






















著者:
(1) Raphaël Millière、マッコーリー大学哲学科 ([email protected])。
(2)キャメロン・バックナー、ヒューストン大学哲学科([email protected])。
リンク一覧
2. LLM入門
2.1. 歴史的背景
大規模言語モデルの起源は、AI 研究の始まりにまで遡ることができます。自然言語処理 (NLP) の初期の歴史は、シンボリック アプローチと確率的アプローチという 2 つの競合するパラダイムの分裂によって特徴づけられました。NLP のシンボリック パラダイムに大きく影響したのは、ノーム チョムスキーの変形生成文法 (Chomsky 1957) です。これは、自然言語の構文は、整形式の文を生成する一連の形式ルールで捉えられると仮定したものです。チョムスキーの研究は、言語理論を活用して文を構成要素に分解するルールベースの構文解析器の開発の基礎を築きました。ウィノグラードの SHRDLU (Winograd 1971) などの初期の会話型 NLP システムでは、ユーザー入力を処理するために、複雑なアドホック ルール セットを備えた構文解析器が必要でした。
同時に、確率論的パラダイムは、クロード・シャノンの情報理論に影響を受けた数学者ウォーレン・ウィーバーなどの研究者によって開拓されました。1949 年に書かれた覚書で、ウィーバーは統計的手法を採用した機械翻訳にコンピューターを使用することを提案しました (Weaver 1955)。この研究は、コーパス内の単語の組み合わせの観測頻度に基づいて単語シーケンスの尤度を推定する n グラム モデルなどの統計的言語モデルの開発への道を開きました (Jelinek 1998)。しかし、当初、確率論的パラダイムは NLP に対する記号的アプローチに遅れをとっていて、限られた用途のトイ モデルでささやかな成功しか収めていませんでした。
現代言語モデルへの道におけるもう一つの重要な理論的足がかりは、1950年代に言語学者ゼリッグ・ハリスによって初めて提唱された、いわゆる分布仮説である (Harris 1954)。この考え方は、言語の構造主義的見解に基づいており、言語単位はシステム内の他の単位との共起パターンを通じて意味を獲得すると仮定している。ハリスは特に、単語の意味はその分布特性、つまり単語が出現する文脈を調べることで推測できると示唆した。ファース (1957) は、この仮説を「単語はそれが一緒にいる人によってわかる」というスローガンで適切に要約し、言語的意味を理解する上で文脈が重要であることを強調するために、ウィトゲンシュタイン (1953) の意味は使用であるという概念の影響を認めている。
分布仮説の研究が進むにつれ、学者たちは単語の意味を多次元空間のベクトルとして表現する可能性を探り始めました 1。この分野における初期の実証研究は心理学に端を発し、単語の意味をさまざまな次元、たとえば価数や効力などに沿って調べました (Osgood 1952)。この研究は意味を多次元ベクトル空間で表現するというアイデアを導入しましたが、言語コーパスの分布特性を分析するのではなく、異なるスケール (たとえば、良い-悪い) に沿った単語の含意についての参加者の明示的な評価に依存していました。その後の情報検索の研究では、ベクトルベースの表現とデータ駆動型アプローチを組み合わせ、文書や単語を高次元ベクトル空間のベクトルとして表現する自動化手法が開発されました (Salton et al. 1975)。
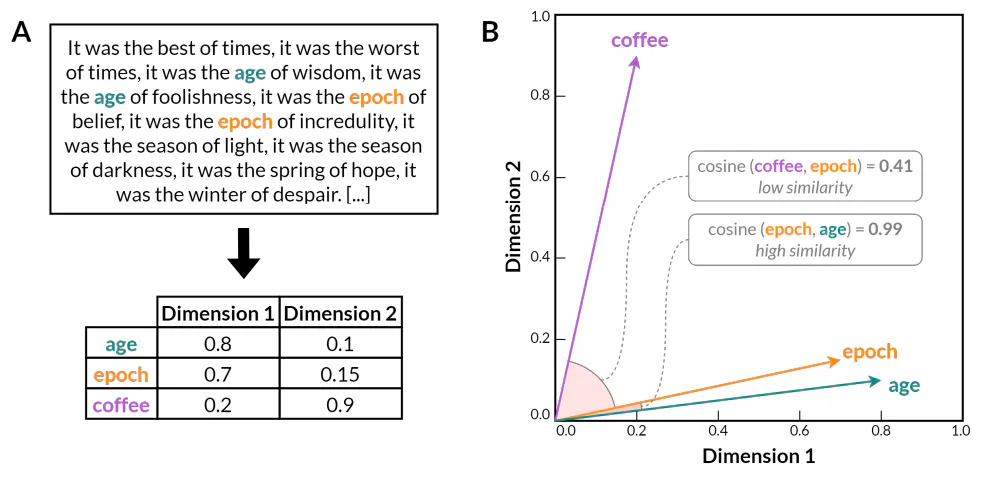
数十年にわたる実験的研究の後、これらのアイデアは、人工ニューラル ネットワークを使用した単語埋め込みモデルの開発によって最終的に成熟しました (Bengio ら、2000 年)。これらのモデルは、単語自体が与えられた場合に単語のコンテキストを予測するようにニューラル ネットワークをトレーニングすることで、単語の分布特性を学習できるという洞察に基づいています。逆もまた同様です。n グラム モデルなどの以前の統計的方法とは異なり、単語埋め込みモデルは、単語を高密度の低次元ベクトル表現にエンコードします (図 1)。結果として得られるベクトル空間は、言語データの次元を大幅に削減しながら、単純な共起統計を超えた意味のある言語関係に関する情報を保持します。特に、単語間の多くの意味的および統語的関係は、単語埋め込みモデルのベクトル空間内の線形サブ構造に反映されます。例えば、Word2Vec(Mikolov et al. 2013)は、単語の埋め込みが意味的規則性と統語的規則性の両方を捉えられることを実証しました。これは、ベクトル空間にエンコードされた潜在的な言語構造を明らかにする単純なベクトル演算を通じて単語の類推タスクを解く能力によって証明されています(例:𝑘𝑖𝑛𝑔 + 𝑤𝑜𝑚𝑎𝑛 − 𝑚𝑎𝑛 ≈ 𝑞𝑢𝑒𝑒𝑛、または𝑤𝑎𝑙𝑘𝑖𝑛𝑔 + 𝑠𝑤𝑎𝑚 − 𝑤𝑎𝑙𝑘𝑒𝑑 ≈ 𝑠𝑤𝑖𝑚𝑚𝑖𝑛𝑔)。
単語埋め込みモデルの開発は、NLPの歴史において転換点となり、大規模なコーパスにおける統計的分布に基づいて、言語単位を連続ベクトル空間で表現する強力で効率的な手段を提供した。しかし、これらのモデルにはいくつかの重大な限界がある。まず、多義性や同音異義性を捉えることができない。

第一に、単語埋め込みモデルは、単語の種類ごとに単一または「静的」な埋め込みしか行わないため、文脈に基づく意味の変化を考慮できません。たとえば、「銀行」には、川の側を指すか金融機関を指すかに関係なく、一意の埋め込みが割り当てられます。第二に、単一の隠れ層を持つ「浅い」人工ニューラル ネットワーク アーキテクチャに依存しているため、単語間の複雑な関係をモデル化する能力が制限されます。最後に、個々の単語のレベルで言語を表現するように設計されているため、フレーズ、文、段落などの複雑な言語表現をモデル化するのにはあまり適していません。文中のすべての単語の埋め込みを平均化することで、文をベクトルとして表現することは可能ですが、これは文レベルの意味を表現する方法としては非常に不十分です。語順に反映される構成構造に関する情報が失われるためです。言い換えると、単語埋め込みモデルは、言語を単に「単語の袋」として扱います。たとえば、「法律書」と「法律書」は、順序のないセット {'a','book','law'} として同じように扱われます。
浅い単語埋め込みモデルの欠点は、「ディープ」言語モデルの導入によって解決されました。これは、リカレント ニューラル ネットワーク (RNN) とその派生モデルである長短期記憶 (LSTM) (Hochreiter & Schmidhuber 1997) やゲート付きリカレント ユニット (GRU) (Cho et al. 2014) にまで遡ります。これらのディープ ニューラル ネットワーク アーキテクチャにはメモリのようなメカニズムが組み込まれており、個々の孤立した単語ではなく、時間の経過とともに入力のシーケンスを記憶して処理することができます。単語埋め込みモデルに比べてこの利点があるにもかかわらず、トレーニングに時間がかかり、長いテキスト シーケンスの処理に苦労するなど、独自の制限があります。これらの問題は、Vaswani et al. (2017) による Transformer アーキテクチャの導入によって解決され、現代の LLM の基礎が築かれました。
この論文は、CC BY 4.0 DEED ライセンスの下でarxiv で公開されています。








