






















Հղումների աղյուսակ
3 Նախնական
3.1 Արդար վերահսկվող ուսուցում և 3.2 Արդարության չափանիշներ
3.3 Կախվածության միջոցառումներ արդար վերահսկվող ուսուցման համար
DP-ի վրա հիմնված արդար վերահսկվող ուսուցման 4 ինդուկտիվ կողմնակալություն
4.1 Տեսական արդյունքների ընդլայնում պատահական կանխատեսման կանոնին
5 Բաշխման առումով կայուն օպտիմալացման մոտեցում DP-ի վրա հիմնված արդար ուսուցման համար
6 Թվային արդյունքներ
6.3 DP-ի վրա հիմնված արդար դասակարգում տարասեռ դաշնային ուսուցման մեջ
Հավելված B Լրացուցիչ արդյունքներ պատկերների տվյալների հավաքածուի համար
Վերացական
Արդար վերահսկվող ուսուցման ալգորիթմները, որոնք պիտակներ են հատկացնում զգայուն հատկանիշից քիչ կախվածությամբ, մեծ ուշադրություն են գրավել մեքենայական ուսուցման համայնքում: Թեև ժողովրդագրական հավասարության (DP) հասկացությունը հաճախ օգտագործվում է արդար դասակարգիչների պատրաստման մոդելի արդարությունը չափելու համար, գրականության մի քանի ուսումնասիրություններ ցույց են տալիս արդար ուսուցման ալգորիթմներում DP կիրառման հնարավոր ազդեցությունները: Այս աշխատանքում մենք վերլուծական կերպով ուսումնասիրում ենք DP-ի վրա հիմնված կանոնավորացման ստանդարտ մեթոդների ազդեցությունը կանխատեսված պիտակի պայմանական բաշխման վրա՝ հաշվի առնելով զգայուն հատկանիշը: Մեր վերլուծությունը ցույց է տալիս, որ ուսուցման անհավասարակշռված տվյալների բազան՝ զգայուն հատկանիշի ոչ միասնական բաշխմամբ, կարող է հանգեցնել դասակարգման կանոնի, որը կողմնակալ է դեպի զգայուն հատկանիշի արդյունքը, որը պարունակում է վերապատրաստման տվյալների մեծ մասը: DP-ի վրա հիմնված արդար ուսուցման մեջ նման ինդուկտիվ կողմնակալությունները վերահսկելու համար մենք առաջարկում ենք զգայուն հատկանիշի վրա հիմնված բաշխման կայուն օպտիմալացման մեթոդ (SA-DRO), որը բարելավում է կայունությունը զգայուն հատկանիշի սահմանային բաշխման նկատմամբ: Վերջապես, մենք ներկայացնում ենք մի քանի թվային արդյունքներ DP-ի վրա հիմնված ուսուցման մեթոդների կիրառման վերաբերյալ ստանդարտ կենտրոնացված և բաշխված ուսուցման խնդիրներում: Էմպիրիկ բացահայտումները հաստատում են մեր տեսական արդյունքները DP-ի վրա հիմնված արդար ուսուցման ալգորիթմների ինդուկտիվ կողմնակալության և առաջարկվող SA-DRO մեթոդի շեղման հետևանքների վերաբերյալ:
1 Ներածություն
Ժամանակակից մեքենայական ուսուցման շրջանակների պատասխանատու տեղակայումը որոշումների կայացման բարձրագույն առաջադրանքներում պահանջում է մեխանիզմներ՝ վերահսկելու դրանց արդյունքի կախվածությունը զգայուն հատկանիշներից, ինչպիսիք են սեռը և էթնիկ պատկանելությունը: Վերահսկվող ուսուցման շրջանակը, որը չի վերահսկում կանխատեսման կախվածությունը մուտքային հատկանիշներից, կարող է հանգեցնել խտրական որոշումների, որոնք զգալիորեն փոխկապակցված են զգայուն հատկանիշների հետ: Հաշվի առնելով մեքենայական ուսուցման մի քանի հավելվածներում արդարության գործոնի կարևոր նշանակությունը՝ արդար վիճակագրական ուսուցման ալգորիթմների ուսումնասիրությունն ու զարգացումը մեծ ուշադրության են արժանացել գրականության մեջ:



DP-ի վրա հիմնված ուսուցման ալգորիթմների շեղումները նվազեցնելու համար մենք առաջարկում ենք զգայուն հատկանիշի վրա հիմնված բաշխման կայուն օպտիմալացում (SA-DRO) մեթոդ, որտեղ արդար սովորողը նվազագույնի է հասցնում DP-ով կանոնավորվող վատագույն կորուստը զգայուն հատկանիշի սահմանային բաշխումների մի շարքի նկատմամբ, որոնք կենտրոնացած են տվյալների վրա հիմնված սահմանային բաշխման շուրջ: Արդյունքում SA-DRO մոտեցումը կարող է հաշվի առնել զգայուն հատկանիշի արդյունքների տարբեր հաճախականություններ և այդպիսով առաջարկել կայուն վարքագիծ զգայուն հատկանիշի մեծամասնության արդյունքի փոփոխությունների նկատմամբ:
Մենք ներկայացնում ենք մի քանի թվային փորձերի արդյունքներ DDP-ի վրա հիմնված արդար դասակարգման մեթոդոլոգիաների պոտենցիալ շեղումների վերաբերյալ այն զգայուն հատկանիշին, որն ունի տվյալների բազայի մեծամասնությունը: Մեր էմպիրիկ բացահայտումները համահունչ են տեսական արդյունքներին, որոնք ենթադրում են DP-ի վրա հիմնված արդար դասակարգման կանոնների ինդուկտիվ կողմնակալությունը զգայուն ատրիբուտների վրա հիմնված մեծամասնության խմբի նկատմամբ: Մյուս կողմից, մեր արդյունքները ցույց են տալիս, որ DRO-SA-ի վրա հիմնված արդար ուսուցման մեթոդը հանգեցնում է արդար դասակարգման կանոնների՝ մեծամասնության զգայուն հատկանիշի ներքո պիտակի բաշխման նկատմամբ ավելի ցածր կողմնակալությամբ:
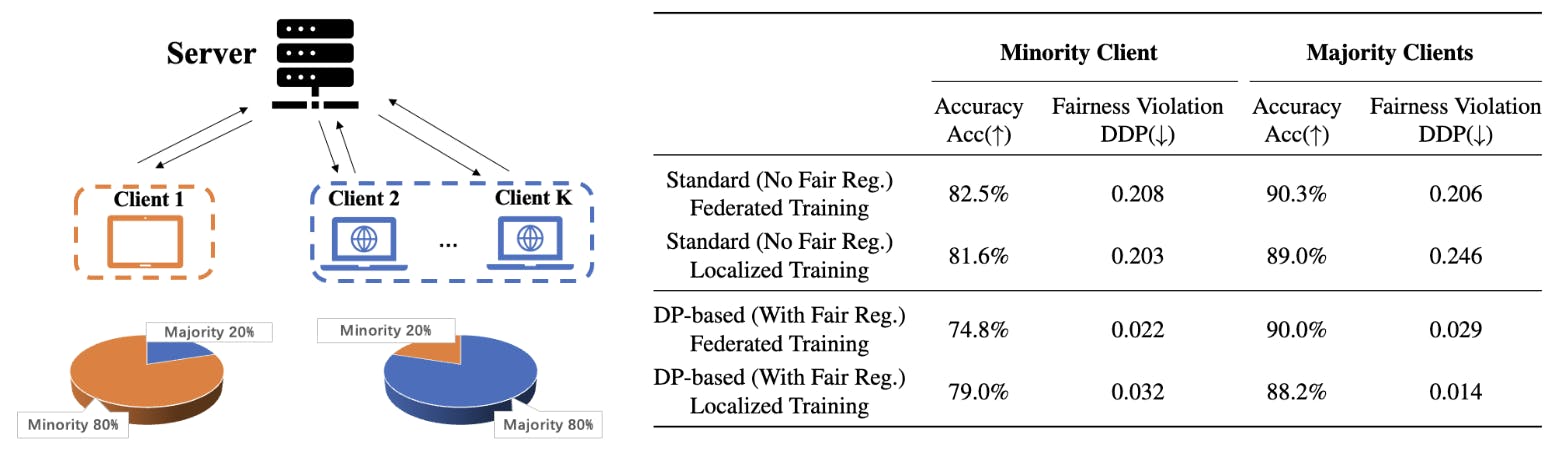
Ավելին, նման ինդուկտիվ կողմնակալությունների ազդեցությունը գործնականում ցույց տալու համար մենք վերլուծում ենք արդար դասակարգման առաջադրանքը դաշնային ուսուցման համատեքստում, որտեղ բազմաթիվ հաճախորդներ փորձում են պատրաստել ապակենտրոնացված մոդել: Մենք կենտրոնանում ենք հաճախորդների միջև տարասեռ զգայուն հատկանիշի բաշխումներով պարամետրի վրա, որտեղ հաճախորդների մեծամասնության զգայուն հատկանիշի արդյունքը կարող է չհամաձայնվել: Գծապատկեր 1-ը ցույց է տալիս նման դաշնային ուսուցման սցենարը Մեծահասակների տվյալների բազայում, որտեղ Հաճախորդ 1-ի մեծամասնության զգայուն հատկանիշը (իգական նմուշներ) տարբերվում է ցանցի մեծամասնության խմբից (տղամարդկանց նմուշներ), և, հետևաբար, Հաճախորդի 1-ի թեստի ճշգրտությունը DP-ի վրա հիմնված արդար դաշնային ուսուցման վրա էականորեն ցածր է տեղական ուսուցման վրա հիմնված ուսուցման արդարացիությունից: Նման թվային արդյունքները կասկածի տակ են դնում հաճախորդի դրդապատճառը` մասնակցելու արդար դաշնային ուսուցմանը: Ստորև ներկայացված է այս աշխատանքի հիմնական ներդրումների ամփոփագիրը.
• Վերլուծականորեն ուսումնասիրելով DP-ի վրա հիմնված արդար ուսուցման կողմնակալությունը մեծամասնության զգայուն հատկանիշի նկատմամբ,
• Բաշխման առումով կայուն օպտիմալացման մեթոդի առաջարկ՝ DP-ի վրա հիմնված արդար դասակարգման շեղումները նվազեցնելու համար,
• Կենտրոնացված և դաշնային ուսուցման սցենարներում DP-ի վրա հիմնված արդար ուսուցման կողմնակալության վերաբերյալ թվային արդյունքների տրամադրում:
2 Առնչվող աշխատանքներ
Արդարության խախտման չափումներ. Այս աշխատանքում մենք կենտրոնանում ենք ուսուցման շրջանակների վրա, որոնք ուղղված են ժողովրդագրական հավասարությանը (DP): Քանի որ DP խստորեն պահելը կարող է ծախսատար լինել և վնասել սովորողի կատարողականին, մեքենայական ուսուցման գրականությունն առաջարկել է կիրառել մի քանի չափումներ՝ գնահատելու կախվածությունը պատահական փոփոխականների միջև, ներառյալ՝ փոխադարձ տեղեկատվությունը՝ [3–7], Պիրսոնի հարաբերակցությունը [8, 9], միջուկի վրա հիմնված առավելագույն միջին անհամապատասխանության տարբերությունը՝ [10]: (DDP) չափում է [11], առավելագույն հարաբերակցությունը [12-15] և էքսպոնենցիալ Renyi փոխադարձ տեղեկատվություն [16]: Մեր վերլուծության մեջ մենք հիմնականում կենտրոնանում ենք DDP-ի վրա հիմնված արդար կանոնակարգման սխեմայի վրա, մինչդեռ մենք ցույց ենք տալիս, որ ինդուկտիվ կողմնակալությունների միայն թույլ տարբերակները կարող են շարունակվել փոխադարձ տեղեկատվության և առավելագույն հարաբերակցության վրա հիմնված արդար ուսուցման ալգորիթմների դեպքում:


Արդար դասակարգման ալգորիթմներ. Արդար մեքենայական ուսուցման ալգորիթմները կարելի է դասակարգել երեք հիմնական կատեգորիաների՝ նախնական մշակում, հետմշակում և վերամշակում: Նախամշակման ալգորիթմները [17-19] փոխակերպում են կողմնակալ տվյալների առանձնահատկությունները նոր տարածության մեջ, որտեղ պիտակները և զգայուն ատրիբուտները վիճակագրորեն անկախ են: Հետմշակման մեթոդները, ինչպիսիք են [2, 20], նպատակ ունեն մեղմել դասակարգչի խտրական ազդեցությունը՝ փոփոխելով նրա վերջնական որոշումը: Մեր աշխատանքի ուշադրության կենտրոնում են միայն վերամշակման մոտեցումները, որոնք կանոնակարգում են վերապատրաստման գործընթացը դեպի DP-ի վրա հիմնված արդար մոդելներ: Նաև, [21–23] առաջարկում է բաշխման առումով կայուն օպտիմալացում (DRO) արդար դասակարգման համար. սակայն, ի տարբերություն մեր մեթոդի, այս աշխատանքները չեն կիրառում DRO-ն զգայուն հատկանիշի բաշխման վրա՝ նվազեցնելու շեղումները:
պարզեցնել
Այս փաստաթուղթը հասանելի է arxiv-ում CC BY-NC-SA 4.0 DEED լիցենզիայի ներքո:
Հեղինակներ:
(1) Haoyu LEI, համակարգչային գիտության և ճարտարագիտության բաժին, Հոնկոնգի չինական համալսարան ([email protected]);
(2) Ամին Գոհարի, Հոնկոնգի Չինական համալսարանի տեղեկատվական ճարտարագիտության բաժին ([email protected]);
(3) Ֆարզան Ֆարնիա, Հոնկոնգի Չինական համալսարանի համակարգչային գիտության և ճարտարագիտության բաժին ([email protected]):








