

























Kẻ cướp theo ngữ cảnh là một loại thuật toán học tăng cường được sử dụng trong các mô hình ra quyết định trong đó người học phải chọn các hành động mang lại nhiều phần thưởng nhất. Chúng được đặt tên theo bài toán cờ bạc "một tay cướp" cổ điển, trong đó người chơi cần quyết định chơi máy đánh bạc nào, chơi bao nhiêu lần cho mỗi máy và chơi theo thứ tự nào.


Điều làm nên sự khác biệt của những kẻ cướp theo ngữ cảnh là quá trình ra quyết định được thông báo bởi ngữ cảnh. Bối cảnh, trong trường hợp này, đề cập đến một tập hợp các biến có thể quan sát được có thể tác động đến kết quả của hành động. Sự bổ sung này làm cho vấn đề kẻ cướp gần gũi hơn với các ứng dụng trong thế giới thực, chẳng hạn như đề xuất được cá nhân hóa, thử nghiệm lâm sàng hoặc vị trí đặt quảng cáo, trong đó quyết định phụ thuộc vào các trường hợp cụ thể.
Công thức của các vấn đề tên cướp theo ngữ cảnh
Vấn đề tên cướp theo ngữ cảnh có thể được thực hiện bằng các thuật toán khác nhau. Dưới đây, tôi cung cấp tổng quan cấp cao chung về cấu trúc thuật toán cho các vấn đề về tên cướp theo ngữ cảnh:

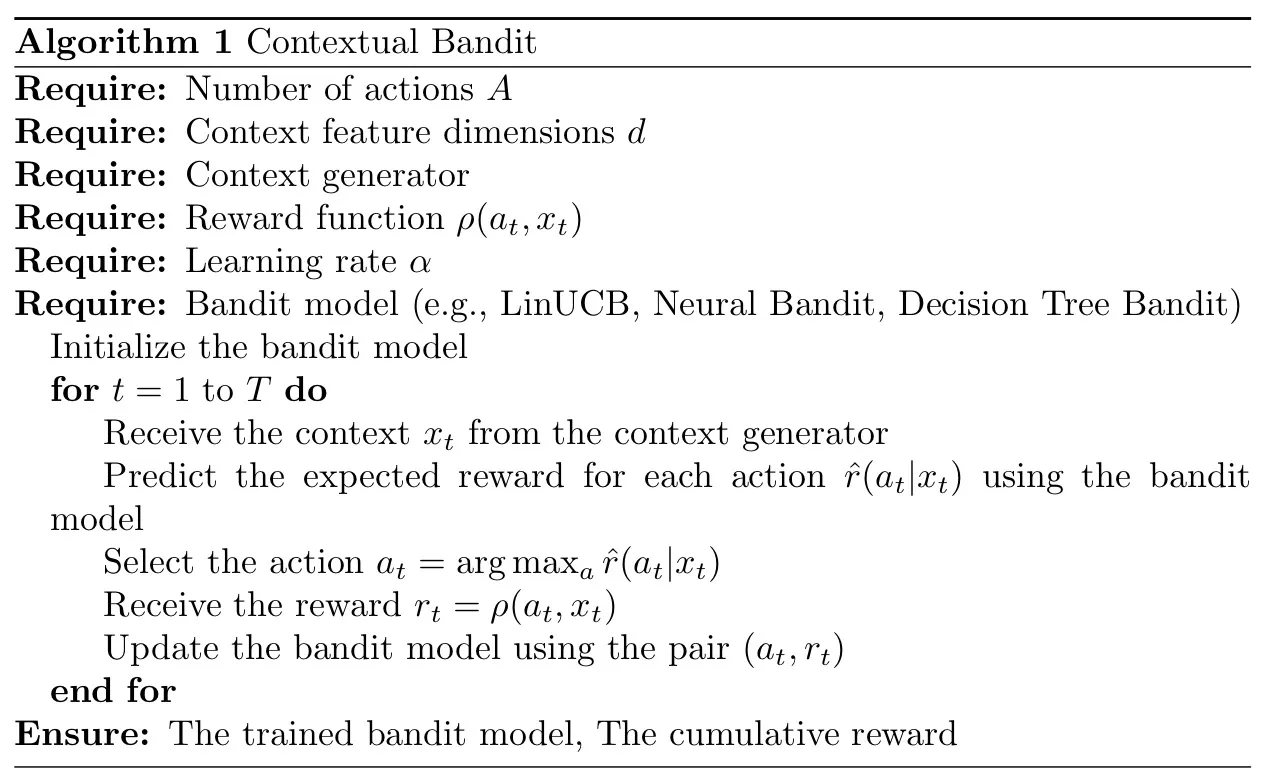
Và thuật toán sau đây là phép toán cơ bản của bài toán tên cướp theo ngữ cảnh:


Tóm lại tất cả những điều trên nói chung, mục tiêu của thuật toán là tối đa hóa phần thưởng tích lũy trong một khoảng thời gian nhất định. Lưu ý rằng trong mỗi vòng, phần thưởng chỉ dành cho hành động đã chọn mới được quan sát. Đây được gọi là phản hồi một phần, giúp phân biệt các vấn đề về tên cướp với việc học có giám sát.
Cách tiếp cận phổ biến nhất để giải quyết vấn đề kẻ cướp theo ngữ cảnh liên quan đến việc cân bằng thăm dò và khai thác. Khai thác có nghĩa là sử dụng kiến thức hiện tại để đưa ra quyết định tốt nhất, trong khi thăm dò liên quan đến việc thực hiện ít hành động nhất định hơn để thu thập thêm thông tin.
Sự đánh đổi giữa khám phá và khai thác được thể hiện trong các thuật toán khác nhau được thiết kế để giải quyết vấn đề Kẻ cướp theo ngữ cảnh, chẳng hạn như LinUCB, Kẻ cướp thần kinh hoặc Kẻ cướp cây quyết định. Tất cả các thuật toán này sử dụng các chiến lược độc đáo của chúng để giải quyết sự đánh đổi này.
Mã đại diện của ý tưởng này cho Bandit là:
class Bandit: def __init__(self, n_actions, n_features): self.n_actions = n_actions self.n_features = n_features self.theta = np.random.randn(n_actions, n_features) def get_reward(self, action, x): return x @ self.theta[action] + np.random.normal() def get_optimal_reward(self, x): return np.max(x @ self.theta.T) # Usage example # Define the bandit environment n_actions = 10 n_features = 5 bandit = Bandit(n_actions, n_features) # Define the model agent model_agent = model(n_features, *args) # Define the context (features) x = np.random.randn(n_features) # The agent makes a prediction pred_rewards = np.array([model_agent.predict(x) for _ in range(n_actions)]) # The agent chooses an action action = np.argmax(pred_rewards) # The agent gets a reward reward = bandit.get_reward(action, x) # The agent updates its parameters model_agent.update(x, reward)Thuật toán LinUCB
Thuật toán LinUCB là một thuật toán kẻ cướp theo ngữ cảnh mô hình hóa phần thưởng dự kiến của một hành động được đưa ra trong bối cảnh dưới dạng một hàm tuyến tính và thuật toán này chọn các hành động dựa trên nguyên tắc Giới hạn tin cậy trên (UCB) để cân bằng giữa khám phá và khai thác. Nó khai thác tùy chọn tốt nhất có sẵn theo mô hình hiện tại (là mô hình tuyến tính), nhưng nó cũng khám phá các tùy chọn có khả năng mang lại phần thưởng cao hơn, xem xét sự không chắc chắn trong các ước tính của mô hình. Về mặt toán học, nó có thể được trình bày dưới dạng:


Cách tiếp cận này đảm bảo rằng thuật toán khám phá các hành động mà nó có độ không chắc chắn cao.
Sau khi chọn hành động và nhận thưởng, LinUCB cập nhật thông số như sau:


Và đây là cách triển khai mã trong Python:
import numpy as np class LinUCB: def __init__(self, n_actions, n_features, alpha=1.0): self.n_actions = n_actions self.n_features = n_features self.alpha = alpha # Initialize parameters self.A = np.array( [np.identity(n_features) for _ in range(n_actions)] ) # action covariance matrix self.b = np.array( [np.zeros(n_features) for _ in range(n_actions)] ) # action reward vector self.theta = np.array( [np.zeros(n_features) for _ in range(n_actions)] ) # action parameter vector def predict(self, context): context = np.array(context) # Convert list to ndarray context = context.reshape( -1, 1 ) # reshape the context to a single-column matrix p = np.zeros(self.n_actions) for a in range(self.n_actions): theta = np.dot( np.linalg.inv(self.A[a]), self.b[a] ) # theta_a = A_a^-1 * b_a theta = theta.reshape(-1, 1) # Explicitly reshape theta p[a] = np.dot(theta.T, context) + self.alpha * np.sqrt( np.dot(context.T, np.dot(np.linalg.inv(self.A[a]), context)) ) # p_t(a|x_t) = theta_a^T * x_t + alpha * sqrt(x_t^T * A_a^-1 * x_t) return p def update(self, action, context, reward): self.A[action] += np.outer(context, context) # A_a = A_a + x_t * x_t^T self.b[action] += reward * context # b_a = b_a + r_t * x_txThuật toán cây quyết định
Cây quyết định Bandit mô hình chức năng phần thưởng dưới dạng cây quyết định, trong đó mỗi nút lá tương ứng với một hành động và mỗi đường dẫn từ nút gốc đến nút lá biểu thị quy tắc quyết định dựa trên ngữ cảnh. Nó thực hiện thăm dò và khai thác thông qua khung thống kê, thực hiện phân tách và hợp nhất trong cây quyết định dựa trên các bài kiểm tra ý nghĩa thống kê.


Mục tiêu là tìm hiểu cây quyết định tốt nhất giúp tối đa hóa phần thưởng tích lũy dự kiến:


Học cây quyết định thường bao gồm hai bước:
- Trồng cây : Bắt đầu với một nút duy nhất (gốc), phân tách đệ quy từng nút dựa trên một tính năng và ngưỡng tối đa hóa phần thưởng mong đợi. Quá trình này tiếp tục cho đến khi một số điều kiện dừng được đáp ứng, chẳng hạn như đạt đến độ sâu tối đa hoặc số lượng mẫu tối thiểu trên mỗi lá.
- Cắt tỉa cây : Bắt đầu từ cây đã phát triển đầy đủ, hợp nhất đệ quy các nút con của mỗi nút nếu nó tăng hoặc không giảm đáng kể phần thưởng dự kiến. Quá trình này tiếp tục cho đến khi không thể thực hiện việc hợp nhất nữa.
Tiêu chí tách và tiêu chí gộp thường được xác định dựa trên các kiểm định thống kê để đảm bảo ý nghĩa thống kê của cải tiến.
from sklearn.tree import DecisionTreeRegressor class DecisionTreeBandit: def __init__(self, n_actions, n_features, max_depth=5): self.n_actions = n_actions self.n_features = n_features self.max_depth = max_depth # Initialize the decision tree model for each action self.models = [ DecisionTreeRegressor(max_depth=self.max_depth) for _ in range(n_actions) ] self.data = [[] for _ in range(n_actions)] def predict(self, context): return np.array( [self._predict_for_action(a, context) for a in range(self.n_actions)] ) def _predict_for_action(self, action, context): if not self.data[action]: return 0.0 X, y = zip(*self.data[action]) self.models[action].fit(np.array(X), np.array(y)) context_np = np.array(context).reshape( 1, -1 ) # convert list to NumPy array and reshape return self.models[action].predict(context_np)[0] def update(self, action, context, reward): self.data[action].append((context, reward)) Đối với DecisionTreeBandit, phương thức predict sử dụng các tham số mô hình hiện tại để dự đoán phần thưởng dự kiến cho từng hành động trong một ngữ cảnh nhất định. Phương thức update cập nhật các tham số mô hình dựa trên phần thưởng quan sát được từ hành động đã chọn. Việc triển khai này sử dụng scikit-learn cho DecisionTreeBandit.
Kẻ cướp theo ngữ cảnh với mạng lưới thần kinh
Các mô hình học sâu có thể được sử dụng để ước tính hàm phần thưởng trong các trường hợp nhiều chiều hoặc phi tuyến tính. Chính sách này thường là một mạng thần kinh lấy bối cảnh và các hành động có sẵn làm đầu vào và xuất ra xác suất thực hiện từng hành động.
Một phương pháp học sâu phổ biến là sử dụng kiến trúc diễn viên-phê bình, trong đó một mạng (tác nhân) quyết định hành động sẽ thực hiện và mạng còn lại (nhà phê bình) đánh giá hành động được thực hiện bởi tác nhân.
Đối với các tình huống phức tạp hơn trong đó mối quan hệ giữa bối cảnh và phần thưởng không phải là tuyến tính, chúng ta có thể sử dụng mạng thần kinh để mô hình hóa chức năng phần thưởng. Một phương pháp phổ biến là sử dụng phương pháp gradient chính sách, chẳng hạn như REINFORCE hoặc diễn viên phê bình.


Tóm lại, Kẻ cướp thần kinh sau đây sử dụng mạng thần kinh để mô hình hóa hàm phần thưởng, có tính đến sự không chắc chắn trong các tham số của mạng thần kinh. Nó tiếp tục giới thiệu tính năng khám phá thông qua độ dốc chính sách, nơi nó cập nhật chính sách theo hướng phần thưởng cao hơn. Hình thức khám phá này được định hướng nhiều hơn, có thể có lợi trong không gian hành động rộng lớn.
Thực hiện mã đơn giản nhất là như sau:
import torch import torch.nn as nn import torch.optim as optim class NeuralNetwork(nn.Module): def __init__(self, n_features): super(NeuralNetwork, self).__init__() self.layer = nn.Sequential( nn.Linear(n_features, 32), nn.ReLU(), nn.Linear(32, 1) ) def forward(self, x): return self.layer(x) class NeuralBandit: def __init__(self, n_actions, n_features, learning_rate=0.01): self.n_actions = n_actions self.n_features = n_features self.learning_rate = learning_rate # Initialize the neural network model for each action self.models = [NeuralNetwork(n_features) for _ in range(n_actions)] self.optimizers = [ optim.Adam(model.parameters(), lr=self.learning_rate) for model in self.models ] self.criterion = nn.MSELoss() def predict(self, context): context_tensor = torch.tensor(context, dtype=torch.float32) # Convert to tensor with torch.no_grad(): return torch.cat( [model(context_tensor).reshape(1) for model in self.models] ) def update(self, action, context, reward): self.optimizers[action].zero_grad() context_tensor = torch.tensor(context, dtype=torch.float32) # Convert to tensor reward_tensor = torch.tensor(reward, dtype=torch.float32) # Convert to tensor pred_reward = self.models[action](context_tensor) loss = self.criterion(pred_reward, reward_tensor) loss.backward() self.optimizers[action].step() Đối với NeuralBandit, hình ảnh tương tự với phương pháp predict và phương pháp update sử dụng các tham số mô hình hiện tại để dự đoán phần thưởng dự kiến cho từng hành động trong một ngữ cảnh và cập nhật các tham số mô hình dựa trên phần thưởng quan sát được từ hành động đã chọn. Việc triển khai này sử dụng PyTorch cho NeuralBandit.
Hiệu suất so sánh của các mô hình
Mỗi mô hình đều có những ưu điểm và nhược điểm riêng và việc lựa chọn mô hình nào phụ thuộc vào các yêu cầu cụ thể của vấn đề hiện tại. Hãy đi sâu vào chi tiết cụ thể của một số kiểu máy này và sau đó so sánh hiệu suất của chúng.
LinUCB
Mô hình Giới hạn tin cậy trên tuyến tính (LinUCB) sử dụng hồi quy tuyến tính để ước tính phần thưởng dự kiến cho mỗi hành động trong một ngữ cảnh nhất định. Nó cũng theo dõi sự không chắc chắn của những ước tính này và sử dụng nó để khuyến khích khám phá.
Thuận lợi:
Nó đơn giản và hiệu quả về mặt tính toán.
Nó cung cấp những đảm bảo về mặt lý thuyết cho giới hạn hối tiếc của nó.
Nhược điểm:
- Nó giả định chức năng phần thưởng là một chức năng tuyến tính của bối cảnh và hành động, có thể không phù hợp với các vấn đề phức tạp hơn.
Quyết định cây cướp
Mô hình Kẻ cướp cây quyết định biểu thị chức năng phần thưởng dưới dạng cây quyết định. Mỗi nút lá tương ứng với một hành động và mỗi đường dẫn từ nút gốc đến nút lá biểu thị một quy tắc quyết định dựa trên ngữ cảnh.
Thuận lợi:
Nó cung cấp các quy tắc quyết định có thể diễn giải được.
Nó có thể xử lý các chức năng phần thưởng phức tạp.
Nhược điểm:
- Nó có thể bị thừa, đặc biệt là đối với những cây lớn.
- Nó yêu cầu điều chỉnh các siêu tham số chẳng hạn như độ sâu tối đa của cây.
Tên cướp thần kinh
Mô hình Kẻ cướp thần kinh sử dụng mạng thần kinh để ước tính phần thưởng dự kiến cho mỗi hành động trong một bối cảnh. Nó sử dụng các phương pháp độ dốc chính sách để khuyến khích khám phá.
Thuận lợi:
Nó có thể xử lý các hàm phần thưởng phức tạp, phi tuyến tính.
Nó có thể thực hiện khám phá theo định hướng, điều này có lợi trong không gian hành động rộng lớn.
Nhược điểm:
- Nó yêu cầu điều chỉnh các siêu tham số như kiến trúc và tốc độ học của mạng thần kinh.
- Nó có thể tốn kém về mặt tính toán, đặc biệt đối với các mạng lớn và không gian hành động lớn.
So sánh mã và ví dụ chạy chung:
Đây là mã Python để so sánh hiệu suất của tất cả những kẻ cướp mô hình này đã đề cập và xác định trước đó với việc chạy mô phỏng cho từng mô hình.
import matplotlib.pyplot as plt # Define the bandit environment n_actions = 10 n_features = 5 bandit = Bandit(n_actions, n_features) # Define the agents linucb_agent = LinUCB(n_actions, n_features, alpha=0.1) neural_agent = NeuralBandit(n_actions, n_features, learning_rate=0.01) tree_agent = DecisionTreeBandit(n_actions, n_features, max_depth=5) # Run the simulation for each agent n_steps = 1000 agents = [linucb_agent, tree_agent, neural_agent] cumulative_rewards = {agent.__class__.__name__: np.zeros(n_steps) for agent in agents} cumulative_regrets = {agent.__class__.__name__: np.zeros(n_steps) for agent in agents} for agent in agents: print(agent) for t in range(n_steps): x = np.random.randn(n_features) pred_rewards = agent.predict([x]) action = np.argmax(pred_rewards) reward = bandit.get_reward(action, x) optimal_reward = bandit.get_optimal_reward(x) agent.update(action, x, reward) cumulative_rewards[agent.__class__.__name__][t] = ( reward if t == 0 else cumulative_rewards[agent.__class__.__name__][t - 1] + reward ) cumulative_regrets[agent.__class__.__name__][t] = ( optimal_reward - reward if t == 0 else cumulative_regrets[agent.__class__.__name__][t - 1] + optimal_reward - reward ) # Plot the results plt.figure(figsize=(12, 6)) plt.subplot(121) for agent_name, rewards in cumulative_rewards.items(): plt.plot(rewards, label=agent_name) plt.xlabel("Steps") plt.ylabel("Cumulative Rewards") plt.legend() plt.subplot(122) for agent_name, regrets in cumulative_regrets.items(): plt.plot(regrets, label=agent_name) plt.xlabel("Steps") plt.ylabel("Cumulative Regrets") plt.legend() plt.show() 

Kịch bản ứng dụng
- Đề xuất được cá nhân hóa : Trong trường hợp này, ngữ cảnh có thể là thông tin người dùng (như tuổi, giới tính, các giao dịch mua trước đây) và thông tin mặt hàng (như danh mục mặt hàng, giá). Các hành động là các mặt hàng để đề xuất và phần thưởng là liệu người dùng có nhấp vào hoặc mua mặt hàng đó hay không. Thuật toán tên cướp theo ngữ cảnh có thể được sử dụng để tìm hiểu chính sách đề xuất được cá nhân hóa nhằm tối đa hóa tỷ lệ nhấp hoặc doanh thu.
- Thử nghiệm lâm sàng : Trong các thử nghiệm lâm sàng, bối cảnh có thể là thông tin bệnh nhân (như tuổi, giới tính, tiền sử bệnh), các hành động là các phương pháp điều trị khác nhau và phần thưởng là kết quả sức khỏe. Thuật toán thay thế theo ngữ cảnh có thể tìm hiểu chính sách điều trị nhằm tối đa hóa kết quả sức khỏe của bệnh nhân, cân bằng giữa hiệu quả điều trị và tác dụng phụ.
- Quảng cáo trực tuyến : Trong quảng cáo trực tuyến, ngữ cảnh có thể là thông tin người dùng và thông tin quảng cáo, hành động là quảng cáo hiển thị và phần thưởng là liệu người dùng có nhấp vào quảng cáo hay không. Thuật toán kẻ cướp theo ngữ cảnh có thể tìm hiểu chính sách tối đa hóa tỷ lệ nhấp hoặc doanh thu, xem xét mức độ liên quan của quảng cáo và sở thích của người dùng.
Trong mỗi ứng dụng này, điều quan trọng là phải cân bằng giữa thăm dò và khai thác. Khai thác là chọn hành động tốt nhất dựa trên kiến thức hiện tại, trong khi thăm dò là thử các hành động khác nhau để có thêm kiến thức. Các thuật toán tên cướp theo ngữ cảnh cung cấp một khuôn khổ để chính thức hóa và giải quyết sự đánh đổi giữa thăm dò và khai thác này.
Phần kết luận
Kẻ cướp theo ngữ cảnh là một công cụ mạnh mẽ để ra quyết định trong môi trường có phản hồi hạn chế. Khả năng tận dụng ngữ cảnh trong quá trình ra quyết định cho phép đưa ra các quyết định phức tạp và nhiều sắc thái hơn so với thuật toán kẻ cướp truyền thống.
Mặc dù chúng tôi không so sánh hiệu suất một cách rõ ràng, nhưng chúng tôi lưu ý rằng việc lựa chọn thuật toán sẽ bị ảnh hưởng bởi các đặc điểm của vấn đề. Đối với các mối quan hệ đơn giản hơn, LinUCB và Cây Quyết định có thể vượt trội, trong khi Mạng Nơ-ron có thể hoạt động tốt hơn trong các tình huống phức tạp. Mỗi phương pháp đều có những điểm mạnh riêng: LinUCB vì tính đơn giản về mặt toán học, Cây Quyết định vì tính dễ hiểu và Mạng Nơ-ron vì khả năng xử lý các mối quan hệ phức tạp. Chọn phương pháp phù hợp là chìa khóa để giải quyết vấn đề hiệu quả trong lĩnh vực thú vị này.
Nhìn chung, các vấn đề về kẻ cướp dựa trên ngữ cảnh thể hiện một lĩnh vực hấp dẫn trong quá trình học tăng cường, với các thuật toán đa dạng có sẵn để giải quyết chúng và chúng ta có thể mong đợi được thấy những cách sử dụng sáng tạo hơn nữa của các mô hình mạnh mẽ này.








