






















リンク一覧
3 予備
5 DPベースの公平学習に対する分布的にロバストな最適化アプローチ
6 数値結果
6.2 DPベースの公平学習で訓練されたモデルの帰納的バイアス
抽象的な
センシティブな属性にほとんど依存せずにラベルを割り当てる公平な教師あり学習アルゴリズムは、機械学習コミュニティで大きな注目を集めています。人口統計的パリティ (DP) の概念は、公平な分類器をトレーニングする際のモデルの公平性を測定するために頻繁に使用されていますが、文献のいくつかの研究では、公平な学習アルゴリズムで DP を強制することの潜在的な影響を示唆しています。この研究では、センシティブな属性が与えられた場合の予測ラベルの条件付き分布に対する標準的な DP ベースの正則化方法の影響を分析的に調査します。分析によると、センシティブな属性の分布が不均一な不均衡なトレーニング データセットでは、トレーニング データの大部分を保持するセンシティブな属性の結果に偏った分類ルールが生成される可能性があります。DP ベースの公平な学習におけるこのような帰納的バイアスを制御するために、センシティブな属性の限界分布に対する堅牢性を向上させるセンシティブな属性ベースの分布的に堅牢な最適化 (SA-DRO) 手法を提案します。最後に、標準的な集中型および分散型学習の問題への DP ベースの学習方法の適用に関するいくつかの数値結果を示します。経験的発見は、DP ベースの公平な学習アルゴリズムにおける帰納的バイアスと、提案された SA-DRO 法のバイアス除去効果に関する理論的結果を裏付けています。
1 はじめに
重要な意思決定タスクに最新の機械学習フレームワークを責任を持って導入するには、性別や民族などの機密属性への出力の依存性を制御するメカニズムが必要です。入力特徴に対する予測の依存性を制御できない教師あり学習フレームワークは、機密属性と大きく相関する差別的な決定につながる可能性があります。いくつかの機械学習アプリケーションでは公平性の要素が極めて重要であるため、公平な統計学習アルゴリズムの研究と開発は文献で大きな注目を集めています。



DP ベースの学習アルゴリズムのバイアスを減らすために、我々は、公平な学習者が、データに基づく周辺分布を中心とした一連の敏感属性周辺分布にわたって最悪の DP 正規化損失を最小化する、敏感属性ベースの分布的に堅牢な最適化 (SA-DRO) 手法を提案します。その結果、SA-DRO アプローチは、敏感属性の結果のさまざまな頻度を考慮できるため、敏感属性の多数派結果の変化に対して堅牢な動作を提供できます。
データセット内で多数を占めるセンシティブ属性に対する DDP ベースの公平な分類方法の潜在的なバイアスに関するいくつかの数値実験の結果を示します。私たちの経験的発見は理論的結果と一致しており、DP ベースの公平な分類ルールがセンシティブ属性ベースの多数派グループに対して誘導バイアスを持っていることを示唆しています。一方、私たちの結果は、DRO-SA ベースの公平な学習方法により、多数派のセンシティブ属性の下でのラベル分布に対するバイアスが低い公平な分類ルールが生成されることを示しています。
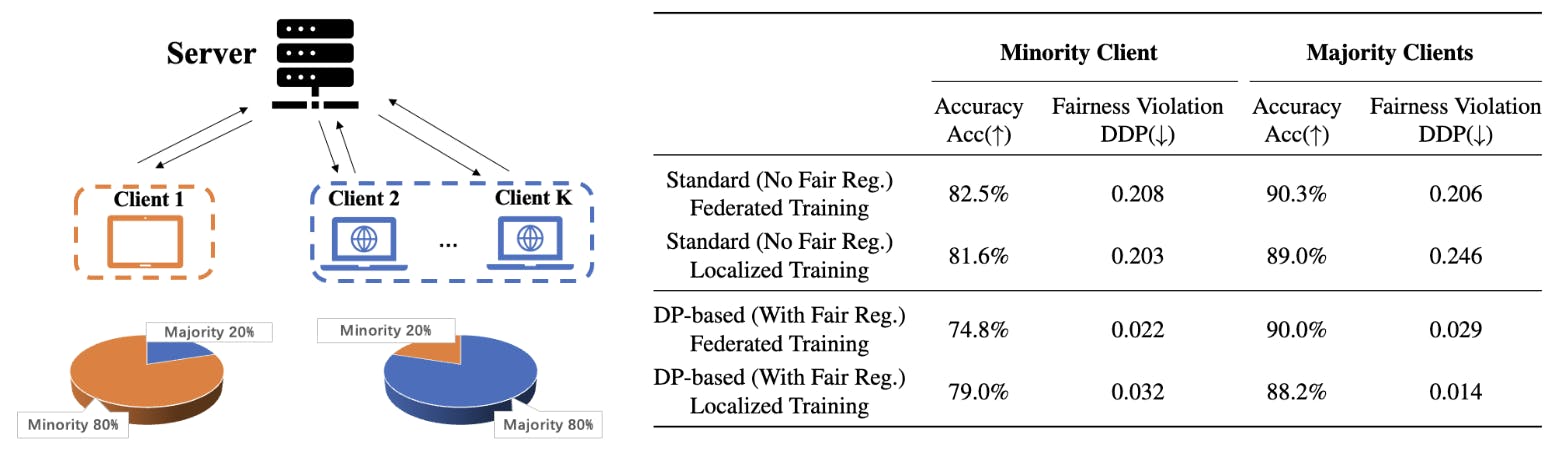
さらに、このような帰納的バイアスの実際の影響を示すために、複数のクライアントが分散モデルのトレーニングを試みる連合学習コンテキストでの公平な分類タスクを分析します。クライアント間でセンシティブ属性の分布が不均一で、クライアントの大多数のセンシティブ属性の結果が一致しない可能性がある設定に焦点を当てます。図 1 は、成人データセットでのこのような連合学習シナリオを示しています。クライアント 1 の大多数のセンシティブ属性 (女性サンプル) はネットワークの大多数のグループ (男性サンプル) とは異なり、その結果、DP ベースの公平な連合学習によるクライアント 1 のテスト精度は、クライアント 1 のデータのみでトレーニングされたローカライズされた公平なモデルのテスト精度よりも大幅に低くなります。このような数値結果は、公平な連合学習に参加するクライアントのインセンティブに疑問を投げかけます。以下は、この研究の主な貢献の要約です。
• DPベースの公平な学習が多数派に敏感な属性に及ぼすバイアスを分析的に研究する。
• DPベースの公平な分類のバイアスを低減するための分布的に堅牢な最適化手法を提案する。
• 集中型および連合型学習シナリオにおける DP ベースの公平な学習のバイアスに関する数値結果を提供します。
関連作品2
公平性違反メトリクス。本研究では、人口統計的パリティ (DP) を目指す学習フレームワークに焦点を当てています。DP を厳密に保持するように強制するとコストがかかり、学習者のパフォーマンスに悪影響を与える可能性があるため、機械学習の文献では、ランダム変数間の依存関係を評価するいくつかのメトリクスを適用することが提案されています。これには、相互情報量: [3–7]、ピアソン相関 [8, 9]、カーネルベースの最大平均差異: [10]、人口統計的パリティ (DDP) 測定の差のカーネル密度推定 [11]、最大相関 [12–15]、指数レニイ相互情報量 [16] が含まれます。私たちの分析では、主に DDP ベースの公平な正則化スキームに焦点を当てていますが、相互情報量と最大相関に基づく公平な学習アルゴリズムの場合にさらに保持される可能性があるのは、帰納的バイアスのより弱いバージョンのみであることを示しています。


公平な分類アルゴリズム。公平な機械学習アルゴリズムは、前処理、後処理、およびインプロセスの3つの主要なカテゴリに分類できます。前処理アルゴリズム[17–19]は、偏ったデータ機能を、ラベルと機密属性が統計的に独立した新しい空間に変換します。[2、20]などの後処理方法は、分類器の最終的な決定を変更することにより、分類器の差別的影響を軽減することを目的としています。私たちの研究の焦点は、DPベースの公平なモデルに向けてトレーニングプロセスを正規化するインプロセスアプローチのみにあります。また、[21–23]は公平な分類のための分布的に堅牢な最適化(DRO)を提案していますが、私たちの方法とは異なり、これらの研究では、バイアスを減らすために機密属性分布にDROを適用していません。
シンプルに
この論文は、CC BY-NC-SA 4.0 DEED ライセンスの下でarxiv で公開されています。
著者:
(1)香港中文大学コンピュータサイエンス工学部、Haoyu LEI([email protected])
(2)アミン・ゴハリ、香港中文大学情報工学部([email protected])
(3)香港中文大学コンピュータサイエンス工学部ファルザン・ファルニア([email protected])。








