

























प्रासंगिक डाकू सुदृढीकरण सीखने के एल्गोरिदम का एक वर्ग है जिसका उपयोग निर्णय लेने वाले मॉडल में किया जाता है जहां एक शिक्षार्थी को ऐसे कार्यों का चयन करना होता है जिसके परिणामस्वरूप सबसे अधिक इनाम मिलता है। इनका नाम जुए की शास्त्रीय "एक-सशस्त्र डाकू" समस्या के नाम पर रखा गया है, जहां एक खिलाड़ी को यह तय करना होता है कि कौन सी स्लॉट मशीन खेलनी है, प्रत्येक मशीन को कितनी बार खेलना है, और उन्हें किस क्रम में खेलना है।


जो बात प्रासंगिक डाकुओं को अलग करती है वह यह है कि निर्णय लेने की प्रक्रिया को संदर्भ द्वारा सूचित किया जाता है। इस मामले में, संदर्भ अवलोकन योग्य चर के एक सेट को संदर्भित करता है जो कार्रवाई के परिणाम को प्रभावित कर सकता है। यह जोड़ दस्यु समस्या को वास्तविक दुनिया के अनुप्रयोगों के करीब बनाता है, जैसे वैयक्तिकृत सिफारिशें, नैदानिक परीक्षण, या विज्ञापन प्लेसमेंट, जहां निर्णय विशिष्ट परिस्थितियों पर निर्भर करता है।
प्रासंगिक दस्यु समस्याओं का निरूपण
प्रासंगिक दस्यु समस्या को विभिन्न एल्गोरिदम का उपयोग करके कार्यान्वित किया जा सकता है। नीचे, मैं प्रासंगिक दस्यु समस्याओं के लिए एल्गोरिथम संरचना का एक सामान्य उच्च-स्तरीय अवलोकन प्रदान करता हूं:

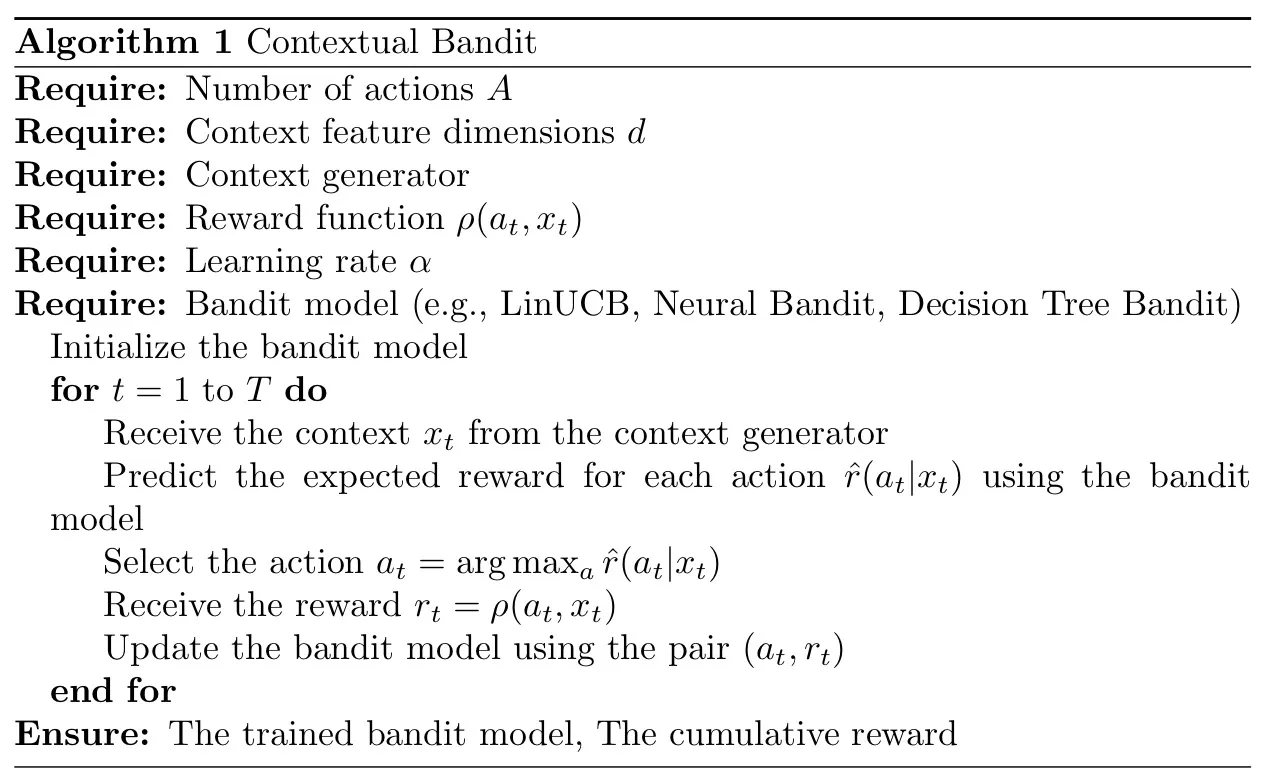
और यहां निम्नलिखित एल्गोरिदम प्रासंगिक दस्यु समस्या का अंतर्निहित गणित है:


उपरोक्त सभी को संक्षेप में कहें तो आम तौर पर एल्गोरिदम का लक्ष्य कुछ समय क्षितिज पर संचयी इनाम को अधिकतम करना है। ध्यान दें कि प्रत्येक दौर में, केवल चुनी गई कार्रवाई के लिए इनाम देखा जाता है। इसे आंशिक फीडबैक के रूप में जाना जाता है, जो दस्यु समस्याओं को पर्यवेक्षित शिक्षण से अलग करता है।
प्रासंगिक दस्यु समस्या को हल करने के लिए सबसे आम दृष्टिकोण में अन्वेषण और शोषण को संतुलित करना शामिल है। शोषण का अर्थ है सबसे अच्छा निर्णय लेने के लिए वर्तमान ज्ञान का उपयोग करना, जबकि अन्वेषण में अधिक जानकारी इकट्ठा करने के लिए कम निश्चित कार्रवाई करना शामिल है।
अन्वेषण और शोषण के बीच का व्यापार प्रासंगिक बैंडिट समस्या को हल करने के लिए डिज़ाइन किए गए विभिन्न एल्गोरिदम में प्रकट होता है, जैसे कि लिनयूसीबी, न्यूरल बैंडिट, या डिसीजन ट्री बैंडिट। ये सभी एल्गोरिदम इस व्यापार-बंद को संबोधित करने के लिए अपनी अनूठी रणनीतियों का उपयोग करते हैं।
बैंडिट के लिए इस विचार का कोड प्रतिनिधित्व है:
class Bandit: def __init__(self, n_actions, n_features): self.n_actions = n_actions self.n_features = n_features self.theta = np.random.randn(n_actions, n_features) def get_reward(self, action, x): return x @ self.theta[action] + np.random.normal() def get_optimal_reward(self, x): return np.max(x @ self.theta.T) # Usage example # Define the bandit environment n_actions = 10 n_features = 5 bandit = Bandit(n_actions, n_features) # Define the model agent model_agent = model(n_features, *args) # Define the context (features) x = np.random.randn(n_features) # The agent makes a prediction pred_rewards = np.array([model_agent.predict(x) for _ in range(n_actions)]) # The agent chooses an action action = np.argmax(pred_rewards) # The agent gets a reward reward = bandit.get_reward(action, x) # The agent updates its parameters model_agent.update(x, reward)लिनयूसीबी एल्गोरिथम
लिनयूसीबी एल्गोरिदम एक प्रासंगिक बैंडिट एल्गोरिदम है जो एक संदर्भ को एक रैखिक फ़ंक्शन के रूप में दिए गए कार्रवाई के अपेक्षित इनाम को मॉडल करता है, और यह अन्वेषण और शोषण को संतुलित करने के लिए ऊपरी कॉन्फिडेंस बाउंड (यूसीबी) सिद्धांत के आधार पर कार्यों का चयन करता है। यह वर्तमान मॉडल (जो एक रैखिक मॉडल है) के अनुसार उपलब्ध सर्वोत्तम विकल्प का उपयोग करता है, लेकिन यह उन विकल्पों की भी खोज करता है जो मॉडल के अनुमानों में अनिश्चितता को देखते हुए संभावित रूप से उच्च पुरस्कार प्रदान कर सकते हैं। गणितीय रूप से इसे इस प्रकार प्रस्तुत किया जा सकता है:


यह दृष्टिकोण सुनिश्चित करता है कि एल्गोरिदम उन कार्यों का पता लगाता है जिनके लिए इसमें उच्च अनिश्चितता है।
किसी कार्रवाई का चयन करने और पुरस्कार प्राप्त करने के बाद, LinUCB मापदंडों को निम्नानुसार अपडेट करता है:


और यहाँ पायथन में कोड कार्यान्वयन है:
import numpy as np class LinUCB: def __init__(self, n_actions, n_features, alpha=1.0): self.n_actions = n_actions self.n_features = n_features self.alpha = alpha # Initialize parameters self.A = np.array( [np.identity(n_features) for _ in range(n_actions)] ) # action covariance matrix self.b = np.array( [np.zeros(n_features) for _ in range(n_actions)] ) # action reward vector self.theta = np.array( [np.zeros(n_features) for _ in range(n_actions)] ) # action parameter vector def predict(self, context): context = np.array(context) # Convert list to ndarray context = context.reshape( -1, 1 ) # reshape the context to a single-column matrix p = np.zeros(self.n_actions) for a in range(self.n_actions): theta = np.dot( np.linalg.inv(self.A[a]), self.b[a] ) # theta_a = A_a^-1 * b_a theta = theta.reshape(-1, 1) # Explicitly reshape theta p[a] = np.dot(theta.T, context) + self.alpha * np.sqrt( np.dot(context.T, np.dot(np.linalg.inv(self.A[a]), context)) ) # p_t(a|x_t) = theta_a^T * x_t + alpha * sqrt(x_t^T * A_a^-1 * x_t) return p def update(self, action, context, reward): self.A[action] += np.outer(context, context) # A_a = A_a + x_t * x_t^T self.b[action] += reward * context # b_a = b_a + r_t * x_txनिर्णय वृक्ष एल्गोरिथम
डिसीजन ट्री बैंडिट रिवॉर्ड फ़ंक्शन को एक डिसीजन ट्री के रूप में मॉडल करता है, जहां प्रत्येक लीफ नोड एक क्रिया से मेल खाता है और रूट से लीफ नोड तक प्रत्येक पथ संदर्भ के आधार पर एक निर्णय नियम का प्रतिनिधित्व करता है। यह सांख्यिकीय ढांचे के माध्यम से अन्वेषण और शोषण करता है, सांख्यिकीय महत्व परीक्षणों के आधार पर निर्णय वृक्ष में विभाजन और विलय करता है।


इसका उद्देश्य सर्वोत्तम निर्णय वृक्ष सीखना है जो अपेक्षित संचयी पुरस्कार को अधिकतम करता है:


निर्णय वृक्ष सीखने में आमतौर पर दो चरण शामिल होते हैं:
- पेड़ उगाना : एक नोड (रूट) से शुरू करके, प्रत्येक नोड को एक सुविधा और सीमा के आधार पर पुनरावर्ती रूप से विभाजित करें जो अपेक्षित इनाम को अधिकतम करता है। यह प्रक्रिया तब तक जारी रहती है जब तक कुछ रुकने की स्थिति पूरी नहीं हो जाती, जैसे कि अधिकतम गहराई या प्रति पत्ती नमूनों की न्यूनतम संख्या तक पहुंचना।
- पेड़ की छंटाई : पूर्ण विकसित पेड़ से शुरू करके, प्रत्येक नोड के बच्चों को पुनरावर्ती रूप से मर्ज करें यदि यह अपेक्षित इनाम में उल्लेखनीय रूप से वृद्धि या कमी नहीं करता है। यह प्रक्रिया तब तक जारी रहती है जब तक आगे कोई विलय नहीं किया जा सके।
सुधार के सांख्यिकीय महत्व को सुनिश्चित करने के लिए विभाजन मानदंड और विलय मानदंड को आमतौर पर सांख्यिकीय परीक्षणों के आधार पर परिभाषित किया जाता है।
from sklearn.tree import DecisionTreeRegressor class DecisionTreeBandit: def __init__(self, n_actions, n_features, max_depth=5): self.n_actions = n_actions self.n_features = n_features self.max_depth = max_depth # Initialize the decision tree model for each action self.models = [ DecisionTreeRegressor(max_depth=self.max_depth) for _ in range(n_actions) ] self.data = [[] for _ in range(n_actions)] def predict(self, context): return np.array( [self._predict_for_action(a, context) for a in range(self.n_actions)] ) def _predict_for_action(self, action, context): if not self.data[action]: return 0.0 X, y = zip(*self.data[action]) self.models[action].fit(np.array(X), np.array(y)) context_np = np.array(context).reshape( 1, -1 ) # convert list to NumPy array and reshape return self.models[action].predict(context_np)[0] def update(self, action, context, reward): self.data[action].append((context, reward)) DecisionTreeBandit के लिए, predict विधि किसी संदर्भ में दी गई प्रत्येक कार्रवाई के लिए अपेक्षित इनाम की भविष्यवाणी करने के लिए वर्तमान मॉडल मापदंडों का उपयोग करती है। update विधि चयनित कार्रवाई से प्राप्त इनाम के आधार पर मॉडल मापदंडों को अद्यतन करती है। यह कार्यान्वयन DecisionTreeBandit के लिए scikit-learn उपयोग करता है।
तंत्रिका नेटवर्क के साथ प्रासंगिक डाकू
गहन शिक्षण मॉडल का उपयोग उच्च-आयामी या गैर-रेखीय मामलों में इनाम फ़ंक्शन का अनुमान लगाने के लिए किया जा सकता है। नीति आम तौर पर एक तंत्रिका नेटवर्क है जो संदर्भ और उपलब्ध क्रियाओं को इनपुट के रूप में लेती है और प्रत्येक क्रिया करने की संभावनाओं को आउटपुट करती है।
एक लोकप्रिय गहन शिक्षण दृष्टिकोण एक अभिनेता-आलोचक वास्तुकला का उपयोग करना है, जहां एक नेटवर्क (अभिनेता) तय करता है कि कौन सी कार्रवाई करनी है, और दूसरा नेटवर्क (आलोचक) अभिनेता द्वारा की गई कार्रवाई का मूल्यांकन करता है।
अधिक जटिल परिदृश्यों के लिए जहां संदर्भ और इनाम के बीच संबंध रैखिक नहीं है, हम इनाम फ़ंक्शन को मॉडल करने के लिए एक तंत्रिका नेटवर्क का उपयोग कर सकते हैं। एक लोकप्रिय तरीका पॉलिसी ग्रेडिएंट पद्धति का उपयोग करना है, जैसे REINFORCE या अभिनेता-आलोचक।


निम्नलिखित को संक्षेप में कहें तो न्यूरल बैंडिट तंत्रिका नेटवर्क के मापदंडों में अनिश्चितता को ध्यान में रखते हुए, इनाम फ़ंक्शन को मॉडल करने के लिए तंत्रिका नेटवर्क का उपयोग करता है। यह आगे नीति ग्रेडिएंट्स के माध्यम से अन्वेषण की शुरुआत करता है जहां यह उच्च पुरस्कारों की दिशा में नीति को अद्यतन करता है। अन्वेषण का यह रूप अधिक निर्देशित है, जो बड़े कार्य स्थानों में फायदेमंद हो सकता है।
सबसे सरल कोड कार्यान्वयन निम्नलिखित है:
import torch import torch.nn as nn import torch.optim as optim class NeuralNetwork(nn.Module): def __init__(self, n_features): super(NeuralNetwork, self).__init__() self.layer = nn.Sequential( nn.Linear(n_features, 32), nn.ReLU(), nn.Linear(32, 1) ) def forward(self, x): return self.layer(x) class NeuralBandit: def __init__(self, n_actions, n_features, learning_rate=0.01): self.n_actions = n_actions self.n_features = n_features self.learning_rate = learning_rate # Initialize the neural network model for each action self.models = [NeuralNetwork(n_features) for _ in range(n_actions)] self.optimizers = [ optim.Adam(model.parameters(), lr=self.learning_rate) for model in self.models ] self.criterion = nn.MSELoss() def predict(self, context): context_tensor = torch.tensor(context, dtype=torch.float32) # Convert to tensor with torch.no_grad(): return torch.cat( [model(context_tensor).reshape(1) for model in self.models] ) def update(self, action, context, reward): self.optimizers[action].zero_grad() context_tensor = torch.tensor(context, dtype=torch.float32) # Convert to tensor reward_tensor = torch.tensor(reward, dtype=torch.float32) # Convert to tensor pred_reward = self.models[action](context_tensor) loss = self.criterion(pred_reward, reward_tensor) loss.backward() self.optimizers[action].step() न्यूरलबैंडिट के लिए predict विधि और update विधि के साथ एक ही तस्वीर जो प्रत्येक कार्रवाई के लिए अपेक्षित इनाम की भविष्यवाणी करने के लिए मौजूदा मॉडल पैरामीटर का उपयोग करती है और चयनित कार्रवाई से देखे गए इनाम के आधार पर मॉडल पैरामीटर को अपडेट करती है। यह कार्यान्वयन न्यूरलबैंडिट के लिए PyTorch का उपयोग करता है।
मॉडलों का तुलनात्मक प्रदर्शन
प्रत्येक मॉडल अपने अनूठे फायदे और नुकसान के साथ आता है, और मॉडल का चुनाव मौजूदा समस्या की विशिष्ट आवश्यकताओं पर निर्भर करता है। आइए इनमें से कुछ मॉडलों की बारीकियों पर गौर करें और फिर उनके प्रदर्शन की तुलना करें।
लिनयूसीबी
लीनियर अपर कॉन्फिडेंस बाउंड (लिनयूसीबी) मॉडल किसी संदर्भ में दी गई प्रत्येक कार्रवाई के लिए अपेक्षित इनाम का अनुमान लगाने के लिए रैखिक प्रतिगमन का उपयोग करता है। यह इन अनुमानों की अनिश्चितता पर भी नज़र रखता है और इसका उपयोग अन्वेषण को प्रोत्साहित करने के लिए करता है।
लाभ:
यह सरल और कम्प्यूटेशनल रूप से कुशल है।
यह अपने पछतावे के लिए सैद्धांतिक गारंटी प्रदान करता है।
नुकसान:
- यह मानता है कि इनाम फ़ंक्शन संदर्भ और कार्रवाई का एक रैखिक कार्य है, जो अधिक जटिल समस्याओं के लिए उपयुक्त नहीं हो सकता है।
डिसीज़न ट्री बैंडिट
डिसीजन ट्री बैंडिट मॉडल एक डिसीजन ट्री के रूप में इनाम फ़ंक्शन का प्रतिनिधित्व करता है। प्रत्येक लीफ नोड एक क्रिया से मेल खाता है, और रूट से लीफ नोड तक प्रत्येक पथ संदर्भ के आधार पर एक निर्णय नियम का प्रतिनिधित्व करता है।
लाभ:
यह व्याख्या योग्य निर्णय नियम प्रदान करता है।
यह जटिल इनाम कार्यों को संभाल सकता है।
नुकसान:
- यह ओवरफिटिंग से पीड़ित हो सकता है, खासकर बड़े पेड़ों के लिए।
- इसके लिए पेड़ की अधिकतम गहराई जैसे हाइपरपैरामीटर को ट्यून करने की आवश्यकता होती है।
तंत्रिका दस्यु
न्यूरल बैंडिट मॉडल एक संदर्भ दिए गए प्रत्येक क्रिया के लिए अपेक्षित इनाम का अनुमान लगाने के लिए एक तंत्रिका नेटवर्क का उपयोग करता है। यह अन्वेषण को प्रोत्साहित करने के लिए नीति ढाल तरीकों का उपयोग करता है।
लाभ:
यह जटिल, गैर-रेखीय इनाम कार्यों को संभाल सकता है।
यह निर्देशित अन्वेषण कर सकता है, जो बड़े एक्शन स्थानों में फायदेमंद है।
नुकसान:
- इसके लिए तंत्रिका नेटवर्क की वास्तुकला और सीखने की दर जैसे हाइपरपैरामीटर को ट्यून करने की आवश्यकता होती है।
- यह कम्प्यूटेशनल रूप से महंगा हो सकता है, खासकर बड़े नेटवर्क और बड़े एक्शन स्पेस के लिए।
कोड तुलना और सामान्य चलन उदाहरण:
प्रत्येक मॉडल के लिए सिमुलेशन चलाने के साथ पहले उल्लिखित और परिभाषित इन सभी मॉडल के डाकुओं के प्रदर्शन की तुलना करने के लिए यहां पायथन कोड है।
import matplotlib.pyplot as plt # Define the bandit environment n_actions = 10 n_features = 5 bandit = Bandit(n_actions, n_features) # Define the agents linucb_agent = LinUCB(n_actions, n_features, alpha=0.1) neural_agent = NeuralBandit(n_actions, n_features, learning_rate=0.01) tree_agent = DecisionTreeBandit(n_actions, n_features, max_depth=5) # Run the simulation for each agent n_steps = 1000 agents = [linucb_agent, tree_agent, neural_agent] cumulative_rewards = {agent.__class__.__name__: np.zeros(n_steps) for agent in agents} cumulative_regrets = {agent.__class__.__name__: np.zeros(n_steps) for agent in agents} for agent in agents: print(agent) for t in range(n_steps): x = np.random.randn(n_features) pred_rewards = agent.predict([x]) action = np.argmax(pred_rewards) reward = bandit.get_reward(action, x) optimal_reward = bandit.get_optimal_reward(x) agent.update(action, x, reward) cumulative_rewards[agent.__class__.__name__][t] = ( reward if t == 0 else cumulative_rewards[agent.__class__.__name__][t - 1] + reward ) cumulative_regrets[agent.__class__.__name__][t] = ( optimal_reward - reward if t == 0 else cumulative_regrets[agent.__class__.__name__][t - 1] + optimal_reward - reward ) # Plot the results plt.figure(figsize=(12, 6)) plt.subplot(121) for agent_name, rewards in cumulative_rewards.items(): plt.plot(rewards, label=agent_name) plt.xlabel("Steps") plt.ylabel("Cumulative Rewards") plt.legend() plt.subplot(122) for agent_name, regrets in cumulative_regrets.items(): plt.plot(regrets, label=agent_name) plt.xlabel("Steps") plt.ylabel("Cumulative Regrets") plt.legend() plt.show() 

अनुप्रयोग परिदृश्य
- वैयक्तिकृत अनुशंसा : इस परिदृश्य में, संदर्भ उपयोगकर्ता की जानकारी (जैसे उम्र, लिंग, पिछली खरीदारी) और आइटम की जानकारी (जैसे आइटम श्रेणी, कीमत) हो सकता है। क्रियाएँ अनुशंसित करने योग्य आइटम हैं, और इनाम यह है कि उपयोगकर्ता ने आइटम पर क्लिक किया या खरीदा। एक व्यक्तिगत अनुशंसा नीति सीखने के लिए एक प्रासंगिक बैंडिट एल्गोरिदम का उपयोग किया जा सकता है जो क्लिक-थ्रू दर या राजस्व को अधिकतम करता है।
- नैदानिक परीक्षण : नैदानिक परीक्षणों में, संदर्भ रोगी की जानकारी (जैसे उम्र, लिंग, चिकित्सा इतिहास) हो सकता है, क्रियाएं अलग-अलग उपचार हैं, और इनाम स्वास्थ्य परिणाम है। एक प्रासंगिक दस्यु एल्गोरिथ्म एक उपचार नीति सीख सकता है जो उपचार प्रभाव और दुष्प्रभावों को संतुलित करते हुए रोगी के स्वास्थ्य परिणाम को अधिकतम करता है।
- ऑनलाइन विज्ञापन : ऑनलाइन विज्ञापन में, संदर्भ उपयोगकर्ता की जानकारी और विज्ञापन की जानकारी हो सकता है, क्रियाएँ प्रदर्शित होने वाले विज्ञापन हैं, और इनाम यह है कि उपयोगकर्ता ने विज्ञापन पर क्लिक किया है या नहीं। एक प्रासंगिक बैंडिट एल्गोरिदम एक ऐसी नीति सीख सकता है जो विज्ञापन प्रासंगिकता और उपयोगकर्ता प्राथमिकताओं को ध्यान में रखते हुए क्लिक-थ्रू दर या राजस्व को अधिकतम करती है।
इनमें से प्रत्येक अनुप्रयोग में, अन्वेषण और दोहन को संतुलित करना महत्वपूर्ण है। शोषण का अर्थ वर्तमान ज्ञान के आधार पर सर्वोत्तम क्रिया को चुनना है, जबकि अन्वेषण का अर्थ अधिक ज्ञान प्राप्त करने के लिए विभिन्न क्रियाओं को आज़माना है। प्रासंगिक दस्यु एल्गोरिदम इस अन्वेषण-शोषण व्यापार-बंद को औपचारिक रूप देने और हल करने के लिए एक रूपरेखा प्रदान करते हैं।
निष्कर्ष
प्रासंगिक डाकू सीमित प्रतिक्रिया वाले वातावरण में निर्णय लेने के लिए एक शक्तिशाली उपकरण हैं। निर्णय लेने में संदर्भ का लाभ उठाने की क्षमता पारंपरिक दस्यु एल्गोरिदम की तुलना में अधिक जटिल और सूक्ष्म निर्णय लेने की अनुमति देती है।
हालाँकि हमने प्रदर्शन की स्पष्ट रूप से तुलना नहीं की, लेकिन हमने नोट किया कि एल्गोरिदम का चुनाव समस्या विशेषताओं से प्रभावित होना चाहिए। सरल रिश्तों के लिए, लिनयूसीबी और डिसीजन ट्री उत्कृष्टता प्राप्त कर सकते हैं, जबकि न्यूरल नेटवर्क जटिल परिदृश्यों में बेहतर प्रदर्शन कर सकते हैं। प्रत्येक विधि अद्वितीय ताकत प्रदान करती है: लिनयूसीबी अपनी गणितीय सादगी के लिए, डिसीजन ट्री अपनी व्याख्या के लिए, और न्यूरल नेटवर्क जटिल रिश्तों को संभालने की अपनी क्षमता के लिए। इस रोमांचक क्षेत्र में प्रभावी समस्या-समाधान के लिए सही दृष्टिकोण चुनना महत्वपूर्ण है।
कुल मिलाकर, संदर्भ-आधारित दस्यु समस्याएं सुदृढीकरण सीखने के भीतर एक आकर्षक क्षेत्र प्रस्तुत करती हैं, उनसे निपटने के लिए विविध एल्गोरिदम उपलब्ध हैं और हम इन शक्तिशाली मॉडलों के और भी अधिक नवीन उपयोग देखने की उम्मीद कर सकते हैं।








