






















Linkkitaulukko
3 Alkuvaiheet
3.1 Reilu valvottu oppiminen ja 3.2 oikeudenmukaisuuskriteerit
3.3 Riippuvuustoimenpiteet reilun ohjatun oppimisen kannalta
4 DP-pohjaisen reilun valvotun oppimisen induktiivista harhaa
4.1 Teoreettisten tulosten laajentaminen satunnaistettuun ennustussääntöön
5 Jakelultaan vankka optimointimenetelmä DP-pohjaiseen oikeudenmukaiseen oppimiseen
6 Numeerista tulosta
6.2 DP-pohjaiseen oikeudenmukaiseen oppimiseen koulutettujen mallien induktiiviset harhat
6.3 DP-pohjainen oikeudenmukainen luokittelu heterogeenisessä liittoutuneessa oppimisessa
Liite B Kuvatietojoukon lisätulokset
Abstrakti
Reilun valvotut oppimisalgoritmit, jotka antavat tunnisteita vain vähän riippuvaisesti herkästä attribuutista, ovat herättäneet suurta huomiota koneoppimisyhteisössä. Vaikka demografisen pariteetin (DP) käsitettä on usein käytetty mittaamaan mallin oikeudenmukaisuutta reilun luokittelun koulutuksessa, useat kirjallisuuden tutkimukset viittaavat mahdollisiin vaikutuksiin DP:n täytäntöönpanolla reilun oppimisen algoritmeissa. Tässä työssä tutkimme analyyttisesti standardien DP-pohjaisten regularisointimenetelmien vaikutusta ennustetun leiman ehdolliseen jakautumiseen herkän attribuutin perusteella. Analyysimme osoittaa, että epätasapainoinen harjoitustietojoukko, jossa herkän attribuutin jakauma on epätasainen, voi johtaa luokitussääntöön, joka on vinoutunut herkän attribuutin lopputulokseen, joka sisältää suurimman osan harjoitustiedoista. Tällaisten induktiivisten harhojen hallitsemiseksi DP-pohjaisessa reilussa oppimisessa ehdotamme herkkää attribuuttipohjaista jakautumisen kestävää optimointimenetelmää (SA-DRO), joka parantaa kestävyyttä herkän attribuutin marginaalijakaumaa vastaan. Lopuksi esittelemme useita numeerisia tuloksia DP-pohjaisten oppimismenetelmien soveltamisesta tavanomaisiin keskitettyihin ja hajautettuihin oppimisongelmiin. Empiiriset havainnot tukevat teoreettisia tuloksiamme DP-pohjaisten reilun oppimisalgoritmien induktiivisista harhoista ja ehdotetun SA-DRO-menetelmän vääristävistä vaikutuksista.
1 Johdanto
Nykyaikaisten koneoppimiskehysten vastuullinen käyttöönotto vaativissa päätöksentekotehtävissä edellyttää mekanismeja, joilla valvotaan niiden tulosten riippuvuutta herkistä ominaisuuksista, kuten sukupuolesta ja etnisyydestä. Valvottu oppimiskehys, jossa ei voida hallita ennusteen riippuvuutta syöteominaisuuksista, voi johtaa syrjiviin päätöksiin, jotka korreloivat merkittävästi herkkien ominaisuuksien kanssa. Johtuen reiluustekijän kriittisestä merkityksestä useissa koneoppimissovelluksissa, reilun tilastollisen oppimisalgoritmien tutkimus ja kehittäminen on saanut kirjallisuudessa paljon huomiota.



DP-pohjaisten oppimisalgoritmien harhojen vähentämiseksi ehdotamme herkkää attribuuttipohjaista jakauman vahvaa optimointimenetelmää (SA-DRO), jossa oikeudenmukainen oppija minimoi pahimman tapauksen DP:n säädellyn menetyksen joukolla herkkiä attribuuttien marginaalijakaumia, jotka keskittyvät tietopohjaisen marginaalijakauman ympärille. Tämän seurauksena SA-DRO-lähestymistapa voi ottaa huomioon herkän attribuutin tulosten eri taajuudet ja siten tarjota vankan käyttäytymisen herkän attribuutin enemmistötuloksissa tapahtuville muutoksille.
Esittelemme useiden numeeristen kokeiden tulokset DDP-pohjaisten oikeudenmukaisten luokittelumenetelmien mahdollisista harhoista herkälle attribuutille, jolla on suurin osa tietojoukosta. Empiiriset havaintomme ovat yhdenmukaisia teoreettisten tulosten kanssa, mikä viittaa DP-pohjaisten oikeudenmukaisten luokittelusääntöjen induktiiviseen harhaan herkkää attribuuttipohjaista enemmistöryhmää kohtaan. Toisaalta tulokset osoittavat, että DRO-SA-pohjainen reilu oppimismenetelmä johtaa oikeudenmukaisiin luokittelusääntöihin, joilla on pienempi harha enemmistön herkän attribuutin etiketin jakaumaan.
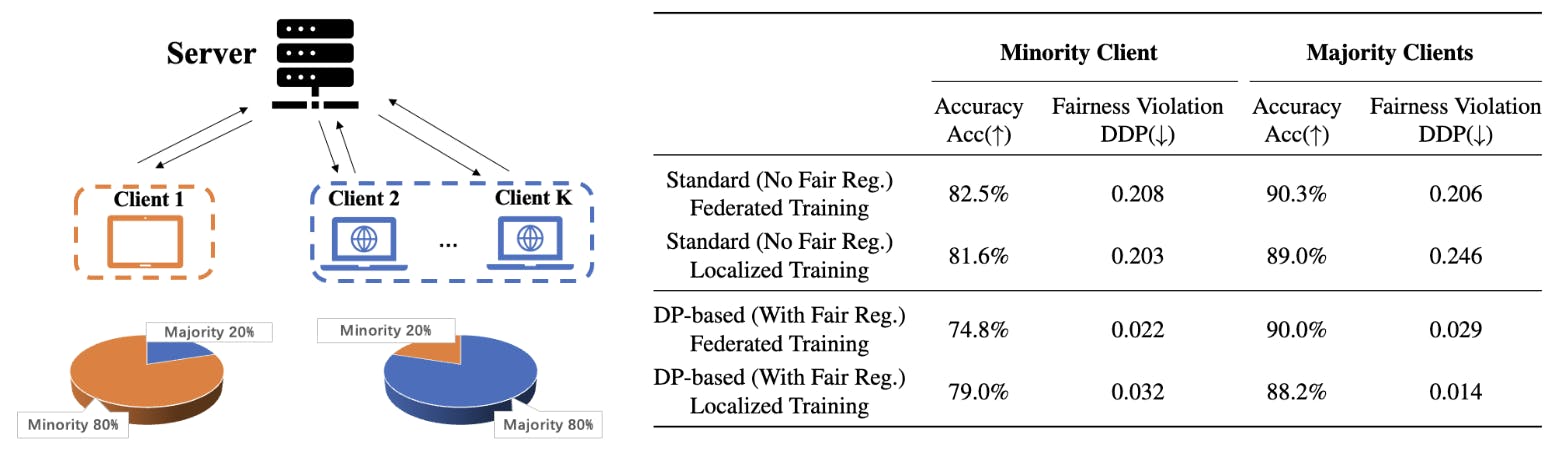
Lisäksi näyttääksemme tällaisten induktiivisten harhojen vaikutukset käytännössä analysoimme reilun luokittelutehtävän liitetyssä oppimiskontekstissa, jossa useat asiakkaat yrittävät kouluttaa hajautettua mallia. Keskitymme asetukseen, jossa on heterogeeniset herkät attribuuttijakaumat asiakkaiden kesken, jolloin asiakkaiden enemmistön herkät attribuutit eivät välttämättä sovi yhteen. Kuva 1 havainnollistaa tällaista yhdistettyä oppimisskenaariota aikuisten tietojoukossa, jossa Asiakas 1:n enemmistön herkkä attribuutti (naisnäytteet) eroaa verkon enemmistöryhmästä (miesnäytteet), ja näin ollen asiakas 1:n testitarkkuus DP-pohjaisella reilulla liittoutuneella oppimisella on huomattavasti pienempi kuin vain lokalisoidun Client-koulutetun1 datamallin testitarkkuus. Tällaiset numeeriset tulokset kyseenalaistavat asiakkaan kannustimen osallistua oikeudenmukaiseen liittoutuneeseen oppimiseen. Seuraavassa on yhteenveto tämän työn tärkeimmistä panoksista:
• Tutkitaan analyyttisesti DP-pohjaisen oikeudenmukaisen oppimisen ennakkoluuloja enemmistön herkkää ominaisuutta kohtaan,
• Jakauman kannalta vankan optimointimenetelmän ehdottaminen DP-pohjaisen oikeudenmukaisen luokituksen harhojen vähentämiseksi,
• Numeeristen tulosten tuottaminen DP-pohjaisen oikeudenmukaisen oppimisen ennakkoluuloista keskitetyissä ja yhdistetyissä oppimisskenaarioissa.
2 Aiheeseen liittyvää työtä
Reiluusrikkomusmittarit. Tässä työssä keskitymme demografiseen pariteettiin (DP) tähtääviin oppimiskehikkoihin. Koska DP:n pakottaminen tiukkaan pitämiseen voi olla kallista ja haitallista oppijan suoritukselle, koneoppimiskirjallisuudessa on ehdotettu useiden mittareiden soveltamista satunnaismuuttujien välisen riippuvuuden arvioimiseksi, mukaan lukien: keskinäinen informaatio: [3–7], Pearson-korrelaatio [8, 9], ytimeen perustuva maksimi keskimääräinen poikkeama: [10], DP-kerneltiheyden erotusmittaus. [11], maksimaalinen korrelaatio [12–15] ja eksponentiaalinen Renyi-keskinen informaatio [16]. Analyysissamme keskitymme enimmäkseen DDP-pohjaiseen oikeudenmukaiseen regularisointijärjestelmään, kun taas näytämme, että vain heikommat versiot induktiivisista harhoista voisivat olla edelleen voimassa keskinäisen tiedon ja maksimaalisen korrelaatioon perustuvien oikeudenmukaisten oppimisalgoritmien tapauksessa.


Kohtuulliset luokitusalgoritmit. Reilut koneoppimisalgoritmit voidaan luokitella kolmeen pääluokkaan: esikäsittely, jälkikäsittely ja prosessointi. Esikäsittelyalgoritmit [17–19] muuttavat puolueelliset dataominaisuudet uuteen tilaan, jossa tunnisteet ja arkaluontoiset attribuutit ovat tilastollisesti riippumattomia. Jälkikäsittelymenetelmillä, kuten [2, 20], pyritään lieventämään luokittelijan syrjivää vaikutusta muokkaamalla sen lopullista päätöstä. Työmme painopiste on vain prosessin sisäisissä lähestymistavoissa, jotka laillistavat koulutusprosessia kohti DP-pohjaisia messumalleja. Lisäksi [21–23] ehdottavat jakauman vahvaa optimointia (DRO) oikeudenmukaista luokittelua varten; Toisin kuin menetelmämme, nämä työt eivät kuitenkaan käytä DRO:ta herkässä attribuuttijakaumassa vääristymien vähentämiseksi.
yksinkertaistaa
Tämä paperi on saatavilla arxivissa CC BY-NC-SA 4.0 DEED -lisenssillä.
Tekijät:
(1) Haoyu LEI, tietojenkäsittelytieteen ja -tekniikan laitos, Hongkongin kiinalainen yliopisto ([email protected]);
(2) Amin Gohari, Hongkongin kiinalaisen yliopiston tietotekniikan laitos ([email protected]);
(3) Farzan Farnia, tietojenkäsittelytieteen ja -tekniikan laitos, Hongkongin kiinalainen yliopisto ([email protected]).








