






















Автори:
(1) Рафаел Милиер, Катедра за филозофија, Универзитетот Мекквари ([email protected]);
(2) Камерон Бакнер, Катедра за филозофија, Универзитетот во Хјустон ([email protected]).
Табела со врски
2. Прајмер на LLM
2.2. LLM базирани на трансформатори
3. Интерфејс со класични филозофски прашања
3.2. Нативизам и усвојување јазик
3.3. Јазично разбирање и заземјување
3.5. Пренос на културни знаења и лингвистички скелиња
4. Заклучок, речник и референци
2.1. Историски основи
Потеклото на големите јазични модели може да се проследи уште од почетокот на истражувањето за вештачка интелигенција. Раната историја на обработката на природниот јазик (НЛП) беше обележана со раскол помеѓу две конкурентни парадигми: симболичкиот и стохастичкиот пристап. Големо влијание врз симболичката парадигма во НЛП имаше трансформациско-генеративната граматика на Ноам Чомски (Чомски 1957), кој постави дека синтаксата на природните јазици може да се доловува со збир на формални правила кои генерираат добро формирани реченици. Работата на Чомски ја постави основата за развој на синтаксички анализатори засновани на правила, кои ја користат лингвистичката теорија за разложување на речениците на нивните составни делови. Раните разговорни НЛП системи, како што е SHRDLU на Виноград (Виноград 1971), бараа синтаксички парсери со комплексен сет на ад хок правила за обработка на внесувањето на корисникот.
Паралелно, стохастичката парадигма беше пионерска од истражувачи како што е математичарот Ворен Вивер, кој беше под влијание на информациската теорија на Клод Шенон. Во меморандум напишан во 1949 година, Вивер предложи употреба на компјутери за машинско преведување со помош на статистички техники (Вивер 1955). Оваа работа го отвори патот за развој на статистички јазични модели, како што се моделите на n-грам, кои ја проценуваат веројатноста за секвенци на зборови врз основа на набљудуваните фреквенции на комбинации на зборови во корпус (Јелинек 1998). Првично, сепак, стохастичката парадигма заостануваше зад симболичните пристапи кон НЛП, покажувајќи само скромен успех во моделите на играчки со ограничени апликации.
Друга важна теоретска отскочна штица на патот кон модерните јазични модели е таканаречената дистрибутивна хипотеза, првпат предложена од лингвистот Зелиг Харис во 1950-тите (Harris 1954). Оваа идеја беше втемелена во структуралистичкиот поглед на јазикот, кој претпоставува дека лингвистичките единици добиваат значење преку нивните обрасци на ко-настанување со другите единици во системот. Харис конкретно сугерираше дека значењето на зборот може да се заклучи со испитување на неговите дистрибутивни својства или контекстите во кои се појавува. Фирт (1957) соодветно ја сумираше оваа хипотеза со слоганот „Ќе знаеш збор од компанијата што ја чува“, признавајќи го влијанието на концепцијата на значењето-како употреба на Витгенштајн (1953) за да се нагласи важноста на контекстот во разбирањето на јазичното значење.
Како што напредуваше истражувањето на хипотезата за дистрибуција, научниците почнаа да ја истражуваат можноста за претставување на значењата на зборовите како вектори во повеќедимензионален простор 1. Раната емпириска работа во оваа област произлезе од психологијата и го испитуваше значењето на зборовите по различни димензии, како што се валентноста и моќта (Осгуд 1952). Додека оваа работа ја воведе идејата за претставување на значењето во повеќедимензионален векторски простор, таа се потпираше на експлицитни оценки на учесниците за конотации на зборови по различни размери (на пр. добро-лошо), наместо да ги анализира дистрибутивните својства на лингвистичкиот корпус. Последователните истражувања во пронаоѓањето информации комбинираа репрезентации базирани на вектор со пристап заснован на податоци, развивајќи автоматизирани техники за претставување на документи и зборови како вектори во високодимензионални векторски простори (Salton et al. 1975).
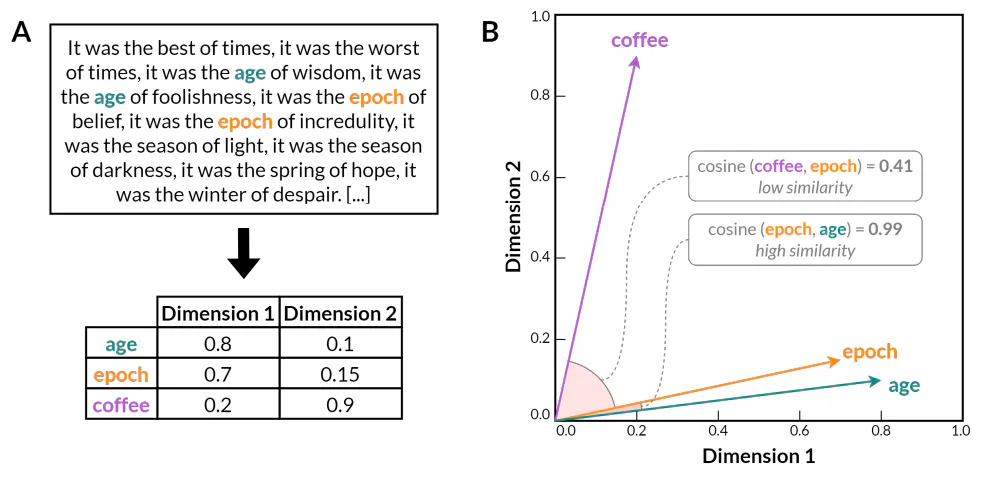
По децении експериментално истражување, овие идеи на крајот достигнаа зрелост со развојот на модели за вградување зборови користејќи вештачки невронски мрежи (Bengio et al. 2000). Овие модели се засноваат на увидот дека дистрибутивните својства на зборовите може да се научат со обука на невронска мрежа да го предвиди контекстот на зборот со оглед на самиот збор, или обратно. За разлика од претходните статистички методи како што се моделите n-грам, моделите за вградување зборови ги кодираат зборовите во густи, нискодимензионални векторски претстави (сл. 1). Резултирачкиот векторски простор драстично ја намалува димензионалноста на лингвистичките податоци додека ги зачувува информациите за значајните јазични односи надвор од едноставна статистика за истовремена појава. Забележително, многу семантички и синтаксички врски меѓу зборовите се рефлектираат во линеарни потструктури во рамките на векторскиот простор на моделите за вградување зборови. На пример, Word2Vec (Mikolov et al. 2013) покажа дека вградувањето на зборови може да ги опфати и семантичките и синтаксичките законитости, како што е потврдено со способноста да се решаваат задачи за аналогија на зборови преку едноставна векторска аритметика што ја открива латентната лингвистичка структура кодирана во векторскиот простор (на пр., 𝑘 𝑤𝑜𝑚𝑎𝑛 − 𝑚𝑎𝑛 ≈ 𝑞𝑢𝑒𝑒𝑛 или 𝑤𝑎𝑙𝑘𝑖𝑛𝑔 𝑤𝑎𝑙𝑘𝑒𝑑 ≈ 𝑠𝑤𝑖𝑚𝑚𝑖𝑛𝑔).
Развојот на моделите за вградување зборови означи пресвртница во историјата на НЛП, обезбедувајќи моќно и ефикасно средство за претставување на јазичните единици во континуиран векторски простор врз основа на нивната статистичка дистрибуција во голем корпус. Сепак, овие модели имаат неколку значајни ограничувања. Прво, тие не се способни да доловат полисемија и хомонимија, бидејќи доделуваат а

единечно или „статичко“ вметнување во секој тип на збор, што не може да ги објасни промените во значењето врз основа на контекстот; на пример, на „банката“ му е доделено единствено вградување без разлика дали се однесува на страната на реката или на финансиската институција. Второ, тие се потпираат на „плитки“ архитектури на вештачки невронски мрежи со еден скриен слој, што ја ограничува нивната способност да моделираат сложени односи меѓу зборовите. Конечно, бидејќи се дизајнирани да го претставуваат јазикот на ниво на поединечни зборови, тие не се добро прилагодени за моделирање на сложени јазични изрази, како што се фрази, реченици и параграфи. Иако е можно да се претстави реченицата како вектор со просечно внесување на секој збор во реченицата, ова е многу лош начин на претставување на значењето на ниво на реченица, бидејќи ги губи информациите за структурата на составот рефлектирана во редоследот на зборовите. Со други зборови, моделите за вградување зборови го третираат јазикот само како „вреќа со зборови“; на пример, „правна книга“ и „закон за книги“ се третираат идентично како неуреденото множество {'a','book',' law'}.
Недостатоците на моделите за вградување на плитки зборови беа решени со воведувањето на „длабоки“ јазични модели, враќајќи се на рекурентните невронски мрежи (RNN) и нивните варијанти, како што се долгата краткорочна меморија (LSTM) (Hochreiter & Schmidhuber 1997) и затворената рекурентна единица (GRU) (Cho 20). Овие архитектури на длабоки невронски мрежи вклучуваат механизам сличен на меморија, овозможувајќи им да запомнат и обработуваат низи од влезови со текот на времето, наместо поединечни, изолирани зборови. И покрај оваа предност во однос на моделите за вградување зборови, тие страдаат од свои ограничувања: бавни се во тренирање и се борат со долги секвенци на текст. Овие прашања беа решени со воведувањето на архитектурата Transformer од Vaswani et al. (2017), што ги постави темелите за современите LLM.
Овој труд е достапен на arxiv под лиценца CC BY 4.0 DEED.




