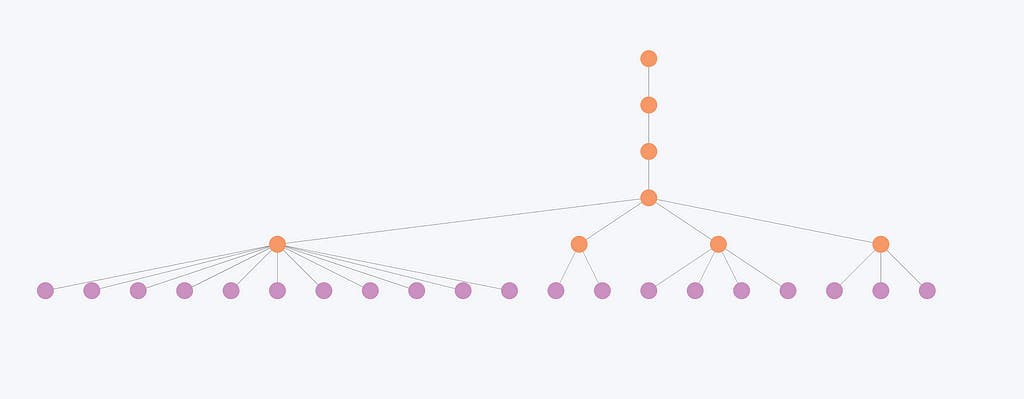
Esta imagen ilustra que las entidades menos conectadas y, en consecuencia, las comunidades más pequeñas experimentan cambios mínimos en los distintos niveles. Por ejemplo, la estructura de la comunidad aquí solo cambia en los dos primeros niveles, pero permanece idéntica en los tres últimos. En consecuencia, los niveles jerárquicos a menudo parecen redundantes para estas entidades, ya que la organización general no se altera significativamente en los diferentes niveles.
Examinemos con más detalle el número de comunidades, sus tamaños y diferentes niveles:
community_size = graph.query( """ MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(e:__Entity__) WITH c, count(distinct e) AS entities RETURN split(c.id, '-')[0] AS level, entities """ ) community_size_df = pd.DataFrame.from_records(community_size) percentiles_data = [] for level in community_size_df["level"].unique(): subset = community_size_df[community_size_df["level"] == level]["entities"] num_communities = len(subset) percentiles = np.percentile(subset, [25, 50, 75, 90, 99]) percentiles_data.append( [ level, num_communities, percentiles[0], percentiles[1], percentiles[2], percentiles[3], percentiles[4], max(subset) ] ) # Create a DataFrame with the percentiles percentiles_df = pd.DataFrame( percentiles_data, columns=[ "Level", "Number of communities", "25th Percentile", "50th Percentile", "75th Percentile", "90th Percentile", "99th Percentile", "Max" ], ) percentiles_df


En la implementación original, se resumían las comunidades de cada nivel. En nuestro caso, serían 8590 comunidades y, en consecuencia, 8590 llamadas LLM. Yo diría que, según la estructura jerárquica de la comunidad, no es necesario resumir todos los niveles. Por ejemplo, la diferencia entre el último y el penúltimo nivel es de solo cuatro comunidades (1192 frente a 1188). Por lo tanto, estaríamos creando muchos resúmenes redundantes. Una solución es crear una implementación que pueda hacer un único resumen para las comunidades de diferentes niveles que no cambian; otra sería contraer las jerarquías de comunidades que no cambian.
Además, no estoy seguro de si queremos resumir comunidades con un solo miembro, ya que podrían no brindar mucho valor o información. Aquí, resumiremos las comunidades en los niveles 0, 1 y 4. Primero, necesitamos recuperar su información de la base de datos:
community_info = graph.query(""" MATCH (c:`__Community__`)<-[:IN_COMMUNITY*]-(e:__Entity__) WHERE c.level IN [0,1,4] WITH c, collect(e ) AS nodes WHERE size(nodes) > 1 CALL apoc.path.subgraphAll(nodes[0], { whitelistNodes:nodes }) YIELD relationships RETURN c.id AS communityId, [n in nodes | {id: n.id, description: n.description, type: [el in labels(n) WHERE el <> '__Entity__'][0]}] AS nodes, [r in relationships | {start: startNode(r).id, type: type(r), end: endNode(r).id, description: r.description}] AS rels """)
Actualmente la información de la comunidad tiene la siguiente estructura:
{'communityId': '0-6014', 'nodes': [{'id': 'Darrell Hughes', 'description': None, type:"Person"}, {'id': 'Chief Pilot', 'description': None, type: "Person"}, ... }], 'rels': [{'start': 'Ryanair Dac', 'description': 'Informed of the change in chief pilot', 'type': 'INFORMED', 'end': 'Irish Aviation Authority'}, {'start': 'Ryanair Dac', 'description': 'Dismissed after internal investigation found unacceptable behaviour', 'type': 'DISMISSED', 'end': 'Aidan Murray'}, ... ]}
Ahora, necesitamos preparar un tema de LLM que genere un resumen en lenguaje natural basado en la información proporcionada por los elementos de nuestra comunidad. Podemos inspirarnos en el tema que usaron los investigadores .
Los autores no solo resumieron las comunidades, sino que también generaron hallazgos para cada una de ellas. Un hallazgo puede definirse como información concisa sobre un evento o un dato específico. Un ejemplo de ello es el siguiente:
"summary": "Abila City Park as the central location", "explanation": "Abila City Park is the central entity in this community, serving as the location for the POK rally. This park is the common link between all other entities, suggesting its significance in the community. The park's association with the rally could potentially lead to issues such as public disorder or conflict, depending on the nature of the rally and the reactions it provokes. [records: Entities (5), Relationships (37, 38, 39, 40)]"
Mi intuición sugiere que extraer hallazgos con una sola pasada podría no ser tan exhaustivo como necesitamos, al igual que extraer entidades y relaciones.
Además, no he encontrado ninguna referencia o ejemplo de su uso en su código en recuperadores de búsqueda locales o globales. Como resultado, nos abstendremos de extraer hallazgos en este caso. O, como suelen decir los académicos: Este ejercicio se deja al lector. Además, también hemos omitido las afirmaciones o la extracción de información de covariables , que a primera vista parecen similares a los hallazgos.
El mensaje que utilizaremos para producir los resúmenes de la comunidad es bastante sencillo:
community_template = """Based on the provided nodes and relationships that belong to the same graph community, generate a natural language summary of the provided information: {community_info} Summary:""" # noqa: E501 community_prompt = ChatPromptTemplate.from_messages( [ ( "system", "Given an input triples, generate the information summary. No pre-amble.", ), ("human", community_template), ] ) community_chain = community_prompt | llm | StrOutputParser()
Lo único que queda es convertir las representaciones de la comunidad en cadenas para reducir la cantidad de tokens evitando la sobrecarga de tokens JSON y envolver la cadena como una función:
def prepare_string(data): nodes_str = "Nodes are:\n" for node in data['nodes']: node_id = node['id'] node_type = node['type'] if 'description' in node and node['description']: node_description = f", description: {node['description']}" else: node_description = "" nodes_str += f"id: {node_id}, type: {node_type}{node_description}\n" rels_str = "Relationships are:\n" for rel in data['rels']: start = rel['start'] end = rel['end'] rel_type = rel['type'] if 'description' in rel and rel['description']: description = f", description: {rel['description']}" else: description = "" rels_str += f"({start})-[:{rel_type}]->({end}){description}\n" return nodes_str + "\n" + rels_str def process_community(community): stringify_info = prepare_string(community) summary = community_chain.invoke({'community_info': stringify_info}) return {"community": community['communityId'], "summary": summary}
Ahora podemos generar resúmenes de la comunidad para los niveles seleccionados. Nuevamente, paralelizamos las llamadas para una ejecución más rápida:
summaries = [] with ThreadPoolExecutor() as executor: futures = {executor.submit(process_community, community): community for community in community_info} for future in tqdm(as_completed(futures), total=len(futures), desc="Processing communities"): summaries.append(future.result())
Un aspecto que no mencioné es que los autores también abordan el problema potencial de exceder el tamaño del contexto al ingresar información de la comunidad. A medida que los gráficos se expanden, las comunidades también pueden crecer significativamente. En nuestro caso, la comunidad más grande estaba compuesta por 545 miembros. Dado que GPT-4o tiene un tamaño de contexto que supera los 100 000 tokens, decidimos omitir este paso.
Como paso final, almacenaremos los resúmenes de la comunidad en la base de datos:
graph.query(""" UNWIND $data AS row MERGE (c:__Community__ {id:row.community}) SET c.summary = row.summary """, params={"data": summaries})
La estructura gráfica final:


El gráfico ahora contiene los documentos originales, las entidades y relaciones extraídas, así como la estructura jerárquica de la comunidad y los resúmenes.
Resumen
Los autores del artículo “From Local to Global” han hecho un gran trabajo al demostrar un nuevo enfoque para GraphRAG. Muestran cómo podemos combinar y resumir información de varios documentos en una estructura jerárquica de gráfico de conocimiento.
Una cosa que no se menciona explícitamente es que también podemos integrar fuentes de datos estructuradas en un gráfico; la entrada no tiene por qué limitarse únicamente a texto no estructurado.
Lo que más valoro de su método de extracción es que capturan descripciones tanto de nodos como de relaciones. Las descripciones permiten que el LLM retenga más información que si redujera todo a los identificadores de nodos y los tipos de relaciones.
Además, demuestran que una única pasada de extracción sobre el texto podría no capturar toda la información relevante e introducen una lógica para realizar varias pasadas si es necesario. Los autores también presentan una idea interesante para realizar resúmenes sobre comunidades de grafos, lo que nos permite incorporar e indexar información temática condensada en múltiples fuentes de datos.
En la próxima publicación del blog, repasaremos las implementaciones del recuperador de búsqueda local y global y hablaremos sobre otros enfoques que podríamos implementar en función de la estructura gráfica dada.
Como siempre, el código está disponible en GitHub .
Esta vez, también he subido el volcado de la base de datos para que puedas explorar los resultados y experimentar con diferentes opciones de recuperación.
También puede importar este volcado a una instancia de AuraDB Neo4j gratuita para siempre , que podemos usar para las exploraciones de recuperación, ya que no necesitamos algoritmos de Graph Data Science para ellas, solo coincidencia de patrones de gráficos, vectores e índices de texto completo.
Obtenga más información sobre las integraciones de Neo4j con todos los marcos GenAI y algoritmos gráficos prácticos en mi libro “Algoritmos gráficos para ciencia de datos”.
Para obtener más información sobre este tema, únase a nosotros en NODES 2024 el 7 de noviembre, nuestra conferencia virtual gratuita para desarrolladores sobre aplicaciones inteligentes, gráficos de conocimiento e IA. ¡Regístrese ahora !








