






















Szerzői:
(1) Raphaël Millière, Filozófiai Tanszék, Macquarie Egyetem ([email protected]);
(2) Cameron Buckner, Filozófiai Tanszék, Houstoni Egyetem ([email protected]).
Hivatkozások táblázata
2. Alapozó az LLM-ekre
2.2. Transzformátor alapú LLM-ek
3. Interfész a klasszikus filozófiai kérdésekkel
3.2. Nativizmus és nyelvelsajátítás
3.5. Kulturális ismeretek átadása és nyelvi állványzat
4. Következtetések, szószedet és hivatkozások
2.1. Történelmi alapok
A nagy nyelvi modellek eredete az AI-kutatás kezdetéig vezethető vissza. A természetes nyelvi feldolgozás (NLP) korai történetét két versengő paradigma – a szimbolikus és a sztochasztikus megközelítés – közötti szakadás jellemezte. Az NLP szimbolikus paradigmájára nagy hatással volt Noam Chomsky transzformációs-generatív nyelvtana (Chomsky 1957), amely azt állította, hogy a természetes nyelvek szintaxisát olyan formális szabályokkal lehet megragadni, amelyek jól formált mondatokat generálnak. Chomsky munkája lefektette a szabályalapú szintaktikai elemzők kifejlesztésének alapjait, amelyek a nyelvi elméletet felhasználva bontják fel a mondatokat alkotórészeikre. A korai párbeszédes NLP rendszerek, mint például a Winograd SHRDLU (Winograd 1971), összetett ad hoc szabályokkal rendelkező szintaktikai elemzőket igényeltek a felhasználói bevitel feldolgozásához.
Ezzel párhuzamosan a sztochasztikus paradigmát olyan kutatók vezették be, mint például Warren Weaver matematikus, akire Claude Shannon információelmélete hatott. Egy 1949-ben írt memorandumban Weaver számítógépek használatát javasolta statisztikai technikákat alkalmazó gépi fordításhoz (Weaver 1955). Ez a munka megnyitotta az utat a statisztikai nyelvi modellek, például az n-gram modellek kidolgozásához, amelyek a szósorozatok valószínűségét becsülik meg a szóösszetételek megfigyelt gyakorisága alapján egy korpuszban (Jelinek 1998). Kezdetben azonban a sztochasztikus paradigma lemaradt az NLP szimbolikus megközelítései mögött, és csak szerény sikert mutatott a korlátozott alkalmazású játékmodellek esetében.
Egy másik fontos elméleti lépcsőfok a modern nyelvi modellek felé vezető úton az úgynevezett disztribúciós hipotézis, amelyet először Zellig Harris nyelvész javasolt az 1950-es években (Harris 1954). Ez az elképzelés a nyelv strukturalista felfogásán alapult, amely azt feltételezi, hogy a nyelvi egységek a rendszer más egységeivel való együttes előfordulási mintáik révén nyernek jelentést. Harris kifejezetten azt javasolta, hogy egy szó jelentésére kikövetkeztethető az eloszlási tulajdonságainak vagy a kontextusnak a vizsgálata, amelyben előfordul. Firth (1957) találóan foglalta össze ezt a hipotézist a következő szlogennel: „A szót attól a cégtől fogod tudni, amelyet megtart”, elismerve Wittgenstein (1953) jelentéshasználat-felfogásának hatását, amely rávilágít a kontextus fontosságára a nyelvi jelentés megértésében.
Az eloszlási hipotézis kutatásának előrehaladtával a tudósok elkezdték feltárni annak lehetőségét, hogy a szójelentéseket vektorokként ábrázolják egy többdimenziós térben 1. Az ezen a területen végzett korai empirikus munka a pszichológiából eredt, és a szavak jelentését különböző dimenziók, például vegyérték és potencia mentén vizsgálta (Osgood 1952). Míg ez a munka bevezette a jelentés többdimenziós vektortérben való megjelenítésének gondolatát, a résztvevők explicit értékelésére támaszkodott a szó konnotációiról különböző skálákon (pl. jó–rossz), nem pedig egy nyelvi korpusz eloszlási tulajdonságait elemezte. A későbbi információ-visszakeresési kutatások a vektor alapú reprezentációkat egyesítették adatvezérelt megközelítéssel, automatizált technikákat fejlesztettek ki dokumentumok és szavak vektorként való megjelenítésére nagy dimenziós vektorterekben (Salton et al. 1975).
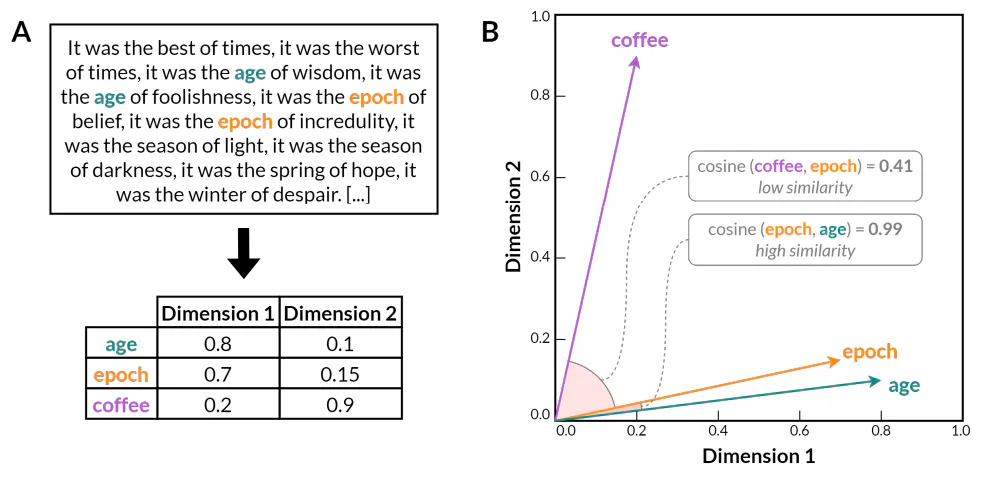
Több évtizedes kísérleti kutatás után ezek az ötletek végül a mesterséges neurális hálózatokat alkalmazó szóbeágyazási modellek kifejlesztésével értek el érettséget (Bengio et al. 2000). Ezek a modellek azon a meglátáson alapulnak, hogy a szavak eloszlási tulajdonságai megtanulhatók egy neurális hálózat betanításával, hogy előre jelezze a szó kontextusát magával a szóval együtt, vagy fordítva. A korábbi statisztikai módszerektől, például az n-gram modellektől eltérően a szóbeágyazási modellek a szavakat sűrű, alacsony dimenziójú vektoros reprezentációkba kódolják (1. ábra). Az így létrejövő vektortér drasztikusan csökkenti a nyelvi adatok dimenzióit, miközben az egyszerű együtt-előfordulási statisztikákon túl megőrzi az értelmes nyelvi kapcsolatokra vonatkozó információkat. Nevezetesen, hogy a szavak közötti számos szemantikai és szintaktikai kapcsolat a szóbeágyazási modellek vektorterén belüli lineáris alstruktúrákban tükröződik. Például a Word2Vec (Mikolov et al. 2013) bebizonyította, hogy a szóbeágyazás szemantikai és szintaktikai szabályszerűségeket is képes megragadni, amit az is bizonyít, hogy egyszerű vektoraritmetika segítségével szóanalógiás feladatokat is meg lehet oldani, amelyek felfedik a vektortérben kódolt látens nyelvi struktúrát (pl. 𝑘𝑖𝑛 𝑤𝑜𝑚𝑎𝑛 − 𝑚𝑎𝑛 ≈ 𝑞𝑢𝑒𝑒𝑛, vagy 𝑤𝑎𝑙𝑘𝑖❑ 𝑤𝑎𝑙𝑘𝑒𝑑 ≈ 𝑠𝑤𝑖𝑚𝑚𝑖𝑛𝑔).
A szóbeágyazási modellek kialakulása fordulópontot jelentett az NLP történetében, hatékony és hatékony eszközt kínálva a nyelvi egységek folyamatos vektortérben történő megjelenítésére, azok statisztikai eloszlása alapján egy nagy korpuszban. Ezeknek a modelleknek azonban számos jelentős korlátja van. Először is, nem képesek megragadni a poliszémiát és a homonímiát, mert hozzárendelnek a

egyetlen vagy „statikus” beágyazás minden szótípushoz, amely nem tudja figyelembe venni a kontextuson alapuló jelentésváltozást; például a „bank” egyedi beágyazást kap, függetlenül attól, hogy folyó partjára vagy pénzintézetre vonatkozik. Másodszor, „sekély” mesterséges neurális hálózati architektúrákra támaszkodnak egyetlen rejtett réteggel, ami korlátozza a szavak közötti összetett kapcsolatok modellezési képességét. Végül, mivel úgy tervezték, hogy a nyelvet az egyes szavak szintjén ábrázolják, nem alkalmasak összetett nyelvi kifejezések, például kifejezések, mondatok és bekezdések modellezésére. Bár lehetséges egy mondat vektorként ábrázolása a mondatban lévő összes szó beágyazásának átlagolásával, ez nagyon rossz módja a mondatszintű jelentés megjelenítésének, mivel elveszíti a szórendben tükröződő kompozíciós szerkezetre vonatkozó információkat. Más szavakkal, a szóbeágyazási modellek csupán „szavak zsákjaként” kezelik a nyelvet; például a „jogkönyv” és a „könyvtörvény” ugyanúgy kezelendő, mint a rendezetlen {'a','könyv','törvény'} halmaz.
A sekély szóbeágyazási modellek hiányosságait a „mély” nyelvi modellek bevezetésével orvosoltuk, visszanyúlva az ismétlődő neurális hálózatokra (RNN) és azok változataira, mint például a hosszú rövid távú memória (LSTM) (Hochreiter & Schmidhuber 1997) és a kapuzott visszatérő egység (GRU) (Cho et al. 2014). Ezek a mély neurális hálózati architektúrák egy memóriaszerű mechanizmust tartalmaznak, lehetővé téve számukra, hogy emlékezzenek és feldolgozzák a bemeneti szekvenciákat az egyes, elszigetelt szavak helyett. A szóbeágyazási modellekkel szembeni előnyük ellenére saját korlátaiktól szenvednek: lassan tanulnak, és hosszú szövegsorozatokkal küzdenek. Ezeket a problémákat a Transformer architektúra Vaswani et al. (2017), amely megalapozta a modern LLM-eket.
Ez a papír a CC BY 4.0 DEED licenc alatt érhető el az arxiv oldalon .








