
























ฉันรู้สึกสนใจแนวทางใหม่ๆ ในการใช้ Retrieval-Augmented Generation (RAG) แทนกราฟ ซึ่งมักเรียกว่า GraphRAG อยู่เสมอ อย่างไรก็ตาม ดูเหมือนว่าทุกคนจะมีแนวคิดการใช้งานที่แตกต่างกันเมื่อได้ยินคำว่า GraphRAG ในโพสต์บล็อกนี้ เราจะเจาะลึกบทความเรื่อง “ From Local to Global GraphRAG ” และการใช้งานโดยนักวิจัยของ Microsoft เราจะกล่าวถึงการสร้างกราฟความรู้และการสรุปข้อมูล และจะปล่อยให้ตัวเรียกข้อมูลอยู่ในโพสต์บล็อกถัดไป นักวิจัยใจดีที่ให้ที่เก็บโค้ดแก่เรา และพวกเขายังมี หน้าโครงการ ด้วย
แนวทางที่ใช้ในบทความที่กล่าวถึงข้างต้นนั้นค่อนข้างน่าสนใจ เท่าที่ฉันเข้าใจ แนวทางนี้เกี่ยวข้องกับการใช้กราฟความรู้เป็นขั้นตอนในกระบวนการรวบรวมและรวมข้อมูลจากหลายแหล่ง การแยกเอนทิตีและความสัมพันธ์ออกจากข้อความนั้นไม่ใช่เรื่องใหม่ อย่างไรก็ตาม ผู้เขียนได้นำเสนอแนวคิดใหม่ (อย่างน้อยก็สำหรับฉัน) ในการสรุปโครงสร้างกราฟและข้อมูลแบบย่อกลับเป็นข้อความภาษาธรรมชาติ กระบวนการเริ่มต้นด้วยข้อความอินพุตจากเอกสาร ซึ่งจะถูกประมวลผลเพื่อสร้างกราฟ จากนั้นกราฟจะถูกแปลงกลับเป็นข้อความภาษาธรรมชาติ โดยข้อความที่สร้างขึ้นจะมีข้อมูลแบบย่อเกี่ยวกับเอนทิตีเฉพาะหรือชุมชนกราฟที่กระจายอยู่ในเอกสารหลายฉบับก่อนหน้านี้


ในระดับสูงมาก อินพุตของไปป์ไลน์ GraphRAG คือเอกสารต้นทางที่มีข้อมูลต่างๆ เอกสารจะได้รับการประมวลผลโดยใช้ LLM เพื่อแยกข้อมูลที่มีโครงสร้างเกี่ยวกับเอนทิตีที่ปรากฏในเอกสารพร้อมกับความสัมพันธ์ของเอนทิตีเหล่านั้น จากนั้นข้อมูลที่มีโครงสร้างที่แยกออกมาจะถูกใช้เพื่อสร้างกราฟความรู้
ข้อดีของการใช้การแสดงข้อมูลกราฟความรู้คือสามารถรวมข้อมูลจากเอกสารหรือแหล่งข้อมูลต่างๆ เกี่ยวกับเอนทิตีเฉพาะต่างๆ ได้อย่างรวดเร็วและตรงไปตรงมา อย่างไรก็ตาม ดังที่ได้กล่าวไปแล้ว กราฟความรู้ไม่ใช่การแสดงข้อมูลเพียงอย่างเดียว หลังจากสร้างกราฟความรู้แล้ว พวกเขาจะใช้ชุดอัลกอริทึมกราฟและคำแนะนำ LLM เพื่อสร้างสรุปข้อมูลชุมชนเอนทิตีที่พบในกราฟความรู้ในภาษาธรรมชาติ
บทสรุปเหล่านี้ประกอบด้วยข้อมูลสรุปที่กระจายอยู่ในแหล่งข้อมูลและเอกสารต่างๆ มากมายสำหรับหน่วยงานและชุมชนต่างๆ
หากต้องการความเข้าใจโดยละเอียดมากขึ้นเกี่ยวกับระบบท่อ เราสามารถดูคำอธิบายทีละขั้นตอนที่ให้ไว้ในเอกสารต้นฉบับได้


ขั้นตอนในการดำเนินการ — รูปภาพจาก เอกสาร GraphRAG ได้รับอนุญาตภายใต้ CC BY 4.0
ต่อไปนี้เป็นสรุประดับสูงของไปป์ไลน์ที่เราจะใช้เพื่อสร้างแนวทางของพวกเขาโดยใช้ Neo4j และ LangChain
การสร้างดัชนี — การสร้างกราฟ
- จากเอกสารต้นฉบับเป็นส่วนข้อความ : เอกสารต้นฉบับจะถูกแบ่งออกเป็นส่วนข้อความย่อยๆ เพื่อการประมวลผล
- ชิ้นส่วนข้อความไปยังอินสแตนซ์องค์ประกอบ : ชิ้นส่วนข้อความแต่ละชิ้นจะได้รับการวิเคราะห์เพื่อแยกเอนทิตีและความสัมพันธ์ และสร้างรายการทูเพิลที่แสดงถึงองค์ประกอบเหล่านี้
- จากอินสแตนซ์องค์ประกอบสู่สรุปองค์ประกอบ : เอนทิตีและความสัมพันธ์ที่แยกออกมาจะถูกสรุปโดย LLM เป็นบล็อกข้อความบรรยายสำหรับแต่ละองค์ประกอบ
- สรุปองค์ประกอบเพื่อสร้างกราฟชุมชน : สรุปเอนทิตีเหล่านี้จะสร้างกราฟ จากนั้นจึงแบ่งออกเป็นชุมชนโดยใช้อัลกอริทึมเช่น Leiden สำหรับโครงสร้างลำดับชั้น
- กราฟชุมชนสู่ผลสรุปของชุมชน : ผลสรุปของแต่ละชุมชนจะถูกสร้างขึ้นด้วย LLM เพื่อทำความเข้าใจโครงสร้างและความหมายตามหัวข้อทั่วโลกของชุดข้อมูล
การค้นคืน — การตอบคำถาม
- สรุปชุมชนสู่คำตอบระดับโลก : สรุปชุมชนใช้เพื่อตอบคำถามของผู้ใช้โดยสร้างคำตอบกลาง จากนั้นจึงรวบรวมเป็นคำตอบระดับโลกขั้นสุดท้าย
โปรดทราบว่าการใช้งานของฉันเสร็จสิ้นก่อนที่โค้ดของพวกเขาจะพร้อมใช้งาน ดังนั้นอาจมีความแตกต่างเล็กน้อยในแนวทางพื้นฐานหรือข้อความแจ้ง LLM ที่ใช้ ฉันจะพยายามอธิบายความแตกต่างเหล่านี้เมื่อเราดำเนินการไป
โค้ดนี้มีอยู่บน GitHub
การตั้งค่าสภาพแวดล้อม Neo4j
เราจะใช้ Neo4j เป็นที่เก็บกราฟพื้นฐาน วิธีที่ง่ายที่สุดในการเริ่มต้นคือใช้อินสแตนซ์ Neo4j Sandbox ฟรี ซึ่งมีอินสแตนซ์คลาวด์ของฐานข้อมูล Neo4j พร้อมปลั๊กอิน Graph Data Science ที่ติดตั้งไว้ หรือคุณสามารถตั้งค่าอินสแตนซ์ภายในเครื่องของฐานข้อมูล Neo4j ได้โดยดาวน์โหลดแอปพลิเคชัน Neo4j Desktop และสร้างอินสแตนซ์ฐานข้อมูลภายในเครื่อง หากคุณใช้เวอร์ชันภายในเครื่อง โปรดติดตั้งปลั๊กอิน APOC และ GDS สำหรับการตั้งค่าการผลิต คุณสามารถใช้อินสแตนซ์ AuraDS (Data Science) ที่ได้รับการจัดการแบบชำระเงิน ซึ่งให้ปลั๊กอิน GDS
เราเริ่มต้นด้วยการสร้างอินสแตนซ์ Neo4jGraph ซึ่งเป็นตัวห่อหุ้มความสะดวกที่เราเพิ่มให้กับ LangChain:
from langchain_community.graphs import Neo4jGraph os.environ["NEO4J_URI"] = "bolt://44.202.208.177:7687" os.environ["NEO4J_USERNAME"] = "neo4j" os.environ["NEO4J_PASSWORD"] = "mast-codes-trails" graph = Neo4jGraph(refresh_schema=False)ชุดข้อมูล
เราจะใช้ชุดข้อมูลบทความข่าวที่ฉันสร้างไว้เมื่อนานมาแล้วโดยใช้ API ของ Diffbot ฉันได้อัปโหลดไปยัง GitHub ของฉันแล้วเพื่อให้ใช้งานซ้ำได้ง่ายขึ้น:
news = pd.read_csv( "https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/news_articles.csv" ) news["tokens"] = [ num_tokens_from_string(f"{row['title']} {row['text']}") for i, row in news.iterrows() ] news.head()
มาตรวจสอบสองแถวแรกจากชุดข้อมูลกัน


เรามีชื่อและข้อความของบทความพร้อมวันที่เผยแพร่และจำนวนโทเค็นโดยใช้ไลบรารี TikTok
การแบ่งข้อความเป็นกลุ่ม
ขั้นตอนการแบ่งข้อความเป็นส่วนๆ มีความสำคัญและส่งผลอย่างมากต่อผลลัพธ์ที่เกิดขึ้นในภายหลัง ผู้เขียนเอกสารพบว่าการใช้ข้อความที่มีขนาดเล็กลงส่งผลให้สามารถแยกเอนทิตีโดยรวมได้มากขึ้น


จำนวนของหน่วยสารสกัดที่กำหนดขนาดของชิ้นส่วนข้อความ — รูปภาพจาก เอกสาร GraphRAG ได้รับอนุญาตภายใต้ CC BY 4.0
อย่างที่คุณเห็น การใช้ชิ้นส่วนข้อความที่มีโทเค็น 2,400 ชิ้นส่งผลให้มีการสกัดเอนทิตีออกมาได้น้อยกว่าเมื่อใช้โทเค็น 600 ชิ้น นอกจากนี้ พวกเขายังระบุด้วยว่า LLM อาจไม่สามารถสกัดเอนทิตีทั้งหมดได้ในการรันครั้งแรก ในกรณีนั้น พวกเขาจึงแนะนำฮิวริสติกส์เพื่อดำเนินการสกัดหลายครั้ง เราจะพูดถึงเรื่องนี้เพิ่มเติมในหัวข้อถัดไป
อย่างไรก็ตาม มักมีการแลกเปลี่ยนกันเสมอ การใช้ข้อความขนาดเล็กอาจส่งผลให้สูญเสียบริบทและการอ้างอิงร่วมของเอนทิตีเฉพาะที่กระจายอยู่ในเอกสาร ตัวอย่างเช่น หากเอกสารกล่าวถึง “จอห์น” และ “เขา” ในประโยคแยกกัน การแบ่งข้อความออกเป็นส่วนย่อยอาจทำให้ไม่ชัดเจนว่า “เขา” หมายถึงจอห์น ปัญหาการอ้างอิงร่วมบางส่วนสามารถแก้ไขได้โดยใช้กลยุทธ์การแบ่งข้อความทับซ้อนกัน แต่ไม่ใช่ทั้งหมด
มาตรวจสอบขนาดข้อความบทความของเรากัน:
sns.histplot(news["tokens"], kde=False) plt.title('Distribution of chunk sizes') plt.xlabel('Token count') plt.ylabel('Frequency') plt.show()


การกระจายของจำนวนโทเค็นบทความนั้นอยู่ในระดับปกติโดยประมาณ โดยมีจุดสูงสุดอยู่ที่ประมาณ 400 โทเค็น ความถี่ของชิ้นส่วนต่างๆ จะค่อยๆ เพิ่มขึ้นจนถึงจุดสูงสุดนี้ จากนั้นจะลดลงอย่างสมมาตร ซึ่งบ่งชี้ว่าชิ้นส่วนข้อความส่วนใหญ่จะอยู่ใกล้เครื่องหมาย 400 โทเค็น
เนื่องจากการกระจายนี้ เราจะไม่ทำการแบ่งข้อความเป็นกลุ่มๆ ที่นี่เพื่อหลีกเลี่ยงปัญหาการอ้างอิงร่วม โดยค่าเริ่มต้น โปรเจ็กต์ GraphRAG จะใช้ ขนาดกลุ่ม ที่ 300 โทเค็นและ 100 โทเค็นที่ทับซ้อนกัน
การแยกโหนดและความสัมพันธ์
ขั้นตอนต่อไปคือการสร้างความรู้จากข้อความ สำหรับกรณีการใช้งานนี้ เราใช้ LLM เพื่อแยกข้อมูลที่มีโครงสร้างในรูปแบบของโหนดและความสัมพันธ์จากข้อความ คุณสามารถตรวจสอบ คำเตือน LLM ที่ผู้เขียนใช้ในเอกสารได้ คำเตือนเหล่านี้มีคำเตือน LLM ที่เราสามารถกำหนดป้ายชื่อโหนดไว้ล่วงหน้าได้หากจำเป็น แต่โดยค่าเริ่มต้นนั้นเป็นทางเลือก นอกจากนี้ ความสัมพันธ์ที่แยกออกมาในเอกสารต้นฉบับไม่มีประเภทจริงๆ แต่มีเฉพาะคำอธิบายเท่านั้น ฉันนึกภาพว่าเหตุผลเบื้องหลังการเลือกนี้คือเพื่อให้ LLM สามารถแยกและเก็บรักษาข้อมูลที่สมบูรณ์และละเอียดอ่อนยิ่งขึ้นเป็นความสัมพันธ์ได้ แต่การมีกราฟความรู้ที่สะอาดโดยไม่มีข้อกำหนดประเภทความสัมพันธ์นั้นเป็นเรื่องยาก (คำอธิบายอาจใส่ไว้ในคุณสมบัติ)
ในการใช้งานของเรา เราจะใช้ LLMGraphTransformer ซึ่งมีอยู่ในไลบรารี LangChain แทนที่จะใช้วิศวกรรมคำสั่งแบบเพียวๆ เหมือนกับการใช้งานในเอกสารบทความ LLMGraphTransformer จะใช้ฟังก์ชันในตัวที่เรียกใช้งานเพื่อดึงข้อมูลที่มีโครงสร้าง (เอาต์พุตที่มีโครงสร้าง LLM ใน LangChain) คุณสามารถตรวจสอบ คำสั่งของระบบ ได้:
from langchain_experimental.graph_transformers import LLMGraphTransformer from langchain_openai import ChatOpenAI llm = ChatOpenAI(temperature=0, model_name="gpt-4o") llm_transformer = LLMGraphTransformer( llm=llm, node_properties=["description"], relationship_properties=["description"] ) def process_text(text: str) -> List[GraphDocument]: doc = Document(page_content=text) return llm_transformer.convert_to_graph_documents([doc])
ในตัวอย่างนี้ เราใช้ GPT-4o สำหรับการดึงกราฟ ผู้เขียนได้สั่งสอน LLM โดยเฉพาะให้ ดึงเอนทิตีและความสัมพันธ์พร้อมคำอธิบายของเอนทิตีและความสัมพันธ์เหล่านั้น ด้วยการใช้งาน LangChain คุณสามารถใช้แอตทริบิวต์ node_properties และ relationship_properties เพื่อระบุคุณสมบัติของโหนดหรือความสัมพันธ์ที่คุณต้องการให้ LLM ดึงออกมา
ความแตกต่างกับการใช้งาน LLMGraphTransformer คือคุณสมบัติโหนดหรือความสัมพันธ์ทั้งหมดเป็นทางเลือก ดังนั้นโหนดบางโหนดจึงไม่มีคุณลักษณะ description หากต้องการ เราสามารถกำหนดการสกัดแบบกำหนดเองเพื่อให้มีคุณสมบัติ description ที่จำเป็นได้ แต่เราจะข้ามคุณสมบัตินั้นในการใช้งานนี้
เราจะทำการประมวลผลคำขอแบบขนานเพื่อทำให้การแยกกราฟเร็วขึ้นและจัดเก็บผลลัพธ์ไปยัง Neo4j:
MAX_WORKERS = 10 NUM_ARTICLES = 2000 graph_documents = [] with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # Submitting all tasks and creating a list of future objects futures = [ executor.submit(process_text, f"{row['title']} {row['text']}") for i, row in news.head(NUM_ARTICLES).iterrows() ] for future in tqdm( as_completed(futures), total=len(futures), desc="Processing documents" ): graph_document = future.result() graph_documents.extend(graph_document) graph.add_graph_documents( graph_documents, baseEntityLabel=True, include_source=True )
ในตัวอย่างนี้ เราดึงข้อมูลกราฟจากบทความ 2,000 บทความและจัดเก็บผลลัพธ์ไว้ใน Neo4j เราได้ดึงข้อมูลเอนทิตีประมาณ 13,000 รายการและความสัมพันธ์ 16,000 รายการ นี่คือตัวอย่างของเอกสารที่ดึงออกมาในกราฟ


การสกัดออกให้เสร็จสิ้นใช้เวลาประมาณ 35 (+/- 5) นาที และมีค่าใช้จ่ายประมาณ 30 เหรียญสหรัฐฯ สำหรับการใช้ GPT-4o
ในขั้นตอนนี้ ผู้เขียนได้แนะนำฮิวริสติกส์เพื่อตัดสินใจว่าจะดึงข้อมูลกราฟออกมามากกว่าหนึ่งครั้งหรือไม่ เพื่อความเรียบง่าย เราจะทำเพียงครั้งเดียว อย่างไรก็ตาม หากเราต้องการทำหลายครั้ง เราสามารถใส่ผลลัพธ์การดึงข้อมูลครั้งแรกเป็นประวัติการสนทนา และเพียงแค่สั่งให้ LLM ทราบว่ามีเอนทิตีหลายรายการหายไป จากนั้น LLM ควรดึงข้อมูลออกมาเพิ่มเติม เช่นเดียวกับที่ผู้เขียน GraphRAG ทำ
ก่อนหน้านี้ ฉันได้กล่าวถึงความสำคัญของขนาดชิ้นส่วนข้อความและผลกระทบต่อจำนวนเอนทิตีที่แยกออกมา เนื่องจากเราไม่ได้แบ่งข้อความเพิ่มเติม เราจึงสามารถประเมินการกระจายของเอนทิตีที่แยกออกมาตามขนาดชิ้นส่วนข้อความได้:
entity_dist = graph.query( """ MATCH (d:Document) RETURN d.text AS text, count {(d)-[:MENTIONS]->()} AS entity_count """ ) entity_dist_df = pd.DataFrame.from_records(entity_dist) entity_dist_df["token_count"] = [ num_tokens_from_string(str(el)) for el in entity_dist_df["text"] ] # Scatter plot with regression line sns.lmplot( x="token_count", y="entity_count", data=entity_dist_df, line_kws={"color": "red"} ) plt.title("Entity Count vs Token Count Distribution") plt.xlabel("Token Count") plt.ylabel("Entity Count") plt.show()


กราฟแบบกระจายแสดงให้เห็นว่าแม้ว่าจะมีแนวโน้มเชิงบวก ซึ่งระบุด้วยเส้นสีแดง แต่ความสัมพันธ์นั้นเป็นแบบย่อยเชิงเส้น จุดข้อมูลส่วนใหญ่จะกระจุกตัวกันที่จำนวนเอนทิตีที่น้อยลง แม้ว่าจำนวนโทเค็นจะเพิ่มขึ้นก็ตาม ซึ่งบ่งชี้ว่าจำนวนเอนทิตีที่แยกออกมาไม่ได้ปรับขนาดตามสัดส่วนของขนาดของกลุ่มข้อความ แม้ว่าจะมีค่าผิดปกติอยู่บ้าง แต่รูปแบบทั่วไปแสดงให้เห็นว่าจำนวนโทเค็นที่มากขึ้นไม่ได้ส่งผลให้จำนวนเอนทิตีที่มากขึ้นเสมอไป ซึ่งยืนยันการค้นพบของผู้เขียนที่ว่าขนาดกลุ่มข้อความที่ต่ำกว่าจะดึงข้อมูลออกมาได้มากขึ้น
ฉันคิดว่าการตรวจสอบการกระจายระดับโหนดของกราฟที่สร้างขึ้นก็น่าสนใจเช่นกัน โค้ดต่อไปนี้จะดึงข้อมูลและแสดงภาพการกระจายระดับโหนด:
degree_dist = graph.query( """ MATCH (e:__Entity__) RETURN count {(e)-[:!MENTIONS]-()} AS node_degree """ ) degree_dist_df = pd.DataFrame.from_records(degree_dist) # Calculate mean and median mean_degree = np.mean(degree_dist_df['node_degree']) percentiles = np.percentile(degree_dist_df['node_degree'], [25, 50, 75, 90]) # Create a histogram with a logarithmic scale plt.figure(figsize=(12, 6)) sns.histplot(degree_dist_df['node_degree'], bins=50, kde=False, color='blue') # Use a logarithmic scale for the x-axis plt.yscale('log') # Adding labels and title plt.xlabel('Node Degree') plt.ylabel('Count (log scale)') plt.title('Node Degree Distribution') # Add mean, median, and percentile lines plt.axvline(mean_degree, color='red', linestyle='dashed', linewidth=1, label=f'Mean: {mean_degree:.2f}') plt.axvline(percentiles[0], color='purple', linestyle='dashed', linewidth=1, label=f'25th Percentile: {percentiles[0]:.2f}') plt.axvline(percentiles[1], color='orange', linestyle='dashed', linewidth=1, label=f'50th Percentile: {percentiles[1]:.2f}') plt.axvline(percentiles[2], color='yellow', linestyle='dashed', linewidth=1, label=f'75th Percentile: {percentiles[2]:.2f}') plt.axvline(percentiles[3], color='brown', linestyle='dashed', linewidth=1, label=f'90th Percentile: {percentiles[3]:.2f}') # Add legend plt.legend() # Show the plot plt.show()


การกระจายระดับโหนดนั้นปฏิบัติตามรูปแบบกฎกำลัง ซึ่งบ่งชี้ว่าโหนดส่วนใหญ่มีการเชื่อมต่อน้อยมากในขณะที่โหนดบางโหนดมีการเชื่อมต่อสูง ระดับเฉลี่ยอยู่ที่ 2.45 และค่ามัธยฐานอยู่ที่ 1.00 ซึ่งแสดงให้เห็นว่าโหนดมากกว่าครึ่งหนึ่งมีการเชื่อมต่อเพียงครั้งเดียว โหนดส่วนใหญ่ (75 เปอร์เซ็นต์) มีการเชื่อมต่อสองครั้งหรือน้อยกว่า และ 90 เปอร์เซ็นต์มีห้าครั้งหรือน้อยกว่า การกระจายนี้เป็นเรื่องปกติสำหรับเครือข่ายในโลกแห่งความเป็นจริงจำนวนมาก ซึ่งฮับจำนวนน้อยมีการเชื่อมต่อหลายครั้ง และโหนดส่วนใหญ่มีเพียงไม่กี่แห่ง
เนื่องจากคำอธิบายทั้งโหนดและความสัมพันธ์ไม่ใช่คุณสมบัติที่จำเป็น เราจึงจะตรวจสอบด้วยว่ามีการแยกออกมาจำนวนเท่าใด:
graph.query(""" MATCH (n:`__Entity__`) RETURN "node" AS type, count(*) AS total_count, count(n.description) AS non_null_descriptions UNION ALL MATCH (n)-[r:!MENTIONS]->() RETURN "relationship" AS type, count(*) AS total_count, count(r.description) AS non_null_descriptions """)
ผลลัพธ์แสดงให้เห็นว่าโหนด 5,926 โหนดจากทั้งหมด 12,994 โหนด (45.6 เปอร์เซ็นต์) มีคุณสมบัติคำอธิบาย ในทางกลับกัน มีเพียงความสัมพันธ์ 5,569 โหนดจากทั้งหมด 15,921 โหนด (35 เปอร์เซ็นต์) เท่านั้นที่มีคุณสมบัติดังกล่าว
โปรดทราบว่าเนื่องจากธรรมชาติของ LLM เป็นไปตามความน่าจะเป็น ตัวเลขจึงอาจแตกต่างกันไปในแต่ละการทำงานและข้อมูลต้นทาง LLM และข้อความเตือนที่แตกต่างกัน
การแก้ไขปัญหาองค์กร
การแก้ไขเอนทิตี (การลบข้อมูลซ้ำซ้อน) เป็นสิ่งสำคัญเมื่อสร้างกราฟความรู้ เนื่องจากจะช่วยให้แน่ใจว่าเอนทิตีแต่ละอันจะแสดงอย่างเฉพาะเจาะจงและถูกต้อง ซึ่งจะช่วยป้องกันไม่ให้เกิดข้อมูลซ้ำซ้อนและการรวมระเบียนที่อ้างอิงถึงเอนทิตีในโลกแห่งความเป็นจริงอันเดียวกัน กระบวนการนี้มีความจำเป็นสำหรับการรักษาความสมบูรณ์และความสอดคล้องของข้อมูลภายในกราฟ หากไม่มีการแก้ไขเอนทิตี กราฟความรู้จะประสบปัญหาจากข้อมูลที่กระจัดกระจายและไม่สอดคล้องกัน ซึ่งนำไปสู่ข้อผิดพลาดและข้อมูลเชิงลึกที่ไม่น่าเชื่อถือ


ภาพนี้แสดงให้เห็นว่าเอนทิตีในโลกแห่งความเป็นจริงหนึ่งรายการอาจปรากฏภายใต้ชื่อที่ต่างกันเล็กน้อยในเอกสารต่างๆ และในกราฟของเราด้วย
ยิ่งไปกว่านั้น ข้อมูลที่เบาบางจะกลายเป็นปัญหาสำคัญหากไม่มีการแก้ไขเอนทิตี ข้อมูลที่ไม่สมบูรณ์หรือบางส่วนจากแหล่งต่างๆ อาจทำให้ข้อมูลกระจัดกระจายและไม่ต่อเนื่องกัน ทำให้ยากต่อการทำความเข้าใจเอนทิตีอย่างสอดคล้องและครอบคลุม การแก้ไขเอนทิตีอย่างแม่นยำจะช่วยแก้ปัญหานี้ได้โดยการรวมข้อมูล เติมช่องว่าง และสร้างมุมมองแบบรวมของแต่ละเอนทิตี


ก่อน/หลังการใช้โซลูชัน Senzing เพื่อเชื่อมโยงข้อมูลรั่วไหลนอกประเทศ ของสมาคมนักข่าวสืบสวนสอบสวนนานาชาติ (ICIJ) — รูปภาพโดย Paco Nathan
ส่วนด้านซ้ายของการแสดงภาพแสดงกราฟที่เบาบางและไม่เชื่อมโยงกัน อย่างไรก็ตาม ตามที่แสดงทางด้านขวา กราฟดังกล่าวสามารถเชื่อมโยงกันได้ดีโดยมีความละเอียดของเอนทิตีที่มีประสิทธิภาพ
โดยรวมแล้ว การแก้ไขเอนทิตี้จะช่วยเพิ่มประสิทธิภาพในการดึงข้อมูลและบูรณาการข้อมูล ทำให้สามารถดูข้อมูลในแหล่งต่างๆ ได้อย่างสอดคล้องกัน และสุดท้ายแล้วจะช่วยให้สามารถตั้งคำถามและตอบคำถามได้อย่างมีประสิทธิภาพมากขึ้นโดยอิงจากกราฟความรู้ที่เชื่อถือได้และสมบูรณ์
น่าเสียดายที่ผู้เขียนเอกสาร GraphRAG ไม่ได้รวมโค้ดการแก้ไขเอนทิตีใดๆ ไว้ในที่เก็บของพวกเขา แม้ว่าพวกเขาจะกล่าวถึงในเอกสารก็ตาม เหตุผลประการหนึ่งในการละเว้นโค้ดนี้อาจเป็นเพราะว่าเป็นเรื่องยากที่จะนำการแก้ไขเอนทิตีที่มีประสิทธิภาพและแข็งแกร่งไปใช้กับโดเมนที่กำหนดใดๆ คุณสามารถใช้ฮิวริสติกแบบกำหนดเองสำหรับโหนดต่างๆ ได้เมื่อจัดการกับโหนดประเภทที่กำหนดไว้ล่วงหน้า (เมื่อไม่ได้กำหนดไว้ล่วงหน้า แสดงว่าโหนดไม่สอดคล้องกันเพียงพอ เช่น บริษัท องค์กร ธุรกิจ เป็นต้น) อย่างไรก็ตาม หากไม่ทราบป้ายกำกับหรือประเภทของโหนดล่วงหน้า เช่นในกรณีของเรา ปัญหาดังกล่าวจะกลายเป็นปัญหาที่ยากยิ่งขึ้น อย่างไรก็ตาม เราจะนำการแก้ไขเอนทิตีเวอร์ชันหนึ่งไปใช้ในโครงการของเราที่นี่ โดยผสมผสานการฝังข้อความและอัลกอริทึมกราฟเข้ากับระยะห่างของคำและ LLM


กระบวนการของเราสำหรับการแก้ไขปัญหามีขั้นตอนดังต่อไปนี้:
- เอนทิตีในกราฟ — เริ่มต้นด้วยเอนทิตีทั้งหมดภายในกราฟ
- กราฟเพื่อนบ้านที่ใกล้ที่สุด K รายการ — สร้างกราฟเพื่อนบ้านที่ใกล้ที่สุด k รายการ โดยเชื่อมโยงเอนทิตีที่คล้ายคลึงกันโดยอิงจากการฝังข้อความ
- ส่วนประกอบที่เชื่อมต่อกันอย่างอ่อน — ระบุส่วนประกอบที่เชื่อมต่อกันอย่างอ่อนในกราฟ k-ที่ใกล้ที่สุด โดยจัดกลุ่มเอนทิตีที่น่าจะมีความคล้ายคลึงกัน เพิ่มขั้นตอนการกรองระยะห่างของคำหลังจากระบุส่วนประกอบเหล่านี้แล้ว
- การประเมิน LLM — ใช้ LLM เพื่อประเมินส่วนประกอบเหล่านี้และตัดสินใจว่าควรจะรวมหน่วยงานภายในแต่ละส่วนประกอบหรือไม่ ซึ่งส่งผลให้เกิดการตัดสินใจขั้นสุดท้ายในการแก้ไขหน่วยงาน (ตัวอย่างเช่น การรวม 'Silicon Valley Bank' และ 'Silicon_Valley_Bank' ในขณะที่ปฏิเสธการรวมในวันที่ต่างกัน เช่น '16 กันยายน 2023' และ '2 กันยายน 2023')
เราเริ่มต้นด้วยการคำนวณการฝังข้อความสำหรับคุณสมบัติชื่อและคำอธิบายของเอนทิตี เราสามารถใช้เมธอด from_existing_graph ในการผสานรวม Neo4jVector ใน LangChain เพื่อให้บรรลุสิ่งนี้:
vector = Neo4jVector.from_existing_graph( OpenAIEmbeddings(), node_label='__Entity__', text_node_properties=['id', 'description'], embedding_node_property='embedding' )
เราสามารถใช้การฝังข้อมูลเหล่านี้เพื่อค้นหาผู้สมัครที่มีศักยภาพที่คล้ายคลึงกันโดยอิงจากระยะห่างโคไซน์ของการฝังข้อมูลเหล่านี้ เราจะใช้อัลกอริทึมกราฟที่มีอยู่ใน ไลบรารี Graph Data Science (GDS) ดังนั้น เราจึงสามารถใช้ ไคลเอนต์ GDS Python เพื่อความสะดวกในการใช้งานในรูปแบบ Pythonic:
from graphdatascience import GraphDataScience gds = GraphDataScience( os.environ["NEO4J_URI"], auth=(os.environ["NEO4J_USERNAME"], os.environ["NEO4J_PASSWORD"]) )
หากคุณไม่คุ้นเคยกับไลบรารี GDS ก่อนอื่นเราก็ต้องฉายกราฟในหน่วยความจำเสียก่อนจึงจะสามารถดำเนินการอัลกอริทึมกราฟใดๆ ได้


ขั้นแรก กราฟที่จัดเก็บไว้ของ Neo4j จะถูกฉายลงในกราฟในหน่วยความจำเพื่อให้ประมวลผลและวิเคราะห์ได้เร็วขึ้น ขั้นต่อไป อัลกอริทึมของกราฟจะถูกดำเนินการบนกราฟในหน่วยความจำ นอกจากนี้ ผลลัพธ์ของอัลกอริทึมยังสามารถจัดเก็บกลับเข้าไปในฐานข้อมูล Neo4j ได้อีกด้วย เรียนรู้เพิ่มเติมเกี่ยวกับเรื่องนี้ได้ใน เอกสารประกอบ
ในการสร้างกราฟเพื่อนบ้านที่ใกล้ที่สุด k แห่ง เราจะฉายเอนทิตีทั้งหมดพร้อมการฝังข้อความ:
G, result = gds.graph.project( "entities", # Graph name "__Entity__", # Node projection "*", # Relationship projection nodeProperties=["embedding"] # Configuration parameters )
ตอนนี้ที่กราฟถูกฉายภายใต้ชื่อ entities แล้ว เราสามารถดำเนินการอัลกอริทึมของกราฟได้ เราจะเริ่มต้นด้วยการสร้าง กราฟ k-nearest พารามิเตอร์ที่สำคัญที่สุดสองตัวที่มีอิทธิพลต่อความเบาบางหรือความหนาแน่นของกราฟ k-nearest คือ similarityCutoff และ topK topK คือจำนวนเพื่อนบ้านที่ต้องค้นหาสำหรับแต่ละโหนด โดยมีค่าต่ำสุดที่ 1 similarityCutoff จะกรองความสัมพันธ์ที่มีความคล้ายคลึงกันต่ำกว่าเกณฑ์นี้ออกไป ในที่นี้ เราจะใช้ topK เริ่มต้นคือ 10 และค่าตัดขาดความคล้ายคลึงที่ค่อนข้างสูงที่ 0.95 การใช้ค่าตัดขาดความคล้ายคลึงที่สูง เช่น 0.95 จะช่วยให้แน่ใจว่ามีเฉพาะคู่ที่มีความคล้ายคลึงกันสูงเท่านั้นที่ถือว่าตรงกัน ซึ่งจะช่วยลดผลบวกปลอมให้น้อยที่สุดและเพิ่มความแม่นยำ


เนื่องจากเราต้องการเก็บผลลัพธ์กลับไปยังกราฟที่ฉายในหน่วยความจำแทนกราฟความรู้ เราจะใช้โหมด mutate ของอัลกอริทึม:
similarity_threshold = 0.95 gds.knn.mutate( G, nodeProperties=['embedding'], mutateRelationshipType= 'SIMILAR', mutateProperty= 'score', similarityCutoff=similarity_threshold )
ขั้นตอนต่อไปคือการระบุกลุ่มของเอนทิตีที่เชื่อมโยงกับความสัมพันธ์ความคล้ายคลึงที่อนุมานใหม่ การระบุกลุ่มของโหนดที่เชื่อมต่อกันเป็นกระบวนการที่เกิดขึ้นบ่อยครั้งในการวิเคราะห์เครือข่าย ซึ่งมักเรียกว่า การตรวจจับชุมชน หรือ การจัดกลุ่ม ซึ่งเกี่ยวข้องกับการค้นหากลุ่มย่อยของโหนดที่เชื่อมต่อกันอย่างหนาแน่น ในตัวอย่างนี้ เราจะใช้ อัลกอริทึมส่วนประกอบที่เชื่อมต่อกันอย่างอ่อนแอ ซึ่งช่วยให้เราค้นหาส่วนต่างๆ ของกราฟที่โหนดทั้งหมดเชื่อมต่อกัน แม้ว่าเราจะละเลยทิศทางของการเชื่อมต่อก็ตาม


เราใช้โหมด write ของอัลกอริทึมเพื่อเก็บผลลัพธ์กลับไปยังฐานข้อมูล (กราฟที่จัดเก็บ):
gds.wcc.write( G, writeProperty="wcc", relationshipTypes=["SIMILAR"] )
การเปรียบเทียบการฝังข้อความช่วยค้นหาข้อมูลที่ซ้ำกัน แต่เป็นเพียงส่วนหนึ่งของกระบวนการแก้ไขเอนทิตีเท่านั้น ตัวอย่างเช่น Google และ Apple มีความใกล้เคียงกันมากในพื้นที่การฝัง (ความคล้ายคลึงของโคไซน์ 0.96 โดยใช้แบบจำลองการฝัง ada-002 ) BMW และ Mercedes Benz ก็เช่นเดียวกัน (ความคล้ายคลึงของโคไซน์ 0.97) ความคล้ายคลึงของการฝังข้อความที่มีจำนวนมากถือเป็นจุดเริ่มต้นที่ดี แต่เราสามารถปรับปรุงได้ ดังนั้น เราจะเพิ่มตัวกรองเพิ่มเติมที่อนุญาตให้มีคู่คำที่มีระยะห่างของข้อความสามหรือน้อยกว่าเท่านั้น (หมายความว่าสามารถเปลี่ยนแปลงได้เฉพาะอักขระเท่านั้น):
word_edit_distance = 3 potential_duplicate_candidates = graph.query( """MATCH (e:`__Entity__`) WHERE size(e.id) > 3 // longer than 3 characters WITH e.wcc AS community, collect(e) AS nodes, count(*) AS count WHERE count > 1 UNWIND nodes AS node // Add text distance WITH distinct [n IN nodes WHERE apoc.text.distance(toLower(node.id), toLower(n.id)) < $distance OR node.id CONTAINS n.id | n.id] AS intermediate_results WHERE size(intermediate_results) > 1 WITH collect(intermediate_results) AS results // combine groups together if they share elements UNWIND range(0, size(results)-1, 1) as index WITH results, index, results[index] as result WITH apoc.coll.sort(reduce(acc = result, index2 IN range(0, size(results)-1, 1) | CASE WHEN index <> index2 AND size(apoc.coll.intersection(acc, results[index2])) > 0 THEN apoc.coll.union(acc, results[index2]) ELSE acc END )) as combinedResult WITH distinct(combinedResult) as combinedResult // extra filtering WITH collect(combinedResult) as allCombinedResults UNWIND range(0, size(allCombinedResults)-1, 1) as combinedResultIndex WITH allCombinedResults[combinedResultIndex] as combinedResult, combinedResultIndex, allCombinedResults WHERE NOT any(x IN range(0,size(allCombinedResults)-1,1) WHERE x <> combinedResultIndex AND apoc.coll.containsAll(allCombinedResults[x], combinedResult) ) RETURN combinedResult """, params={'distance': word_edit_distance})
ข้อความ Cypher นี้มีความซับซ้อนมากกว่าเล็กน้อย และการตีความก็เกินขอบเขตของโพสต์บล็อกนี้ คุณสามารถขอให้ LLM ตีความข้อความนี้ได้เสมอ


นอกจากนี้ การตัดระยะทางคำอาจเป็นฟังก์ชันของความยาวของคำแทนที่จะเป็นตัวเลขตัวเดียว และการนำไปใช้งานยังสามารถปรับขนาดได้มากขึ้น
สิ่งที่สำคัญคือมันจะแสดงกลุ่มของเอนทิตีที่เราอาจต้องการรวมเข้าด้วยกัน นี่คือรายการโหนดที่อาจจะรวมเข้าด้วยกัน:
{'combinedResult': ['Sinn Fein', 'Sinn Féin']}, {'combinedResult': ['Government', 'Governments']}, {'combinedResult': ['Unreal Engine', 'Unreal_Engine']}, {'combinedResult': ['March 2016', 'March 2020', 'March 2022', 'March_2023']}, {'combinedResult': ['Humana Inc', 'Humana Inc.']}, {'combinedResult': ['New York Jets', 'New York Mets']}, {'combinedResult': ['Asia Pacific', 'Asia-Pacific', 'Asia_Pacific']}, {'combinedResult': ['Bengaluru', 'Mangaluru']}, {'combinedResult': ['US Securities And Exchange Commission', 'Us Securities And Exchange Commission']}, {'combinedResult': ['Jp Morgan', 'Jpmorgan']}, {'combinedResult': ['Brighton', 'Brixton']},
อย่างที่คุณเห็น แนวทางการแก้ไขปัญหาของเรานั้นได้ผลดีกับโหนดบางประเภทมากกว่าประเภทอื่นๆ จากการตรวจสอบอย่างรวดเร็ว แนวทางนี้ดูเหมือนว่าจะได้ผลดีกว่าสำหรับบุคคลและองค์กร ในขณะที่แนวทางนี้ค่อนข้างแย่สำหรับวันที่ หากเราใช้โหนดประเภทที่กำหนดไว้ล่วงหน้า เราสามารถเตรียมฮิวริสติกที่แตกต่างกันสำหรับโหนดประเภทต่างๆ ได้ ในตัวอย่างนี้ เราไม่มีป้ายกำกับโหนดที่กำหนดไว้ล่วงหน้า ดังนั้น เราจะหันไปใช้ LLM เพื่อตัดสินใจขั้นสุดท้ายว่าควรจะรวมเอนทิตีเข้าด้วยกันหรือไม่
ก่อนอื่น เราต้องกำหนดคำแนะนำ LLM เพื่อให้คำแนะนำและแจ้งการตัดสินใจขั้นสุดท้ายเกี่ยวกับการรวมโหนดอย่างมีประสิทธิภาพ:
system_prompt = """You are a data processing assistant. Your task is to identify duplicate entities in a list and decide which of them should be merged. The entities might be slightly different in format or content, but essentially refer to the same thing. Use your analytical skills to determine duplicates. Here are the rules for identifying duplicates: 1. Entities with minor typographical differences should be considered duplicates. 2. Entities with different formats but the same content should be considered duplicates. 3. Entities that refer to the same real-world object or concept, even if described differently, should be considered duplicates. 4. If it refers to different numbers, dates, or products, do not merge results """ user_template = """ Here is the list of entities to process: {entities} Please identify duplicates, merge them, and provide the merged list. """
ฉันชอบใช้เมธอด with_structured_output ใน LangChain เสมอเมื่อต้องการเอาท์พุตข้อมูลที่มีโครงสร้าง เพื่อหลีกเลี่ยงการแยกวิเคราะห์เอาท์พุตด้วยตนเอง
ที่นี่ เราจะกำหนดผลลัพธ์เป็น list of lists โดยแต่ละรายการภายในประกอบด้วยเอนทิตีที่ควรผสานเข้าด้วยกัน โครงสร้างนี้ใช้ในการจัดการสถานการณ์ที่อินพุตอาจเป็น [Sony, Sony Inc, Google, Google Inc] ตัวอย่างเช่น ในกรณีเช่นนี้ คุณจะต้องการผสาน "Sony" และ "Sony Inc" แยกจาก "Google" และ "Google Inc."
class DuplicateEntities(BaseModel): entities: List[str] = Field( description="Entities that represent the same object or real-world entity and should be merged" ) class Disambiguate(BaseModel): merge_entities: Optional[List[DuplicateEntities]] = Field( description="Lists of entities that represent the same object or real-world entity and should be merged" ) extraction_llm = ChatOpenAI(model_name="gpt-4o").with_structured_output( Disambiguate )
ถัดไป เราจะรวมพรอมต์ LLM เข้ากับเอาต์พุตที่มีโครงสร้างเพื่อสร้างเชนโดยใช้ไวยากรณ์ LangChain Expression Language (LCEL) และห่อหุ้มไว้ในฟังก์ชัน disambiguate
extraction_chain = extraction_prompt | extraction_llm def entity_resolution(entities: List[str]) -> Optional[List[List[str]]]: return [ el.entities for el in extraction_chain.invoke({"entities": entities}).merge_entities ]
เราจำเป็นต้องเรียกใช้โหนดผู้สมัครที่มีศักยภาพทั้งหมดผ่านฟังก์ชัน entity_resolution เพื่อตัดสินใจว่าจะรวมโหนดเหล่านั้นเข้าด้วยกันหรือไม่ เพื่อเร่งกระบวนการ เราจะดำเนินการเรียก LLM แบบขนานอีกครั้ง:
merged_entities = [] with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # Submitting all tasks and creating a list of future objects futures = [ executor.submit(entity_resolution, el['combinedResult']) for el in potential_duplicate_candidates ] for future in tqdm( as_completed(futures), total=len(futures), desc="Processing documents" ): to_merge = future.result() if to_merge: merged_entities.extend(to_merge)
ขั้นตอนสุดท้ายของการแก้ไขเอนทิตีเกี่ยวข้องกับการนำผลลัพธ์จาก LLM ของ entity_resolution และเขียนกลับไปยังฐานข้อมูลโดยการรวมโหนดที่ระบุ:
graph.query(""" UNWIND $data AS candidates CALL { WITH candidates MATCH (e:__Entity__) WHERE e.id IN candidates RETURN collect(e) AS nodes } CALL apoc.refactor.mergeNodes(nodes, {properties: { description:'combine', `.*`: 'discard' }}) YIELD node RETURN count(*) """, params={"data": merged_entities})
การแก้ไขปัญหาเอนทิตีนี้ไม่สมบูรณ์แบบ แต่ช่วยให้เรามีจุดเริ่มต้นที่สามารถปรับปรุงได้ นอกจากนี้ เรายังสามารถปรับปรุงตรรกะในการกำหนดว่าควรเก็บเอนทิตีใดไว้
การสรุปองค์ประกอบ
ในขั้นตอนถัดไป ผู้เขียนจะดำเนินการขั้นตอนการสรุปองค์ประกอบ โดยพื้นฐานแล้ว โหนดและความสัมพันธ์ทั้งหมดจะถูกส่งผ่าน พรอมต์การสรุปเอนทิตี ผู้เขียนสังเกตเห็นความแปลกใหม่และน่าสนใจของแนวทางของพวกเขา:
“โดยรวมแล้ว การใช้ข้อความบรรยายที่มีเนื้อหาสมบูรณ์สำหรับโหนดที่เป็นเนื้อเดียวกันในโครงสร้างกราฟที่อาจมีสัญญาณรบกวนนั้นสอดคล้องกับทั้งความสามารถของ LLM และความต้องการของการสรุปข้อมูลโดยรวมที่เน้นที่การค้นหา คุณลักษณะเหล่านี้ยังทำให้ดัชนีกราฟของเราแตกต่างจากกราฟความรู้ทั่วไป ซึ่งอาศัยความรู้สามประการที่กระชับและสอดคล้องกัน (เรื่อง คำทำนาย วัตถุ) สำหรับงานการใช้เหตุผลแบบต่อเนื่อง”
แนวคิดนี้ค่อนข้างน่าตื่นเต้น เราจะยังคงแยก ID หรือชื่อของเรื่องและวัตถุออกจากข้อความ ซึ่งทำให้เราสามารถเชื่อมโยงความสัมพันธ์เข้ากับเอนทิตีที่ถูกต้องได้ แม้ว่าเอนทิตีจะปรากฏอยู่ในข้อความหลายส่วนก็ตาม อย่างไรก็ตาม ความสัมพันธ์ไม่ได้ลดลงเหลือเพียงประเภทเดียว ในทางกลับกัน ประเภทความสัมพันธ์เป็นข้อความรูปแบบอิสระที่ช่วยให้เราเก็บข้อมูลที่มีรายละเอียดและรายละเอียดมากขึ้นได้
นอกจากนี้ ข้อมูลเอนทิตีจะสรุปโดยใช้ LLM ซึ่งทำให้เราสามารถฝังและสร้างดัชนีข้อมูลและเอนทิตีเหล่านี้ได้อย่างมีประสิทธิภาพมากขึ้น เพื่อการดึงข้อมูลที่แม่นยำยิ่งขึ้น
อาจมีการโต้แย้งได้ว่าข้อมูลที่สมบูรณ์และละเอียดอ่อนยิ่งขึ้นนี้สามารถเก็บรักษาไว้ได้โดยการเพิ่มคุณสมบัติโหนดและความสัมพันธ์เพิ่มเติม ซึ่งอาจเกิดขึ้นเองได้ ปัญหาประการหนึ่งของคุณสมบัติโหนดและความสัมพันธ์โดยพลการก็คือ อาจเป็นเรื่องยากที่จะดึงข้อมูลออกมาได้อย่างสม่ำเสมอ เนื่องจาก LLM อาจใช้ชื่อคุณสมบัติที่แตกต่างกันหรือเน้นที่รายละเอียดต่างๆ ในการดำเนินการแต่ละครั้ง
ปัญหาบางส่วนเหล่านี้สามารถแก้ไขได้โดยใช้ชื่อคุณสมบัติที่กำหนดไว้ล่วงหน้าพร้อมข้อมูลประเภทและคำอธิบายเพิ่มเติม ในกรณีนั้น คุณจะต้องมีผู้เชี่ยวชาญเฉพาะด้านมาช่วยกำหนดคุณสมบัติเหล่านั้น ทำให้ LLM แทบไม่มีโอกาสดึงข้อมูลสำคัญใดๆ ออกมานอกเหนือจากคำอธิบายที่กำหนดไว้ล่วงหน้า
เป็นวิธีการที่น่าตื่นเต้นในการแสดงข้อมูลที่มีคุณค่ามากขึ้นในกราฟความรู้
ปัญหาที่อาจเกิดขึ้นประการหนึ่งกับขั้นตอนการสรุปองค์ประกอบก็คือ ขั้นตอนการสรุปนั้นไม่ได้ปรับขนาดได้ดีนัก เนื่องจากต้องเรียกใช้ LLM สำหรับทุกเอนทิตีและความสัมพันธ์ในกราฟ กราฟของเรามีขนาดค่อนข้างเล็ก โดยมีโหนด 13,000 โหนดและความสัมพันธ์ 16,000 รายการ แม้แต่สำหรับกราฟขนาดเล็กเช่นนี้ เราก็ยังต้องใช้การเรียกใช้ LLM ถึง 29,000 ครั้ง และการเรียกใช้แต่ละครั้งจะใช้โทเค็นประมาณสองร้อยโทเค็น ทำให้ค่อนข้างมีค่าใช้จ่ายสูงและใช้เวลานาน ดังนั้น เราจะหลีกเลี่ยงขั้นตอนนี้ในที่นี้ เราสามารถใช้คุณสมบัติคำอธิบายที่แยกออกมาในระหว่างการประมวลผลข้อความเริ่มต้นได้
การสร้างและสรุปชุมชน
ขั้นตอนสุดท้ายในการสร้างกราฟและจัดทำดัชนีเกี่ยวข้องกับการระบุชุมชนภายในกราฟ ในบริบทนี้ ชุมชนคือกลุ่มโหนดที่เชื่อมต่อกันอย่างหนาแน่นมากกว่าโหนดอื่นๆ ในกราฟ ซึ่งบ่งชี้ถึงระดับการโต้ตอบหรือความคล้ายคลึงกันที่สูงกว่า ภาพต่อไปนี้แสดงตัวอย่างผลลัพธ์การตรวจจับชุมชน


เมื่อระบุชุมชนเอนทิตีเหล่านี้โดยใช้อัลกอริทึมการจัดกลุ่มแล้ว LLM จะสร้างสรุปสำหรับแต่ละชุมชน โดยให้ข้อมูลเชิงลึกเกี่ยวกับลักษณะเฉพาะและความสัมพันธ์ของแต่ละชุมชน
เราใช้ไลบรารี Graph Data Science อีกครั้ง โดยเริ่มต้นด้วยการฉายกราฟในหน่วยความจำ เพื่อให้สอดคล้องกับบทความต้นฉบับ เราจะฉายกราฟของเอนทิตีเป็นเครือข่ายที่มีน้ำหนักแบบไม่มีทิศทาง โดยเครือข่ายจะแสดงจำนวนการเชื่อมต่อระหว่างเอนทิตีสองตัว:
G, result = gds.graph.project( "communities", # Graph name "__Entity__", # Node projection { "_ALL_": { "type": "*", "orientation": "UNDIRECTED", "properties": {"weight": {"property": "*", "aggregation": "COUNT"}}, } }, )
ผู้เขียนใช้ อัลกอริทึมของไลเดน ซึ่งเป็นวิธีการจัดกลุ่มตามลำดับชั้น เพื่อระบุชุมชนภายในกราฟ ข้อดีอย่างหนึ่งของการใช้อัลกอริทึมการตรวจจับชุมชนตามลำดับชั้นคือความสามารถในการตรวจสอบชุมชนในระดับรายละเอียดหลายระดับ ผู้เขียนแนะนำให้สรุปชุมชนทั้งหมดในแต่ละระดับ เพื่อให้เข้าใจโครงสร้างของกราฟได้อย่างครอบคลุม
ขั้นแรก เราจะใช้อัลกอริทึม Weakly Connected Components (WCC) เพื่อประเมินการเชื่อมต่อของกราฟ อัลกอริทึมนี้จะระบุส่วนที่แยกจากกันภายในกราฟ ซึ่งหมายความว่าอัลกอริทึมจะตรวจจับชุดย่อยของโหนดหรือส่วนประกอบที่เชื่อมต่อถึงกันแต่ไม่เชื่อมต่อกับส่วนที่เหลือของกราฟ ส่วนประกอบเหล่านี้ช่วยให้เราเข้าใจการแตกตัวภายในเครือข่ายและระบุกลุ่มของโหนดที่เป็นอิสระจากโหนดอื่นๆ WCC มีความสำคัญต่อการวิเคราะห์โครงสร้างโดยรวมและการเชื่อมต่อของกราฟ
wcc = gds.wcc.stats(G) print(f"Component count: {wcc['componentCount']}") print(f"Component distribution: {wcc['componentDistribution']}") # Component count: 1119 # Component distribution: { # "min":1, # "p5":1, # "max":9109, # "p999":43, # "p99":19, # "p1":1, # "p10":1, # "p90":7, # "p50":2, # "p25":1, # "p75":4, # "p95":10, # "mean":11.3 }
ผลลัพธ์ของอัลกอริทึม WCC ระบุส่วนประกอบที่แตกต่างกัน 1,119 ชิ้น โดยเฉพาะอย่างยิ่ง ส่วนประกอบที่ใหญ่ที่สุดประกอบด้วยโหนด 9,109 ชิ้น ซึ่งมักพบในเครือข่ายในโลกแห่งความเป็นจริง โดยที่ซูเปอร์ส่วนประกอบเพียงชิ้นเดียวจะอยู่ร่วมกับส่วนประกอบแยกย่อยขนาดเล็กจำนวนมาก ส่วนประกอบที่เล็กที่สุดมีโหนดเดียว และขนาดส่วนประกอบโดยเฉลี่ยอยู่ที่ประมาณ 11.3 โหนด
ขั้นต่อไป เราจะเรียกใช้อัลกอริทึม Leiden ซึ่งมีอยู่ในไลบรารี GDS ด้วย และเปิดใช้งานพารามิเตอร์ includeIntermediateCommunities เพื่อส่งคืนและจัดเก็บชุมชนในทุกระดับ นอกจากนี้ เรายังรวมพารามิเตอร์ relationshipWeightProperty ไว้เพื่อเรียกใช้อัลกอริทึม Leiden แบบถ่วงน้ำหนัก การใช้โหมด write ของอัลกอริทึมจะจัดเก็บผลลัพธ์เป็นคุณสมบัติของโหนด
gds.leiden.write( G, writeProperty="communities", includeIntermediateCommunities=True, relationshipWeightProperty="weight", )
อัลกอริธึมระบุชุมชน 5 ระดับ โดยระดับสูงสุด (ระดับที่มีรายละเอียดน้อยที่สุด โดยชุมชนมีขนาดใหญ่ที่สุด) มี 1,188 ชุมชน (ต่างจาก 1,119 องค์ประกอบ) ต่อไปนี้คือการแสดงภาพของชุมชนในระดับสุดท้ายโดยใช้ Gephi


การสร้างภาพชุมชนมากกว่า 1,000 แห่งเป็นเรื่องยาก แม้แต่การเลือกสีสำหรับแต่ละชุมชนก็แทบจะเป็นไปไม่ได้ อย่างไรก็ตาม สิ่งเหล่านี้สามารถถ่ายทอดออกมาเป็นงานศิลปะได้อย่างสวยงาม
จากนี้ เราจะสร้างโหนดที่แยกจากกันสำหรับแต่ละชุมชนและแสดงโครงสร้างลำดับชั้นของชุมชนเป็นกราฟที่เชื่อมโยงกัน ในภายหลัง เราจะจัดเก็บสรุปชุมชนและแอตทริบิวต์อื่นๆ เป็นคุณสมบัติของโหนดด้วย
graph.query(""" MATCH (e:`__Entity__`) UNWIND range(0, size(e.communities) - 1 , 1) AS index CALL { WITH e, index WITH e, index WHERE index = 0 MERGE (c:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])}) ON CREATE SET c.level = index MERGE (e)-[:IN_COMMUNITY]->(c) RETURN count(*) AS count_0 } CALL { WITH e, index WITH e, index WHERE index > 0 MERGE (current:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])}) ON CREATE SET current.level = index MERGE (previous:`__Community__` {id: toString(index - 1) + '-' + toString(e.communities[index - 1])}) ON CREATE SET previous.level = index - 1 MERGE (previous)-[:IN_COMMUNITY]->(current) RETURN count(*) AS count_1 } RETURN count(*) """)
นอกจากนี้ผู้เขียนยังแนะนำ community rank ซึ่งระบุจำนวนชิ้นข้อความที่แตกต่างกันซึ่งมีเอนทิตีภายในชุมชนปรากฏอยู่ด้วย:
graph.query(""" MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(:__Entity__)<-[:MENTIONS]-(d:Document) WITH c, count(distinct d) AS rank SET c.community_rank = rank; """)
ตอนนี้เรามาตรวจสอบโครงสร้างลำดับชั้นตัวอย่างที่มีชุมชนระดับกลางจำนวนมากรวมกันในระดับที่สูงกว่า ชุมชนเหล่านี้ไม่ทับซ้อนกัน ซึ่งหมายความว่าแต่ละหน่วยงานจะเป็นสมาชิกชุมชนเดียวในแต่ละระดับ


รูปภาพแสดงโครงสร้างลำดับชั้นที่เกิดจากอัลกอริทึมการตรวจจับชุมชนไลเดน โหนดสีม่วงแสดงถึงเอนทิตีแต่ละส่วน ในขณะที่โหนดสีส้มแสดงถึงชุมชนตามลำดับชั้น
ลำดับชั้นแสดงให้เห็นการจัดองค์กรของหน่วยงานต่างๆ เหล่านี้ลงในชุมชนต่างๆ โดยชุมชนเล็กๆ จะรวมเข้าด้วยกันเป็นชุมชนใหญ่ในระดับที่สูงกว่า
ตอนนี้เรามาดูกันว่าชุมชนขนาดเล็กจะรวมตัวกันในระดับที่สูงกว่าได้อย่างไร

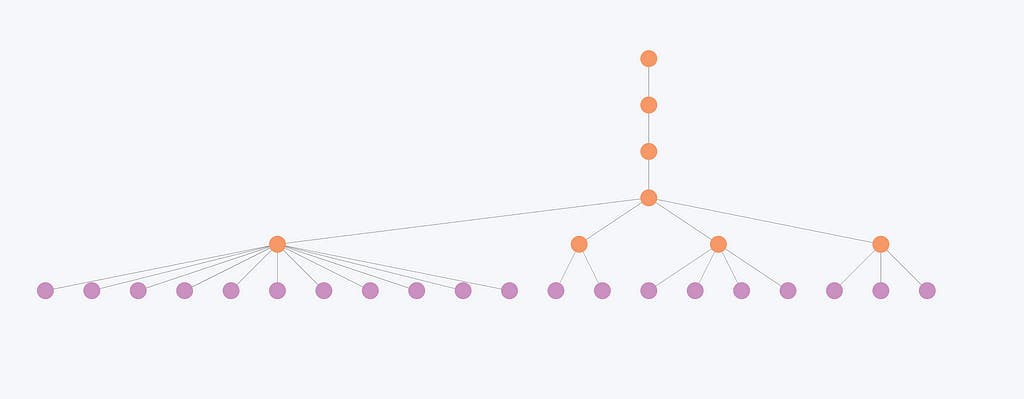
ภาพนี้แสดงให้เห็นว่าหน่วยงานที่มีการเชื่อมต่อกันน้อยลงและส่งผลให้ชุมชนมีขนาดเล็กลงนั้นมีการเปลี่ยนแปลงเพียงเล็กน้อยในแต่ละระดับ ตัวอย่างเช่น โครงสร้างของชุมชนที่นี่จะเปลี่ยนแปลงเฉพาะในสองระดับแรกเท่านั้น แต่ยังคงเหมือนเดิมในสามระดับสุดท้าย ดังนั้น ระดับลำดับชั้นจึงมักดูซ้ำซ้อนสำหรับหน่วยงานเหล่านี้ เนื่องจากองค์กรโดยรวมไม่เปลี่ยนแปลงไปอย่างมากในแต่ละระดับ
มาตรวจสอบจำนวนชุมชน ขนาด และระดับต่างๆ ของชุมชนอย่างละเอียดกัน:
community_size = graph.query( """ MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(e:__Entity__) WITH c, count(distinct e) AS entities RETURN split(c.id, '-')[0] AS level, entities """ ) community_size_df = pd.DataFrame.from_records(community_size) percentiles_data = [] for level in community_size_df["level"].unique(): subset = community_size_df[community_size_df["level"] == level]["entities"] num_communities = len(subset) percentiles = np.percentile(subset, [25, 50, 75, 90, 99]) percentiles_data.append( [ level, num_communities, percentiles[0], percentiles[1], percentiles[2], percentiles[3], percentiles[4], max(subset) ] ) # Create a DataFrame with the percentiles percentiles_df = pd.DataFrame( percentiles_data, columns=[ "Level", "Number of communities", "25th Percentile", "50th Percentile", "75th Percentile", "90th Percentile", "99th Percentile", "Max" ], ) percentiles_df


ในการใช้งานจริง ชุมชนในทุกระดับได้รับการสรุป ในกรณีของเรา จะมี 8,590 ชุมชน และด้วยเหตุนี้จึงมีการเรียก LLM ถึง 8,590 ครั้ง ฉันขอโต้แย้งว่าขึ้นอยู่กับโครงสร้างชุมชนตามลำดับชั้น ไม่จำเป็นต้องสรุปทุกระดับ ตัวอย่างเช่น ความแตกต่างระหว่างระดับสุดท้ายและระดับถัดไปสุดท้ายมีเพียงสี่ชุมชน (1,192 เทียบกับ 1,188) ดังนั้น เราจึงสร้างการสรุปซ้ำซ้อนจำนวนมาก วิธีแก้ปัญหาอย่างหนึ่งคือการสร้างการใช้งานที่สามารถสร้างการสรุปเดียวสำหรับชุมชนในระดับต่างๆ ที่ไม่เปลี่ยนแปลง อีกวิธีหนึ่งคือการยุบลำดับชั้นของชุมชนที่ไม่เปลี่ยนแปลง
นอกจากนี้ ฉันไม่แน่ใจว่าเราต้องการสรุปชุมชนที่มีสมาชิกเพียงคนเดียวหรือไม่ เนื่องจากชุมชนเหล่านี้อาจไม่มีคุณค่าหรือข้อมูลมากนัก ในที่นี้ เราจะสรุปชุมชนในระดับ 0, 1 และ 4 ก่อนอื่น เราต้องดึงข้อมูลของชุมชนเหล่านี้จากฐานข้อมูล:
community_info = graph.query(""" MATCH (c:`__Community__`)<-[:IN_COMMUNITY*]-(e:__Entity__) WHERE c.level IN [0,1,4] WITH c, collect(e ) AS nodes WHERE size(nodes) > 1 CALL apoc.path.subgraphAll(nodes[0], { whitelistNodes:nodes }) YIELD relationships RETURN c.id AS communityId, [n in nodes | {id: n.id, description: n.description, type: [el in labels(n) WHERE el <> '__Entity__'][0]}] AS nodes, [r in relationships | {start: startNode(r).id, type: type(r), end: endNode(r).id, description: r.description}] AS rels """)
ในขณะนี้ข้อมูลชุมชนมีโครงสร้างดังนี้:
{'communityId': '0-6014', 'nodes': [{'id': 'Darrell Hughes', 'description': None, type:"Person"}, {'id': 'Chief Pilot', 'description': None, type: "Person"}, ... }], 'rels': [{'start': 'Ryanair Dac', 'description': 'Informed of the change in chief pilot', 'type': 'INFORMED', 'end': 'Irish Aviation Authority'}, {'start': 'Ryanair Dac', 'description': 'Dismissed after internal investigation found unacceptable behaviour', 'type': 'DISMISSED', 'end': 'Aidan Murray'}, ... ]}
ตอนนี้ เราต้องเตรียมคำถามสำหรับ LLM ที่จะสร้างการสรุปเป็นภาษาธรรมชาติโดยอิงจากข้อมูลที่ให้มาโดยองค์ประกอบของชุมชนของเรา เราสามารถได้รับแรงบันดาลใจจาก คำถามที่นักวิจัยใช้
ผู้เขียนไม่เพียงแต่สรุปชุมชนเท่านั้น แต่ยังสร้างผลลัพธ์สำหรับแต่ละชุมชนด้วย ผลลัพธ์สามารถกำหนดได้ว่าเป็นข้อมูลสั้น ๆ เกี่ยวกับเหตุการณ์เฉพาะหรือข้อมูลชิ้นหนึ่ง ตัวอย่างเช่น:
"summary": "Abila City Park as the central location", "explanation": "Abila City Park is the central entity in this community, serving as the location for the POK rally. This park is the common link between all other entities, suggesting its significance in the community. The park's association with the rally could potentially lead to issues such as public disorder or conflict, depending on the nature of the rally and the reactions it provokes. [records: Entities (5), Relationships (37, 38, 39, 40)]"
สัญชาตญาณของฉันบอกว่าการดึงผลลัพธ์ออกมาด้วยเพียงครั้งเดียวอาจไม่ครอบคลุมเท่าที่เราต้องการ เช่นเดียวกับการดึงข้อมูลและความสัมพันธ์
นอกจากนี้ ฉันยังไม่พบข้อมูลอ้างอิงหรือตัวอย่างการใช้งานในโค้ดของโปรแกรมค้นหาทั้งแบบโลคัลและแบบโกลบอล ดังนั้น ในกรณีนี้ เราจะละเว้นการดึงข้อมูลออกมา หรืออย่างที่นักวิชาการมักจะพูดว่า แบบฝึกหัดนี้ปล่อยให้ผู้อ่านเป็นคนตัดสินใจ นอกจากนี้ เรายังข้าม การอ้างสิทธิ์หรือการดึงข้อมูลตัวแปรร่วม ซึ่งดูคล้ายกับข้อมูลที่พบเมื่อดูเผินๆ
ข้อความแจ้งเตือนที่เราจะใช้ในการสร้างสรุปของชุมชนนั้นค่อนข้างตรงไปตรงมา:
community_template = """Based on the provided nodes and relationships that belong to the same graph community, generate a natural language summary of the provided information: {community_info} Summary:""" # noqa: E501 community_prompt = ChatPromptTemplate.from_messages( [ ( "system", "Given an input triples, generate the information summary. No pre-amble.", ), ("human", community_template), ] ) community_chain = community_prompt | llm | StrOutputParser()
สิ่งเดียวที่เหลืออยู่คือการเปลี่ยนการแสดงชุมชนเป็นสตริงเพื่อลดจำนวนโทเค็นโดยหลีกเลี่ยงโอเวอร์เฮดของโทเค็น JSON และห่อเชนเป็นฟังก์ชัน:
def prepare_string(data): nodes_str = "Nodes are:\n" for node in data['nodes']: node_id = node['id'] node_type = node['type'] if 'description' in node and node['description']: node_description = f", description: {node['description']}" else: node_description = "" nodes_str += f"id: {node_id}, type: {node_type}{node_description}\n" rels_str = "Relationships are:\n" for rel in data['rels']: start = rel['start'] end = rel['end'] rel_type = rel['type'] if 'description' in rel and rel['description']: description = f", description: {rel['description']}" else: description = "" rels_str += f"({start})-[:{rel_type}]->({end}){description}\n" return nodes_str + "\n" + rels_str def process_community(community): stringify_info = prepare_string(community) summary = community_chain.invoke({'community_info': stringify_info}) return {"community": community['communityId'], "summary": summary}
ตอนนี้เราสามารถสร้างสรุปชุมชนสำหรับระดับที่เลือกได้แล้ว อีกครั้งหนึ่ง เราจะดำเนินการแบบขนานกันเพื่อการดำเนินการที่รวดเร็วยิ่งขึ้น:
summaries = [] with ThreadPoolExecutor() as executor: futures = {executor.submit(process_community, community): community for community in community_info} for future in tqdm(as_completed(futures), total=len(futures), desc="Processing communities"): summaries.append(future.result())
ประเด็นหนึ่งที่ฉันไม่ได้พูดถึงก็คือผู้เขียนยังกล่าวถึงปัญหาที่อาจเกิดขึ้นจากการเกินขนาดบริบทเมื่อป้อนข้อมูลชุมชนอีกด้วย เมื่อกราฟขยายขึ้น ชุมชนก็สามารถเติบโตได้อย่างมากเช่นกัน ในกรณีของเรา ชุมชนที่ใหญ่ที่สุดประกอบด้วยสมาชิก 545 คน เนื่องจาก GPT-4o มีขนาดบริบทเกิน 100,000 โทเค็น เราจึงตัดสินใจข้ามขั้นตอนนี้ไป
ขั้นตอนสุดท้ายของเราคือการเก็บสรุปของชุมชนกลับไปยังฐานข้อมูล:
graph.query(""" UNWIND $data AS row MERGE (c:__Community__ {id:row.community}) SET c.summary = row.summary """, params={"data": summaries})
โครงสร้างกราฟขั้นสุดท้าย:


ขณะนี้กราฟประกอบด้วยเอกสารต้นฉบับ เอนทิตีและความสัมพันธ์ที่แยกออกมา รวมไปถึงโครงสร้างและบทสรุปของชุมชนตามลำดับชั้น
สรุป
ผู้เขียน เอกสาร "From Local to Global" ได้นำเสนอแนวทางใหม่ในการใช้ GraphRAG ได้เป็นอย่างดี โดยพวกเขาได้แสดงให้เห็นว่าเราสามารถรวมและสรุปข้อมูลจากเอกสารต่างๆ ให้เป็นโครงสร้างกราฟความรู้แบบลำดับชั้นได้อย่างไร
สิ่งหนึ่งที่ไม่ได้กล่าวถึงโดยชัดเจนคือเราสามารถรวมแหล่งข้อมูลที่มีโครงสร้างในกราฟได้ โดยอินพุตไม่จำเป็นต้องจำกัดอยู่แค่ข้อความที่ไม่มีโครงสร้างเท่านั้น
สิ่งที่ฉันชื่นชอบเป็นพิเศษเกี่ยวกับแนวทางการแยกข้อมูลของพวกเขาคือพวกเขาจับคำอธิบายสำหรับทั้งโหนดและความสัมพันธ์ คำอธิบายช่วยให้ LLM สามารถเก็บข้อมูลได้มากกว่าการลดทุกอย่างให้เหลือเพียง ID โหนดและประเภทความสัมพันธ์
นอกจากนี้ ยังแสดงให้เห็นว่าการสกัดข้อความเพียงครั้งเดียวอาจไม่สามารถรวบรวมข้อมูลที่เกี่ยวข้องทั้งหมดได้ และต้องใช้ตรรกะในการดำเนินการหลายครั้งหากจำเป็น นอกจากนี้ ผู้เขียนยังเสนอแนวคิดที่น่าสนใจในการสรุปข้อมูลในชุมชนกราฟ ซึ่งช่วยให้เราสามารถฝังและสร้างดัชนีข้อมูลหัวข้อย่อยที่ย่อลงในแหล่งข้อมูลหลายแหล่งได้
ในการโพสต์บล็อกถัดไป เราจะกล่าวถึงการนำตัวดึงข้อมูลการค้นหาแบบโลคัลและระดับโลกไปใช้งาน และพูดคุยเกี่ยวกับแนวทางอื่นๆ ที่เราสามารถนำไปใช้งานได้ตามโครงสร้างกราฟที่กำหนดให้
เช่นเคย โค้ดมีอยู่บน GitHub
ในครั้งนี้ ฉันได้อัพโหลด ฐานข้อมูล แล้วเพื่อให้คุณสามารถสำรวจผลลัพธ์และทดลองใช้ตัวเลือกตัวดึงข้อมูลที่แตกต่างกัน
คุณยังสามารถนำเข้าข้อมูลดัมพ์นี้ไปยัง อินสแตนซ์ Neo4j AuraDB ที่ใช้งานได้ฟรีตลอดไปได้ ซึ่งเราสามารถใช้สำหรับการสำรวจการดึงข้อมูล เนื่องจากเราไม่จำเป็นต้องใช้อัลกอริทึม Graph Data Science สำหรับสิ่งเหล่านี้ แต่จะใช้เพียงแค่การจับคู่รูปแบบกราฟ เวกเตอร์ และดัชนีข้อความเต็มเท่านั้น
เรียนรู้เพิ่มเติมเกี่ยวกับ การผสานรวม Neo4j กับเฟรมเวิร์ก GenAI ทั้งหมด และอัลกอริทึมกราฟเชิงปฏิบัติได้ในหนังสือของฉัน เรื่อง "Graph Algorithms for Data Science"
หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับหัวข้อนี้ โปรดเข้าร่วมงาน NODES 2024 ในวันที่ 7 พฤศจิกายน ซึ่งเป็นงานประชุมนักพัฒนาเสมือนจริงฟรีเกี่ยวกับแอปอัจฉริยะ กราฟความรู้ และ AI ลงทะเบียนเลยตอนนี้ !








