






















저자:
(1) Raphaël Millière, 맥쿼리 대학교 철학과 ([email protected]);
(2) 휴스턴 대학교 철학과 Cameron Buckner([email protected]).
링크 표
2. LLM에 대한 입문서
2.1. 역사적 기초
대규모 언어 모델의 기원은 AI 연구의 시작으로 거슬러 올라갈 수 있습니다. 자연어 처리(NLP)의 초기 역사는 두 가지 경쟁 패러다임인 상징적 접근 방식과 확률적 접근 방식 간의 분열로 표시되었습니다. NLP의 상징적 패러다임에 큰 영향을 미친 것은 노암 촘스키의 변형-생성 문법(Chomsky 1957)으로, 자연어의 구문은 잘 구성된 문장을 생성하는 일련의 형식적 규칙으로 포착될 수 있다고 가정했습니다. 촘스키의 연구는 언어 이론을 활용하여 문장을 구성 요소로 분해하는 규칙 기반 구문 파서 개발의 토대를 마련했습니다. 위노그래드의 SHRDLU(Winograd 1971)와 같은 초기 대화형 NLP 시스템은 사용자 입력을 처리하기 위해 복잡한 임시 규칙 집합이 있는 구문 파서가 필요했습니다.
동시에 확률적 패러다임은 Claude Shannon의 정보 이론에 영향을 받은 수학자 Warren Weaver와 같은 연구자들에 의해 개척되었습니다. Weaver는 1949년에 작성된 메모에서 통계적 기법을 사용하여 기계 번역에 컴퓨터를 사용할 것을 제안했습니다(Weaver 1955). 이 작업은 n-gram 모델과 같은 통계적 언어 모델의 개발을 위한 길을 열었습니다. 이 모델은 코퍼스에서 관찰된 단어 조합의 빈도를 기반으로 단어 시퀀스의 가능성을 추정합니다(Jelinek 1998). 그러나 처음에는 확률적 패러다임이 NLP에 대한 상징적 접근 방식보다 뒤쳐져 있었고, 제한된 응용 프로그램을 가진 장난감 모델에서만 겸손한 성공을 보였습니다.
현대 언어 모델로 가는 길에서 또 다른 중요한 이론적 발판은 언어학자 젤리그 해리스가 1950년대에 처음 제안한 소위 분포 가설입니다(Harris 1954). 이 아이디어는 언어에 대한 구조주의적 관점에 근거를 두고 있는데, 이 관점은 언어 단위가 체계의 다른 단위와 공존하는 패턴을 통해 의미를 획득한다고 가정합니다. 해리스는 특히 단어의 의미는 분포적 속성, 즉 단어가 발생하는 맥락을 조사하여 추론할 수 있다고 제안했습니다. 퍼스(1957)는 이 가설을 "단어는 그것이 머무는 곳으로 알 수 있을 것이다"라는 슬로건으로 적절하게 요약하면서, 언어적 의미를 이해하는 데 있어 맥락의 중요성을 강조하기 위해 비트겐슈타인(1953)의 사용으로서의 의미 개념의 영향을 인정했습니다.
분포 가설에 대한 연구가 진행됨에 따라 학자들은 다차원 공간에서 벡터로 단어 의미를 표현할 가능성을 탐구하기 시작했습니다.1 이 분야의 초기 경험적 연구는 심리학에서 비롯되었으며 가치와 효능과 같은 다양한 차원에서 단어의 의미를 조사했습니다(Osgood 1952). 이 연구는 다차원 벡터 공간에서 의미를 표현하는 아이디어를 도입했지만 언어 코퍼스의 분포적 속성을 분석하기보다는 다양한 척도(예: 좋음-나쁨)에서 단어 의미에 대한 명시적인 참가자 평가에 의존했습니다. 정보 검색에 대한 후속 연구에서는 벡터 기반 표현과 데이터 기반 접근 방식을 결합하여 고차원 벡터 공간에서 문서와 단어를 벡터로 표현하기 위한 자동화된 기술을 개발했습니다(Salton et al. 1975).
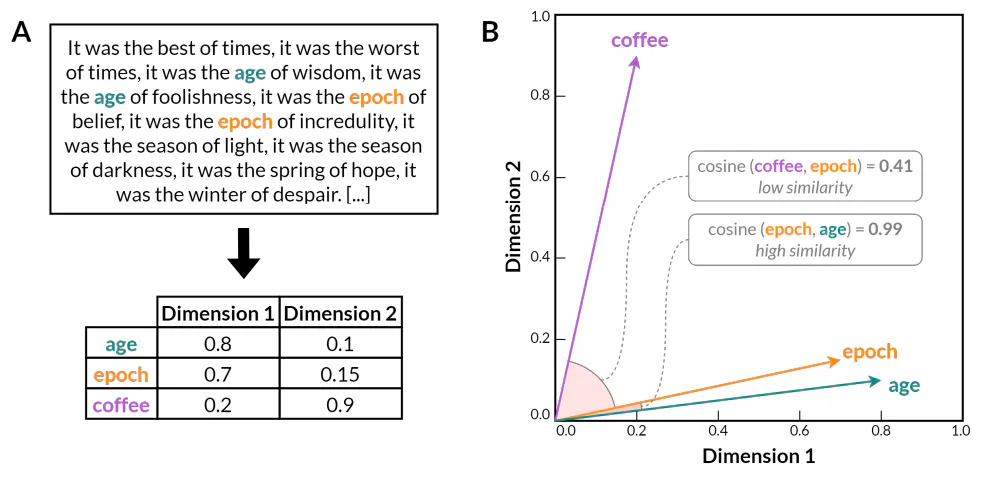
수십 년간의 실험적 연구 끝에 이러한 아이디어는 결국 인공 신경망을 사용한 단어 임베딩 모델(Bengio et al. 2000)의 개발로 완성되었습니다. 이러한 모델은 단어의 분포적 특성은 단어 자체를 기준으로 단어의 맥락을 예측하도록 신경망을 훈련하거나 그 반대로 학습할 수 있다는 통찰력에 기반합니다. n-gram 모델과 같은 이전의 통계적 방법과 달리 단어 임베딩 모델은 단어를 밀도가 높고 저차원 벡터 표현으로 인코딩합니다(그림 1). 그 결과 벡터 공간은 언어 데이터의 차원을 크게 줄이는 동시에 단순한 동시 발생 통계를 넘어 의미 있는 언어 관계에 대한 정보를 보존합니다. 특히 단어 간의 많은 의미적 및 구문적 관계는 단어 임베딩 모델의 벡터 공간 내의 선형 하위 구조에 반영됩니다. 예를 들어, Word2Vec(Mikolov et al. 2013)은 단어 임베딩이 의미적 및 구문적 규칙성을 모두 포착할 수 있음을 보여주었습니다. 이는 벡터 공간에 인코딩된 잠재적 언어 구조를 드러내는 간단한 벡터 산술을 통해 단어 유추 작업을 해결하는 능력에서 입증되었습니다(예: 𝑘𝑖𝑛𝑔 + 𝑤𝑜𝑚𝑎𝑛 − 𝑚𝑎𝑛 ≈ 𝑞𝑢𝑒𝑛, 또는 𝑤𝑎𝑙𝑘𝑖𝑛𝑔 + 𝑠𝑤𝑎𝑚 − 𝑤𝑎𝑙𝑘𝑒𝑑 ≈ 𝑠𝑤𝑖𝑚𝑚𝑖𝑛𝑔).
단어 임베딩 모델의 개발은 NLP 역사에서 전환점을 표시하여 대규모 코퍼스의 통계적 분포를 기반으로 연속 벡터 공간에서 언어 단위를 표현하는 강력하고 효율적인 수단을 제공했습니다. 그러나 이러한 모델에는 몇 가지 중요한 한계가 있습니다. 첫째, 다의성과 동음이의성을 포착할 수 없습니다.

각 단어 유형에 단일 또는 "정적" 임베딩을 적용하여 맥락에 따른 의미 변화를 설명할 수 없습니다. 예를 들어, "은행"은 강변을 의미하든 금융 기관을 의미하든 고유한 임베딩이 할당됩니다. 둘째, 단일 은닉 계층이 있는 "얕은" 인공 신경망 아키텍처에 의존하여 단어 간의 복잡한 관계를 모델링하는 능력이 제한됩니다. 마지막으로, 개별 단어 수준에서 언어를 표현하도록 설계되었으므로 구문, 문장 및 단락과 같은 복잡한 언어 표현을 모델링하는 데 적합하지 않습니다. 문장의 모든 단어 임베딩을 평균하여 문장을 벡터로 표현할 수는 있지만, 이는 단어 순서에 반영된 구성 구조에 대한 정보를 잃기 때문에 문장 수준의 의미를 표현하는 매우 나쁜 방법입니다. 즉, 단어 임베딩 모델은 언어를 단순히 "단어의 가방"으로 취급합니다. 예를 들어, "법률 서적"과 "법률 서적"은 순서 없는 집합 {'a','book','law'}으로 동일하게 취급됩니다.
얕은 단어 임베딩 모델의 단점은 순환 신경망(RNN)과 그 변형인 장단기 기억(LSTM)(Hochreiter & Schmidhuber 1997) 및 게이트 순환 단위(GRU)(Cho et al. 2014)로 거슬러 올라가는 "심층" 언어 모델의 도입으로 해결되었습니다. 이러한 심층 신경망 아키텍처는 메모리와 같은 메커니즘을 통합하여 개별적이고 고립된 단어가 아닌 시간이 지남에 따라 입력 시퀀스를 기억하고 처리할 수 있습니다. 단어 임베딩 모델에 비해 이러한 이점이 있음에도 불구하고 고유한 한계가 있습니다. 즉, 훈련 속도가 느리고 긴 텍스트 시퀀스를 처리하는 데 어려움을 겪습니다. 이러한 문제는 Vaswani et al.(2017)이 Transformer 아키텍처를 도입하면서 해결되었으며, 이는 현대 LLM의 토대를 마련했습니다.
이 논문은 CC BY 4.0 DEED 라이선스에 따라 arxiv에서 볼 수 있습니다 .








