






















Autores:
(1) Raphaël Millière, Departamento de Filosofía, Universidad Macquarie ([email protected]);
(2) Cameron Buckner, Departamento de Filosofía, Universidad de Houston ([email protected]).
Tabla de enlaces
2. Introducción a los LLM
2.2. LLM basados en transformadores
3. Interfaz con cuestiones filosóficas clásicas
3.2. Nativismo y adquisición de la lengua
3.3. Comprensión y fundamentos del lenguaje
3.5. Transmisión de conocimientos culturales y andamiaje lingüístico
4. Conclusión, glosario y referencias
2.1 Fundamentos históricos
Los orígenes de los grandes modelos lingüísticos se remontan a los inicios de la investigación en IA. La historia temprana del procesamiento del lenguaje natural (PLN) estuvo marcada por un cisma entre dos paradigmas en competencia: el enfoque simbólico y el estocástico. Una influencia importante en el paradigma simbólico en el PLN fue la gramática transformacional-generativa de Noam Chomsky (Chomsky 1957), que postulaba que la sintaxis de los lenguajes naturales podía ser capturada por un conjunto de reglas formales que generaban oraciones bien formadas. El trabajo de Chomsky sentó las bases para el desarrollo de analizadores sintácticos basados en reglas, que aprovechan la teoría lingüística para descomponer las oraciones en sus partes constituyentes. Los primeros sistemas de PLN conversacionales, como SHRDLU de Winograd (Winograd 1971), requerían analizadores sintácticos con un conjunto complejo de reglas ad hoc para procesar la entrada del usuario.
Paralelamente, el paradigma estocástico fue desarrollado por investigadores como el matemático Warren Weaver, quien fue influenciado por la teoría de la información de Claude Shannon. En un memorando escrito en 1949, Weaver propuso el uso de computadoras para la traducción automática empleando técnicas estadísticas (Weaver 1955). Este trabajo allanó el camino para el desarrollo de modelos estadísticos del lenguaje, como los modelos n-gramas, que estiman la probabilidad de secuencias de palabras en función de las frecuencias observadas de combinaciones de palabras en un corpus (Jelinek 1998). Sin embargo, inicialmente el paradigma estocástico se quedó atrás de los enfoques simbólicos de la PNL, mostrando solo un éxito modesto en modelos de juguete con aplicaciones limitadas.
Otro importante paso teórico en el camino hacia los modelos lingüísticos modernos es la llamada hipótesis distributiva, propuesta por primera vez por el lingüista Zellig Harris en la década de 1950 (Harris 1954). Esta idea se basaba en la visión estructuralista del lenguaje, que postula que las unidades lingüísticas adquieren significado a través de sus patrones de coocurrencia con otras unidades en el sistema. Harris sugirió específicamente que el significado de una palabra podría inferirse examinando sus propiedades distributivas, o los contextos en los que aparece. Firth (1957) resumió acertadamente esta hipótesis con el lema “Reconocerás una palabra por la compañía que tiene”, reconociendo la influencia de la concepción de Wittgenstein (1953) del significado como uso para resaltar la importancia del contexto para comprender el significado lingüístico.
A medida que avanzaba la investigación sobre la hipótesis distributiva, los investigadores comenzaron a explorar la posibilidad de representar los significados de las palabras como vectores en un espacio multidimensional 1. Los primeros trabajos empíricos en esta área surgieron de la psicología y examinaron el significado de las palabras a lo largo de varias dimensiones, como la valencia y la potencia (Osgood 1952). Si bien este trabajo introdujo la idea de representar el significado en un espacio vectorial multidimensional, se basó en calificaciones explícitas de los participantes sobre las connotaciones de las palabras a lo largo de diferentes escalas (por ejemplo, bueno-malo), en lugar de analizar las propiedades distributivas de un corpus lingüístico. Las investigaciones posteriores en recuperación de información combinaron representaciones basadas en vectores con un enfoque basado en datos, desarrollando técnicas automatizadas para representar documentos y palabras como vectores en espacios vectoriales de alta dimensión (Salton et al. 1975).
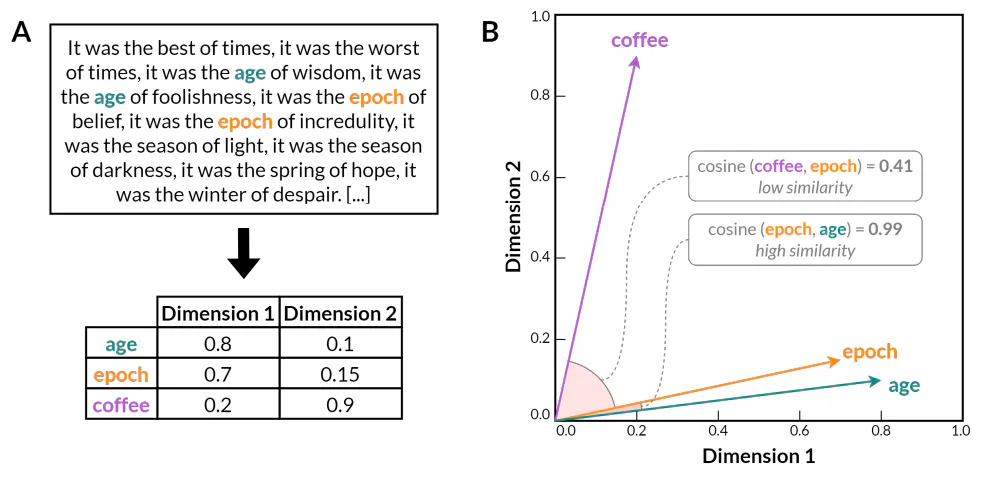
Tras décadas de investigación experimental, estas ideas finalmente alcanzaron su madurez con el desarrollo de modelos de incrustación de palabras que utilizan redes neuronales artificiales (Bengio et al. 2000). Estos modelos se basan en la idea de que las propiedades distributivas de las palabras se pueden aprender entrenando una red neuronal para predecir el contexto de una palabra dada la palabra misma, o viceversa. A diferencia de los métodos estadísticos anteriores, como los modelos de n-gramas, los modelos de incrustación de palabras codifican las palabras en representaciones vectoriales densas y de baja dimensión (Fig. 1). El espacio vectorial resultante reduce drásticamente la dimensionalidad de los datos lingüísticos al tiempo que preserva la información sobre las relaciones lingüísticas significativas más allá de las simples estadísticas de coocurrencia. Cabe destacar que muchas relaciones semánticas y sintácticas entre palabras se reflejan en subestructuras lineales dentro del espacio vectorial de los modelos de incrustación de palabras. Por ejemplo, Word2Vec (Mikolov et al. 2013) demostró que las incrustaciones de palabras pueden capturar regularidades tanto semánticas como sintácticas, como lo evidencia la capacidad de resolver tareas de analogía de palabras a través de una aritmética vectorial simple que revela la estructura lingüística latente codificada en el espacio vectorial (por ejemplo, 𝑘𝑖𝑛𝑔 + 𝑤𝑜𝑚𝑎𝑛 − 𝑚𝑎𝑛 ≈ 𝑞𝑢𝑒𝑒𝑛, o 𝑤𝑎𝑙𝑘𝑖𝑛𝑔 + 𝑠𝑤𝑎𝑚 − 𝑤𝑎𝑙𝑘𝑒𝑑 ≈ 𝑠𝑖𝑚𝑚𝑖𝑛𝑑𝑜).
El desarrollo de modelos de incrustación de palabras marcó un punto de inflexión en la historia del procesamiento del lenguaje natural, al proporcionar un medio potente y eficiente para representar unidades lingüísticas en un espacio vectorial continuo basado en su distribución estadística en un corpus grande. Sin embargo, estos modelos tienen varias limitaciones significativas. En primer lugar, no son capaces de capturar la polisemia y la homonimia, porque asignan una

En segundo lugar, se basan en arquitecturas de redes neuronales artificiales “superficiales” con una sola capa oculta, lo que limita su capacidad para modelar relaciones complejas entre palabras. Por último, al estar diseñados para representar el lenguaje a nivel de palabras individuales, no son adecuados para modelar expresiones lingüísticas complejas, como frases, oraciones y párrafos. Si bien es posible representar una oración como un vector promediando las incrustaciones de cada palabra en la oración, esta es una forma muy deficiente de representar el significado a nivel de oración, ya que pierde información sobre la estructura compositiva reflejada en el orden de las palabras. En otras palabras, los modelos de incrustación de palabras simplemente tratan el lenguaje como una “bolsa de palabras”; por ejemplo, “un libro de leyes” y “un libro de leyes” se tratan de manera idéntica como el conjunto desordenado {'un','libro','ley'}.
Las deficiencias de los modelos de incrustación de palabras superficiales se abordaron con la introducción de modelos de lenguaje “profundos”, que se remontan a las redes neuronales recurrentes (RNN) y sus variantes, como la memoria a corto plazo larga (LSTM) (Hochreiter y Schmidhuber 1997) y la unidad recurrente controlada (GRU) (Cho et al. 2014). Estas arquitecturas de redes neuronales profundas incorporan un mecanismo similar a la memoria, lo que les permite recordar y procesar secuencias de entradas a lo largo del tiempo, en lugar de palabras individuales y aisladas. A pesar de esta ventaja sobre los modelos de incrustación de palabras, sufren sus propias limitaciones: son lentos de entrenar y tienen dificultades con secuencias largas de texto. Estos problemas se abordaron con la introducción de la arquitectura Transformer por Vaswani et al. (2017), que sentó las bases para los LLM modernos.
Este artículo está disponible en arxiv bajo la licencia CC BY 4.0 DEED.








