






















Pengarang:
(1) Raphaël Millière, Jabatan Falsafah, Universiti Macquarie ([email protected]);
(2) Cameron Buckner, Jabatan Falsafah, Universiti Houston ([email protected]).
Jadual Pautan
2. Buku asas mengenai LLM
3. Antara muka dengan isu falsafah klasik
3.2. Nativisme dan pemerolehan bahasa
3.3. Pemahaman dan asas bahasa
3.5. Penghantaran pengetahuan budaya dan perancah linguistik
4. Kesimpulan, Glosari, dan Rujukan
2.1. Asas sejarah
Asal-usul model bahasa yang besar boleh dikesan kembali kepada permulaan penyelidikan AI. Sejarah awal pemprosesan bahasa semula jadi (NLP) ditandai dengan perpecahan antara dua paradigma yang bersaing: pendekatan simbolik dan stokastik. Pengaruh utama pada paradigma simbolik dalam NLP ialah tatabahasa transformasi-generatif Noam Chomsky (Chomsky 1957), yang menyatakan bahawa sintaks bahasa semula jadi boleh ditangkap oleh satu set peraturan formal yang menghasilkan ayat yang terbentuk dengan baik. Kerja Chomsky meletakkan asas untuk pembangunan penghurai sintaksis berasaskan peraturan, yang memanfaatkan teori linguistik untuk menguraikan ayat ke bahagian konstituennya. Sistem NLP perbualan awal, seperti SHRDLU Winograd (Winograd 1971), memerlukan penghurai sintaksis dengan set peraturan ad hoc yang kompleks untuk memproses input pengguna.
Secara selari, paradigma stokastik dipelopori oleh penyelidik seperti ahli matematik Warren Weaver, yang dipengaruhi oleh teori maklumat Claude Shannon. Dalam memorandum yang ditulis pada tahun 1949, Weaver mencadangkan penggunaan komputer untuk terjemahan mesin yang menggunakan teknik statistik (Weaver 1955). Kerja ini membuka jalan kepada pembangunan model bahasa statistik, seperti model n-gram, yang menganggarkan kemungkinan urutan perkataan berdasarkan frekuensi yang diperhatikan gabungan perkataan dalam korpus (Jelinek 1998). Walau bagaimanapun, pada mulanya, paradigma stokastik telah ketinggalan di belakang pendekatan simbolik kepada NLP, menunjukkan hanya kejayaan sederhana dalam model mainan dengan aplikasi terhad.
Satu lagi batu loncatan teori yang penting di jalan menuju model bahasa moden ialah apa yang dipanggil hipotesis pengedaran, pertama kali dicadangkan oleh ahli bahasa Zellig Harris pada tahun 1950-an (Harris 1954). Idea ini didasarkan pada pandangan strukturalis bahasa, yang berpendapat bahawa unit linguistik memperoleh makna melalui pola kejadian bersama dengan unit lain dalam sistem. Harris secara khusus mencadangkan bahawa makna sesuatu perkataan boleh disimpulkan dengan meneliti sifat pengedarannya, atau konteks di mana ia berlaku. Firth (1957) dengan tepat merumuskan hipotesis ini dengan slogan "Anda akan tahu perkataan oleh syarikat yang disimpannya," mengakui pengaruh konsep Wittgenstein (1953) tentang makna-sebagai-guna untuk menyerlahkan kepentingan konteks dalam memahami makna linguistik.
Apabila penyelidikan mengenai hipotesis pengedaran berkembang, para sarjana mula meneroka kemungkinan mewakili makna perkataan sebagai vektor dalam ruang multidimensi 1. Kerja empirikal awal dalam bidang ini berpunca daripada psikologi dan meneliti makna perkataan sepanjang pelbagai dimensi, seperti valensi dan potensi (Osgood 1952). Walaupun kerja ini memperkenalkan idea untuk mewakili makna dalam ruang vektor berbilang dimensi, ia bergantung pada penilaian peserta yang jelas tentang konotasi perkataan sepanjang skala yang berbeza (cth, baik-buruk), dan bukannya menganalisis sifat pengedaran korpus linguistik. Penyelidikan seterusnya dalam pencarian maklumat menggabungkan perwakilan berasaskan vektor dengan pendekatan dipacu data, membangunkan teknik automatik untuk mewakili dokumen dan perkataan sebagai vektor dalam ruang vektor berdimensi tinggi (Salton et al. 1975).
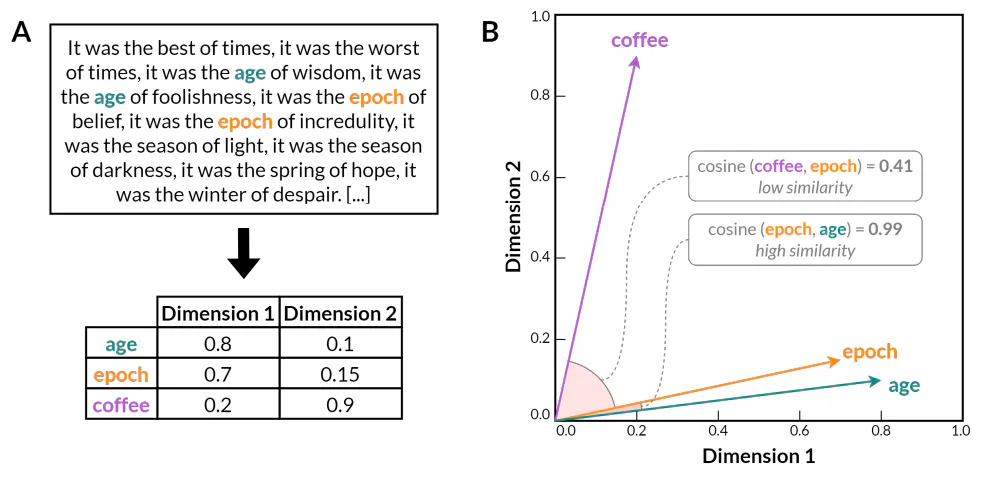
Selepas beberapa dekad penyelidikan eksperimental, idea-idea ini akhirnya mencapai kematangan dengan pembangunan model pembenaman perkataan menggunakan rangkaian saraf tiruan (Bengio et al. 2000). Model-model ini adalah berdasarkan pandangan bahawa sifat pengedaran perkataan boleh dipelajari dengan melatih rangkaian saraf untuk meramalkan konteks perkataan memandangkan perkataan itu sendiri, atau sebaliknya. Tidak seperti kaedah statistik sebelumnya seperti model n-gram, model pembenaman perkataan mengekod perkataan ke dalam perwakilan vektor berdimensi rendah yang padat (Rajah 1). Ruang vektor yang terhasil secara drastik mengurangkan dimensi data linguistik sambil mengekalkan maklumat tentang hubungan linguistik yang bermakna melangkaui statistik kejadian bersama yang mudah. Terutama, banyak hubungan semantik dan sintaksis antara perkataan dicerminkan dalam substruktur linear dalam ruang vektor model pembenaman perkataan. Sebagai contoh, Word2Vec (Mikolov et al. 2013) menunjukkan bahawa embeddings perkataan boleh menangkap kedua-dua keteraturan semantik dan sintaksis, seperti yang dibuktikan oleh keupayaan untuk menyelesaikan tugasan analogi perkataan melalui aritmetik vektor ringkas yang mendedahkan struktur linguistik terpendam yang dikodkan dalam ruang vektor (cth, 𝑘𝑖𝑛𝑖𝑛 𝑤𝑜𝑚𝑎𝑛 − 𝑚𝑎𝑛 ≈ 𝑞𝑢𝑒𝑒𝑛, atau 𝑤𝑎𝑙𝑘𝑖𝑛𝑔𝑠 𝑤𝑎𝑙𝑘𝑒𝑑 ≈ 𝑠𝑤𝑖𝑚𝑚𝑖𝑛𝑔).
Perkembangan model pembenaman perkataan menandakan titik perubahan dalam sejarah NLP, menyediakan cara yang berkuasa dan cekap untuk mewakili unit linguistik dalam ruang vektor berterusan berdasarkan taburan statistik mereka dalam korpus besar. Walau bagaimanapun, model ini mempunyai beberapa batasan yang ketara. Pertama, mereka tidak mampu menangkap polisemi dan homonimi, kerana mereka menetapkan a

pembenaman tunggal atau "statik" pada setiap jenis perkataan, yang tidak dapat menjelaskan perubahan dalam makna berdasarkan konteks; sebagai contoh, "bank" diberikan pembenaman unik tanpa mengira sama ada ia merujuk kepada tepi sungai atau institusi kewangan. Kedua, mereka bergantung pada seni bina rangkaian saraf tiruan "cetek" dengan satu lapisan tersembunyi, yang mengehadkan keupayaan mereka untuk memodelkan hubungan kompleks antara perkataan. Akhirnya, direka bentuk untuk mewakili bahasa pada peringkat perkataan individu, ia tidak sesuai untuk memodelkan ungkapan linguistik yang kompleks, seperti frasa, ayat dan perenggan. Walaupun adalah mungkin untuk mewakili ayat sebagai vektor dengan meratakan benam setiap perkataan dalam ayat, ini adalah cara yang sangat buruk untuk mewakili makna peringkat ayat, kerana ia kehilangan maklumat tentang struktur gubahan yang ditunjukkan dalam susunan perkataan. Dalam erti kata lain, model pembenaman perkataan hanya menganggap bahasa sebagai "beg perkataan"; contohnya, "buku undang-undang" dan "undang-undang buku" dianggap sama sebagai set tidak tertib {'a','book','law'}.
Kelemahan model pembenaman perkataan cetek telah ditangani dengan pengenalan model bahasa "mendalam", kembali kepada rangkaian saraf berulang (RNN) dan variannya, seperti ingatan jangka pendek panjang (LSTM) (Hochreiter & Schmidhuber 1997) dan unit berulang berpagar (GRU) (Cho et al.). Seni bina rangkaian saraf dalam ini menggabungkan mekanisme seperti ingatan, membolehkan mereka mengingati dan memproses urutan input dari semasa ke semasa, dan bukannya perkataan terpencil secara individu. Walaupun kelebihan ini berbanding model pembenaman perkataan, mereka mengalami batasan mereka sendiri: mereka lambat untuk melatih dan bergelut dengan urutan teks yang panjang. Isu-isu ini telah ditangani dengan pengenalan seni bina Transformer oleh Vaswani et al. (2017), yang meletakkan asas untuk LLM moden.
Kertas kerja ini boleh didapati di arxiv di bawah lesen CC BY 4.0 DEED.




