






















Tabla de enlaces
3 Preliminares
3.1 Aprendizaje supervisado justo y 3.2 Criterios de imparcialidad
3.3 Medidas de dependencia para un aprendizaje supervisado justo
4 sesgos inductivos del aprendizaje supervisado justo basado en PD
4.1 Extensión de los resultados teóricos a la regla de predicción aleatoria
5 Un enfoque de optimización distributivamente robusta para el aprendizaje justo basado en PD
6 Resultados numéricos
6.1 Configuración experimental
6.2 Sesgos inductivos de los modelos entrenados en el aprendizaje justo basado en PD
6.3 Clasificación justa basada en DP en el aprendizaje federado heterogéneo
Apéndice B Resultados adicionales para el conjunto de datos de imágenes
Abstracto
Los algoritmos de aprendizaje supervisado justos que asignan etiquetas con poca dependencia de un atributo sensible han atraído gran atención en la comunidad del aprendizaje automático. Si bien el concepto de paridad demográfica (PD) se ha utilizado con frecuencia para medir la imparcialidad de un modelo al entrenar clasificadores justos, varios estudios en la literatura sugieren los posibles impactos de aplicar PD en algoritmos de aprendizaje justo. En este trabajo, estudiamos analíticamente el efecto de los métodos de regularización estándar basados en PD en la distribución condicional de la etiqueta predicha dado el atributo sensible. Nuestro análisis muestra que un conjunto de datos de entrenamiento desequilibrado con una distribución no uniforme del atributo sensible podría generar una regla de clasificación sesgada hacia el resultado del atributo sensible que contiene la mayoría de los datos de entrenamiento. Para controlar estos sesgos inductivos en el aprendizaje justo basado en PD, proponemos un método de optimización distribucionalmente robusta basada en atributos sensibles (SA-DRO) que mejora la robustez frente a la distribución marginal del atributo sensible. Finalmente, presentamos varios resultados numéricos sobre la aplicación de métodos de aprendizaje basados en PD a problemas estándar de aprendizaje centralizado y distribuido. Los hallazgos empíricos respaldan nuestros resultados teóricos sobre los sesgos inductivos en los algoritmos de aprendizaje justo basados en DP y los efectos de eliminación de sesgos del método SA-DRO propuesto.
1 Introducción
Una implementación responsable de marcos modernos de aprendizaje automático en tareas de toma de decisiones de alto impacto requiere mecanismos para controlar la dependencia de sus resultados con respecto a atributos sensibles como el género y la etnia. Un marco de aprendizaje supervisado sin control sobre la dependencia de la predicción con respecto a las características de entrada podría conducir a decisiones discriminatorias con una correlación significativa con los atributos sensibles. Debido a la importancia crucial del factor de equidad en diversas aplicaciones de aprendizaje automático, el estudio y desarrollo de algoritmos de aprendizaje estadístico justos han recibido gran atención en la literatura.



Para reducir los sesgos de los algoritmos de aprendizaje basados en PD, proponemos un método de optimización robusta distribucional basada en atributos sensibles (SA-DRO), donde el aprendiz justo minimiza la pérdida regularizada por PD en el peor de los casos sobre un conjunto de distribuciones marginales de atributos sensibles centradas en la distribución marginal basada en datos. Como resultado, el enfoque SA-DRO puede considerar diferentes frecuencias de los resultados de los atributos sensibles y, por lo tanto, ofrecer un comportamiento robusto ante los cambios en el resultado mayoritario del atributo sensible.
Presentamos los resultados de varios experimentos numéricos sobre los posibles sesgos de las metodologías de clasificación justa basadas en DDP hacia el atributo sensible mayoritario en el conjunto de datos. Nuestros hallazgos empíricos concuerdan con los resultados teóricos, lo que sugiere sesgos inductivos de las reglas de clasificación justa basadas en DP hacia el grupo mayoritario basado en atributos sensibles. Por otro lado, nuestros resultados indican que el método de aprendizaje justo basado en DRO-SA genera reglas de clasificación justa con un menor sesgo hacia la distribución de etiquetas bajo el atributo sensible mayoritario.
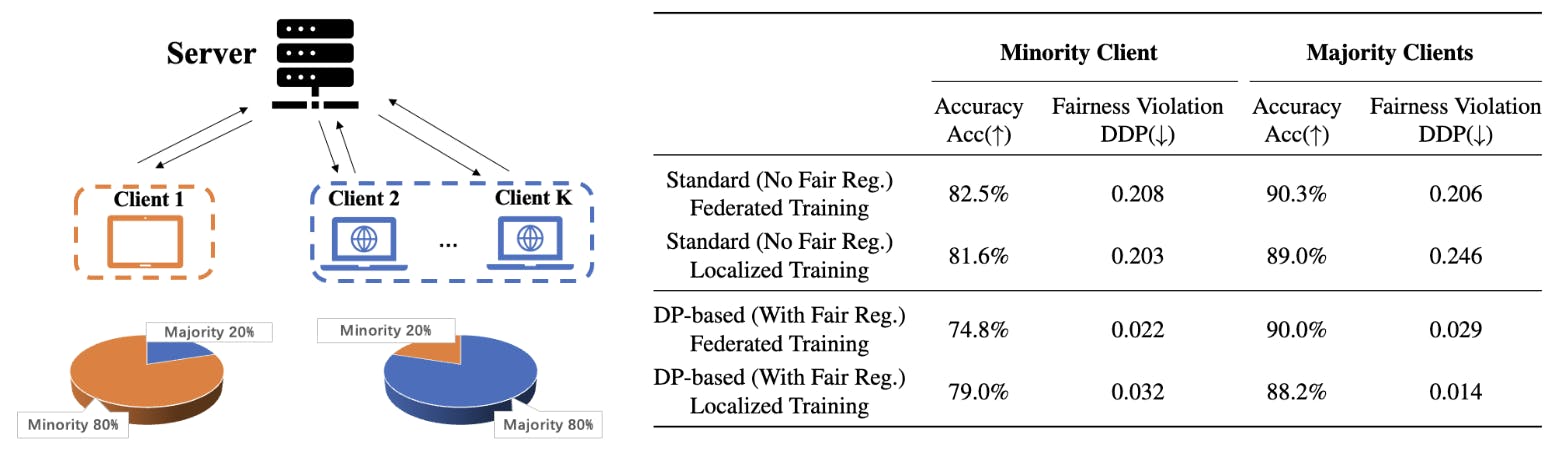
Además, para mostrar el impacto de estos sesgos inductivos en la práctica, analizamos la tarea de clasificación justa en un contexto de aprendizaje federado donde varios clientes intentan entrenar un modelo descentralizado. Nos centramos en un entorno con distribuciones heterogéneas de atributos sensibles entre los clientes, donde el resultado de los atributos sensibles mayoritarios de los clientes puede no coincidir. La Figura 1 ilustra este escenario de aprendizaje federado sobre el conjunto de datos Adultos, donde el atributo sensible mayoritario del Cliente 1 (muestras femeninas) es diferente del grupo mayoritario de la red (muestras masculinas) y, en consecuencia, la precisión de la prueba del Cliente 1 con un aprendizaje federado justo basado en PD es significativamente menor que la precisión de la prueba de un modelo justo localizado entrenado únicamente con los datos del Cliente 1. Estos resultados numéricos cuestionan el incentivo del cliente para participar en el aprendizaje federado justo. A continuación, se presenta un resumen de las principales contribuciones de este trabajo:
• Estudiar analíticamente los sesgos del aprendizaje justo basado en el PD hacia el atributo sensible a la mayoría,
• Proponer un método de optimización distributivamente robusto para reducir los sesgos de la clasificación justa basada en DP,
• Proporcionar resultados numéricos sobre los sesgos del aprendizaje justo basado en el PD en escenarios de aprendizaje centralizado y federado.
2 obras relacionadas
Métricas de Violación de Equidad. En este trabajo, nos enfocamos en los marcos de aprendizaje que apuntan hacia la paridad demográfica (PD). Dado que imponer un cumplimiento estricto de la PD podría ser costoso y perjudicial para el desempeño del estudiante, la literatura de aprendizaje automático ha propuesto aplicar varias métricas que evalúan la dependencia entre variables aleatorias, incluyendo: la información mutua: [3–7], la correlación de Pearson [8, 9], la discrepancia media máxima basada en kernel: [10], la estimación de densidad kernel de la diferencia de medidas de paridad demográfica (DDP) [11], la correlación máxima [12–15] y la información mutua exponencial de Renyi [16]. En nuestro análisis, nos enfocamos principalmente en un esquema de regularización justa basado en DDP, mientras que mostramos que solo versiones más débiles de los sesgos inductivos podrían mantenerse en el caso de algoritmos de aprendizaje justo basados en información mutua y correlación máxima.


Algoritmos de Clasificación Justa. Los algoritmos de aprendizaje automático justos se pueden clasificar en tres categorías principales: preprocesamiento, posprocesamiento y procesamiento interno. Los algoritmos de preprocesamiento [17-19] transforman las características de datos sesgadas en un nuevo espacio donde las etiquetas y los atributos sensibles son estadísticamente independientes. Los métodos de posprocesamiento, como [2, 20], buscan mitigar el impacto discriminatorio de un clasificador modificando su decisión final. Nuestro trabajo se centra únicamente en los enfoques de procesamiento interno que regularizan el proceso de entrenamiento hacia modelos justos basados en DP. Asimismo, [21-23] proponen una optimización robusta a la distribución (DRO) para una clasificación justa; sin embargo, a diferencia de nuestro método, estos trabajos no aplican DRO a la distribución de atributos sensibles para reducir los sesgos.
Simplificar
Este artículo está disponible en arxiv bajo la licencia CC BY-NC-SA 4.0 DEED.
Autores:
(1) Haoyu LEI, Departamento de Ciencias de la Computación e Ingeniería, Universidad China de Hong Kong ([email protected]);
(2) Amin Gohari, Departamento de Ingeniería de la Información, Universidad China de Hong Kong ([email protected]);
(3) Farzan Farnia, Departamento de Ciencias de la Computación e Ingeniería, Universidad China de Hong Kong ([email protected]).








