






















مصنفین:
(1) Raphaël Millière, Department of Philosophy, Macquarie University ([email protected])؛
(2) کیمرون بکنر، شعبہ فلسفہ، یونیورسٹی آف ہیوسٹن ([email protected])۔
لنکس کی میز
2. LLMs پر ایک پرائمر
3. کلاسک فلسفیانہ مسائل کے ساتھ انٹرفیس
3.5 ثقافتی علم اور لسانی سہاروں کی ترسیل
2.1 تاریخی بنیادیں۔
بڑے زبان کے ماڈلز کی ابتدا AI تحقیق کے آغاز سے ہی کی جا سکتی ہے۔ نیچرل لینگویج پروسیسنگ (NLP) کی ابتدائی تاریخ کو دو مسابقتی تمثیلوں کے درمیان فرق سے نشان زد کیا گیا تھا: علامتی اور اسٹاکسٹک نقطہ نظر۔ NLP میں علامتی تمثیل پر ایک بڑا اثر نوام چومسکی کا ٹرانسفارمیشنل جنریٹیو گرائمر (چومسکی 1957) تھا، جس نے کہا کہ فطری زبانوں کے نحو کو رسمی اصولوں کے ایک سیٹ کے ذریعے حاصل کیا جا سکتا ہے جو اچھی طرح سے جملے تیار کرتے ہیں۔ چومسکی کے کام نے اصول پر مبنی نحوی تجزیہ کاروں کی ترقی کی بنیاد رکھی، جو کہ لسانی نظریہ کو ان کے جزوی حصوں میں تحلیل کرنے کے لیے استعمال کرتے ہیں۔ ابتدائی بات چیت کے NLP نظام، جیسے Winograd's SHRDLU (Winograd 1971)، کو صارف کے ان پٹ پر کارروائی کرنے کے لیے ایڈہاک قواعد کے پیچیدہ سیٹ کے ساتھ نحوی تجزیہ کاروں کی ضرورت ہوتی ہے۔
متوازی طور پر، سٹاکسٹک پیراڈائم کا آغاز ریاضی دان وارن ویور جیسے محققین نے کیا، جو کلاڈ شینن کے انفارمیشن تھیوری سے متاثر تھے۔ 1949 میں لکھے گئے ایک میمورنڈم میں، ویور نے شماریاتی تکنیکوں (ویور 1955) کو استعمال کرنے والے مشینی ترجمہ کے لیے کمپیوٹر کے استعمال کی تجویز پیش کی۔ اس کام نے شماریاتی زبان کے ماڈلز کی ترقی کی راہ ہموار کی، جیسے کہ n-gram ماڈل، جو ایک کارپس (Jelinek 1998) میں الفاظ کے امتزاج کی مشاہدہ شدہ تعدد کی بنیاد پر الفاظ کی ترتیب کے امکانات کا اندازہ لگاتے ہیں۔ تاہم، ابتدائی طور پر، سٹاکسٹک پیراڈیم NLP کے لیے علامتی نقطہ نظر سے پیچھے تھا، جو محدود ایپلی کیشنز کے ساتھ کھلونا ماڈلز میں صرف معمولی کامیابی دکھا رہا تھا۔
جدید زبان کے ماڈلز کی راہ پر ایک اور اہم نظریاتی قدمی پتھر نام نہاد تقسیمی مفروضہ ہے، جسے سب سے پہلے ماہر لسانیات زیلیگ ہیرس نے 1950 کی دہائی میں تجویز کیا تھا (Harris 1954)۔ اس خیال کی بنیاد زبان کے ساختیاتی نقطہ نظر پر رکھی گئی تھی، جس میں کہا گیا ہے کہ لسانی اکائیاں نظام میں دیگر اکائیوں کے ساتھ ہم آہنگی کے اپنے نمونوں کے ذریعے معنی حاصل کرتی ہیں۔ ہیریس نے خاص طور پر تجویز کیا کہ کسی لفظ کے معنی اس کی تقسیمی خصوصیات یا ان سیاق و سباق کی جانچ کر کے لگائے جا سکتے ہیں جن میں یہ واقع ہوتا ہے۔ فرتھ (1957) نے اس مفروضے کا مناسب طور پر اس نعرے کے ساتھ خلاصہ کیا کہ "آپ کو اس کمپنی کی طرف سے ایک لفظ معلوم ہوگا جو یہ رکھتا ہے،" وٹگنسٹین (1953) کے معنی کے طور پر استعمال کے تصور کے اثر کو تسلیم کرتے ہوئے لسانی معنی کو سمجھنے میں سیاق و سباق کی اہمیت کو اجاگر کیا۔
جیسے جیسے تقسیمی مفروضے پر تحقیق آگے بڑھی، اسکالرز نے کثیر جہتی جگہ میں لفظ کے معنی ویکٹر کے طور پر پیش کرنے کے امکان کو تلاش کرنا شروع کیا۔ 1۔ اس علاقے میں ابتدائی تجرباتی کام نفسیات سے ہوا اور مختلف جہتوں کے ساتھ الفاظ کے معنی کا جائزہ لیا، جیسے کہ valence اور potency (Osgood 1952)۔ اگرچہ اس کام نے کثیر جہتی ویکٹر اسپیس میں معنی کی نمائندگی کرنے کا خیال متعارف کرایا، اس نے کسی لسانی کارپس کی تقسیمی خصوصیات کا تجزیہ کرنے کے بجائے مختلف پیمانوں (مثلاً، اچھا – برا) کے ساتھ الفاظ کے مفہوم کے بارے میں واضح شریک درجہ بندیوں پر انحصار کیا۔ معلومات کی بازیافت میں بعد کی تحقیق نے اعداد و شمار پر مبنی نقطہ نظر کے ساتھ ویکٹر پر مبنی نمائندگی کو یکجا کیا، اعلی جہتی ویکٹر اسپیس میں ویکٹر کے طور پر دستاویزات اور الفاظ کی نمائندگی کرنے کے لیے خودکار تکنیک تیار کی (سالٹن ایٹ ال۔ 1975)۔
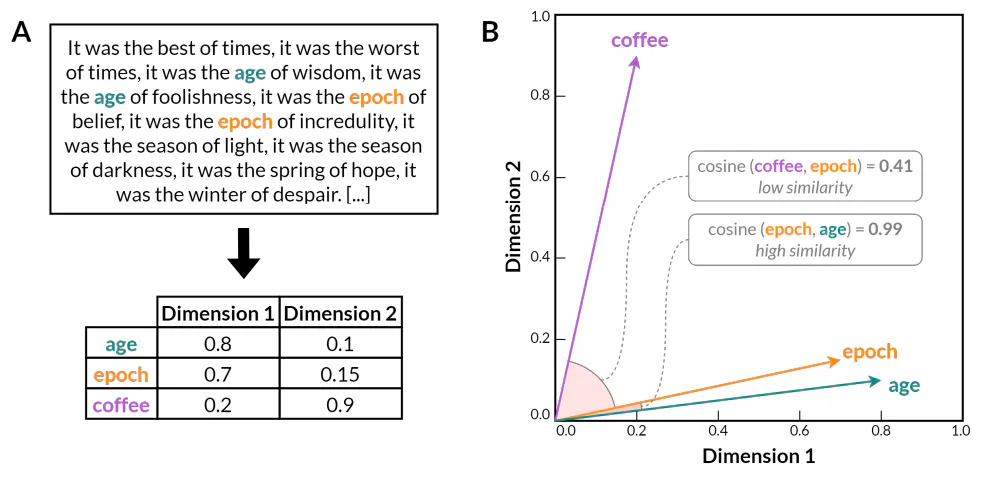
کئی دہائیوں کی تجرباتی تحقیق کے بعد، یہ خیالات بالآخر مصنوعی اعصابی نیٹ ورکس (Bengio et al. 2000) کا استعمال کرتے ہوئے لفظ سرایت کرنے والے ماڈلز کی ترقی کے ساتھ پختگی کو پہنچ گئے۔ یہ ماڈل اس بصیرت پر مبنی ہیں کہ الفاظ کی تقسیم کی خصوصیات کو ایک عصبی نیٹ ورک کی تربیت دے کر سیکھا جا سکتا ہے تاکہ لفظ کے سیاق و سباق کی پیشین گوئی خود لفظ کو دیا جائے، یا اس کے برعکس۔ پچھلے شماریاتی طریقوں کے برعکس جیسے کہ n-gram ماڈلز، لفظ سرایت کرنے والے ماڈل الفاظ کو گھنے، کم جہتی ویکٹر کی نمائندگی میں انکوڈ کرتے ہیں (تصویر 1)۔ نتیجہ خیز ویکٹر اسپیس لسانی اعداد و شمار کی جہت کو کافی حد تک کم کر دیتا ہے جبکہ بامعنی لسانی رشتوں کے بارے میں معلومات کو عام ہم آہنگی کے اعدادوشمار سے باہر محفوظ رکھتا ہے۔ خاص طور پر، الفاظ کے درمیان بہت سے معنوی اور نحوی تعلقات ورڈ ایمبیڈنگ ماڈلز کے ویکٹر اسپیس کے اندر لکیری ذیلی ساخت میں جھلکتے ہیں۔ مثال کے طور پر، Word2Vec (Mikolov et al. 2013) نے یہ ظاہر کیا کہ لفظ ایمبیڈنگز لفظی اور نحوی دونوں طرح کے معمولات کو حاصل کر سکتے ہیں، جیسا کہ سادہ ویکٹر ریاضی کے ذریعے لفظ تشبیہ کے کاموں کو حل کرنے کی صلاحیت سے ظاہر ہوتا ہے جو ویکٹر اسپیس میں انکوڈ شدہ اویکت لسانی ساخت کو ظاہر کرتا ہے (مثال کے طور پر، +👔 𝑤𝑜𝑚𝑎𝑛 − 𝑚𝑎𝑛 ≈ 𝑞𝑢𝑒𝑒𝑛، یا 𝑤𝑎𝑙𝑘𝑖𝑛𝑔 + 𝑚𝑎𝑛 𝑤𝑎𝑙𝑘𝑒𝑑 ≈ 𝑠𝑤𝑖𝑚𝑚𝑖𝑛𝑔)۔
ورڈ ایمبیڈنگ ماڈلز کی ترقی نے NLP کی تاریخ میں ایک اہم موڑ کا نشان لگایا، جو کہ ایک بڑے کارپس میں ان کی شماریاتی تقسیم کی بنیاد پر مسلسل ویکٹر اسپیس میں لسانی اکائیوں کی نمائندگی کرنے کا ایک طاقتور اور موثر ذریعہ فراہم کرتا ہے۔ تاہم، ان ماڈلز میں کئی اہم حدود ہیں۔ سب سے پہلے، وہ polysemy اور homonymy پر قبضہ کرنے کے قابل نہیں ہیں، کیونکہ وہ a تفویض کرتے ہیں۔

ہر لفظ کی قسم میں واحد یا "جامد" سرایت کرنا، جو سیاق و سباق کی بنیاد پر معنی میں تبدیلیوں کا حساب نہیں دے سکتا۔ مثال کے طور پر، "بینک" کو ایک منفرد سرایت تفویض کی گئی ہے اس سے قطع نظر کہ اس کا مطلب کسی دریا کے کنارے یا مالیاتی ادارے سے ہے۔ دوسرا، وہ ایک ہی پوشیدہ پرت کے ساتھ "اتلی" مصنوعی عصبی نیٹ ورک کے فن تعمیر پر انحصار کرتے ہیں، جو الفاظ کے درمیان پیچیدہ تعلقات کو ماڈل کرنے کی ان کی صلاحیت کو محدود کرتی ہے۔ آخر میں، انفرادی الفاظ کی سطح پر زبان کی نمائندگی کرنے کے لیے ڈیزائن کیا گیا ہے، وہ پیچیدہ لسانی اظہار، جیسے کہ جملے، جملے اور پیراگراف کے لیے موزوں نہیں ہیں۔ اگرچہ جملے میں ہر لفظ کی سرایت کی اوسط سے کسی جملے کی بطور ویکٹر نمائندگی کرنا ممکن ہے، لیکن یہ جملے کی سطح کے معنی کی نمائندگی کرنے کا ایک بہت ہی ناقص طریقہ ہے، کیونکہ یہ لفظی ترتیب میں جھلکتی ساختی ساخت کے بارے میں معلومات کھو دیتا ہے۔ دوسرے لفظوں میں، لفظ سرایت کرنے والے ماڈلز صرف زبان کو "الفاظ کے تھیلے" کے طور پر دیکھتے ہیں۔ مثال کے طور پر، "ایک قانون کی کتاب" اور "ایک کتاب کا قانون" کو غیر ترتیب شدہ سیٹ {'a','book','law'} کے طور پر ایک جیسا سمجھا جاتا ہے۔
اتھلے الفاظ کے سرایت کرنے والے ماڈلز کی خامیوں کو "گہری" زبان کے ماڈلز کے تعارف کے ساتھ دور کیا گیا، جو بار بار چلنے والے نیورل نیٹ ورکس (RNNs) اور ان کی مختلف حالتوں، جیسے طویل مختصر مدتی میموری (LSTM) (Hochreiter & Schmidhuber 1997) اور گیٹڈ ریکرنٹ یونٹ (GRU) (Choet14). یہ گہرے عصبی نیٹ ورک کے فن تعمیر میں میموری جیسا میکانزم شامل کیا جاتا ہے، جس سے وہ انفرادی، الگ تھلگ الفاظ کے بجائے وقت کے ساتھ ساتھ ان پٹ کی ترتیب کو یاد رکھنے اور اس پر کارروائی کرنے کی اجازت دیتے ہیں۔ ورڈ ایمبیڈنگ ماڈلز پر اس فائدے کے باوجود، وہ اپنی حدود سے دوچار ہیں: وہ تربیت دینے میں سست ہیں اور متن کے طویل سلسلے کے ساتھ جدوجہد کرتے ہیں۔ واسوانی وغیرہ کے ذریعہ ٹرانسفارمر فن تعمیر کے تعارف کے ساتھ ان مسائل کو حل کیا گیا۔ (2017)، جس نے جدید LLMs کی بنیاد رکھی۔
یہ کاغذ CC BY 4.0 DEED لائسنس کے تحت arxiv پر دستیاب ہے۔








