






















Tabel met links
3 Voorrondes
3.1 Eerlijk begeleid leren en 3.2 criteria voor eerlijkheid
3.3 Afhankelijkheidsmaatregelen voor eerlijk begeleid leren
4 Inductieve vooroordelen van DP-gebaseerd eerlijk begeleid leren
4.1 Uitbreiding van de theoretische resultaten naar de gerandomiseerde voorspellingsregel
5 Een distributief robuuste optimalisatiebenadering voor DP-gebaseerd eerlijk leren
6 Numerieke resultaten
6.2 Inductieve vooroordelen van modellen die zijn getraind in DP-gebaseerd eerlijk leren
6.3 DP-gebaseerde eerlijke classificatie in heterogene gefedereerde leeromgevingen
Bijlage B Aanvullende resultaten voor beelddataset
Abstract
Eerlijke supervised learning-algoritmen die labels toewijzen met weinig afhankelijkheid van een gevoelig kenmerk, hebben veel aandacht getrokken in de machine learning-community. Hoewel het begrip demografische pariteit (DP) vaak is gebruikt om de eerlijkheid van een model te meten bij het trainen van eerlijke classificatoren, suggereren verschillende studies in de literatuur mogelijke gevolgen van het afdwingen van DP in eerlijke learning-algoritmen. In dit werk bestuderen we analytisch het effect van standaard DP-gebaseerde regularisatiemethoden op de voorwaardelijke verdeling van het voorspelde label gegeven het gevoelige kenmerk. Onze analyse toont aan dat een onevenwichtige trainingsdataset met een niet-uniforme verdeling van het gevoelige kenmerk kan leiden tot een classificatieregel die bevooroordeeld is ten gunste van de uitkomst van het gevoelige kenmerk die de meerderheid van de trainingsgegevens bevat. Om dergelijke inductieve vertekeningen in DP-gebaseerd eerlijk leren te beheersen, stellen we een gevoelige kenmerk-gebaseerde distributief robuuste optimalisatiemethode (SA-DRO) voor die de robuustheid verbetert tegen de marginale verdeling van het gevoelige kenmerk. Tot slot presenteren we verschillende numerieke resultaten over de toepassing van DP-gebaseerde leermethoden op standaard gecentraliseerde en gedistribueerde leerproblemen. De empirische bevindingen ondersteunen onze theoretische resultaten over de inductieve vertekeningen in DP-gebaseerde eerlijke leeralgoritmen en de debiasing-effecten van de voorgestelde SA-DRO-methode.
1 Inleiding
Een verantwoorde inzet van moderne machine learning frameworks in besluitvormingstaken met hoge inzet vereist mechanismen voor het controleren van de afhankelijkheid van hun output van gevoelige kenmerken zoals geslacht en etniciteit. Een supervised learning framework zonder controle over de afhankelijkheid van de voorspelling van de invoerkenmerken zou kunnen leiden tot discriminerende beslissingen die significant correleren met de gevoelige kenmerken. Vanwege het cruciale belang van de eerlijkheidsfactor in verschillende machine learning-toepassingen, hebben de studie en ontwikkeling van eerlijke statistische leeralgoritmen veel aandacht gekregen in de literatuur.



Om de vertekeningen van DP-gebaseerde leeralgoritmen te verminderen, stellen we een gevoelige attribuutgebaseerde distributief robuuste optimalisatiemethode (SA-DRO) voor, waarbij de eerlijke leerling het worst-case DP-geregulariseerde verlies minimaliseert over een set gevoelige attribuut marginale distributies die gecentreerd zijn rond de data-gebaseerde marginale distributie. Als gevolg hiervan kan de SA-DRO-benadering rekening houden met verschillende frequenties van de gevoelige attribuutuitkomsten en zo een robuust gedrag bieden voor de veranderingen in de meerderheidsuitkomst van het gevoelige attribuut.
We presenteren de resultaten van verschillende numerieke experimenten over de mogelijke vertekeningen van DDP-gebaseerde eerlijke classificatiemethodologieën voor het gevoelige kenmerk dat de meerderheid in de dataset bezit. Onze empirische bevindingen zijn consistent met de theoretische resultaten, wat suggereert dat de inductieve vertekeningen van DP-gebaseerde eerlijke classificatieregels richting de gevoelige kenmerk-gebaseerde meerderheidsgroep zijn. Aan de andere kant geven onze resultaten aan dat de DRO-SA-gebaseerde eerlijke leermethode resulteert in eerlijke classificatieregels met een lagere vertekening richting de labelverdeling onder het meerderheidsgevoelige kenmerk.
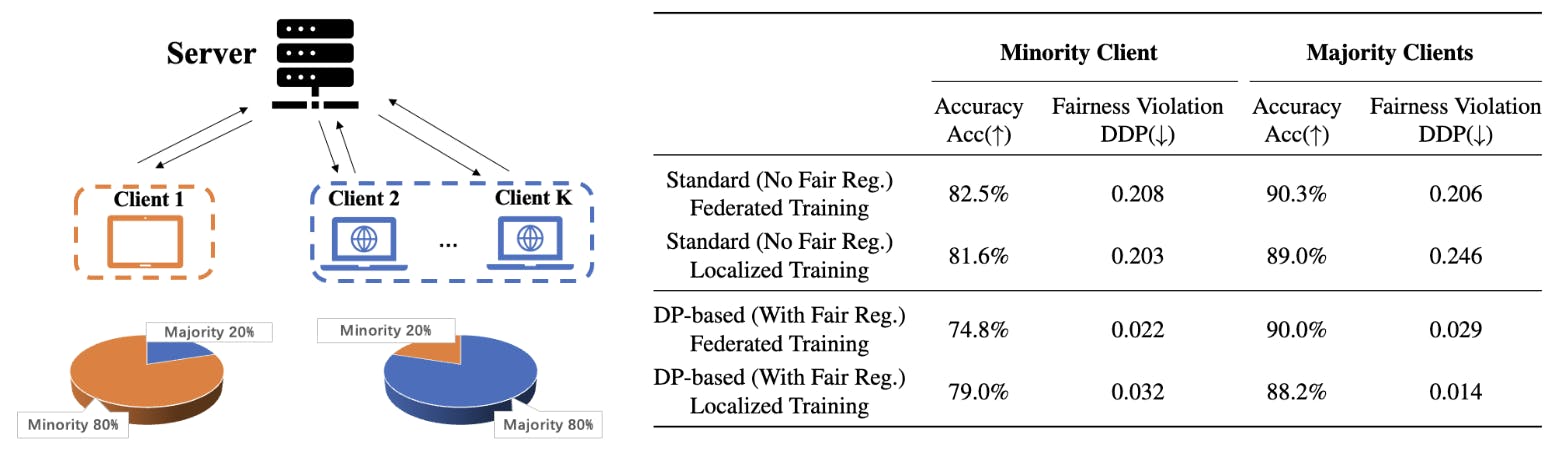
Bovendien analyseren we, om de impact van dergelijke inductieve vertekeningen in de praktijk te laten zien, de eerlijke classificatietaak in een federatieve leercontext waarin meerdere cliënten proberen een gedecentraliseerd model te trainen. We richten ons op een setting met heterogene gevoelige attribuutverdelingen over cliënten waarbij de meerderheidsgevoelige attribuutuitkomst van de cliënten mogelijk niet overeenkomt. Afbeelding 1 illustreert een dergelijk federatief leerscenario over de Adult-dataset, waarbij het meerderheidsgevoelige attribuut van cliënt 1 (vrouwelijke steekproeven) verschilt van de meerderheidsgroep van het netwerk (mannelijke steekproeven), en bijgevolg de testnauwkeurigheid van cliënt 1 met een DP-gebaseerd eerlijk federatief leren aanzienlijk lager is dan de testnauwkeurigheid van een gelokaliseerd eerlijk model dat alleen is getraind op de gegevens van cliënt 1. Dergelijke numerieke resultaten stellen de prikkel van de cliënt om deel te nemen aan eerlijk federatief leren ter discussie. Hieronder volgt een samenvatting van de belangrijkste bijdragen van dit werk:
• Analytisch bestuderen van de vooroordelen van DP-gebaseerd eerlijk leren ten opzichte van het meerderheidsgevoelige kenmerk,
• Het voorstellen van een distributief robuuste optimalisatiemethode om de vertekeningen van DP-gebaseerde eerlijke classificatie te verminderen,
• Het leveren van numerieke resultaten over de vertekeningen van DP-gebaseerd eerlijk leren in gecentraliseerde en gefedereerde leerscenario's.
2 Gerelateerde werken
Fairness Violation Metrics. In dit werk richten we ons op de leerkaders die gericht zijn op demografische pariteit (DP). Omdat het afdwingen van DP om strikt te houden kostbaar en schadelijk kan zijn voor de prestaties van de leerling, heeft de literatuur over machine learning voorgesteld om verschillende metrieken toe te passen om de afhankelijkheid tussen willekeurige variabelen te beoordelen, waaronder: de wederzijdse informatie: [3–7], Pearson-correlatie [8, 9], kernel-gebaseerde maximale gemiddelde discrepantie: [10], kernel-dichtheidsschatting van het verschil van demografische pariteit (DDP) -metingen [11], de maximale correlatie [12–15] en de exponentiële Renyi-wederzijdse informatie [16]. In onze analyse richten we ons voornamelijk op een DDP-gebaseerd eerlijk regularisatieschema, terwijl we alleen zwakkere versies van de inductieve vertekeningen laten zien die verder kunnen gelden in het geval van wederzijdse informatie en op maximale correlatie gebaseerde eerlijke leeralgoritmen.


Eerlijke classificatiealgoritmen. Eerlijke machine learning-algoritmen kunnen worden ingedeeld in drie hoofdcategorieën: pre-processing, post-processing en in-processing. Pre-processing-algoritmen [17–19] transformeren bevooroordeelde datakenmerken in een nieuwe ruimte waarin labels en gevoelige kenmerken statistisch onafhankelijk zijn. Post-processing-methoden zoals [2, 20] zijn erop gericht de discriminerende impact van een classificator te verminderen door de uiteindelijke beslissing ervan te wijzigen. De focus van ons werk ligt alleen op in-processing-benaderingen die het trainingsproces regulariseren richting DP-gebaseerde eerlijke modellen. Ook stellen [21–23] distributioneel robuuste optimalisatie (DRO) voor voor eerlijke classificatie voor; echter, in tegenstelling tot onze methode, passen deze werken geen DRO toe op de gevoelige kenmerkdistributie om de vertekeningen te verminderen.
vereenvoudigen
Dit artikel is beschikbaar op arxiv onder de CC BY-NC-SA 4.0 DEED-licentie.
Auteurs:
(1) Haoyu LEI, afdeling computerwetenschappen en -techniek, Chinese Universiteit van Hong Kong ([email protected]);
(2) Amin Gohari, afdeling Informatietechnologie, Chinese Universiteit van Hong Kong ([email protected]);
(3) Farzan Farnia, afdeling computerwetenschappen en -techniek, Chinese Universiteit van Hong Kong ([email protected]).




