






















Taula d'enllaços
3 Preliminars
3.1 Aprenentatge Supervisat Just i 3.2 Criteris d'Equitat
3.3 Mesures de dependència per a un aprenentatge just i supervisat
4 biaixos inductius de l'aprenentatge just i supervisat basat en el PD
4.1 Ampliació dels resultats teòrics a la regla de predicció aleatòria
5 Un enfocament d'optimització distribucionalment robust per a l'aprenentatge just basat en el PD
6 Resultats numèrics
6.2 Biaixos inductius de models formats en aprenentatge just basat en DP
6.3 Classificació justa basada en DP en aprenentatge federat heterogeni
Apèndix B Resultats addicionals per al conjunt de dades d'imatges
Resum
Els algorismes d'aprenentatge supervisat just que assignen etiquetes amb poca dependència d'un atribut sensible han cridat una gran atenció a la comunitat d'aprenentatge automàtic. Tot i que la noció de paritat demogràfica (DP) s'ha utilitzat amb freqüència per mesurar l'equitat d'un model en la formació de classificadors justos, diversos estudis de la literatura suggereixen impactes potencials de l'aplicació de la DP en algorismes d'aprenentatge just. En aquest treball, estudiem analíticament l'efecte dels mètodes de regularització estàndard basats en DP sobre la distribució condicional de l'etiqueta prevista donat l'atribut sensible. La nostra anàlisi mostra que un conjunt de dades d'entrenament desequilibrat amb una distribució no uniforme de l'atribut sensible podria conduir a una regla de classificació esbiaixada cap al resultat de l'atribut sensible que conté la majoria de les dades d'entrenament. Per controlar aquests biaixos inductius en l'aprenentatge just basat en DP, proposem un mètode d'optimització distributiva robusta basat en atributs sensibles (SA-DRO) que millora la robustesa davant la distribució marginal de l'atribut sensible. Finalment, presentem diversos resultats numèrics sobre l'aplicació de mètodes d'aprenentatge basats en DP a problemes estàndard d'aprenentatge centralitzat i distribuït. Les troballes empíriques donen suport als nostres resultats teòrics sobre els biaixos inductius en algorismes d'aprenentatge just basats en DP i els efectes de desbiaització del mètode SA-DRO proposat.
1 Introducció
Un desplegament responsable de marcs moderns d'aprenentatge automàtic en tasques de presa de decisions d'alt risc requereix mecanismes per controlar la dependència de la seva producció d'atributs sensibles com el gènere i l'ètnia. Un marc d'aprenentatge supervisat sense control sobre la dependència de la predicció de les característiques d'entrada podria conduir a decisions discriminatòries que es correlacionin significativament amb els atributs sensibles. A causa de la importància crítica del factor d'equitat en diverses aplicacions d'aprenentatge automàtic, l'estudi i el desenvolupament d'algoritmes d'aprenentatge estadístic just han rebut una gran atenció a la literatura.



Per reduir els biaixos dels algorismes d'aprenentatge basats en DP, proposem un mètode d'optimització distributiva robusta basat en atributs sensibles (SA-DRO) on l'aprenent just minimitza la pèrdua regularitzada per DP en el pitjor dels casos sobre un conjunt de distribucions marginals d'atributs sensibles centrades al voltant de la distribució marginal basada en dades. Com a resultat, l'enfocament SA-DRO pot tenir en compte diferents freqüències dels resultats de l'atribut sensible i, per tant, oferir un comportament robust als canvis en el resultat majoritari de l'atribut sensible.
Presentem els resultats de diversos experiments numèrics sobre els biaixos potencials de les metodologies de classificació justa basades en DDP a l'atribut sensible que té la majoria en el conjunt de dades. Les nostres troballes empíriques són coherents amb els resultats teòrics, cosa que suggereix els biaixos inductius de les regles de classificació justa basades en DP cap al grup majoritari sensible basat en atributs. D'altra banda, els nostres resultats indiquen que el mètode d'aprenentatge just basat en DRO-SA dóna lloc a regles de classificació justes amb un biaix més baix cap a la distribució de l'etiqueta sota l'atribut sensible majoritari.
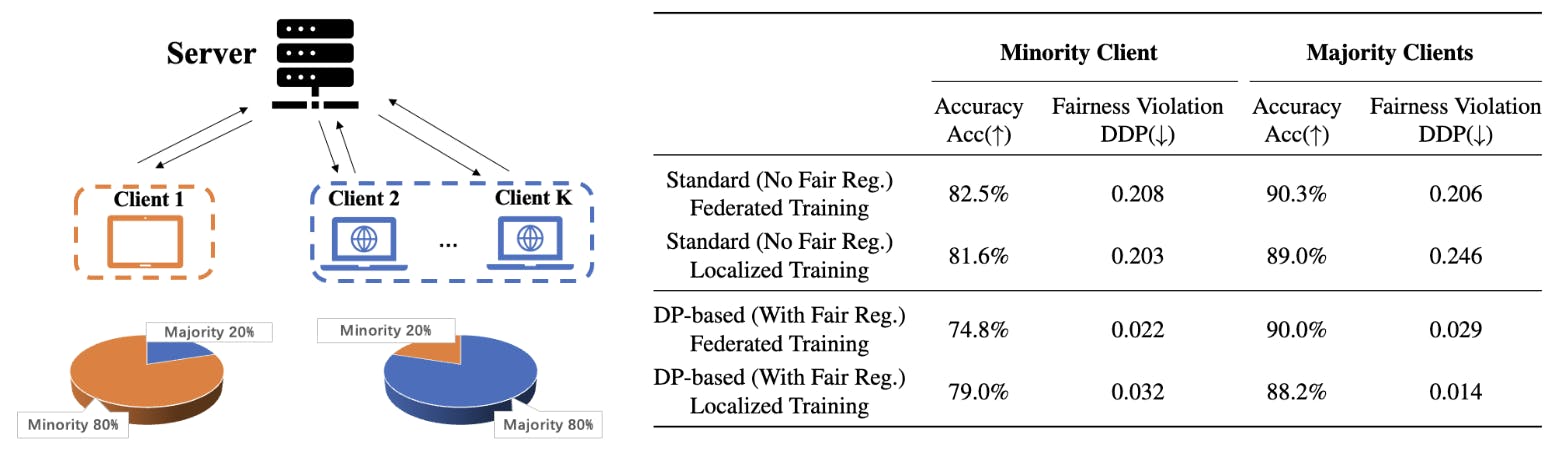
A més, per mostrar els impactes d'aquests biaixos inductius a la pràctica, analitzem la tasca de classificació justa en un context d'aprenentatge federat on diversos clients intenten entrenar un model descentralitzat. Ens centrem en un entorn amb distribucions heterogènies d'atributs sensibles entre clients on el resultat d'atributs sensibles majoritari dels clients pot no coincidir. La figura 1 il·lustra aquest escenari d'aprenentatge federat sobre el conjunt de dades d'adults, on l'atribut sensible majoritari del client 1 (mostres femenines) és diferent del grup majoritari de la xarxa (mostres masculines) i, per tant, la precisió de la prova del client 1 amb un aprenentatge federat just basat en DP és significativament inferior a la precisió de la prova d'un model de tren just localitzat només en dades del client 1. Aquests resultats numèrics qüestionen l'incentiu del client per participar en un aprenentatge federat just. A continuació es mostra un resum de les principals aportacions d'aquest treball:
• Estudiant analíticament els biaixos de l'aprenentatge just basat en el PD cap a l'atribut sensible a la majoria.
• Proposar un mètode d'optimització distributivament robust per reduir els biaixos de la classificació justa basada en DP,
• Proporcionar resultats numèrics sobre els biaixos de l'aprenentatge just basat en el PD en escenaris d'aprenentatge centralitzat i federat.
2 Obres relacionades
Mètriques de violació d'equitat. En aquest treball, ens centrem en els marcs d'aprenentatge que tenen com a objectiu la paritat demogràfica (PD). Com que obligar a DP a mantenir estrictament podria ser costós i perjudicial per al rendiment de l'alumne, la literatura d'aprenentatge automàtic ha proposat aplicar diverses mètriques per avaluar la dependència entre variables aleatòries, com ara: la informació mútua: [3–7], correlació de Pearson [8, 9], discrepància mitjana màxima basada en el nucli: [10] diferencia demogràfica de l'estimació de la diferència demogràfica, (DDP) mesures [11], la correlació màxima [12–15] i la informació mútua exponencial de Renyi [16]. En la nostra anàlisi, ens centrem principalment en un esquema de regularització just basat en DDP, mentre que només mostrem que les versions més febles dels biaixos inductius podrien mantenir-se encara més en el cas de la informació mútua i els algorismes d'aprenentatge just basats en la correlació màxima.


Algoritmes de classificació justos. Els algorismes d'aprenentatge automàtic just es poden classificar en tres categories principals: preprocessament, postprocessament i en procés. Els algorismes de preprocessament [17–19] transformen les característiques de dades esbiaixades en un nou espai on les etiquetes i els atributs sensibles són estadísticament independents. Els mètodes de postprocessament com [2, 20] pretenen alleujar l'impacte discriminatori d'un classificador modificant la seva decisió final. L'enfocament del nostre treball es centra només en els enfocaments en procés de regularització del procés de formació cap a models de fira basats en DP. A més, [21–23] proposen una optimització distributiva robusta (DRO) per a una classificació justa; tanmateix, a diferència del nostre mètode, aquests treballs no apliquen DRO a la distribució d'atributs sensibles per reduir els biaixos.
simplificar
Aquest document està disponible a arxiv sota la llicència CC BY-NC-SA 4.0 DEED.
Autors:
(1) Haoyu LEI, Departament d'Informàtica i Enginyeria de la Universitat Xinesa de Hong Kong ([email protected]);
(2) Amin Gohari, Departament d'Enginyeria de la Informació de la Universitat Xinesa de Hong Kong ([email protected]);
(3) Farzan Farnia, Departament d'Informàtica i Enginyeria de la Universitat Xinesa de Hong Kong ([email protected]).








