

























Os bandidos contextuais são uma classe de algoritmos de aprendizado por reforço usados em modelos de tomada de decisão em que um aluno deve escolher ações que resultem na maior recompensa. Eles receberam o nome do clássico problema do "bandido de um braço" do jogo, em que um jogador precisa decidir em quais caça-níqueis jogar, quantas vezes jogar em cada máquina e em que ordem jogá-las.


O que diferencia os bandidos contextuais é que o processo de tomada de decisão é informado pelo contexto. O contexto, neste caso, refere-se a um conjunto de variáveis observáveis que podem impactar o resultado da ação. Essa adição torna o problema do bandido mais próximo de aplicações do mundo real, como recomendações personalizadas, ensaios clínicos ou posicionamento de anúncios, em que a decisão depende de circunstâncias específicas.
A formulação dos problemas contextuais do bandido
O problema do bandido contextual pode ser implementado usando vários algoritmos. Abaixo, forneço uma visão geral de alto nível da estrutura algorítmica para problemas de bandidos contextuais:

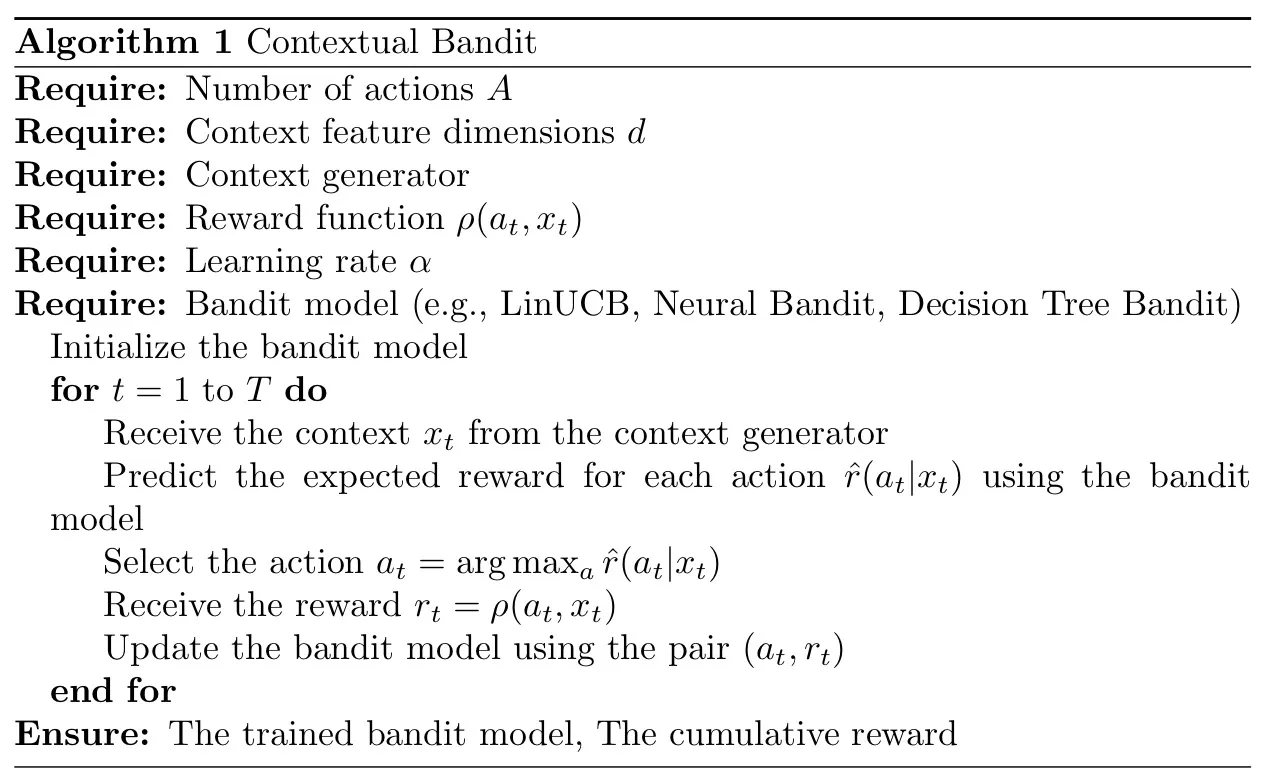
E o seguinte algoritmo aqui é a matemática subjacente do problema do bandido contextual:


Para resumir tudo acima, de um modo geral, o objetivo do algoritmo é maximizar a recompensa cumulativa ao longo de algum horizonte de tempo. Observe que em cada rodada, a recompensa apenas para a ação escolhida é observada. Isso é conhecido como feedback parcial, que diferencia problemas de bandidos de aprendizado supervisionado.
A abordagem mais comum para resolver um problema de bandido contextual envolve equilibrar exploração e aproveitamento. A exploração significa usar o conhecimento atual para tomar a melhor decisão, enquanto a exploração envolve a realização de menos ações certas para coletar mais informações.
O trade-off entre exploração e exploração se manifesta em vários algoritmos projetados para resolver o problema do Bandido Contextual, como LinUCB, Neural Bandit ou Decision Tree Bandit. Todos esses algoritmos empregam suas estratégias exclusivas para lidar com essa compensação.
A representação de código dessa ideia para o Bandit é:
class Bandit: def __init__(self, n_actions, n_features): self.n_actions = n_actions self.n_features = n_features self.theta = np.random.randn(n_actions, n_features) def get_reward(self, action, x): return x @ self.theta[action] + np.random.normal() def get_optimal_reward(self, x): return np.max(x @ self.theta.T) # Usage example # Define the bandit environment n_actions = 10 n_features = 5 bandit = Bandit(n_actions, n_features) # Define the model agent model_agent = model(n_features, *args) # Define the context (features) x = np.random.randn(n_features) # The agent makes a prediction pred_rewards = np.array([model_agent.predict(x) for _ in range(n_actions)]) # The agent chooses an action action = np.argmax(pred_rewards) # The agent gets a reward reward = bandit.get_reward(action, x) # The agent updates its parameters model_agent.update(x, reward)Algoritmo LinUCB
O algoritmo LinUCB é um algoritmo de bandido contextual que modela a recompensa esperada de uma ação, dado um contexto como uma função linear, e seleciona ações com base no princípio Upper Confidence Bound (UCB) para equilibrar exploração e exploração. Ele explora a melhor opção disponível de acordo com o modelo atual (que é um modelo linear), mas também explora opções que poderiam fornecer maiores recompensas, considerando a incerteza nas estimativas do modelo. Matematicamente pode ser apresentado como:


Essa abordagem garante que o algoritmo explore ações para as quais possui alta incerteza.
Depois de selecionar uma ação e receber uma recompensa, o LinUCB atualiza os parâmetros da seguinte forma:


E aqui está a implementação do código em Python:
import numpy as np class LinUCB: def __init__(self, n_actions, n_features, alpha=1.0): self.n_actions = n_actions self.n_features = n_features self.alpha = alpha # Initialize parameters self.A = np.array( [np.identity(n_features) for _ in range(n_actions)] ) # action covariance matrix self.b = np.array( [np.zeros(n_features) for _ in range(n_actions)] ) # action reward vector self.theta = np.array( [np.zeros(n_features) for _ in range(n_actions)] ) # action parameter vector def predict(self, context): context = np.array(context) # Convert list to ndarray context = context.reshape( -1, 1 ) # reshape the context to a single-column matrix p = np.zeros(self.n_actions) for a in range(self.n_actions): theta = np.dot( np.linalg.inv(self.A[a]), self.b[a] ) # theta_a = A_a^-1 * b_a theta = theta.reshape(-1, 1) # Explicitly reshape theta p[a] = np.dot(theta.T, context) + self.alpha * np.sqrt( np.dot(context.T, np.dot(np.linalg.inv(self.A[a]), context)) ) # p_t(a|x_t) = theta_a^T * x_t + alpha * sqrt(x_t^T * A_a^-1 * x_t) return p def update(self, action, context, reward): self.A[action] += np.outer(context, context) # A_a = A_a + x_t * x_t^T self.b[action] += reward * context # b_a = b_a + r_t * x_txAlgoritmo de Árvore de Decisão
O Decision Tree Bandit modela a função de recompensa como uma árvore de decisão, onde cada nó folha corresponde a uma ação e cada caminho da raiz a um nó folha representa uma regra de decisão baseada no contexto. Ele realiza exploração e exploração por meio de uma estrutura estatística, fazendo divisões e mesclagens na árvore de decisão com base em testes de significância estatística.


O objetivo é aprender a melhor árvore de decisão que maximiza a recompensa cumulativa esperada:


O aprendizado da árvore de decisão geralmente envolve duas etapas:
- Crescimento da árvore : começando com um único nó (raiz), divida recursivamente cada nó com base em um recurso e um limite que maximize a recompensa esperada. Esse processo continua até que alguma condição de parada seja atendida, como atingir uma profundidade máxima ou um número mínimo de amostras por folha.
- Poda de árvore : começando na árvore totalmente crescida, mescle recursivamente os filhos de cada nó se aumentar ou não diminuir significativamente a recompensa esperada. Este processo continua até que nenhuma outra fusão possa ser realizada.
O critério de divisão e o critério de fusão geralmente são definidos com base em testes estatísticos para garantir a significância estatística da melhoria.
from sklearn.tree import DecisionTreeRegressor class DecisionTreeBandit: def __init__(self, n_actions, n_features, max_depth=5): self.n_actions = n_actions self.n_features = n_features self.max_depth = max_depth # Initialize the decision tree model for each action self.models = [ DecisionTreeRegressor(max_depth=self.max_depth) for _ in range(n_actions) ] self.data = [[] for _ in range(n_actions)] def predict(self, context): return np.array( [self._predict_for_action(a, context) for a in range(self.n_actions)] ) def _predict_for_action(self, action, context): if not self.data[action]: return 0.0 X, y = zip(*self.data[action]) self.models[action].fit(np.array(X), np.array(y)) context_np = np.array(context).reshape( 1, -1 ) # convert list to NumPy array and reshape return self.models[action].predict(context_np)[0] def update(self, action, context, reward): self.data[action].append((context, reward)) Para DecisionTreeBandit, o método predict usa os parâmetros do modelo atual para prever a recompensa esperada para cada ação em um determinado contexto. O método update atualiza os parâmetros do modelo com base na recompensa observada da ação selecionada. Esta implementação usa scikit-learn para DecisionTreeBandit.
Bandidos contextuais com redes neurais
Modelos de aprendizado profundo podem ser usados para aproximar a função de recompensa em casos de alta dimensão ou não lineares. A política é tipicamente uma rede neural que usa o contexto e as ações disponíveis como entrada e gera como saída as probabilidades de realizar cada ação.
Uma abordagem popular de deep learning é usar uma arquitetura ator-crítica, onde uma rede (o ator) decide qual ação tomar e a outra rede (o crítico) avalia a ação tomada pelo ator.
Para cenários mais complexos onde a relação entre o contexto e a recompensa não é linear, podemos usar uma rede neural para modelar a função de recompensa. Um método popular é usar um método de gradiente de política, como REINFORCE ou crítico de ator.


Para resumir o seguinte Neural Bandit usa redes neurais para modelar a função de recompensa, levando em consideração a incerteza nos parâmetros da rede neural. Além disso, introduz a exploração por meio de gradientes de política, onde atualiza a política na direção de recompensas mais altas. Essa forma de exploração é mais direcionada, o que pode ser benéfico em grandes espaços de ação.
A implementação de código mais simples é a seguinte:
import torch import torch.nn as nn import torch.optim as optim class NeuralNetwork(nn.Module): def __init__(self, n_features): super(NeuralNetwork, self).__init__() self.layer = nn.Sequential( nn.Linear(n_features, 32), nn.ReLU(), nn.Linear(32, 1) ) def forward(self, x): return self.layer(x) class NeuralBandit: def __init__(self, n_actions, n_features, learning_rate=0.01): self.n_actions = n_actions self.n_features = n_features self.learning_rate = learning_rate # Initialize the neural network model for each action self.models = [NeuralNetwork(n_features) for _ in range(n_actions)] self.optimizers = [ optim.Adam(model.parameters(), lr=self.learning_rate) for model in self.models ] self.criterion = nn.MSELoss() def predict(self, context): context_tensor = torch.tensor(context, dtype=torch.float32) # Convert to tensor with torch.no_grad(): return torch.cat( [model(context_tensor).reshape(1) for model in self.models] ) def update(self, action, context, reward): self.optimizers[action].zero_grad() context_tensor = torch.tensor(context, dtype=torch.float32) # Convert to tensor reward_tensor = torch.tensor(reward, dtype=torch.float32) # Convert to tensor pred_reward = self.models[action](context_tensor) loss = self.criterion(pred_reward, reward_tensor) loss.backward() self.optimizers[action].step() Para NeuralBandit, a mesma imagem com método predict e método update que usa os parâmetros do modelo atual para prever a recompensa esperada para cada ação, dado um contexto e atualiza os parâmetros do modelo com base na recompensa observada da ação selecionada. Esta implementação usa PyTorch para NeuralBandit.
Desempenho comparativo de modelos
Cada modelo vem com suas vantagens e desvantagens únicas, e a escolha do modelo depende dos requisitos específicos do problema em questão. Vamos nos aprofundar nas especificidades de alguns desses modelos e depois comparar seus desempenhos.
LinUCB
O modelo Linear Upper Confidence Bound (LinUCB) usa regressão linear para estimar a recompensa esperada para cada ação dado um contexto. Ele também acompanha a incerteza dessas estimativas e as utiliza para incentivar a exploração.
Vantagens:
É simples e computacionalmente eficiente.
Ele fornece garantias teóricas para o seu arrependimento.
Desvantagens:
- Ele assume que a função de recompensa é uma função linear do contexto e da ação, o que pode não valer para problemas mais complexos.
bandido da árvore de decisão
O modelo Decision Tree Bandit representa a função de recompensa como uma árvore de decisão. Cada nó folha corresponde a uma ação, e cada caminho da raiz até um nó folha representa uma regra de decisão baseada no contexto.
Vantagens:
Ele fornece regras de decisão interpretáveis.
Ele pode lidar com funções de recompensa complexas.
Desvantagens:
- Pode sofrer de overfitting, especialmente para árvores grandes.
- Requer hiperparâmetros de ajuste, como a profundidade máxima da árvore.
bandido neural
O modelo Neural Bandit usa uma rede neural para estimar a recompensa esperada para cada ação dado um contexto. Ele usa métodos de gradiente de política para encorajar a exploração.
Vantagens:
Ele pode lidar com funções de recompensa complexas e não lineares.
Ele pode realizar exploração direcionada, o que é benéfico em grandes espaços de ação.
Desvantagens:
- Isso requer o ajuste de hiperparâmetros, como a arquitetura e a taxa de aprendizado da rede neural.
- Pode ser computacionalmente caro, especialmente para grandes redes e grandes espaços de ação.
Comparação de código e exemplo de execução geral:
Aqui está o código Python para comparar os desempenhos de todos esses bandidos do modelo mencionados e definidos anteriormente com a execução de uma simulação para cada modelo.
import matplotlib.pyplot as plt # Define the bandit environment n_actions = 10 n_features = 5 bandit = Bandit(n_actions, n_features) # Define the agents linucb_agent = LinUCB(n_actions, n_features, alpha=0.1) neural_agent = NeuralBandit(n_actions, n_features, learning_rate=0.01) tree_agent = DecisionTreeBandit(n_actions, n_features, max_depth=5) # Run the simulation for each agent n_steps = 1000 agents = [linucb_agent, tree_agent, neural_agent] cumulative_rewards = {agent.__class__.__name__: np.zeros(n_steps) for agent in agents} cumulative_regrets = {agent.__class__.__name__: np.zeros(n_steps) for agent in agents} for agent in agents: print(agent) for t in range(n_steps): x = np.random.randn(n_features) pred_rewards = agent.predict([x]) action = np.argmax(pred_rewards) reward = bandit.get_reward(action, x) optimal_reward = bandit.get_optimal_reward(x) agent.update(action, x, reward) cumulative_rewards[agent.__class__.__name__][t] = ( reward if t == 0 else cumulative_rewards[agent.__class__.__name__][t - 1] + reward ) cumulative_regrets[agent.__class__.__name__][t] = ( optimal_reward - reward if t == 0 else cumulative_regrets[agent.__class__.__name__][t - 1] + optimal_reward - reward ) # Plot the results plt.figure(figsize=(12, 6)) plt.subplot(121) for agent_name, rewards in cumulative_rewards.items(): plt.plot(rewards, label=agent_name) plt.xlabel("Steps") plt.ylabel("Cumulative Rewards") plt.legend() plt.subplot(122) for agent_name, regrets in cumulative_regrets.items(): plt.plot(regrets, label=agent_name) plt.xlabel("Steps") plt.ylabel("Cumulative Regrets") plt.legend() plt.show() 

Cenários de Aplicação
- Recomendação personalizada : neste cenário, o contexto pode ser informações do usuário (como idade, sexo, compras anteriores) e informações do item (como categoria do item, preço). As ações são os itens a serem recomendados e a recompensa é se o usuário clicou ou comprou o item. Um algoritmo bandido contextual pode ser usado para aprender uma política de recomendação personalizada que maximiza a taxa de cliques ou a receita.
- Ensaios clínicos : nos ensaios clínicos, o contexto pode ser a informação do paciente (como idade, sexo, histórico médico), as ações são os diferentes tratamentos e a recompensa é o resultado da saúde. Um algoritmo bandido contextual pode aprender uma política de tratamento que maximiza o resultado de saúde do paciente, equilibrando o efeito do tratamento e os efeitos colaterais.
- Publicidade on-line : na publicidade on-line, o contexto pode ser as informações do usuário e do anúncio, as ações são os anúncios a serem exibidos e a recompensa é se o usuário clicou no anúncio. Um algoritmo bandido contextual pode aprender uma política que maximiza a taxa de cliques ou receita, considerando a relevância do anúncio e as preferências do usuário.
Em cada uma dessas aplicações, é crucial equilibrar exploração e aproveitamento. Exploração é escolher a melhor ação com base no conhecimento atual, enquanto exploração é tentar diferentes ações para obter mais conhecimento. Algoritmos de bandidos contextuais fornecem uma estrutura para formalizar e resolver essa troca de exploração-exploração.
Conclusão
Os bandidos contextuais são uma ferramenta poderosa para a tomada de decisões em ambientes com feedback limitado. A capacidade de alavancar o contexto na tomada de decisões permite decisões mais complexas e diferenciadas do que os algoritmos bandit tradicionais.
Embora não tenhamos comparado o desempenho explicitamente, observamos que a escolha do algoritmo deve ser influenciada pelas características do problema. Para relacionamentos mais simples, o LinUCB e as Árvores de Decisão podem se destacar, enquanto as Redes Neurais podem superar em cenários complexos. Escolher a abordagem certa é a chave para a solução eficaz de problemas neste domínio emocionante.
No geral, os problemas de bandido baseados em contexto apresentam uma área envolvente no aprendizado por reforço, com diversos algoritmos disponíveis para resolvê-los e podemos esperar ver usos ainda mais inovadores desses modelos poderosos.








