






















Tabel Tautan
3 Pendahuluan
3.1 Pembelajaran Terbimbing yang Adil dan 3.2 Kriteria Keadilan
3.3 Ukuran Ketergantungan untuk Pembelajaran Terbimbing yang Adil
4 Bias Induktif Pembelajaran Terbimbing yang Adil Berbasis DP
4.1 Memperluas Hasil Teoritis ke Aturan Prediksi Acak
5 Pendekatan Optimasi Distribusi yang Kuat terhadap Pembelajaran Adil Berbasis DP
6 Hasil Numerik
6.2 Bias Induktif Model yang Dilatih dalam Pembelajaran Adil Berbasis DP
6.3 Klasifikasi Wajar Berbasis DP dalam Pembelajaran Terfederasi Heterogen
7 Kesimpulan dan Daftar Pustaka
Lampiran B Hasil Tambahan untuk Dataset Gambar
Abstrak
Algoritme pembelajaran terawasi yang adil yang menetapkan label dengan sedikit ketergantungan pada atribut sensitif telah menarik perhatian besar dalam komunitas pembelajaran mesin. Sementara gagasan paritas demografis (DP) telah sering digunakan untuk mengukur kewajaran model dalam melatih pengklasifikasi yang adil, beberapa studi dalam literatur menunjukkan dampak potensial dari menegakkan DP dalam algoritme pembelajaran yang adil. Dalam karya ini, kami secara analitis mempelajari efek metode regularisasi berbasis DP standar pada distribusi kondisional label yang diprediksi mengingat atribut sensitif. Analisis kami menunjukkan bahwa kumpulan data pelatihan yang tidak seimbang dengan distribusi atribut sensitif yang tidak seragam dapat menyebabkan aturan klasifikasi yang bias terhadap hasil atribut sensitif yang memegang sebagian besar data pelatihan. Untuk mengendalikan bias induktif tersebut dalam pembelajaran yang adil berbasis DP, kami mengusulkan metode optimisasi distribusi yang kuat (SA-DRO) berbasis atribut sensitif yang meningkatkan ketahanan terhadap distribusi marginal atribut sensitif. Akhirnya, kami menyajikan beberapa hasil numerik tentang penerapan metode pembelajaran berbasis DP pada masalah pembelajaran terpusat dan terdistribusi standar. Temuan empiris mendukung hasil teoritis kami mengenai bias induktif dalam algoritma pembelajaran adil berbasis DP dan efek debiasing dari metode SA-DRO yang diusulkan.
1 Pendahuluan
Penerapan kerangka kerja pembelajaran mesin modern yang bertanggung jawab dalam tugas-tugas pengambilan keputusan berisiko tinggi memerlukan mekanisme untuk mengendalikan ketergantungan output mereka pada atribut-atribut sensitif seperti jenis kelamin dan etnis. Kerangka kerja pembelajaran terbimbing tanpa kendali atas ketergantungan prediksi pada fitur-fitur input dapat menyebabkan keputusan-keputusan diskriminatif yang secara signifikan berkorelasi dengan atribut-atribut sensitif. Karena pentingnya faktor kewajaran dalam beberapa aplikasi pembelajaran mesin, studi dan pengembangan algoritma pembelajaran statistik yang adil telah mendapat perhatian besar dalam literatur.



Untuk mengurangi bias algoritma pembelajaran berbasis DP, kami mengusulkan metode optimisasi distribusional tangguh berbasis atribut sensitif (SA-DRO) di mana pembelajar wajar meminimalkan kerugian DP-regularized terburuk atas serangkaian distribusi marginal atribut sensitif yang berpusat di sekitar distribusi marginal berbasis data. Hasilnya, pendekatan SA-DRO dapat memperhitungkan frekuensi yang berbeda dari hasil atribut sensitif dan dengan demikian menawarkan perilaku tangguh terhadap perubahan dalam hasil mayoritas atribut sensitif.
Kami menyajikan hasil beberapa eksperimen numerik tentang potensi bias metodologi klasifikasi wajar berbasis DDP terhadap atribut sensitif yang memiliki mayoritas dalam kumpulan data. Temuan empiris kami konsisten dengan hasil teoritis, yang menunjukkan bias induktif aturan klasifikasi wajar berbasis DP terhadap kelompok mayoritas berbasis atribut sensitif. Di sisi lain, hasil kami menunjukkan bahwa metode pembelajaran wajar berbasis DRO-SA menghasilkan aturan klasifikasi wajar dengan bias yang lebih rendah terhadap distribusi label di bawah atribut sensitif mayoritas.
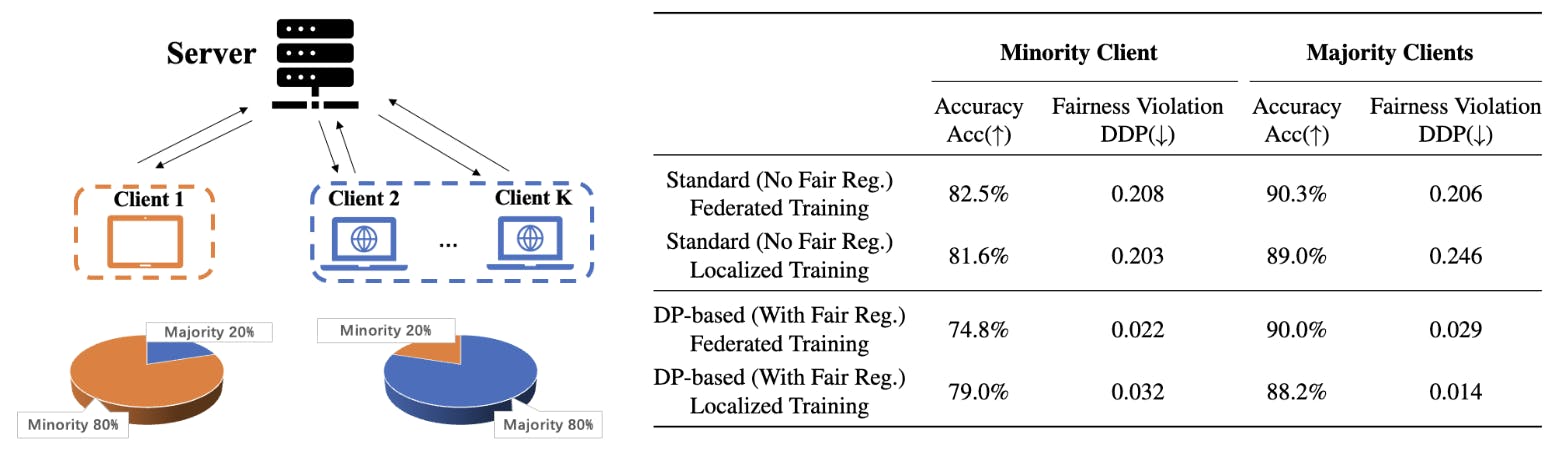
Lebih jauh, untuk menunjukkan dampak bias induktif tersebut dalam praktik, kami menganalisis tugas klasifikasi wajar dalam konteks pembelajaran terfederasi di mana beberapa klien mencoba melatih model yang terdesentralisasi. Kami fokus pada pengaturan dengan distribusi atribut sensitif yang heterogen di seluruh klien di mana hasil atribut sensitif mayoritas klien mungkin tidak sesuai. Gambar 1 mengilustrasikan skenario pembelajaran terfederasi tersebut pada kumpulan data Dewasa, di mana atribut sensitif mayoritas Klien 1 (sampel perempuan) berbeda dari kelompok mayoritas jaringan (sampel laki-laki), dan akibatnya, akurasi pengujian Klien 1 dengan pembelajaran terfederasi wajar berbasis DP secara signifikan lebih rendah daripada akurasi pengujian model wajar lokal yang hanya dilatih pada data Klien 1. Hasil numerik tersebut mempertanyakan insentif klien dalam berpartisipasi dalam pembelajaran terfederasi wajar. Berikut ini adalah ringkasan dari kontribusi utama karya ini:
• Secara analitis mempelajari bias pembelajaran adil berbasis DP terhadap atribut sensitif mayoritas,
• Mengusulkan metode optimasi distribusi yang kuat untuk menurunkan bias klasifikasi adil berbasis DP,
• Menyediakan hasil numerik tentang bias pembelajaran adil berbasis DP dalam skenario pembelajaran terpusat dan terfederasi.
2 Karya Terkait
Metrik Pelanggaran Kewajaran. Dalam karya ini, kami berfokus pada kerangka pembelajaran yang bertujuan menuju paritas demografi (DP). Karena menegakkan DP secara ketat dapat merugikan dan merusak kinerja pembelajar, literatur pembelajaran mesin telah mengusulkan penerapan beberapa metrik yang menilai ketergantungan antara variabel acak, termasuk: informasi bersama: [3–7], korelasi Pearson [8, 9], perbedaan rata-rata maksimum berbasis kernel: [10], estimasi kepadatan kernel dari ukuran perbedaan paritas demografi (DDP) [11], korelasi maksimal [12–15], dan informasi bersama Renyi eksponensial [16]. Dalam analisis kami, kami sebagian besar berfokus pada skema regularisasi wajar berbasis DDP, sementara kami hanya menunjukkan versi bias induktif yang lebih lemah yang dapat berlaku lebih lanjut dalam kasus algoritma pembelajaran wajar berbasis korelasi maksimal dan informasi bersama.


Algoritma Klasifikasi Wajar. Algoritma pembelajaran mesin yang wajar dapat diklasifikasikan ke dalam tiga kategori utama: pra-pemrosesan, pasca-pemrosesan, dan dalam-pemrosesan. Algoritma pra-pemrosesan [17–19] mengubah fitur data yang bias ke dalam ruang baru tempat label dan atribut sensitif bersifat independen secara statistik. Metode pasca-pemrosesan seperti [2, 20] bertujuan untuk mengurangi dampak diskriminatif dari pengklasifikasi dengan memodifikasi keputusan akhirnya. Fokus pekerjaan kami hanya pada pendekatan dalam-pemrosesan yang mengatur proses pelatihan menuju model wajar berbasis DP. Selain itu, [21–23] mengusulkan optimasi distribusi yang kuat (DRO) untuk klasifikasi yang wajar; namun, tidak seperti metode kami, karya-karya ini tidak menerapkan DRO pada distribusi atribut sensitif untuk mengurangi bias.
menyederhanakan
Makalah ini tersedia di arxiv di bawah lisensi CC BY-NC-SA 4.0 DEED.
Penulis:
(1) Haoyu LEI, Departemen Ilmu Komputer dan Teknik, Universitas Cina Hong Kong ([email protected]);
(2) Amin Gohari, Departemen Teknik Informasi, Universitas Cina Hong Kong ([email protected]);
(3) Farzan Farnia, Departemen Ilmu Komputer dan Teknik, Universitas Cina Hong Kong ([email protected]).








