






















نویسندگان:
(1) Raphaël Millière، گروه فلسفه، دانشگاه Macquarie ([email protected]);
(2) کامرون باکنر، گروه فلسفه، دانشگاه هیوستون ([email protected]).
جدول پیوندها
2. پرایمر روی LLM ها
2.2. LLM های مبتنی بر ترانسفورماتور
3. ارتباط با مسائل فلسفی کلاسیک
3.2. بومی گرایی و فراگیری زبان
3.5. انتقال دانش فرهنگی و داربست زبانی
4. نتیجه گیری، واژه نامه، و منابع
2.1. مبانی تاریخی
منشاء مدلهای زبان بزرگ را میتوان در آغاز تحقیقات هوش مصنوعی جستجو کرد. تاریخ اولیه پردازش زبان طبیعی (NLP) با شکاف بین دو پارادایم رقیب مشخص شد: رویکرد نمادین و تصادفی. تأثیر عمده بر پارادایم نمادین در NLP، گرامر دگرگونی-زاینده نوام چامسکی بود (چامسکی 1957)، که بیان می کرد که نحو زبان های طبیعی را می توان با مجموعه ای از قوانین رسمی که جملاتی به خوبی شکل گرفته است، دریافت کرد. کار چامسکی پایه و اساس توسعه تجزیهکنندههای نحوی مبتنی بر قاعده را ایجاد کرد که از نظریه زبانشناختی برای تجزیه جملات به اجزای سازندهشان استفاده میکنند. سیستمهای NLP محاورهای اولیه، مانند SHRDLU وینوگراد (وینوگراد 1971)، به تجزیهکنندههای نحوی با مجموعهای پیچیده از قوانین ad hoc برای پردازش ورودی کاربر نیاز داشت.
به موازات آن، پارادایم تصادفی توسط محققانی مانند ریاضیدان وارن ویور، که تحت تأثیر نظریه اطلاعات کلود شانون بود، پیشگام شد. در یادداشتی که در سال 1949 نوشته شد، ویور استفاده از رایانه را برای ترجمه ماشینی با استفاده از تکنیک های آماری پیشنهاد کرد (ویور 1955). این کار راه را برای توسعه مدلهای زبانی آماری، مانند مدلهای n-gram، که احتمال توالی کلمات را بر اساس فراوانیهای مشاهدهشده ترکیبهای کلمه در یک پیکره تخمین میزند، هموار کرد (Jelinek 1998). با این حال، در ابتدا، الگوی تصادفی از رویکردهای نمادین NLP عقب مانده بود، و تنها موفقیت متوسطی را در مدلهای اسباببازی با کاربردهای محدود نشان میداد.
یکی دیگر از پله های نظری مهم در راه رسیدن به مدل های زبان مدرن، فرضیه موسوم به توزیعی است که برای اولین بار توسط زلیگ هریس زبان شناس در دهه 1950 ارائه شد (Harris 1954). این ایده مبتنی بر دیدگاه ساختارگرایانه زبان بود، که معتقد است واحدهای زبانی از طریق الگوهای همزمانی خود با واحدهای دیگر در سیستم معنا پیدا میکنند. هریس به طور خاص پیشنهاد کرد که معنای یک کلمه را می توان با بررسی ویژگی های توزیعی آن، یا زمینه هایی که در آن رخ می دهد، استنباط کرد. فرث (1957) به درستی این فرضیه را با شعار "شما باید یک کلمه را توسط شرکتی که نگه می دارد بشناسید" خلاصه کرد و تأثیر مفهوم ویتگنشتاین (1953) از معنا-به عنوان-استفاده را برای برجسته کردن اهمیت زمینه در درک معنای زبانی تأیید کرد.
با پیشرفت تحقیق در مورد فرضیه توزیعی، محققان شروع به بررسی امکان نمایش معانی کلمات به عنوان بردار در فضای چند بعدی کردند. 1. کارهای تجربی اولیه در این زمینه از روانشناسی سرچشمه می گرفت و معنای کلمات را در ابعاد مختلف، مانند ظرفیت و قدرت بررسی می کرد (Osgood 1952). در حالی که این کار ایده نمایش معنا را در یک فضای برداری چند بعدی معرفی کرد، به جای تجزیه و تحلیل ویژگیهای توزیعی یک پیکره زبانی، بر رتبهبندیهای صریح شرکتکنندگان در مورد معانی کلمات در مقیاسهای مختلف (مثلاً خوب-بد) تکیه داشت. تحقیقات بعدی در بازیابی اطلاعات، نمایشهای مبتنی بر برداری را با رویکرد دادهمحور ترکیب کرد و تکنیکهای خودکار را برای نمایش اسناد و کلمات بهعنوان بردار در فضاهای برداری با ابعاد بالا توسعه داد (سالتون و همکاران 1975).
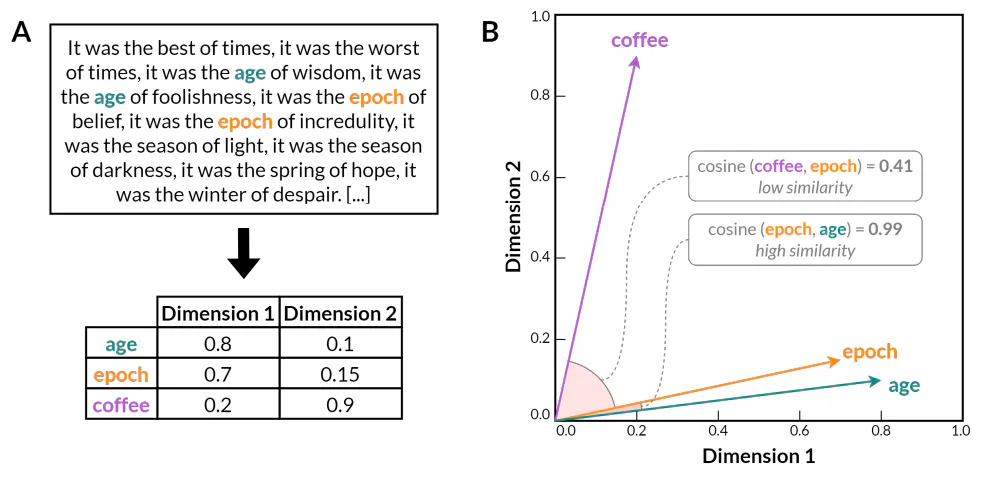
پس از دههها تحقیق تجربی، این ایدهها در نهایت با توسعه مدلهای جاسازی کلمه با استفاده از شبکههای عصبی مصنوعی به بلوغ رسیدند (Bengio et al. 2000). این مدلها مبتنی بر این بینش هستند که ویژگیهای توزیعی کلمات را میتوان با آموزش یک شبکه عصبی برای پیشبینی بافت کلمه با توجه به خود کلمه یا برعکس، آموخت. بر خلاف روشهای آماری قبلی مانند مدلهای n-gram، مدلهای جاسازی کلمه، کلمات را به نمایشهای برداری متراکم و کمبعدی رمزگذاری میکنند (شکل 1). فضای برداری حاصل، ابعاد داده های زبانی را به شدت کاهش می دهد در حالی که اطلاعات مربوط به روابط زبانی معنادار را فراتر از آمارهای ساده همزمان حفظ می کند. قابل توجه است که بسیاری از روابط معنایی و نحوی بین کلمات در زیرساختهای خطی در فضای برداری مدلهای جاسازی کلمه منعکس میشوند. به عنوان مثال، Word2Vec (Mikolov و همکاران 2013) نشان داد که تعبیههای کلمه میتوانند هم نظم معنایی و هم نظم نحوی را به تصویر بکشند، همانطور که با توانایی حل تکالیف قیاس کلمه از طریق حساب برداری ساده که ساختار زبانی پنهان کدگذاری شده در فضای برداری را آشکار میکند، مشهود است (به عنوان مثال، 👘). 𝑤𝑜𝑚𝑎𝑛 − 𝑚𝑎𝑛 ≈ 𝑞𝑢 𝑤𝑎𝑙𝑘𝑒𝑑 ≈ 𝑠𝑤𝑖𝑚𝑚𝑖.
توسعه مدلهای جاسازی کلمه نقطه عطفی در تاریخ NLP بود و ابزار قدرتمند و کارآمدی را برای نمایش واحدهای زبانی در یک فضای برداری پیوسته بر اساس توزیع آماری آنها در یک مجموعه بزرگ فراهم کرد. با این حال، این مدل ها دارای چندین محدودیت قابل توجه هستند. اولاً، آنها قادر به گرفتن چندمعنی و متجانس نیستند، زیرا آنها a را اختصاص می دهند

تعبیه تک یا "ایستا" در هر نوع کلمه، که نمی تواند تغییرات در معنا را بر اساس زمینه توضیح دهد. به عنوان مثال، "بانک" بدون توجه به اینکه به کنار رودخانه یا موسسه مالی اشاره دارد، یک جاسازی منحصر به فرد اختصاص داده می شود. دوم، آنها به معماری شبکه های عصبی مصنوعی "کم عمق" با یک لایه پنهان تکیه می کنند، که توانایی آنها را برای مدل سازی روابط پیچیده بین کلمات محدود می کند. در نهایت، طراحی شده برای نشان دادن زبان در سطح کلمات فردی، آنها برای مدل سازی بیان پیچیده زبانی، مانند عبارات، جملات، و پاراگراف ها مناسب نیستند. در حالی که میتوان یک جمله را بهعنوان یک بردار با میانگینگیری از جاسازیهای هر کلمه در جمله نشان داد، این روش بسیار ضعیفی برای نمایش معنای سطح جمله است، زیرا اطلاعات مربوط به ساختار ترکیبی منعکسشده در ترتیب کلمات را از دست میدهد. به عبارت دیگر، مدلهای جاسازی کلمه، زبان را صرفاً به عنوان «کیف کلمات» در نظر میگیرند. برای مثال، "یک کتاب قانون" و "یک قانون کتاب" به طور یکسان به عنوان مجموعه نامرتب {'a','book',' law'} در نظر گرفته می شوند.
کاستیهای مدلهای جاسازی کلمه کم عمق با معرفی مدلهای زبانی «عمیق»، که به شبکههای عصبی بازگشتی (RNN) و انواع آنها، مانند حافظه کوتاهمدت بلندمدت (LSTM) (Hochreiter & Schmidhuber 1997) و واحد بازگشتی دروازهای (GRU) (GRU) باز میگردد، برطرف شد. این معماریهای شبکه عصبی عمیق مکانیزمی شبیه حافظه را در خود جای دادهاند که به آنها اجازه میدهد توالیهایی از ورودیها را در طول زمان به خاطر بسپارند و پردازش کنند، نه کلمات مجزا. علیرغم این مزیت نسبت به مدلهای جاسازی کلمه، آنها از محدودیتهای خاص خود رنج میبرند: در آموزش آهسته هستند و با دنبالههای طولانی متن مبارزه میکنند. این مسائل با معرفی معماری ترانسفورماتور توسط واسوانی و همکاران مطرح شد. (2017)، که زمینه را برای LLM های مدرن فراهم کرد.
این مقاله در arxiv تحت مجوز CC BY 4.0 DEED موجود است.




