






















Jadual Pautan
3 Pendahuluan
3.1 Pembelajaran Diawasi Adil dan 3.2 Kriteria Keadilan
3.3 Langkah-langkah Kebergantungan untuk Pembelajaran Diselia Adil
4 Bias Induktif Pembelajaran Diselia Adil berasaskan DP
4.1 Memperluaskan Keputusan Teori kepada Peraturan Ramalan Rawak
5 Pendekatan Pengoptimuman Teguh Agihan kepada Pembelajaran Adil berasaskan DP
6 Keputusan Berangka
6.2 Bias Induktif Model yang dilatih dalam Pembelajaran Adil berasaskan DP
6.3 Klasifikasi Adil berasaskan DP dalam Pembelajaran Bersekutu Heterogen
Lampiran B Keputusan Tambahan untuk Set Data Imej
Abstrak
Algoritma pembelajaran diselia adil yang memberikan label dengan sedikit pergantungan pada atribut sensitif telah menarik perhatian besar dalam komuniti pembelajaran mesin. Walaupun tanggapan pariti demografi (DP) telah kerap digunakan untuk mengukur kesaksamaan model dalam melatih pengelas adil, beberapa kajian dalam literatur mencadangkan potensi kesan penguatkuasaan DP dalam algoritma pembelajaran adil. Dalam kerja ini, kami mengkaji secara analitik kesan kaedah regularisasi berasaskan DP standard ke atas pengedaran bersyarat label yang diramalkan diberikan atribut sensitif. Analisis kami menunjukkan bahawa set data latihan yang tidak seimbang dengan taburan atribut sensitif yang tidak seragam boleh membawa kepada peraturan klasifikasi yang berat sebelah terhadap hasil atribut sensitif yang memegang majoriti data latihan. Untuk mengawal bias induktif sedemikian dalam pembelajaran saksama berasaskan DP, kami mencadangkan kaedah pengoptimuman teguh pengedaran (SA-DRO) berasaskan atribut sensitif yang meningkatkan keteguhan terhadap taburan marginal atribut sensitif. Akhir sekali, kami membentangkan beberapa keputusan berangka mengenai aplikasi kaedah pembelajaran berasaskan DP kepada masalah pembelajaran terpusat dan teragih standard. Penemuan empirikal menyokong keputusan teori kami tentang bias induktif dalam algoritma pembelajaran adil berasaskan DP dan kesan debiasing kaedah SA-DRO yang dicadangkan.
1 Pengenalan
Penggunaan rangka kerja pembelajaran mesin moden yang bertanggungjawab dalam tugasan membuat keputusan berkepentingan tinggi memerlukan mekanisme untuk mengawal pergantungan output mereka pada atribut sensitif seperti jantina dan etnik. Rangka kerja pembelajaran yang diselia tanpa kawalan ke atas pergantungan ramalan pada ciri input boleh membawa kepada keputusan diskriminasi yang berkait rapat dengan sifat sensitif. Disebabkan oleh kepentingan kritikal faktor keadilan dalam beberapa aplikasi pembelajaran mesin, kajian dan pembangunan algoritma pembelajaran statistik yang adil telah mendapat perhatian besar dalam literatur.



Untuk mengurangkan berat sebelah algoritma pembelajaran berasaskan DP, kami mencadangkan kaedah pengoptimuman teguh pengedaran berasaskan atribut sensitif (SA-DRO) di mana pelajar yang adil meminimumkan kerugian terkawal DP kes terburuk berbanding set pengedaran marginal atribut sensitif yang berpusat di sekitar pengedaran marginal berasaskan data. Akibatnya, pendekatan SA-DRO boleh mengambil kira frekuensi yang berbeza bagi hasil atribut sensitif dan dengan itu menawarkan tingkah laku yang mantap kepada perubahan dalam hasil majoriti atribut sensitif.
Kami membentangkan hasil beberapa eksperimen berangka mengenai potensi bias metodologi klasifikasi adil berasaskan DDP kepada atribut sensitif yang memiliki majoriti dalam dataset. Penemuan empirikal kami adalah konsisten dengan keputusan teori, mencadangkan bias induktif peraturan pengelasan adil berasaskan DP terhadap kumpulan majoriti berasaskan atribut sensitif. Sebaliknya, keputusan kami menunjukkan bahawa kaedah pembelajaran adil berasaskan DRO-SA menghasilkan peraturan pengelasan adil dengan berat sebelah yang lebih rendah terhadap pengedaran label di bawah atribut sensitif majoriti.
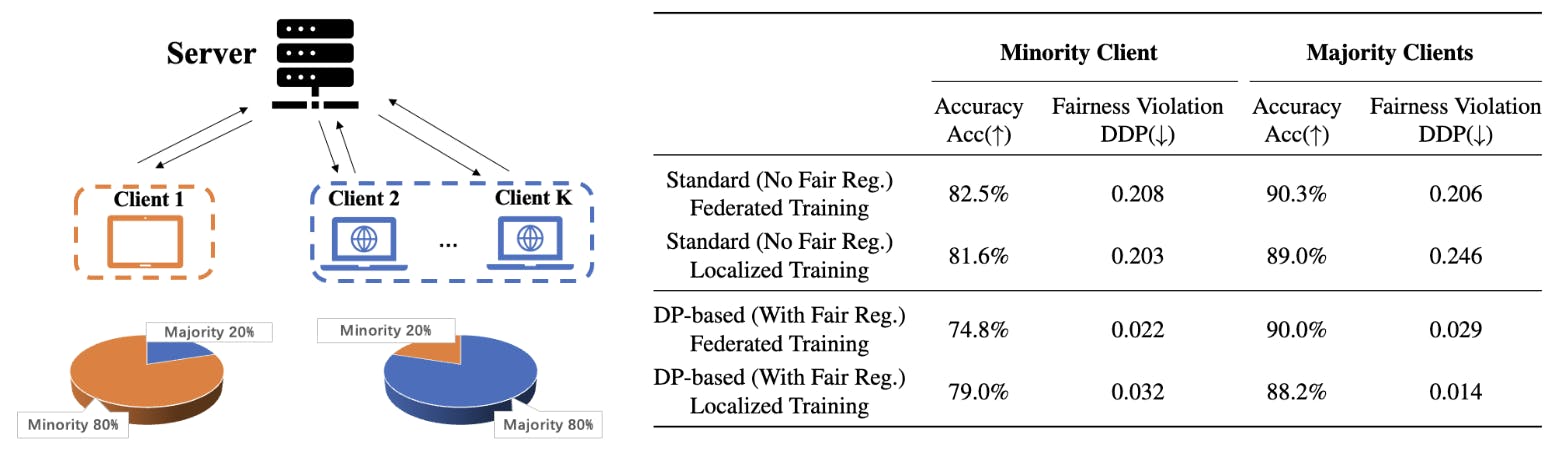
Tambahan pula, untuk menunjukkan kesan berat sebelah induktif tersebut dalam amalan, kami menganalisis tugas pengelasan adil dalam konteks pembelajaran bersekutu di mana berbilang pelanggan cuba melatih model terdesentralisasi. Kami menumpukan pada tetapan dengan pengedaran atribut sensitif heterogen merentas pelanggan yang mana hasil atribut sensitif majoriti pelanggan mungkin tidak bersetuju. Rajah 1 menggambarkan senario pembelajaran bersekutu sedemikian ke atas set data Dewasa, di mana atribut sensitif majoriti Pelanggan 1 (sampel wanita) adalah berbeza daripada kumpulan majoriti rangkaian (sampel lelaki), dan akibatnya, ketepatan ujian Pelanggan 1 dengan pembelajaran bersekutu adil berasaskan DP adalah jauh lebih rendah daripada ketepatan data Pelanggan tempatan yang terlatih dengan ketara berbanding ketepatan data Pelanggan tempatan sahaja. Keputusan berangka sedemikian mempersoalkan insentif pelanggan dalam mengambil bahagian dalam pembelajaran bersekutu yang adil. Berikut adalah ringkasan sumbangan utama karya ini:
• Mengkaji secara analitik kecenderungan pembelajaran adil berasaskan DP terhadap atribut sensitif majoriti,
• Mencadangkan kaedah pengoptimuman yang mantap dari segi pengagihan untuk mengurangkan berat sebelah klasifikasi adil berasaskan DP,
• Menyediakan keputusan berangka pada berat sebelah pembelajaran adil berasaskan DP dalam senario pembelajaran berpusat dan bersekutu.
2 Karya Berkaitan
Metrik Pelanggaran Keadilan. Dalam kerja ini, kami menumpukan pada rangka kerja pembelajaran yang bertujuan ke arah pariti demografi (DP). Memandangkan penguatkuasaan DP untuk dipegang secara ketat boleh memakan kos dan merosakkan prestasi pelajar, literatur pembelajaran mesin telah mencadangkan penggunaan beberapa metrik menilai pergantungan antara pembolehubah rawak, termasuk: maklumat bersama: [3-7], korelasi Pearson [8, 9], percanggahan min maksimum berasaskan kernel: [10], ukuran ketumpatan kernel [10] (penilaian ketumpatan kernel 1) korelasi maksimum [12–15], dan maklumat bersama Renyi eksponen [16]. Dalam analisis kami, kami kebanyakannya menumpukan pada skim regularisasi adil berasaskan DDP, sementara kami menunjukkan hanya versi lemah bagi bias induktif yang boleh terus dipegang dalam kes maklumat bersama dan algoritma pembelajaran adil berasaskan korelasi maksimum.


Algoritma Klasifikasi Adil. Algoritma pembelajaran mesin yang adil boleh diklasifikasikan kepada tiga kategori utama: pra-pemprosesan, pasca-pemprosesan dan dalam-pemprosesan. Algoritma pra-pemprosesan [17–19] mengubah ciri data berat sebelah kepada ruang baharu di mana label dan atribut sensitif adalah bebas dari segi statistik. Kaedah pasca pemprosesan seperti [2, 20] bertujuan untuk mengurangkan kesan diskriminasi pengelas dengan mengubah suai keputusan muktamadnya. Tumpuan fokus kerja kami hanya pada pendekatan dalam pemprosesan yang melaraskan proses latihan ke arah model adil berasaskan DP. Juga, [21–23] mencadangkan pengoptimuman teguh pengagihan (DRO) untuk pengelasan saksama; walau bagaimanapun, tidak seperti kaedah kami, kerja-kerja ini tidak menggunakan DRO pada pengedaran atribut sensitif untuk mengurangkan berat sebelah.
permudahkan
Kertas kerja ini tersedia di arxiv di bawah lesen CC BY-NC-SA 4.0 DEED.
Pengarang:
(1) Haoyu LEI, Jabatan Sains Komputer dan Kejuruteraan, Universiti Cina Hong Kong ([email protected]);
(2) Amin Gohari, Jabatan Kejuruteraan Maklumat, Universiti Cina Hong Kong ([email protected]);
(3) Farzan Farnia, Jabatan Sains Komputer dan Kejuruteraan, Universiti Cina Hong Kong ([email protected]).




