






















Autori:
(1) Raphaël Millière, Odsjek za filozofiju, Sveučilište Macquarie ([email protected]);
(2) Cameron Buckner, Odsjek za filozofiju, Sveučilište u Houstonu ([email protected]).
Tablica veza
2. Početni dio studija LLM
2.2. LLM na bazi transformatora
3. Sučelje s klasičnim filozofskim pitanjima
3.2. Nativizam i usvajanje jezika
3.3. Razumijevanje jezika i utemeljenje
3.5. Prijenos kulturnog znanja i jezične skele
4. Zaključak, pojmovnik i literatura
2.1. Povijesni temelji
Porijeklo velikih jezičnih modela može se pratiti do početka istraživanja umjetne inteligencije. Ranu povijest obrade prirodnog jezika (NLP) obilježio je raskol između dviju konkurentskih paradigmi: simboličkog i stohastičkog pristupa. Veliki utjecaj na simboličku paradigmu u NLP-u imala je transformacijsko-generativna gramatika Noama Chomskog (Chomsky 1957.), koja je postavila da se sintaksa prirodnih jezika može obuhvatiti skupom formalnih pravila koja generiraju dobro oblikovane rečenice. Chomskyjev rad postavio je temelj za razvoj sintaktičkih parsera temeljenih na pravilima, koji koriste lingvističku teoriju za rastavljanje rečenica na njihove sastavne dijelove. Rani konverzacijski NLP sustavi, kao što je Winogradov SHRDLU (Winograd 1971.), zahtijevali su sintaktičke parsere sa složenim skupom ad hoc pravila za obradu korisničkog unosa.
Paralelno, stohastičku paradigmu uveli su istraživači poput matematičara Warrena Weavera, koji je bio pod utjecajem teorije informacija Claudea Shannona. U memorandumu napisanom 1949. Weaver je predložio korištenje računala za strojno prevođenje koristeći statističke tehnike (Weaver 1955). Ovaj je rad otvorio put razvoju statističkih jezičnih modela, poput modela n-grama, koji procjenjuju vjerojatnost nizova riječi na temelju promatranih učestalosti kombinacija riječi u korpusu (Jelinek 1998). Međutim, u početku je stohastička paradigma zaostajala za simboličkim pristupom NLP-u, pokazujući samo skroman uspjeh u modelima igračaka s ograničenom primjenom.
Druga važna teorijska odskočna daska na putu do modernih jezičnih modela je takozvana distribucijska hipoteza, koju je prvi predložio lingvist Zellig Harris 1950-ih (Harris 1954). Ta je ideja utemeljena na strukturalističkom pogledu na jezik, koji pretpostavlja da jezične jedinice stječu značenje kroz svoje obrasce zajedničkog pojavljivanja s drugim jedinicama u sustavu. Harris je posebno predložio da se značenje riječi može zaključiti ispitivanjem njezinih distribucijskih svojstava ili konteksta u kojima se pojavljuje. Firth (1957.) je prikladno sažeo ovu hipotezu sloganom "Prepoznat ćeš riječ po tvrtki koju drži", priznajući utjecaj Wittgensteinove (1953.) koncepcije značenja-kao-uporabe kako bi se istaknula važnost konteksta u razumijevanju jezičnog značenja.
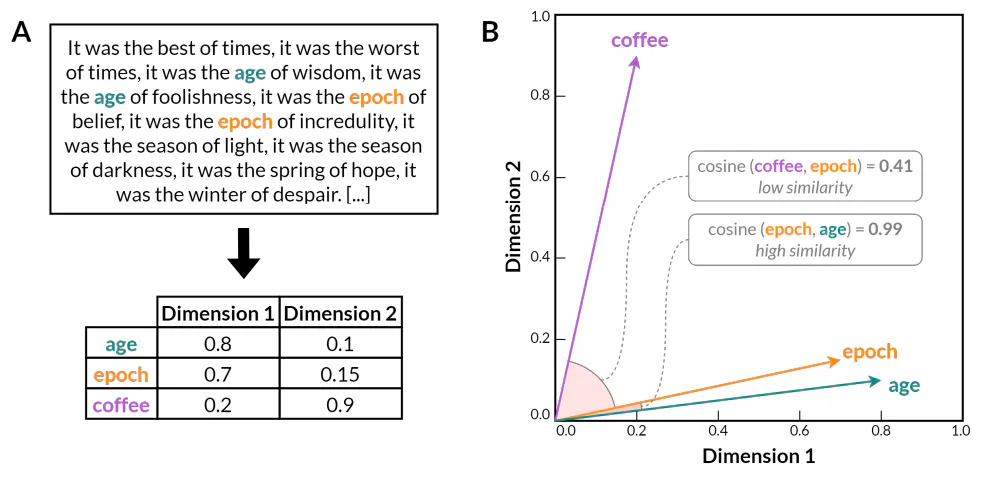
Kako je istraživanje distribucijske hipoteze napredovalo, znanstvenici su počeli istraživati mogućnost predstavljanja značenja riječi kao vektora u višedimenzionalnom prostoru 1. Rani empirijski radovi u ovom području proizašli su iz psihologije i ispitivali su značenje riječi duž različitih dimenzija, kao što su valentnost i moć (Osgood 1952). Iako je ovaj rad uveo ideju predstavljanja značenja u višedimenzionalnom vektorskom prostoru, oslanjao se na eksplicitne ocjene sudionika o konotacijama riječi na različitim ljestvicama (npr. dobro–loše), umjesto na analizu distribucijskih svojstava jezičnog korpusa. Naknadna istraživanja pronalaženja informacija kombinirala su vektorske prikaze s pristupom vođenim podacima, razvijajući automatizirane tehnike za predstavljanje dokumenata i riječi kao vektora u visokodimenzionalnim vektorskim prostorima (Salton et al. 1975).
Nakon desetljeća eksperimentalnog istraživanja, te su ideje konačno dosegle zrelost s razvojem modela ugrađivanja riječi pomoću umjetnih neuronskih mreža (Bengio et al. 2000). Ovi se modeli temelje na uvidu da se distribucijska svojstva riječi mogu naučiti obučavanjem neuronske mreže da predvidi kontekst riječi s obzirom na samu riječ ili obrnuto. Za razliku od prethodnih statističkih metoda kao što su modeli n-grama, modeli ugrađivanja riječi kodiraju riječi u guste, niskodimenzionalne vektorske reprezentacije (slika 1). Rezultirajući vektorski prostor drastično smanjuje dimenzionalnost lingvističkih podataka dok istovremeno čuva informacije o smislenim lingvističkim odnosima izvan jednostavne statistike supojavljivanja. Naime, mnogi semantički i sintaktički odnosi između riječi odražavaju se u linearnim podstrukturama unutar vektorskog prostora modela ugrađivanja riječi. Na primjer, Word2Vec (Mikolov et al. 2013) pokazao je da ugrađivanje riječi može uhvatiti i semantičke i sintaktičke pravilnosti, što je dokazano sposobnošću rješavanja zadataka analogije riječi pomoću jednostavne vektorske aritmetike koja otkriva latentnu jezičnu strukturu kodiranu u vektorskom prostoru (npr. 𝑘𝑖𝑛𝑔 + 𝑤𝑜𝑚𝑎𝑛 − 𝑚𝑎𝑛 ≈ 𝑞𝑢𝑒𝑒𝑛, ili 𝑤𝑎𝑙𝑘𝑖𝑛𝑔 + 𝑠𝑤𝑎𝑚 − 𝑤𝑎𝑙𝑘𝑒𝑑 ≈ 𝑠𝑤𝑖𝑚𝑚𝑖𝑛𝑔).
Razvoj modela ugrađivanja riječi označio je prekretnicu u povijesti NLP-a, pružajući snažno i učinkovito sredstvo za predstavljanje jezičnih jedinica u kontinuiranom vektorskom prostoru na temelju njihove statističke distribucije u velikom korpusu. Međutim, ovi modeli imaju nekoliko značajnih ograničenja. Prvo, oni nisu sposobni uhvatiti polisemiju i homonimiju, jer dodjeljuju a

pojedinačno ili "statično" ugrađivanje u svaku vrstu riječi, koje ne može objasniti promjene značenja na temelju konteksta; na primjer, "banka" je dodijeljena jedinstvena ugradnja bez obzira na to odnosi li se na obalu rijeke ili financijsku instituciju. Drugo, oslanjaju se na "plitku" arhitekturu umjetne neuronske mreže s jednim skrivenim slojem, što ograničava njihovu sposobnost modeliranja složenih odnosa između riječi. Naposljetku, budući da su dizajnirani da predstavljaju jezik na razini pojedinačnih riječi, nisu prikladni za modeliranje složenih jezičnih izraza, kao što su fraze, rečenice i odlomci. Iako je moguće predstaviti rečenicu kao vektor izračunavanjem prosjeka ugrađenosti svake riječi u rečenici, ovo je vrlo loš način predstavljanja značenja na razini rečenice, budući da se gubi informacija o kompozicijskoj strukturi koja se odražava u redu riječi. Drugim riječima, modeli ugrađivanja riječi samo tretiraju jezik kao "vreću riječi"; na primjer, "knjiga zakona" i "knjiga zakona" tretiraju se identično kao neuređeni skup {'a','knjiga','zakon'}.
Nedostaci plitkih modela ugrađivanja riječi riješeni su uvođenjem "dubokih" jezičnih modela, vraćajući se na rekurentne neuronske mreže (RNN) i njihove varijante, kao što je dugo kratkoročno pamćenje (LSTM) (Hochreiter & Schmidhuber 1997) i zatvorena rekurentna jedinica (GRU) (Cho et al. 2014). Ove duboke arhitekture neuronske mreže uključuju mehanizam sličan memoriji, omogućujući im da pamte i obrađuju nizove unosa tijekom vremena, umjesto pojedinačnih, izoliranih riječi. Unatoč ovoj prednosti u odnosu na modele ugrađivanja riječi, oni pate od vlastitih ograničenja: spori su za obuku i bore se s dugim sekvencama teksta. Ovi problemi su riješeni uvođenjem Transformer arhitekture od strane Vaswanija i sur. (2017), koji je postavio temelje modernim LLM-ovima.
Ovaj je dokument dostupan na arxiv pod licencom CC BY 4.0 DEED.




