






















Tabuľka odkazov
3 Prípravné zápasy
3.1 Spravodlivé vyučovanie pod dohľadom a 3.2 Kritériá spravodlivosti
3.3 Opatrenia závislosti pre spravodlivé vyučovanie pod dohľadom
4 Induktívne predsudky spravodlivého supervidovaného učenia založeného na RP
4.1 Rozšírenie teoretických výsledkov na pravidlo randomizovanej predikcie
5 Distribučne robustný optimalizačný prístup k spravodlivému vzdelávaniu založenému na RP
6 Číselné výsledky
6.2 Induktívne predsudky modelov trénovaných v spravodlivom učení založenom na RP
6.3 Spravodlivá klasifikácia založená na DP v heterogénnom federatívnom učení
Príloha B Ďalšie výsledky pre množinu údajov o obrázku
Abstraktné
Spravodlivé algoritmy učenia pod dohľadom, ktoré priraďujú štítky s malou závislosťou od citlivého atribútu, pritiahli veľkú pozornosť v komunite strojového učenia. Zatiaľ čo pojem demografická parita (DP) sa často používa na meranie spravodlivosti modelu pri školení spravodlivých klasifikátorov, niekoľko štúdií v literatúre naznačuje potenciálne vplyvy presadzovania RP v algoritmoch spravodlivého učenia. V tejto práci analyticky študujeme vplyv štandardných regularizačných metód založených na DP na podmienenú distribúciu predpovedaného označenia vzhľadom na citlivý atribút. Naša analýza ukazuje, že nevyvážená množina tréningových údajov s nerovnomernou distribúciou citlivého atribútu by mohla viesť k klasifikačnému pravidlu orientovanému na výsledok citlivého atribútu, ktorý obsahuje väčšinu tréningových údajov. Na kontrolu takýchto induktívnych skreslení v spravodlivom učení založenom na DP navrhujeme metódu citlivej distribučnej robustnej optimalizácie založenej na atribútoch (SA-DRO), ktorá zlepšuje odolnosť voči marginálnej distribúcii citlivého atribútu. Nakoniec uvádzame niekoľko numerických výsledkov o aplikácii metód učenia založených na DP na štandardné centralizované a distribuované problémy učenia. Empirické zistenia podporujú naše teoretické výsledky týkajúce sa induktívnych skreslení v algoritmoch spravodlivého učenia založených na DP a debiasingových efektoch navrhovanej metódy SA-DRO.
1 Úvod
Zodpovedné nasadenie moderných rámcov strojového učenia pri rozhodovacích úlohách s vysokým podielom vyžaduje mechanizmy na kontrolu závislosti ich výstupov od citlivých atribútov, akými sú pohlavie a etnická príslušnosť. Rámec učenia pod dohľadom bez kontroly závislosti predikcie na vstupných vlastnostiach by mohol viesť k diskriminačným rozhodnutiam, ktoré významne korelujú s citlivými atribútmi. Vzhľadom na kritický význam faktora spravodlivosti v niekoľkých aplikáciách strojového učenia sa v literatúre venovala veľká pozornosť štúdiu a vývoju spravodlivých štatistických algoritmov učenia.



Aby sme znížili zaujatosti algoritmov učenia založených na DP, navrhujeme metódu citlivej distribučnej robustnej optimalizácie založenej na atribútoch (SA-DRO), kde spravodlivý študent minimalizuje najhoršiu stratu regulovanú DP cez súbor citlivých marginálnych distribúcií sústredených okolo marginálnej distribúcie založenej na údajoch. Výsledkom je, že prístup SA-DRO môže zodpovedať za rôzne frekvencie výsledkov citlivých atribútov, a tak ponúkať robustné správanie k zmenám vo väčšinovom výsledku citlivého atribútu.
Uvádzame výsledky niekoľkých numerických experimentov o potenciálnych skresleniach metodológií spravodlivej klasifikácie založených na DDP voči citlivému atribútu, ktorý má väčšinu v súbore údajov. Naše empirické zistenia sú v súlade s teoretickými výsledkami, čo naznačuje induktívne skreslenie pravidiel spravodlivej klasifikácie založených na DP smerom k citlivej väčšinovej skupine založenej na atribútoch. Na druhej strane naše výsledky naznačujú, že metóda spravodlivého učenia založená na DRO-SA vedie k pravidlám spravodlivej klasifikácie s nižším sklonom k distribúcii označenia podľa atribútu citlivej väčšiny.
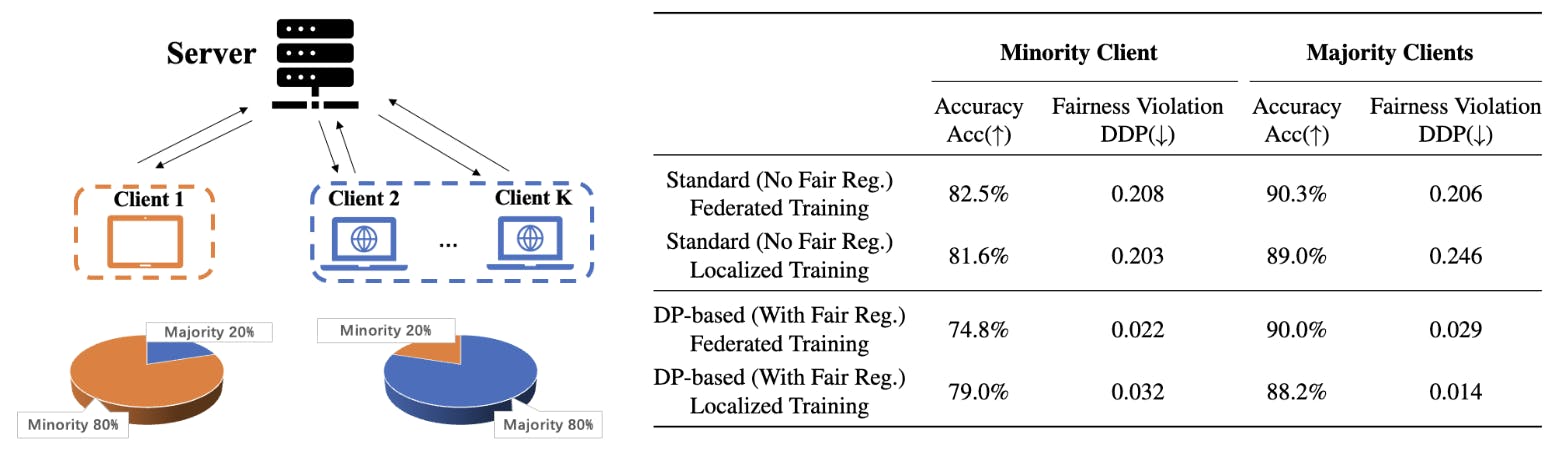
Okrem toho, aby sme ukázali dopady takýchto induktívnych skreslení v praxi, analyzujeme úlohu spravodlivej klasifikácie v kontexte federatívneho vzdelávania, kde sa viacerí klienti pokúšajú trénovať decentralizovaný model. Zameriavame sa na prostredie s heterogénnou distribúciou citlivých atribútov medzi klientmi, kde sa nemusia zhodovať výsledky s väčšinovo citlivými atribútmi klientov. Obrázok 1 ilustruje takýto scenár federatívneho učenia na množine údajov pre dospelých, kde sa väčšinový citlivý atribút klienta 1 (vzorky žien) líši od väčšinovej skupiny siete (vzorky mužov), a preto je presnosť testu klienta 1 s spravodlivým federatívnym učením založeným na DP výrazne nižšia ako presnosť testu lokalizovaného spravodlivého modelu trénovaného iba na údajoch klienta 1. Takéto číselné výsledky spochybňujú motiváciu klienta zúčastniť sa na spravodlivom federálnom vzdelávaní. Nasleduje súhrn hlavných príspevkov tejto práce:
• Analytické skúmanie predsudkov spravodlivého učenia založeného na RP smerom k atribútu citlivému na väčšinu,
• Navrhnutie distribučne robustnej optimalizačnej metódy na zníženie skreslenia spravodlivej klasifikácie založenej na DP,
• Poskytovanie numerických výsledkov o predsudkoch spravodlivého vzdelávania založeného na RP v centralizovaných a federatívnych vzdelávacích scenároch.
2 Súvisiace práce
Metriky porušenia spravodlivosti. V tejto práci sa zameriavame na vzdelávacie rámce zamerané na demografickú paritu (DP). Keďže vynútenie prísneho dodržiavania DP by mohlo byť nákladné a škodlivé pre výkon učiaceho sa, v literatúre o strojovom učení sa navrhlo použiť niekoľko metrík na hodnotenie závislosti medzi náhodnými premennými, vrátane: vzájomnej informácie: [3–7], Pearsonovej korelácie [8, 9], maximálnej priemernej diskrepancie založenej na jadre: [10], miery rozdielu v jadre (1 estim) maximálna korelácia [12–15] a exponenciálna vzájomná Renyiho informácia [16]. V našej analýze sa väčšinou zameriavame na schému spravodlivej regularizácie založenú na DDP, zatiaľ čo ukazujeme len slabšie verzie induktívnych skreslení, ktoré by mohli ďalej platiť v prípade vzájomných informácií a algoritmov spravodlivého učenia založených na maximálnej korelácii.


Spravodlivé klasifikačné algoritmy. Spravodlivé algoritmy strojového učenia možno rozdeliť do troch hlavných kategórií: predbežné spracovanie, následné spracovanie a priebežné spracovanie. Algoritmy predbežného spracovania [17–19] transformujú skreslené vlastnosti údajov do nového priestoru, kde sú štítky a citlivé atribúty štatisticky nezávislé. Metódy následného spracovania ako [2, 20] majú za cieľ zmierniť diskriminačný vplyv klasifikátora úpravou jeho konečného rozhodnutia. Ťažisko našej práce je len na prístupoch v procese regulácie tréningového procesu smerom k férovým modelom založeným na RP. [21–23] tiež navrhujú distribučne robustnú optimalizáciu (DRO) pre spravodlivú klasifikáciu; na rozdiel od našej metódy však tieto práce neaplikujú DRO na distribúciu citlivých atribútov, aby sa znížili odchýlky.
jednoduché
Tento dokument je dostupný na arxiv pod licenciou CC BY-NC-SA 4.0 DEED.
Autori:
(1) Haoyu LEI, Katedra počítačovej vedy a inžinierstva, Čínska univerzita v Hong Kongu ([email protected]);
(2) Amin Gohari, Katedra informačného inžinierstva, Čínska univerzita v Hong Kongu ([email protected]);
(3) Farzan Farnia, Katedra počítačovej vedy a inžinierstva, Čínska univerzita v Hong Kongu ([email protected]).








