
























زه تل د ګرافونو په اوږدو کې د بیا ترلاسه کولو - لوړ شوي نسل (RAG) پلي کولو لپاره د نوي لارو چارو په اړه لیواله یم ، چې ډیری وختونه د ګرافراګ په نوم یادیږي. په هرصورت، داسې ښکاري چې هرڅوک په ذهن کې مختلف تطبیق لري کله چې دوی د GraphRAG اصطالح واوري. پدې بلاګ پوسټ کې ، موږ به د مایکروسافټ څیړونکو لخوا د " سیمه ایز څخه تر نړیوال ګرافراګ " مقالې او پلي کولو کې ژور ډوب کړو. موږ به د پوهې ګراف جوړونې او لنډیز کولو برخه پوښو او د راتلونکي بلاګ پوسټ لپاره ترلاسه کونکي پریږدو. څیړونکي دومره مهربان وو چې موږ ته د کوډ ذخیره چمتو کړي، او دوی د پروژې پاڼه هم لري.
په پورته ذکر شوي مقاله کې اخیستل شوی چلند خورا په زړه پوری دی. تر هغه ځایه چې زه پوهیږم، پدې کې د پوهې ګراف کارول شامل دي په پایپ لاین کې د یو ګام په توګه د ډیرو سرچینو څخه د معلوماتو راټولولو او یوځای کولو لپاره. له متن څخه د ادارو او اړیکو استخراج کومه نوې خبره نه ده. په هرصورت، لیکوالان یو ناول (لږترلږه ما ته) د لنډیز شوي ګراف جوړښت او معلومات د طبیعي ژبې متن په توګه د لنډیز کولو مفکوره وړاندې کوي. پایپ لاین د اسنادو د ان پټ متن سره پیل کیږي، کوم چې د ګراف تولید لپاره پروسس کیږي. ګراف بیا د طبیعي ژبې متن ته بدلیږي، چیرته چې تولید شوی متن د ځانګړو ادارو یا ګراف ټولنو په اړه کم شوي معلومات لري چې مخکې په ډیرو اسنادو کې خپاره شوي.


په ډیره لوړه کچه، د ګرافراګ پایپ لاین ته ننوتل د سرچینې اسناد دي چې مختلف معلومات لري. اسناد د LLM په کارولو سره پروسس کیږي ترڅو د ادارو په اړه جوړښت شوي معلومات راټول کړي چې په کاغذونو کې د دوی د اړیکو سره څرګندیږي. دا استخراج شوي جوړښت شوي معلومات بیا د پوهې ګراف جوړولو لپاره کارول کیږي.
د پوهې ګراف ډیټا نمایندګۍ کارولو ګټه دا ده چې دا کولی شي په چټکه او مستقیم ډول د ځانګړو ادارو په اړه د ډیری اسنادو یا ډیټا سرچینو څخه معلومات یوځای کړي. لکه څنګه چې یادونه وشوه، د پوهې ګراف یوازې د معلوماتو استازیتوب نه دی، که څه هم. وروسته له دې چې د پوهې ګراف جوړ شو، دوی د ګراف الګوریتمونو او LLM هڅونې ترکیب کاروي ترڅو د پوهې ګراف کې موندل شوي د ټولنو ټولنو طبیعي ژبې لنډیز رامینځته کړي.
دا لنډیزونه بیا د ځانګړو ادارو او ټولنو لپاره د ډیری ډیټا سرچینو او اسنادو په اوږدو کې پراخه شوي معلومات لري.
د پایپ لاین په اړه د لا زیاتو مفاهیمو لپاره، موږ کولی شو د ګام په ګام توضیحاتو ته مراجعه وکړو چې په اصلي کاغذ کې چمتو شوي.


په پایپ لاین کې ګامونه - د ګرافراګ کاغذ څخه عکس، د CC BY 4.0 لاندې جواز شوی
لاندې د پایپ لاین د لوړې کچې لنډیز دی چې موږ به یې د Neo4j او LangChain په کارولو سره د دوی چلند بیا تولید لپاره وکاروو.
لیست کول - د ګراف تولید
- د سرچینې اسناد د متن ټوټو ته : د سرچینې اسناد د پروسس کولو لپاره په کوچنیو متنونو ویشل شوي دي.
- د عناصرو مثالونو ته د متن ټوټې : د متن هره برخه د ادارو او اړیکو استخراج لپاره تحلیل کیږي، د ټپلونو لیست تولیدوي چې د دې عناصرو استازیتوب کوي.
- د عنصر لنډیزونو ته د عنصر مثالونه : استخراج شوي ادارې او اړیکې د LLM لخوا د هر عنصر لپاره د توضیحي متن بلاکونو کې لنډیز شوي.
- د ګراف ټولنو ته د عنصر لنډیزونه : دا د وجود لنډیزونه یو ګراف جوړوي، چې بیا وروسته په ټولنو کې ویشل کیږي لکه الګوریتمونه لکه لیډن د درجه بندي جوړښت لپاره.
- د ټولنې لنډیزونو ته ګراف ټولنې : د هرې ټولنې لنډیز د LLM سره رامینځته کیږي ترڅو د ډیټاسیټ نړیوال موضوعي جوړښت او سیمانټیک پوه شي.
ترلاسه کول - ځواب ورکول
- نړیوال ځوابونو ته د ټولنې لنډیز : د ټولنې لنډیز د منځګړیتوب ځوابونو په جوړولو سره د کارونکي پوښتنې ته د ځواب ویلو لپاره کارول کیږي، کوم چې بیا په وروستي نړیوال ځواب کې راټول شوي.
په یاد ولرئ چې زما پلي کول مخکې له دې چې د دوی کوډ شتون ولري ترسره شوی و، نو ممکن د اصلي طریقې یا LLM په کارولو کې لږ توپیرونه شتون ولري. زه به هڅه وکړم چې دا توپیرونه تشریح کړم کله چې موږ ورسره ځو.
کوډ په GitHub کې شتون لري.
د Neo4j چاپیریال تنظیم کول
موږ به Neo4j د اصلي ګراف پلورنځي په توګه وکاروو. د پیل کولو ترټولو اسانه لار د Neo4j Sandbox وړیا مثال کارول دي، کوم چې د ګراف ډیټا ساینس پلگ ان نصب سره د Neo4j ډیټابیس کلاوډ مثالونه وړاندې کوي. په بدیل سره ، تاسو کولی شئ د Neo4j ډیسټاپ غوښتنلیک ډاونلوډ کولو او د ځایی ډیټابیس مثال رامینځته کولو سره د Neo4j ډیټابیس ځایی مثال تنظیم کړئ. که تاسو محلي نسخه کاروئ، ډاډ ترلاسه کړئ چې دواړه APOC او GDS پلگ ان نصب کړئ. د تولید تنظیماتو لپاره ، تاسو کولی شئ تادیه شوي ، اداره شوي AuraDS (ډیټا ساینس) مثال وکاروئ ، کوم چې د GDS پلگ ان چمتو کوي.
موږ د Neo4jGraph مثال په رامینځته کولو سره پیل کوو ، کوم چې د اسانتیا ریپر دی چې موږ په لینګ چین کې اضافه کړ:
from langchain_community.graphs import Neo4jGraph os.environ["NEO4J_URI"] = "bolt://44.202.208.177:7687" os.environ["NEO4J_USERNAME"] = "neo4j" os.environ["NEO4J_PASSWORD"] = "mast-codes-trails" graph = Neo4jGraph(refresh_schema=False)ډیټاسیټ
موږ به د خبر مقالې ډیټاسیټ وکاروو چې ما یو څه وخت دمخه د Diffbot د API په کارولو سره رامینځته کړی. ما دا زما GitHub ته د اسانه بیا کارولو لپاره اپلوډ کړی دی:
news = pd.read_csv( "https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/news_articles.csv" ) news["tokens"] = [ num_tokens_from_string(f"{row['title']} {row['text']}") for i, row in news.iterrows() ] news.head()
راځئ چې د ډیټاسیټ څخه لومړۍ دوه قطارونه معاینه کړو.


موږ د مقالو سرلیک او متن لرو ، د دوی د خپرولو نیټې او د ټیکټوکن کتابتون په کارولو سره د ټوکن شمیر سره.
د متن ټوټې کول
د متن ټوټې کولو ګام خورا مهم دی او د پام وړ د لاندې پایلو اغیزه کوي. د کاغذ لیکوالانو وموندله چې د کوچني متن ټوټو کارول په ټولیز ډول د ډیرو ادارو استخراج پایله لري.


د استخراجي ادارو شمیر چې د متن ټوټو اندازه ورکول کیږي — د ګرافراګ کاغذ څخه عکس چې د CC BY 4.0 لاندې جواز لري
لکه څنګه چې تاسو لیدلی شئ، د 2,400 ټوکنونو متن ټوټو کارول د 600 ټوکنونو په پرتله لږ استخراج شوي ادارو کې پایلې لري. برسیره پردې، دوی پیژندلي چې LLMs ممکن په لومړي پړاو کې ټولې ادارې نه استخراج کړي. په دې حالت کې، دوی څو ځله د استخراج ترسره کولو لپاره هوریستیک معرفي کوي. موږ به په راتلونکي برخه کې پدې اړه نور خبرې وکړو.
په هرصورت، تل د سوداګرۍ بندونه شتون لري. د کوچني متن ټوټو کارول کولی شي د سندونو په اوږدو کې د ځانګړو ادارو د شرایطو او اصلي حوالې له لاسه ورکولو پایله ولري. د مثال په توګه، که یو سند په جلا جملو کې "جان" او "هغه" ذکر کړي، متن په کوچنیو برخو کې ماتول ممکن دا روښانه کړي چې "هغه" جان ته اشاره کوي. ځینې اصلي مسلې د متن د راټولولو ستراتیژۍ په کارولو سره حل کیدی شي، مګر دا ټول نه.
راځئ چې زموږ د مقالې متنونو اندازه وڅیړو:
sns.histplot(news["tokens"], kde=False) plt.title('Distribution of chunk sizes') plt.xlabel('Token count') plt.ylabel('Frequency') plt.show()


د مقالو توکیو شمیرو ویش تقریبا نورمال دی، د شاوخوا 400 ټوکنونو لوړوالی سره. د ټوټو فریکونسۍ په تدریجي ډول دې چوکۍ ته لوړیږي ، بیا په سمیټریک ډول کمیږي ، دا په ګوته کوي چې ډیری متن ټوټې د 400 نښه نښه ته نږدې دي.
د دې توزیع له امله، موږ به دلته د متن ټوټې کول ترسره نه کړو ترڅو د اصلي مسلو څخه مخنیوی وشي. په ډیفالټ ډول، د GraphRAG پروژه د 100 ټوکنونو اوورلیپ سره د 300 ټوکنونو اندازه کاروي.
د نوډونو او اړیکو استخراج
بل ګام د متن ټوټو څخه پوهه جوړول دي. د دې کارونې قضیې لپاره، موږ د متن څخه د نوډونو او اړیکو په بڼه جوړښت شوي معلومات استخراج لپاره LLM کاروو. تاسو کولی شئ د LLM پرامپټ معاینه کړئ هغه لیکوالان چې په کاغذ کې کارول شوي. دوی د LLM وړاندیزونه لري چیرې چې موږ کولی شو د اړتیا په صورت کې د نوډ لیبل تعریف کړو ، مګر په ډیفالټ ، دا اختیاري دی. برسیره پردې، په اصلي اسنادو کې استخراج شوي اړیکې واقعیا یو ډول نه لري، یوازې یو توضیح. زه فکر کوم چې د دې انتخاب تر شا دلیل دا دی چې LLM ته اجازه ورکړي چې د اړیکو په توګه بډایه او خورا مهم معلومات استخراج او وساتي. مګر دا ستونزمنه ده چې د پاکې پوهې ګراف ولرئ پرته له دې چې د اړیکو ډول ډول مشخصات ولري (تفصیلات کیدای شي ملکیت ته لاړ شي).
زموږ په تطبیق کې، موږ به د LLMGraphTransformer څخه کار واخلو، کوم چې په LangChain کتابتون کې شتون لري. د خالص پرامپټ انجینرۍ کارولو پرځای ، لکه څنګه چې د مقالې مقاله کې پلي کیږي ، LLMGraphTransformer د جوړښت شوي معلوماتو استخراج لپاره د جوړ شوي فنکشن کال کولو ملاتړ کاروي (په LangChain کې جوړښت شوي محصول LLMs). تاسو کولی شئ د سیسټم پرامپټ معاینه کړئ:
from langchain_experimental.graph_transformers import LLMGraphTransformer from langchain_openai import ChatOpenAI llm = ChatOpenAI(temperature=0, model_name="gpt-4o") llm_transformer = LLMGraphTransformer( llm=llm, node_properties=["description"], relationship_properties=["description"] ) def process_text(text: str) -> List[GraphDocument]: doc = Document(page_content=text) return llm_transformer.convert_to_graph_documents([doc])
په دې مثال کې، موږ د ګراف استخراج لپاره GPT-4o کاروو. لیکوالان په ځانګړې توګه LLM ته لارښوونه کوي چې ادارې او اړیکې او د دوی توضیحات استخراج کړي . د LangChain تطبیق سره، تاسو کولی شئ د node_properties او relationship_properties ځانګړتیاوې وکاروئ ترڅو مشخص کړئ چې کوم نوډ یا د اړیکو ملکیتونه تاسو غواړئ چې LLM استخراج کړئ.
د LLMGraphTransformer تطبیق سره توپیر دا دی چې ټول نوډ یا د اړیکو ملکیت اختیاري دي، نو ټول نوډونه به د description ملکیت ونه لري. که موږ وغواړو، موږ کولی شو یو دودیز استخراج تعریف کړو ترڅو د اجباري description ملکیت ولري، مګر موږ به دا په دې تطبیق کې پریږدو.
موږ به د ګراف استخراج ګړندي کولو لپاره غوښتنې موازي کړو او پایلې به Neo4j ته ذخیره کړو:
MAX_WORKERS = 10 NUM_ARTICLES = 2000 graph_documents = [] with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # Submitting all tasks and creating a list of future objects futures = [ executor.submit(process_text, f"{row['title']} {row['text']}") for i, row in news.head(NUM_ARTICLES).iterrows() ] for future in tqdm( as_completed(futures), total=len(futures), desc="Processing documents" ): graph_document = future.result() graph_documents.extend(graph_document) graph.add_graph_documents( graph_documents, baseEntityLabel=True, include_source=True )
په دې مثال کې، موږ د 2,000 مقالو څخه د ګراف معلومات راټولوو او پایلې یې Neo4j ته ذخیره کوو. موږ شاوخوا 13,000 ادارې او 16,000 اړیکې استخراج کړې. دلته په ګراف کې د استخراج شوي سند یوه بیلګه ده.


دا د استخراج بشپړولو لپاره شاوخوا 35 (+/- 5) دقیقې وخت نیسي او د GPT-4o سره شاوخوا $ 30 لګښت لري.
پدې مرحله کې ، لیکوالان هوریستیک معرفي کوي ترڅو پریکړه وکړي چې ایا د ګراف معلومات له یو څخه ډیر پاس کې استخراج کړي. د سادگي لپاره، موږ به یوازې یو پاس ترسره کړو. په هرصورت، که موږ وغواړو څو څو پاسونه ترسره کړو، موږ کولی شو د استخراج لومړنۍ پایلې د خبرو اترو تاریخ په توګه وساتو او په ساده ډول LLM ته لارښوونه وکړو چې ډیری ادارې ورکې دي ، او دا باید نور استخراج کړي، لکه د GraphRAG لیکوالان یې کوي.
مخکې، ما یادونه وکړه چې د متن اندازه څومره حیاتي ده او دا څنګه د استخراج شویو ادارو شمیر اغیزه کوي. له هغه ځایه چې موږ کوم اضافي متن ټوټه کول نه دي ترسره کړي، موږ کولی شو د استخراج شویو ادارو ویش د متن د اندازې پر بنسټ ارزونه وکړو:
entity_dist = graph.query( """ MATCH (d:Document) RETURN d.text AS text, count {(d)-[:MENTIONS]->()} AS entity_count """ ) entity_dist_df = pd.DataFrame.from_records(entity_dist) entity_dist_df["token_count"] = [ num_tokens_from_string(str(el)) for el in entity_dist_df["text"] ] # Scatter plot with regression line sns.lmplot( x="token_count", y="entity_count", data=entity_dist_df, line_kws={"color": "red"} ) plt.title("Entity Count vs Token Count Distribution") plt.xlabel("Token Count") plt.ylabel("Entity Count") plt.show()


د توزیع پلاټ ښیي چې پداسې حال کې چې یو مثبت رجحان شتون لري، د سره کرښې لخوا اشاره شوې، اړیکه فرعي ده. ډیری ډیټا پوائنټونه د ټیټ ادارو شمیرو کې کلستر کیږي ، حتی لکه څنګه چې د نښې شمیرې ډیریږي. دا په ګوته کوي چې د استخراج شویو ادارو شمیر د متن د ټوټو د اندازې سره متناسب اندازه نه کوي. که څه هم ځینې بهرنیان شتون لري، عمومي نمونه ښیي چې د لوړې نښې شمیرې په دوامداره توګه د لوړو ادارو شمیرو لامل نه کیږي. دا د لیکوالانو موندنه تاییدوي چې د ټیټ متن ټوټې اندازه به نور معلومات استخراج کړي.
ما دا هم فکر کاوه چې دا به په زړه پوري وي چې د جوړ شوي ګراف د نوډ درجې توزیع معاینه کړئ. لاندې کوډ د نوډ درجې توزیع ترلاسه کوي او لید یې کوي:
degree_dist = graph.query( """ MATCH (e:__Entity__) RETURN count {(e)-[:!MENTIONS]-()} AS node_degree """ ) degree_dist_df = pd.DataFrame.from_records(degree_dist) # Calculate mean and median mean_degree = np.mean(degree_dist_df['node_degree']) percentiles = np.percentile(degree_dist_df['node_degree'], [25, 50, 75, 90]) # Create a histogram with a logarithmic scale plt.figure(figsize=(12, 6)) sns.histplot(degree_dist_df['node_degree'], bins=50, kde=False, color='blue') # Use a logarithmic scale for the x-axis plt.yscale('log') # Adding labels and title plt.xlabel('Node Degree') plt.ylabel('Count (log scale)') plt.title('Node Degree Distribution') # Add mean, median, and percentile lines plt.axvline(mean_degree, color='red', linestyle='dashed', linewidth=1, label=f'Mean: {mean_degree:.2f}') plt.axvline(percentiles[0], color='purple', linestyle='dashed', linewidth=1, label=f'25th Percentile: {percentiles[0]:.2f}') plt.axvline(percentiles[1], color='orange', linestyle='dashed', linewidth=1, label=f'50th Percentile: {percentiles[1]:.2f}') plt.axvline(percentiles[2], color='yellow', linestyle='dashed', linewidth=1, label=f'75th Percentile: {percentiles[2]:.2f}') plt.axvline(percentiles[3], color='brown', linestyle='dashed', linewidth=1, label=f'90th Percentile: {percentiles[3]:.2f}') # Add legend plt.legend() # Show the plot plt.show()


د نوډ درجې توزیع د بریښنا قانون نمونه تعقیبوي، دا په ګوته کوي چې ډیری نوډونه خورا لږ ارتباط لري پداسې حال کې چې یو څو نوډونه خورا ډیر تړلي دي. منځنۍ درجه 2.45 ده، او منځنۍ درجه 1.00 ده، دا ښیي چې له نیمایي څخه زیات نوډونه یوازې یو تړاو لري. ډیری نوډونه (75 سلنه) دوه یا لږ اړیکې لري، او 90 سلنه پنځه یا لږ څه لري. دا توزیع د ډیری ریښتیني نړۍ شبکو لپاره ځانګړی دی ، چیرې چې لږ شمیر مرکزونه ډیری اړیکې لري ، او ډیری نوډونه لږ دي.
څرنګه چې دواړه نوډ او د اړیکو توضیحات لازمي ملکیتونه ندي، موږ به دا هم وڅیړو چې څومره استخراج شوي:
graph.query(""" MATCH (n:`__Entity__`) RETURN "node" AS type, count(*) AS total_count, count(n.description) AS non_null_descriptions UNION ALL MATCH (n)-[r:!MENTIONS]->() RETURN "relationship" AS type, count(*) AS total_count, count(r.description) AS non_null_descriptions """)
پایلې ښیې چې د 12,994 څخه 5,926 نوډونه (45.6 سلنه) د توضیح ملکیت لري. له بلې خوا، له 15,921 څخه یوازې 5,569 اړیکې (35 سلنه) دا ډول ملکیت لري.
په یاد ولرئ چې د LLMs احتمالي طبیعت له امله ، شمیرې په مختلف منډو او مختلف سرچینې ډیټا ، LLMs ، او اشارو کې توپیر کولی شي.
د ادارې قرارداد
د ادارې ریزولوشن (د نقل کولو) د پوهې ګرافونو رامینځته کولو کې خورا مهم دی ځکه چې دا ډاډ ورکوي چې هره اداره په ځانګړي او دقیق ډول نمایش کیږي ، د نقلونو مخه نیسي او د ریکارډونو یوځای کول چې ورته ریښتیني نړۍ ته راجع کیږي. دا پروسه په ګراف کې د معلوماتو بشپړتیا او ثبات ساتلو لپاره اړینه ده. د ادارې ریزولوشن پرته، د پوهې ګرافونه به د ټوټې او متناسب معلوماتو سره مخ شي، چې د غلطیو او غیر باوري بصیرت لامل کیږي.


دا انځور ښیي چې څنګه د ریښتینې نړۍ یو واحد وجود په مختلفو اسنادو کې او په پایله کې، زموږ په ګراف کې د یو څه مختلف نومونو لاندې ښکاره کیدی شي.
برسېره پردې، لږ معلومات د ادارې حل پرته د پام وړ مسله کیږي. د مختلفو سرچینو څخه نیمګړی یا جزوی معلومات کولی شي د معلوماتو د ویشل شوي او منحل شوي ټوټو لامل شي، چې دا ستونزمن کوي چې د ادارو یو همغږي او هراړخیز پوهه رامینځته کړي. د ادارې دقیق حل دا د ډیټا راټولولو ، تشو ډکولو ، او د هرې ادارې متحد لید رامینځته کولو سره حل کوي.


د تحقیقاتي ژورنالیستانو نړیوال کنسورشیم (ICIJ) آف شور لیک ډیټا سره وصل کولو لپاره د سینزینګ ادارې ریزولوشن کارولو دمخه / وروسته - د پیکو ناتان عکس
د بصری کیڼ برخه یو نری او غیر مربوط ګراف وړاندې کوي. په هرصورت، لکه څنګه چې په ښي خوا کې ښودل شوي، دا ډول ګراف کولی شي د اغیزمنې ادارې حل سره ښه وصل شي.
په ټولیز ډول، د ادارې ریزولوشن د معلوماتو د ترلاسه کولو او ادغام موثریت ته وده ورکوي، په مختلفو سرچینو کې د معلوماتو یو همغږي لید چمتو کوي. دا په نهایت کې د باور وړ او بشپړ پوهې ګراف پراساس خورا مؤثره پوښتنو ځوابونو ته وړتیا ورکوي.
له بده مرغه، د ګرافراګ کاغذ لیکوالانو په خپل ریپو کې د ادارې د حل کوډ شامل نه کړ، که څه هم دوی دا په خپل کاغذ کې یادونه کوي. د دې کوډ پریښودو یو دلیل کیدی شي دا وي چې د هرې ډومین لپاره د قوي او ښه فعالیت کونکي ادارې حل پلي کول سخت دي. تاسو کولی شئ د مختلف نوډونو لپاره دودیز هوریستیک پلي کړئ کله چې د مخکې ټاکل شوي نوډونو سره معامله کوئ (کله چې دوی دمخه نه ټاکل شوي وي ، دوی کافي نه وي لکه شرکت ، سازمان ، سوداګرۍ او داسې نور). که څه هم، که د نوډ لیبل یا ډولونه مخکې له مخکې نه پیژندل شوي، لکه څنګه چې زموږ په قضیه کې، دا حتی سخته ستونزه کیږي. په هرصورت، موږ به دلته زموږ په پروژه کې د ادارې ریزولوشن یوه نسخه پلي کړو، د متن ایمبیډینګونه او ګراف الګوریتمونه د کلمې فاصلې او LLMs سره یوځای کول.


د ادارې د حل لپاره زموږ پروسه لاندې مرحلې لري:
- په ګراف کې موجودات - په ګراف کې د ټولو ادارو سره پیل کړئ.
- د K-نږدې ګراف - د k-نږدې ګاونډی ګراف جوړ کړئ، د متن ایډیډینګونو پراساس ورته ادارې وصل کړئ.
- کمزوري وصل شوي اجزا - د k-نږدې ګراف کې ضعیفه وصل شوي اجزاوې وپیژنئ، د هغو ادارو ګروپ کول چې احتمال ورته ورته وي. د دې اجزاو پیژندلو وروسته د کلمې فاصله فلټر کولو مرحله اضافه کړئ.
- د LLM ارزونه - د دې اجزاو ارزولو لپاره LLM وکاروئ او پریکړه وکړئ چې ایا د هرې برخې دننه ادارې باید ضمیمه شي ، په پایله کې د ادارې ریزولوشن په اړه وروستۍ پریکړه کیږي (د مثال په توګه ، د 'سیلیکون ویلی بانک' او 'سیلیکون_ویلی_بانک' یوځای کول پداسې حال کې چې د مختلف لپاره ادغام رد کول. نیټې لکه 'سپتمبر 16، 2023' او 'سپتمبر 2، 2023').
موږ د ادارو د نوم او توضیحي ملکیتونو لپاره د متن سرایتونو محاسبه کولو سره پیل کوو. موږ کولی شو د دې ترلاسه کولو لپاره په LangChain کې د Neo4jVector ادغام کې د from_existing_graph میتود وکاروو:
vector = Neo4jVector.from_existing_graph( OpenAIEmbeddings(), node_label='__Entity__', text_node_properties=['id', 'description'], embedding_node_property='embedding' )
موږ کولی شو دا سرایتونه د احتمالي نوماندانو موندلو لپاره وکاروو چې د دې ایمبیډینګونو د کوزین فاصلې پراساس ورته وي. موږ به د ګراف ډیټا ساینس (GDS) کتابتون کې موجود ګراف الګوریتمونه وکاروو؛ له همدې امله، موږ کولی شو د Pythonیک طریقې کې د اسانتیا لپاره د GDS Python مراجع وکاروو:
from graphdatascience import GraphDataScience gds = GraphDataScience( os.environ["NEO4J_URI"], auth=(os.environ["NEO4J_USERNAME"], os.environ["NEO4J_PASSWORD"]) )
که تاسو د GDS کتابتون سره بلد نه یاست، موږ باید لومړی د حافظې ګراف وړاندې کړو مخکې لدې چې موږ کوم ګراف الګوریتم اجرا کړو.


لومړی، د Neo4j زیرمه شوی ګراف د ګړندي پروسس او تحلیل لپاره په حافظه کې ګراف کې وړاندیز شوی. بیا، د ګراف الګوریتم د حافظې په ګراف کې اجرا کیږي. په اختیاري توګه، د الګوریتم پایلې بیرته په Neo4j ډیټابیس کې زیرمه کیدی شي. د دې په اړه نور معلومات په اسنادو کې زده کړئ.
د k-نږدې ګاونډی ګراف د جوړولو لپاره، موږ به ټول شرکتونه د دوی د متن ایمبیډینګونو سره وړاندې کړو:
G, result = gds.graph.project( "entities", # Graph name "__Entity__", # Node projection "*", # Relationship projection nodeProperties=["embedding"] # Configuration parameters )
اوس چې ګراف د entities نوم لاندې اټکل شوی، موږ کولی شو د ګراف الګوریتم اجرا کړو. موږ به د k - نږدې ګراف په جوړولو سره پیل وکړو. دوه خورا مهم پیرامیټرونه چې تاثیر کوي چې د k - نږدې ګراف به څومره کم یا کثافت وي similarityCutoff او topK دي. topK د هر نوډ لپاره د موندلو لپاره د ګاونډیانو شمیر دی، چې لږ تر لږه 1 ارزښت لري. similarityCutoff د دې حد لاندې د ورته والی سره اړیکې فلټر کوي. دلته، موږ به د 10 ډیفالټ topK او د 0.95 نسبتا لوړ ورته والی کټ آف وکاروو. د لوړ ورته والی کټ آف کارول، لکه 0.95، دا یقیني کوي چې یوازې خورا ورته ورته جوړه میچونه ګڼل کیږي، غلط مثبت کموي او دقت ښه کوي.


له هغه ځایه چې موږ غواړو پایلې بیرته د پوهې ګراف پرځای په یادداشت کې اټکل شوي ګراف ته وسپارو، موږ به د الګوریتم mutate موډ وکاروو:
similarity_threshold = 0.95 gds.knn.mutate( G, nodeProperties=['embedding'], mutateRelationshipType= 'SIMILAR', mutateProperty= 'score', similarityCutoff=similarity_threshold )
بل ګام دا دی چې د ادارو ګروپونه وپیژني کوم چې د نوي اټکل شوي ورته ورته اړیکو سره تړلي دي. د وصل شوي نوډونو ګروپونو پیژندل د شبکې تحلیل کې یو پرله پسې پروسه ده چې ډیری وختونه د ټولنې کشف یا کلسترینګ په نوم یادیږي ، کوم چې د ډیری تړل شوي نوډونو فرعي ګروپونو موندل شامل دي. په دې مثال کې، موږ به د کمزوري وصل شوي اجزاو الګوریتم وکاروو، کوم چې موږ سره د ګراف د برخو په موندلو کې مرسته کوي چیرې چې ټول نوډونه وصل دي، حتی که موږ د ارتباط لوري ته سترګې پټې کړو.


موږ د الګوریتم د write حالت کاروو ترڅو پایلې بیرته ډیټابیس ته ذخیره کړو (ذخیره شوي ګراف):
gds.wcc.write( G, writeProperty="wcc", relationshipTypes=["SIMILAR"] )
د متن سرایت پرتله کول د احتمالي نقلونو موندلو کې مرسته کوي ، مګر دا یوازې د ادارې حل پروسې برخه ده. د مثال په توګه، ګوګل او ایپل د سرایت کولو ځای کې خورا نږدې دي (0.96 کوزین ورته والی د ada-002 ایمبیډینګ ماډل په کارولو سره). ورته د BMW او مرسډیز بینز (0.97 کوزین ورته والی) لپاره ځي. د لوړ متن سرایت ورته والی یو ښه پیل دی، مګر موږ کولی شو دا ښه کړو. له همدې امله، موږ به یو اضافي فلټر اضافه کړو چې یوازې د دریو یا لږ متن فاصله سره د کلمو جوړه اجازه ورکوي (په دې معنی چې یوازې حروف بدل کیدی شي):
word_edit_distance = 3 potential_duplicate_candidates = graph.query( """MATCH (e:`__Entity__`) WHERE size(e.id) > 3 // longer than 3 characters WITH e.wcc AS community, collect(e) AS nodes, count(*) AS count WHERE count > 1 UNWIND nodes AS node // Add text distance WITH distinct [n IN nodes WHERE apoc.text.distance(toLower(node.id), toLower(n.id)) < $distance OR node.id CONTAINS n.id | n.id] AS intermediate_results WHERE size(intermediate_results) > 1 WITH collect(intermediate_results) AS results // combine groups together if they share elements UNWIND range(0, size(results)-1, 1) as index WITH results, index, results[index] as result WITH apoc.coll.sort(reduce(acc = result, index2 IN range(0, size(results)-1, 1) | CASE WHEN index <> index2 AND size(apoc.coll.intersection(acc, results[index2])) > 0 THEN apoc.coll.union(acc, results[index2]) ELSE acc END )) as combinedResult WITH distinct(combinedResult) as combinedResult // extra filtering WITH collect(combinedResult) as allCombinedResults UNWIND range(0, size(allCombinedResults)-1, 1) as combinedResultIndex WITH allCombinedResults[combinedResultIndex] as combinedResult, combinedResultIndex, allCombinedResults WHERE NOT any(x IN range(0,size(allCombinedResults)-1,1) WHERE x <> combinedResultIndex AND apoc.coll.containsAll(allCombinedResults[x], combinedResult) ) RETURN combinedResult """, params={'distance': word_edit_distance})
دا د سایفر بیان یو څه ډیر ښکیل دی، او د دې تفسیر د دې بلاګ پوسټ له ساحې څخه بهر دی. تاسو کولی شئ تل د LLM څخه د دې تشریح کولو غوښتنه وکړئ.


برسیره پردې، د فاصلې کټ آف کلمه کیدای شي د یوې شمیرې پر ځای د کلمې د اوږدوالي فعالیت وي او پلي کول کیدای شي د اندازې وړ وي.
هغه څه چې مهم دي دا دي چې دا د احتمالي ادارو ګروپونه تولیدوي چې موږ یې یوځای کول غواړو. دلته د ضم کولو احتمالي نوډونو لیست دی:
{'combinedResult': ['Sinn Fein', 'Sinn Féin']}, {'combinedResult': ['Government', 'Governments']}, {'combinedResult': ['Unreal Engine', 'Unreal_Engine']}, {'combinedResult': ['March 2016', 'March 2020', 'March 2022', 'March_2023']}, {'combinedResult': ['Humana Inc', 'Humana Inc.']}, {'combinedResult': ['New York Jets', 'New York Mets']}, {'combinedResult': ['Asia Pacific', 'Asia-Pacific', 'Asia_Pacific']}, {'combinedResult': ['Bengaluru', 'Mangaluru']}, {'combinedResult': ['US Securities And Exchange Commission', 'Us Securities And Exchange Commission']}, {'combinedResult': ['Jp Morgan', 'Jpmorgan']}, {'combinedResult': ['Brighton', 'Brixton']},
لکه څنګه چې تاسو لیدلی شئ، زموږ د حل طریقه د نورو په پرتله د ځینې نوډ ډولونو لپاره غوره کار کوي. د ګړندي ازموینې پراساس ، داسې بریښي چې د خلکو او سازمانونو لپاره غوره کار کوي ، پداسې حال کې چې دا د نیټو لپاره خورا خراب دی. که موږ له مخکې ټاکل شوي نوډ ډولونه وکاروو، موږ کولی شو د مختلف نوډ ډولونو لپاره مختلف هوریستیک چمتو کړو. په دې مثال کې، موږ مخکې له مخکې ټاکل شوي نوډ لیبلونه نلرو، نو موږ به LLM ته وګرځو ترڅو وروستۍ پریکړه وکړو چې آیا ادارې باید یوځای شي یا نه.
لومړی، موږ اړتیا لرو چې د LLM پرامپټ جوړ کړو ترڅو د نوډونو ادغام په اړه وروستۍ پریکړه په مؤثره توګه لارښود او خبر کړو:
system_prompt = """You are a data processing assistant. Your task is to identify duplicate entities in a list and decide which of them should be merged. The entities might be slightly different in format or content, but essentially refer to the same thing. Use your analytical skills to determine duplicates. Here are the rules for identifying duplicates: 1. Entities with minor typographical differences should be considered duplicates. 2. Entities with different formats but the same content should be considered duplicates. 3. Entities that refer to the same real-world object or concept, even if described differently, should be considered duplicates. 4. If it refers to different numbers, dates, or products, do not merge results """ user_template = """ Here is the list of entities to process: {entities} Please identify duplicates, merge them, and provide the merged list. """
زه تل خوښوم چې په LangChain کې with_structured_output میتود وکاروم کله چې د جوړښت شوي ډیټا محصول تمه کول ترڅو د محصول په لاسي ډول پارس کولو څخه مخنیوی وشي.
دلته، موږ به محصول list of lists په توګه تعریف کړو، چیرته چې هر داخلي لیست هغه ادارې لري چې باید یوځای شي. دا جوړښت د سناریوګانو اداره کولو لپاره کارول کیږي چیرې چې د بیلګې په توګه، ان پټ ممکن وي [Sony, Sony Inc, Google, Google Inc] . په داسې حاالتو کې، تاسو غواړئ "سوني" او "سوني شرکت" د "ګوګل" او "ګوګل شرکت" څخه جلا جلا کړئ.
class DuplicateEntities(BaseModel): entities: List[str] = Field( description="Entities that represent the same object or real-world entity and should be merged" ) class Disambiguate(BaseModel): merge_entities: Optional[List[DuplicateEntities]] = Field( description="Lists of entities that represent the same object or real-world entity and should be merged" ) extraction_llm = ChatOpenAI(model_name="gpt-4o").with_structured_output( Disambiguate )
بیا، موږ د LLM پرامپټ د جوړښت شوي محصول سره مدغم کوو ترڅو د LangChain Expression Language (LCEL) ترکیب په کارولو سره یو زنځیر رامینځته کړي او دا په یو disambiguate فعالیت کې ځای په ځای کړي.
extraction_chain = extraction_prompt | extraction_llm def entity_resolution(entities: List[str]) -> Optional[List[List[str]]]: return [ el.entities for el in extraction_chain.invoke({"entities": entities}).merge_entities ]
موږ اړتیا لرو چې ټول احتمالي کاندید نوډونه د entity_resolution فنکشن له لارې پرمخ بوځو ترڅو پریکړه وکړو چې ایا دوی باید یوځای شي. د پروسې ګړندۍ کولو لپاره ، موږ به بیا د LLM تلیفونونه موازي کړو:
merged_entities = [] with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # Submitting all tasks and creating a list of future objects futures = [ executor.submit(entity_resolution, el['combinedResult']) for el in potential_duplicate_candidates ] for future in tqdm( as_completed(futures), total=len(futures), desc="Processing documents" ): to_merge = future.result() if to_merge: merged_entities.extend(to_merge)
د ادارې ریزولوشن وروستی ګام د entity_resolution LLM څخه پایلې اخیستل او د ټاکل شوي نوډونو په یوځای کولو سره ډیټابیس ته بیرته لیکل شامل دي:
graph.query(""" UNWIND $data AS candidates CALL { WITH candidates MATCH (e:__Entity__) WHERE e.id IN candidates RETURN collect(e) AS nodes } CALL apoc.refactor.mergeNodes(nodes, {properties: { description:'combine', `.*`: 'discard' }}) YIELD node RETURN count(*) """, params={"data": merged_entities})
د دې ادارې ریزولوشن کامل نه دی، مګر دا موږ ته د پیل ټکی راکوي چې موږ یې ښه کولی شو. برسیره پردې، موږ کولی شو منطق ته وده ورکړو ترڅو معلومه کړو چې کوم شرکتونه باید وساتل شي.
د عنصر لنډیز
په بل ګام کې، لیکوالان د عنصر لنډیز ګام ترسره کوي. په لازمي ډول، هر نوډ او اړیکه د ادارې لنډیز پرامپټ له لارې تیریږي. لیکوالان د دوی د تګلارې نوښت او علاقه یادوي:
"په ټولیز ډول ، زموږ په احتمالي شور لرونکي ګراف جوړښت کې د همجنس نوډونو لپاره د بډایه توضیحي متن کارول د LLMs ظرفیتونو او د نړیوال ، پوښتنې متمرکز لنډیز اړتیاو سره همغږي دي. دا ځانګړتیاوې زموږ د ګراف شاخص د عادي پوهې ګرافونو څخه هم توپیر کوي، کوم چې د الندې استدلال دندو لپاره په لنډ او دوامداره پوهه درې ګونی (موضوع، وړاندوینه، اعتراض) تکیه کوي.
خیال په زړه پوری دی. موږ لاهم د متن څخه د موضوع او اعتراض IDs یا نومونه استخراج کوو، کوم چې موږ ته اجازه راکوي چې اړیکې سمو ادارو سره وصل کړو، حتی کله چې ادارې د متن په څو برخو کې څرګندیږي. په هرصورت، اړیکې یو واحد ډول ته ندي کم شوي. پرځای یې، د اړیکو ډول په حقیقت کې یو وړیا متن دی چې موږ ته اجازه راکوي چې بډایه او ډیر مهم معلومات وساتو.
برسیره پردې، د ادارې معلومات د LLM په کارولو سره لنډیز شوي، موږ ته اجازه راکوي چې دا معلومات او ادارې د لا دقیقو لاسته راوړلو لپاره په اغیزمنه توګه داخل او شاخص کړو.
یو څوک استدلال کولی شي چې دا خورا بډایه او خورا مهم معلومات د اضافي ، احتمالي خپلسري ، نوډ او اړیکو ملکیتونو اضافه کولو سره هم ساتل کیدی شي. د خپلسري نوډ او اړیکو ملکیتونو سره یوه مسله دا ده چې دا به سخت وي چې معلومات په دوامداره توګه استخراج کړي ځکه چې LLM ممکن د ملکیت مختلف نومونه وکاروي یا په هر اجرا کولو مختلف توضیحاتو تمرکز وکړي.
ځینې دا ستونزې د اضافي ډول او توضیحاتو معلوماتو سره د مخکیني تعریف شوي ملکیت نومونو په کارولو سره حل کیدی شي. په دې حالت کې، تاسو به د موضوع متخصص ته اړتیا ولرئ ترڅو د دې ملکیتونو په تعریف کې مرسته وکړي، د LLM لپاره لږ ځای پریږدي ترڅو د وړاندې شوي توضیحاتو څخه بهر کوم مهم معلومات راوباسي.
دا د پوهې په ګراف کې د بډایه معلوماتو استازیتوب کولو لپاره په زړه پورې طریقه ده.
د عنصر لنډیز کولو مرحلې سره یوه احتمالي مسله دا ده چې دا ښه اندازه نه کوي ځکه چې دا په ګراف کې د هرې ادارې او اړیکو لپاره LLM غوښتنې ته اړتیا لري. زموږ ګراف د 13,000 نوډونو او 16,000 اړیکو سره نسبتا کوچنی دی. حتی د داسې کوچني ګراف لپاره، موږ به 29,000 LLM زنګونو ته اړتیا ولرو، او هر کال به څو سوه ټوکنونه وکاروي، چې دا خورا ګران او وخت نیسي. له همدې امله، موږ به دلته د دې ګام څخه ډډه وکړو. موږ لاهم کولی شو د لومړني متن پروسس کولو پرمهال استخراج شوي توضیحي ملکیتونه وکاروو.
د ټولنو جوړول او لنډیز کول
د ګراف د جوړولو او د لیست کولو په بهیر کې وروستی ګام په ګراف کې د ټولنو پیژندل شامل دي. په دې شرایطو کې، یوه ټولنه د نوډونو یوه ډله ده چې د ګراف د پاتې برخې په پرتله یو له بل سره ډیر تړلي دي، د متقابل عمل یا ورته والی لوړه کچه په ګوته کوي. لاندې لید د ټولنې د موندلو پایلو یوه بیلګه ښیي.


یوځل چې دا ادارې ټولنې د کلسترینګ الګوریتم سره وپیژندل شي ، LLM د هرې ټولنې لپاره لنډیز رامینځته کوي ، د دوی انفرادي ځانګړتیاو او اړیکو ته بصیرت چمتو کوي.
یوځل بیا ، موږ د ګراف ډیټا ساینس کتابتون کاروو. موږ د حافظې د ګراف په وړاندې کولو سره پیل کوو. د دې لپاره چې اصلي مقاله په سمه توګه تعقیب کړو، موږ به د ادارو ګراف د یوې غیر مستقیم وزن لرونکي شبکې په توګه وړاندې کړو، چیرې چې شبکه د دوو ادارو ترمنځ د اړیکو شمیر څرګندوي:
G, result = gds.graph.project( "communities", # Graph name "__Entity__", # Node projection { "_ALL_": { "type": "*", "orientation": "UNDIRECTED", "properties": {"weight": {"property": "*", "aggregation": "COUNT"}}, } }, )
لیکوالانو د لیډن الګوریتم کار کړی، د درجه بندي کلستر کولو طریقه، په ګراف کې د ټولنو پیژندلو لپاره. د هراړخیز ټولنې کشف الګوریتم کارولو یوه ګټه دا ده چې د ګرانولریت په څو کچو کې ټولنې معاینه کړي. لیکوالان په هره کچه د ټولو ټولنو لنډیز وړاندیز کوي، د ګراف جوړښت په اړه هراړخیز پوهه چمتو کوي.
لومړی، موږ به زموږ د ګراف د ارتباط ارزولو لپاره کمزوري تړل شوي اجزا (WCC) الګوریتم وکاروو. دا الګوریتم په ګراف کې جلا جلا برخې پیژني، پدې معنی چې دا د نوډونو یا اجزاو فرعي سیټونه کشف کوي چې یو له بل سره وصل دي مګر د ګراف پاتې برخې ته ندي. دا اجزا زموږ سره مرسته کوي چې په شبکه کې د ټوټې کولو په اړه پوه شي او د نوډونو ګروپونه وپیژني چې له نورو څخه خپلواک دي. WCC د ګراف د ټولیز جوړښت او ارتباط تحلیل لپاره حیاتي دی.
wcc = gds.wcc.stats(G) print(f"Component count: {wcc['componentCount']}") print(f"Component distribution: {wcc['componentDistribution']}") # Component count: 1119 # Component distribution: { # "min":1, # "p5":1, # "max":9109, # "p999":43, # "p99":19, # "p1":1, # "p10":1, # "p90":7, # "p50":2, # "p25":1, # "p75":4, # "p95":10, # "mean":11.3 }
د WCC الګوریتم پایلې 1,119 جلا جلا برخې په ګوته کړې. په پام کې نیولو سره، ترټولو لوی برخه 9,109 نوډونه لري، چې د ریښتینې نړۍ په شبکو کې عام دي چیرې چې یو واحد سوپر اجزا د ډیری کوچنیو جلا جلا برخو سره یوځای شتون لري. ترټولو کوچنۍ برخه یو نوډ لري، او د منځنۍ برخې اندازه شاوخوا 11.3 نوډونه دي.
بیا، موږ به د لیډن الګوریتم چلوو، کوم چې د GDS کتابتون کې هم شتون لري، او includeIntermediateCommunities پیرامیټر په ټولو کچو کې د ټولنو بیرته راستنیدو او ذخیره کولو لپاره فعال کړو. موږ د لیډین الګوریتم وزن لرونکي ډول چلولو لپاره د relationshipWeightProperty پیرامیټر هم شامل کړی دی. د الګوریتم write حالت کارول پایلې د نوډ ملکیت په توګه ذخیره کوي.
gds.leiden.write( G, writeProperty="communities", includeIntermediateCommunities=True, relationshipWeightProperty="weight", )
الګوریتم د ټولنو پنځه درجې په ګوته کړي، په لوړه کچه (لږترلږه دانه کچه چیرې چې ټولنې لویې دي) 1,188 ټولنې لري (د 1,119 برخو په مقابل کې). دلته د ګیفي په کارولو سره په وروستي کچه د ټولنو لید دی.


د 1,000 څخه زیاتو ټولنو لیدل سخت دي؛ حتی د هر یو لپاره د رنګونو غوره کول په عملي توګه ناممکن دي. په هرصورت، دوی د ښه هنري نندارې لپاره جوړوي.
د دې په جوړولو سره، موږ به د هرې ټولنې لپاره یو جلا نوډ جوړ کړو او د یو بل سره تړلي ګراف په توګه به د دوی درجه بندي جوړښت استازیتوب وکړو. وروسته، موږ به د ټولنې لنډیز او نور ځانګړتیاوې د نوډ ملکیتونو په توګه ذخیره کړو.
graph.query(""" MATCH (e:`__Entity__`) UNWIND range(0, size(e.communities) - 1 , 1) AS index CALL { WITH e, index WITH e, index WHERE index = 0 MERGE (c:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])}) ON CREATE SET c.level = index MERGE (e)-[:IN_COMMUNITY]->(c) RETURN count(*) AS count_0 } CALL { WITH e, index WITH e, index WHERE index > 0 MERGE (current:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])}) ON CREATE SET current.level = index MERGE (previous:`__Community__` {id: toString(index - 1) + '-' + toString(e.communities[index - 1])}) ON CREATE SET previous.level = index - 1 MERGE (previous)-[:IN_COMMUNITY]->(current) RETURN count(*) AS count_1 } RETURN count(*) """)
لیکوالان د community rank هم معرفي کوي، چې د متن د بیلابیلو برخو شمیره په ګوته کوي چې په ټولنه کې شتون لري:
graph.query(""" MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(:__Entity__)<-[:MENTIONS]-(d:Document) WITH c, count(distinct d) AS rank SET c.community_rank = rank; """)
اوس راځئ چې د نمونې درجه بندي جوړښت معاینه کړو چې ډیری منځنۍ ټولنې په لوړو کچو سره یوځای کیږي. ټولنې غیر متقابلې دي، پدې معنی چې هره اداره په هره کچه په دقیق ډول د یوې ټولنې پورې اړه لري.


عکس د لیډین ټولنې کشف الګوریتم پایله کې د یو درجه بندۍ جوړښت استازیتوب کوي. ارغواني نوډونه د انفرادي ادارو استازیتوب کوي، پداسې حال کې چې نارنجي نوډونه د طبقاتي ټولنو استازیتوب کوي.
درجه بندي د دې ادارو تنظیم په مختلفو ټولنو کې ښیي، چې وړې ټولنې په لوړو کچو کې په لویو ټولنو سره یوځای کیږي.
اوس راځئ وګورو چې کوچنۍ ټولنې په لوړو کچو کې څنګه یوځای کیږي.

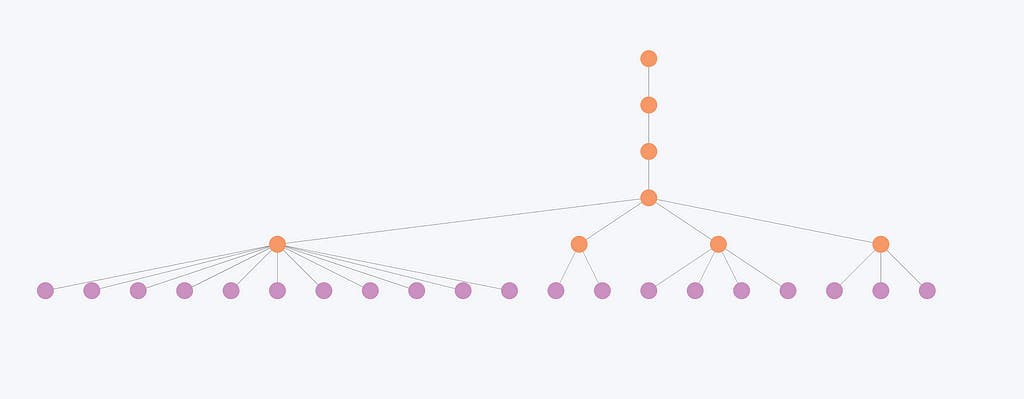
دا انځور ښیي چې لږ تړلي ادارې او په پایله کې کوچنۍ ټولنې په کچه کې لږ بدلونونه تجربه کوي. د بیلګې په توګه، دلته د ټولنې جوړښت یوازې په لومړیو دوو کچو کې بدلون راولي مګر د وروستیو دریو کچو لپاره یو شان پاتې کیږي. په پایله کې، د ترتیب کچه اکثرا د دې ادارو لپاره بې ځایه ښکاري، ځکه چې ټولیز سازمان په مختلفو درجو کې د پام وړ بدلون نه کوي.
راځئ چې د ټولنو شمیر او د دوی اندازې او مختلفې کچې په ډیر تفصیل سره وڅیړو:
community_size = graph.query( """ MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(e:__Entity__) WITH c, count(distinct e) AS entities RETURN split(c.id, '-')[0] AS level, entities """ ) community_size_df = pd.DataFrame.from_records(community_size) percentiles_data = [] for level in community_size_df["level"].unique(): subset = community_size_df[community_size_df["level"] == level]["entities"] num_communities = len(subset) percentiles = np.percentile(subset, [25, 50, 75, 90, 99]) percentiles_data.append( [ level, num_communities, percentiles[0], percentiles[1], percentiles[2], percentiles[3], percentiles[4], max(subset) ] ) # Create a DataFrame with the percentiles percentiles_df = pd.DataFrame( percentiles_data, columns=[ "Level", "Number of communities", "25th Percentile", "50th Percentile", "75th Percentile", "90th Percentile", "99th Percentile", "Max" ], ) percentiles_df


په اصلي تطبیق کې، په هره کچه ټولنې لنډیز شوي. زموږ په قضیه کې، دا به 8,590 ټولنې وي او په پایله کې، 8,590 LLM زنګونه. زه به استدلال وکړم چې د ټولنې د تنظیمي جوړښت پورې اړه لري، د هرې کچې لنډیز ته اړتیا نلري. د مثال په توګه، د وروستي او راتلونکي څخه تر وروستي کچې توپیر یوازې څلور ټولنې دی (1,192 vs. 1,188). له همدې امله ، موږ به ډیری بې ځایه لنډیزونه رامینځته کړو. یو حل دا دی چې یو داسې تطبیق رامینځته کړي چې کولی شي په مختلفو کچو کې د ټولنو لپاره یو واحد لنډیز رامینځته کړي چې بدلون نه کوي؛ بل به دا وي چې د ټولنې درجه بندي له مینځه یوسي چې بدلون نه کوي.
همچنان، زه ډاډه نه یم که موږ غواړو یوازې د یو غړي سره ټولنې لنډیز کړو، ځکه چې دوی ممکن ډیر ارزښت یا معلومات چمتو نکړي. دلته، موږ به ټولنې په 0، 1، او 4 کچه لنډیز کړو. لومړی، موږ اړتیا لرو چې د دوی معلومات له ډیټابیس څخه ترلاسه کړو:
community_info = graph.query(""" MATCH (c:`__Community__`)<-[:IN_COMMUNITY*]-(e:__Entity__) WHERE c.level IN [0,1,4] WITH c, collect(e ) AS nodes WHERE size(nodes) > 1 CALL apoc.path.subgraphAll(nodes[0], { whitelistNodes:nodes }) YIELD relationships RETURN c.id AS communityId, [n in nodes | {id: n.id, description: n.description, type: [el in labels(n) WHERE el <> '__Entity__'][0]}] AS nodes, [r in relationships | {start: startNode(r).id, type: type(r), end: endNode(r).id, description: r.description}] AS rels """)
اوس مهال، د ټولنې معلومات لاندې جوړښت لري:
{'communityId': '0-6014', 'nodes': [{'id': 'Darrell Hughes', 'description': None, type:"Person"}, {'id': 'Chief Pilot', 'description': None, type: "Person"}, ... }], 'rels': [{'start': 'Ryanair Dac', 'description': 'Informed of the change in chief pilot', 'type': 'INFORMED', 'end': 'Irish Aviation Authority'}, {'start': 'Ryanair Dac', 'description': 'Dismissed after internal investigation found unacceptable behaviour', 'type': 'DISMISSED', 'end': 'Aidan Murray'}, ... ]}
اوس، موږ اړتیا لرو چې د LLM پرامپټ چمتو کړو چې زموږ د ټولنې د عناصرو لخوا چمتو شوي معلوماتو پراساس د طبیعي ژبې لنډیز رامینځته کوي. موږ کولی شو له هغه ګړندی څخه یو څه الهام واخلو چې څیړونکو کارولی .
لیکوالانو نه یوازې ټولنې لنډیز کړي بلکې د هرې یوې لپاره موندنې هم رامینځته کړي. یوه موندنه د یوې ځانګړې پیښې یا د معلوماتو برخې په اړه د لنډ معلومات په توګه تعریف کیدی شي. داسې یوه بیلګه:
"summary": "Abila City Park as the central location", "explanation": "Abila City Park is the central entity in this community, serving as the location for the POK rally. This park is the common link between all other entities, suggesting its significance in the community. The park's association with the rally could potentially lead to issues such as public disorder or conflict, depending on the nature of the rally and the reactions it provokes. [records: Entities (5), Relationships (37, 38, 39, 40)]"
زما هوښیارتیا وړاندیز کوي چې یوازې د یو واحد پاس سره د موندنو استخراج ممکن دومره جامع نه وي لکه څنګه چې موږ ورته اړتیا لرو، لکه د ادارو او اړیکو استخراج.
برسېره پردې، ما د دوی په کوډ کې د محلي یا نړیوال لټون بیرته اخیستونکو کې د دوی د کارولو هیڅ حواله یا مثال ندی موندلی. د پایلې په توګه، موږ به په دې مثال کې د موندنو د استخراج څخه ډډه وکړو. یا، لکه څنګه چې اکادمیکان اکثرا دا بیانوي: دا تمرین لوستونکي ته پریښودل کیږي. سربیره پردې، موږ ادعاګانې یا د معلوماتو استخراج هم پریږدو، کوم چې په لومړي نظر کې موندنو ته ورته ښکاري.
هغه ګړندی چې موږ به یې د ټولنې لنډیز تولیدولو لپاره وکاروو خورا مستقیم دی:
community_template = """Based on the provided nodes and relationships that belong to the same graph community, generate a natural language summary of the provided information: {community_info} Summary:""" # noqa: E501 community_prompt = ChatPromptTemplate.from_messages( [ ( "system", "Given an input triples, generate the information summary. No pre-amble.", ), ("human", community_template), ] ) community_chain = community_prompt | llm | StrOutputParser()
یوازینی شی پاتې دی چې د ټولنې نمایندګۍ په تارونو بدل کړئ ترڅو د JSON ټوکن سر څخه مخنیوی کولو سره د ټوکنونو شمیر کم کړئ او زنځیر د فنکشن په توګه وپلټئ:
def prepare_string(data): nodes_str = "Nodes are:\n" for node in data['nodes']: node_id = node['id'] node_type = node['type'] if 'description' in node and node['description']: node_description = f", description: {node['description']}" else: node_description = "" nodes_str += f"id: {node_id}, type: {node_type}{node_description}\n" rels_str = "Relationships are:\n" for rel in data['rels']: start = rel['start'] end = rel['end'] rel_type = rel['type'] if 'description' in rel and rel['description']: description = f", description: {rel['description']}" else: description = "" rels_str += f"({start})-[:{rel_type}]->({end}){description}\n" return nodes_str + "\n" + rels_str def process_community(community): stringify_info = prepare_string(community) summary = community_chain.invoke({'community_info': stringify_info}) return {"community": community['communityId'], "summary": summary}
اوس موږ کولی شو د ټاکل شوي کچو لپاره د ټولنې لنډیز رامینځته کړو. یوځل بیا ، موږ د ګړندي اجرا کولو غوښتنې موازي کوو:
summaries = [] with ThreadPoolExecutor() as executor: futures = {executor.submit(process_community, community): community for community in community_info} for future in tqdm(as_completed(futures), total=len(futures), desc="Processing communities"): summaries.append(future.result())
یو اړخ چې ما یې یادونه نه ده کړې هغه دا ده چې لیکوالان د ټولنې معلوماتو داخلولو په وخت کې د شرایطو اندازې څخه ډیر احتمالي مسله هم په ګوته کوي. لکه څنګه چې ګراف پراخیږي، ټولنې هم د پام وړ وده کولی شي. زموږ په قضیه کې، ترټولو لویه ټولنه 545 غړي لري. دې ته په پام سره چې GPT-4o د شرایطو اندازه له 100,000 ټوکنونو څخه زیاته ده، موږ پریکړه وکړه چې دا مرحله پریږدو.
زموږ د وروستي ګام په توګه، موږ به د ټولنې لنډیز بیرته ډیټابیس ته ذخیره کړو:
graph.query(""" UNWIND $data AS row MERGE (c:__Community__ {id:row.community}) SET c.summary = row.summary """, params={"data": summaries})
د وروستي ګراف جوړښت:


په ګراف کې اوس اصلي اسناد، استخراج شوي بنسټونه او اړیکې، او همدارنګه د ټولنې درجه بندي جوړښت او لنډیز شامل دي.
لنډیز
د "سیمه ایز څخه نړیوال ته" مقالې لیکوالانو ګرافراګ ته د نوي چلند په ښودلو کې عالي دنده ترسره کړې. دوی ښیي چې موږ څنګه کولی شو د مختلفو اسنادو څخه معلومات د درجه بندي پوهې ګراف جوړښت کې یوځای او لنډیز کړو.
یو شی چې په واضح ډول نه دی ذکر شوی دا دی چې موږ کولی شو د جوړښت شوي ډیټا سرچینې هم په ګراف کې مدغم کړو؛ ان پټ باید یوازې په غیر منظم متن پورې محدود نه وي.
هغه څه چې زه په ځانګړې توګه د دوی د استخراج طریقې په اړه ستاینه کوم دا دی چې دوی د نوډونو او اړیکو دواړو لپاره توضیحات نیسي. توضیحات LLM ته اجازه ورکوي چې یوازې د نوډ IDs او اړیکو ډولونو ته د هرڅه کمولو په پرتله نور معلومات وساتي.
برسیره پردې، دوی ښیي چې د متن په اړه یو واحد استخراج ممکن ټول اړونده معلومات ونه نیسي او د اړتیا په صورت کې د ډیری پاسونو ترسره کولو لپاره منطق معرفي کړي. لیکوالان د ګراف ټولنو په اړه د لنډیزونو د ترسره کولو لپاره په زړه پورې نظر هم وړاندې کوي، موږ ته اجازه راکوي چې د ډیری ډیټا سرچینو په اوږدو کې کنډنډ شوي موضوعي معلومات سرایت او شاخص کړو.
په راتلونکی بلاګ پوسټ کې، موږ به د محلي او نړیوال لټون د بیاکتنې پلي کولو ته لاړ شو او د نورو طریقو په اړه وغږیږو چې موږ کولی شو د ورکړل شوي ګراف جوړښت پراساس پلي کړو.
د تل په څیر، کوډ په GitHub کې شتون لري.
دا ځل، ما د ډیټابیس ډمپ هم اپلوډ کړی دی نو تاسو کولی شئ پایلې وپلټئ او د بیا رغونې مختلف انتخابونو سره تجربه کړئ.
تاسو کولی شئ دا ډمپ د تل لپاره وړیا Neo4j AuraDB مثال کې هم وارد کړئ، کوم چې موږ کولی شو د استخراج سپړنې لپاره وکاروو ځکه چې موږ د دې لپاره د ګراف ډیټا ساینس الګوریتم ته اړتیا نلرو - یوازې د ګراف نمونې میچ کول، ویکتور، او بشپړ متن شاخصونه.
زما په کتاب "د ډیټا ساینس لپاره ګراف الګوریتم" کې د ټولو GenAI چوکاټونو او عملي ګراف الګوریتمونو سره د Neo4j ادغام په اړه نور معلومات زده کړئ.
د دې موضوع په اړه د لا زیاتو معلوماتو لپاره، موږ سره د نومبر په 7 کې په NODES 2024 کې ګډون وکړئ، زموږ وړیا مجازی پراختیا کونکي کنفرانس د هوښیار ایپسونو، پوهې ګرافونو، او AI په اړه. اوس راجستر کړئ !








