

























上下文老虎机是一类用于决策模型的强化学习算法,学习者必须选择能带来最大回报的行动。它们以赌博中经典的“单臂强盗”问题命名,即玩家需要决定玩哪些老虎机、每台老虎机玩多少次以及玩它们的顺序。


上下文强盗的与众不同之处在于,决策过程是根据上下文进行的。在这种情况下,上下文指的是一组可以影响操作结果的可观察变量。这一添加使得强盗问题更接近现实世界的应用,例如个性化推荐、临床试验或广告投放,其中的决定取决于具体情况。
上下文强盗问题的表述
上下文强盗问题可以使用各种算法来实现。下面,我提供了上下文老虎机问题的算法结构的总体高级概述:

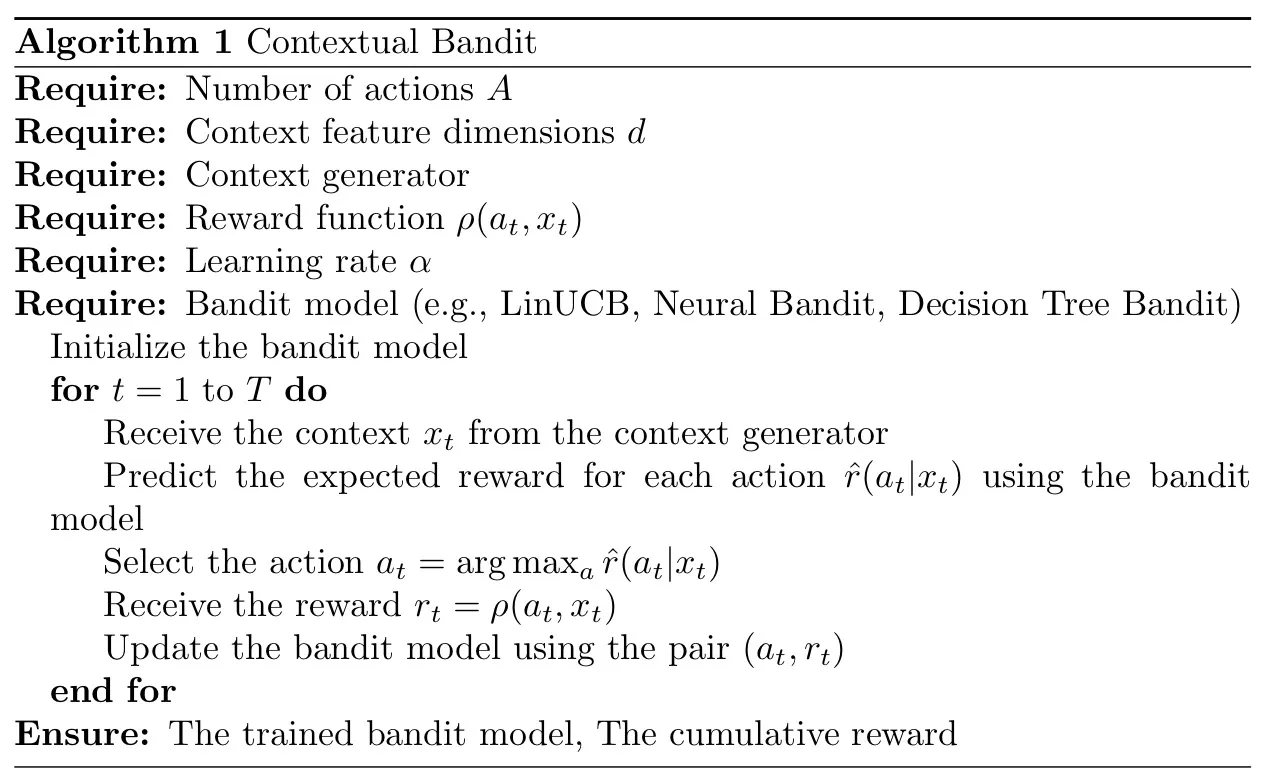
下面的算法是上下文强盗问题的基础数学:


综上所述,一般来说,算法的目标是在一段时间内最大化累积奖励。请注意,在每一轮中,仅观察所选操作的奖励。这被称为部分反馈,它将老虎机问题与监督学习区分开来。
解决上下文强盗问题的最常见方法涉及平衡探索和利用。利用意味着利用当前的知识做出最佳决策,而探索则意味着采取不太确定的行动来收集更多信息。
探索和利用之间的权衡体现在旨在解决上下文强盗问题的各种算法中,例如 LinUCB、神经强盗或决策树强盗。所有这些算法都采用其独特的策略来解决这种权衡问题。
Bandit 的这个想法的代码表示是:
class Bandit: def __init__(self, n_actions, n_features): self.n_actions = n_actions self.n_features = n_features self.theta = np.random.randn(n_actions, n_features) def get_reward(self, action, x): return x @ self.theta[action] + np.random.normal() def get_optimal_reward(self, x): return np.max(x @ self.theta.T) # Usage example # Define the bandit environment n_actions = 10 n_features = 5 bandit = Bandit(n_actions, n_features) # Define the model agent model_agent = model(n_features, *args) # Define the context (features) x = np.random.randn(n_features) # The agent makes a prediction pred_rewards = np.array([model_agent.predict(x) for _ in range(n_actions)]) # The agent chooses an action action = np.argmax(pred_rewards) # The agent gets a reward reward = bandit.get_reward(action, x) # The agent updates its parameters model_agent.update(x, reward)LinUCB算法
LinUCB 算法是一种上下文老虎机算法,它将给定上下文的操作的预期奖励建模为线性函数,并根据上置信界 (UCB) 原则选择操作以平衡探索和利用。它根据当前模型(线性模型)利用可用的最佳选项,但考虑到模型估计的不确定性,它也探索可能提供更高奖励的选项。从数学上讲,它可以表示为:


这种方法确保算法探索具有高度不确定性的动作。
选择动作并收到奖励后,LinUCB 更新参数如下:


下面是 Python 中的代码实现:
import numpy as np class LinUCB: def __init__(self, n_actions, n_features, alpha=1.0): self.n_actions = n_actions self.n_features = n_features self.alpha = alpha # Initialize parameters self.A = np.array( [np.identity(n_features) for _ in range(n_actions)] ) # action covariance matrix self.b = np.array( [np.zeros(n_features) for _ in range(n_actions)] ) # action reward vector self.theta = np.array( [np.zeros(n_features) for _ in range(n_actions)] ) # action parameter vector def predict(self, context): context = np.array(context) # Convert list to ndarray context = context.reshape( -1, 1 ) # reshape the context to a single-column matrix p = np.zeros(self.n_actions) for a in range(self.n_actions): theta = np.dot( np.linalg.inv(self.A[a]), self.b[a] ) # theta_a = A_a^-1 * b_a theta = theta.reshape(-1, 1) # Explicitly reshape theta p[a] = np.dot(theta.T, context) + self.alpha * np.sqrt( np.dot(context.T, np.dot(np.linalg.inv(self.A[a]), context)) ) # p_t(a|x_t) = theta_a^T * x_t + alpha * sqrt(x_t^T * A_a^-1 * x_t) return p def update(self, action, context, reward): self.A[action] += np.outer(context, context) # A_a = A_a + x_t * x_t^T self.b[action] += reward * context # b_a = b_a + r_t * x_tx决策树算法
Decision Tree Bandit 将奖励函数建模为决策树,其中每个叶节点对应一个操作,从根到叶节点的每条路径表示基于上下文的决策规则。它通过统计框架进行探索和利用,根据统计显着性测试在决策树中进行拆分和合并。


目标是学习最大化预期累积奖励的最佳决策树:


决策树学习通常涉及两个步骤:
- 树生长:从单个节点(根)开始,根据特征和最大化预期奖励的阈值递归地分割每个节点。此过程持续进行,直到满足某些停止条件,例如达到最大深度或每片叶子的最小样本数。
- 树修剪:从完全生长的树开始,如果每个节点的子节点显着增加或没有显着减少预期奖励,则递归地合并该节点的子节点。该过程持续进行,直到无法进行进一步的合并为止。
分裂准则和合并准则通常基于统计检验来定义,以确保改进的统计显着性。
from sklearn.tree import DecisionTreeRegressor class DecisionTreeBandit: def __init__(self, n_actions, n_features, max_depth=5): self.n_actions = n_actions self.n_features = n_features self.max_depth = max_depth # Initialize the decision tree model for each action self.models = [ DecisionTreeRegressor(max_depth=self.max_depth) for _ in range(n_actions) ] self.data = [[] for _ in range(n_actions)] def predict(self, context): return np.array( [self._predict_for_action(a, context) for a in range(self.n_actions)] ) def _predict_for_action(self, action, context): if not self.data[action]: return 0.0 X, y = zip(*self.data[action]) self.models[action].fit(np.array(X), np.array(y)) context_np = np.array(context).reshape( 1, -1 ) # convert list to NumPy array and reshape return self.models[action].predict(context_np)[0] def update(self, action, context, reward): self.data[action].append((context, reward))对于 DecisionTreeBandit, predict方法使用当前模型参数来预测给定上下文的每个操作的预期奖励。 update方法根据从所选操作中观察到的奖励来更新模型参数。此实现使用scikit-learn来实现 DecisionTreeBandit。
具有神经网络的上下文强盗
深度学习模型可用于近似高维或非线性情况下的奖励函数。该策略通常是一个神经网络,它将上下文和可用操作作为输入并输出采取每个操作的概率。
一种流行的深度学习方法是使用演员-评论家架构,其中一个网络(演员)决定采取哪个行动,另一个网络(批评家)评估演员采取的行动。
对于上下文和奖励之间的关系不是线性的更复杂的场景,我们可以使用神经网络对奖励函数进行建模。一种流行的方法是使用策略梯度方法,例如 REINFORCE 或 actor-critic。


总结如下 Neural Bandit 使用神经网络对奖励函数进行建模,同时考虑到神经网络参数的不确定性。它进一步引入了通过策略梯度的探索,其中它朝着更高奖励的方向更新策略。这种形式的探索更具针对性,这在大型行动空间中可能是有益的。
最简单的代码实现如下:
import torch import torch.nn as nn import torch.optim as optim class NeuralNetwork(nn.Module): def __init__(self, n_features): super(NeuralNetwork, self).__init__() self.layer = nn.Sequential( nn.Linear(n_features, 32), nn.ReLU(), nn.Linear(32, 1) ) def forward(self, x): return self.layer(x) class NeuralBandit: def __init__(self, n_actions, n_features, learning_rate=0.01): self.n_actions = n_actions self.n_features = n_features self.learning_rate = learning_rate # Initialize the neural network model for each action self.models = [NeuralNetwork(n_features) for _ in range(n_actions)] self.optimizers = [ optim.Adam(model.parameters(), lr=self.learning_rate) for model in self.models ] self.criterion = nn.MSELoss() def predict(self, context): context_tensor = torch.tensor(context, dtype=torch.float32) # Convert to tensor with torch.no_grad(): return torch.cat( [model(context_tensor).reshape(1) for model in self.models] ) def update(self, action, context, reward): self.optimizers[action].zero_grad() context_tensor = torch.tensor(context, dtype=torch.float32) # Convert to tensor reward_tensor = torch.tensor(reward, dtype=torch.float32) # Convert to tensor pred_reward = self.models[action](context_tensor) loss = self.criterion(pred_reward, reward_tensor) loss.backward() self.optimizers[action].step()对于 NeuralBandit,具有predict方法和update方法的相同图片,使用当前模型参数来预测给定上下文的每个动作的预期奖励,并根据从所选动作观察到的奖励更新模型参数。此实现使用 PyTorch 进行 NeuralBandit。
模型性能比较
每个模型都有其独特的优点和缺点,模型的选择取决于当前问题的具体要求。让我们深入研究其中一些模型的细节,然后比较它们的性能。
林UCB
线性置信上限 (LinUCB) 模型使用线性回归来估计给定上下文中每个操作的预期奖励。它还跟踪这些估计的不确定性,并用它来鼓励探索。
优点:
它简单且计算效率高。
它为其遗憾界限提供了理论保证。
缺点:
- 它假设奖励函数是上下文和动作的线性函数,这可能不适用于更复杂的问题。
决策树强盗
决策树强盗模型将奖励函数表示为决策树。每个叶子节点对应一个动作,从根到叶子节点的每条路径代表一个基于上下文的决策规则。
优点:
它提供了可解释的决策规则。
它可以处理复杂的奖励函数。
缺点:
- 它可能会受到过度拟合的影响,尤其是对于大树。
- 它需要调整超参数,例如树的最大深度。
神经强盗
Neural Bandit 模型使用神经网络来估计给定上下文的每个操作的预期奖励。它使用政策梯度方法来鼓励探索。
优点:
它可以处理复杂的非线性奖励函数。
它可以执行定向探索,这在大型行动空间中是有益的。
缺点:
- 它需要调整超参数,例如神经网络的架构和学习率。
- 它的计算成本可能很高,尤其是对于大型网络和大型动作空间。
代码对比及一般运行示例:
下面是 Python 代码,用于比较之前提到和定义的所有这些模型的 bandits 的性能,并为每个模型运行模拟。
import matplotlib.pyplot as plt # Define the bandit environment n_actions = 10 n_features = 5 bandit = Bandit(n_actions, n_features) # Define the agents linucb_agent = LinUCB(n_actions, n_features, alpha=0.1) neural_agent = NeuralBandit(n_actions, n_features, learning_rate=0.01) tree_agent = DecisionTreeBandit(n_actions, n_features, max_depth=5) # Run the simulation for each agent n_steps = 1000 agents = [linucb_agent, tree_agent, neural_agent] cumulative_rewards = {agent.__class__.__name__: np.zeros(n_steps) for agent in agents} cumulative_regrets = {agent.__class__.__name__: np.zeros(n_steps) for agent in agents} for agent in agents: print(agent) for t in range(n_steps): x = np.random.randn(n_features) pred_rewards = agent.predict([x]) action = np.argmax(pred_rewards) reward = bandit.get_reward(action, x) optimal_reward = bandit.get_optimal_reward(x) agent.update(action, x, reward) cumulative_rewards[agent.__class__.__name__][t] = ( reward if t == 0 else cumulative_rewards[agent.__class__.__name__][t - 1] + reward ) cumulative_regrets[agent.__class__.__name__][t] = ( optimal_reward - reward if t == 0 else cumulative_regrets[agent.__class__.__name__][t - 1] + optimal_reward - reward ) # Plot the results plt.figure(figsize=(12, 6)) plt.subplot(121) for agent_name, rewards in cumulative_rewards.items(): plt.plot(rewards, label=agent_name) plt.xlabel("Steps") plt.ylabel("Cumulative Rewards") plt.legend() plt.subplot(122) for agent_name, regrets in cumulative_regrets.items(): plt.plot(regrets, label=agent_name) plt.xlabel("Steps") plt.ylabel("Cumulative Regrets") plt.legend() plt.show() 

应用场景
- 个性化推荐:在这种情况下,上下文可以是用户信息(如年龄、性别、过去的购买记录)和商品信息(如商品类别、价格)。动作是推荐的商品,奖励是用户是否点击或购买了该商品。上下文强盗算法可用于学习最大化点击率或收入的个性化推荐策略。
- 临床试验:在临床试验中,上下文可以是患者信息(如年龄、性别、病史),操作是不同的治疗方法,奖励是健康结果。上下文强盗算法可以学习最大化患者健康结果、平衡治疗效果和副作用的治疗策略。
- 在线广告:在线广告中,上下文可以是用户信息和广告信息,动作是要展示的广告,奖励是用户是否点击广告。考虑到广告相关性和用户偏好,上下文强盗算法可以学习最大化点击率或收入的策略。
在每个应用程序中,平衡探索和利用都至关重要。利用是根据当前知识选择最佳操作,而探索是尝试不同的操作以获得更多知识。上下文强盗算法提供了一个框架来形式化和解决这种探索-利用权衡。
结论
上下文强盗是在反馈有限的环境中进行决策的强大工具。与传统老虎机算法相比,在决策中利用上下文的能力可以做出更复杂、更细致的决策。
虽然我们没有明确比较性能,但我们注意到算法的选择应该受到问题特征的影响。对于更简单的关系,LinUCB 和决策树可能表现出色,而神经网络在复杂场景中可能表现更出色。每种方法都具有独特的优势:LinUCB 具有数学简单性,决策树具有可解释性,神经网络具有处理复杂关系的能力。选择正确的方法是在这个令人兴奋的领域有效解决问题的关键。
总体而言,基于上下文的老虎机问题在强化学习中提出了一个引人入胜的领域,可以使用多种算法来解决这些问题,我们可以期望看到这些强大模型的更多创新用途。








