


























상황별 도적은 학습자가 가장 많은 보상을 받는 행동을 선택해야 하는 의사 결정 모델에 사용되는 강화 학습 알고리즘 클래스입니다. 그들은 도박의 고전적인 "외팔이 산적" 문제의 이름을 따서 명명되었습니다. 여기서 플레이어는 어떤 슬롯머신을 플레이할지, 각 기계를 몇 번 플레이할지, 어떤 순서로 플레이할지 결정해야 합니다.


상황별 밴디트를 차별화하는 점은 의사결정 과정이 상황에 따라 결정된다는 점입니다. 이 경우 컨텍스트는 작업 결과에 영향을 미칠 수 있는 관찰 가능한 변수 집합을 나타냅니다. 이러한 추가로 인해 적기 문제는 특정 상황에 따라 결정이 달라지는 개인화된 권장 사항, 임상 시험 또는 광고 게재와 같은 실제 응용 프로그램에 더 가까워졌습니다.
상황적 도적 문제의 공식화
상황적 밴딧 문제는 다양한 알고리즘을 사용하여 구현될 수 있습니다. 아래에서는 상황별 밴딧 문제에 대한 알고리즘 구조에 대한 일반적인 상위 수준 개요를 제공합니다.

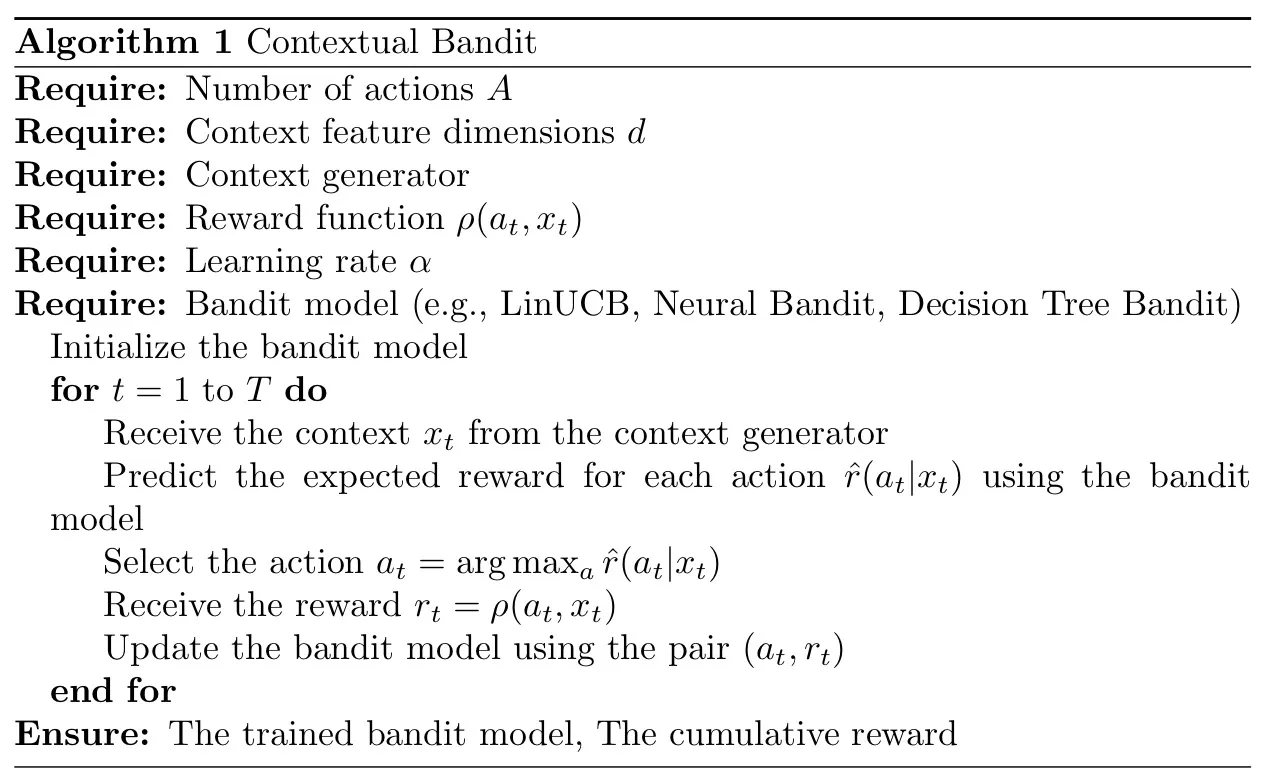
다음 알고리즘은 상황별 도적 문제의 기본 수학입니다.


위의 모든 내용을 일반적으로 요약하면 알고리즘의 목표는 일정 기간 동안 누적 보상을 최대화하는 것입니다. 각 라운드에서는 선택한 행동에 대한 보상만 관찰됩니다. 이를 부분 피드백이라고 하며, 적기 문제를 지도 학습과 구별합니다.
상황별 밴딧 문제를 해결하기 위한 가장 일반적인 접근 방식은 탐색과 활용의 균형을 맞추는 것입니다. 활용은 최선의 결정을 내리기 위해 현재 지식을 사용하는 것을 의미하는 반면, 탐색에는 더 많은 정보를 수집하기 위해 덜 확실한 조치를 취하는 것이 포함됩니다.
탐색과 활용 사이의 균형은 LinUCB, Neural Bandit 또는 Decision Tree Bandit과 같은 Contextual Bandit 문제를 해결하기 위해 설계된 다양한 알고리즘에서 나타납니다. 이러한 알고리즘은 모두 이러한 균형을 해결하기 위해 고유한 전략을 사용합니다.
Bandit에 대한 이 아이디어의 코드 표현은 다음과 같습니다.
class Bandit: def __init__(self, n_actions, n_features): self.n_actions = n_actions self.n_features = n_features self.theta = np.random.randn(n_actions, n_features) def get_reward(self, action, x): return x @ self.theta[action] + np.random.normal() def get_optimal_reward(self, x): return np.max(x @ self.theta.T) # Usage example # Define the bandit environment n_actions = 10 n_features = 5 bandit = Bandit(n_actions, n_features) # Define the model agent model_agent = model(n_features, *args) # Define the context (features) x = np.random.randn(n_features) # The agent makes a prediction pred_rewards = np.array([model_agent.predict(x) for _ in range(n_actions)]) # The agent chooses an action action = np.argmax(pred_rewards) # The agent gets a reward reward = bandit.get_reward(action, x) # The agent updates its parameters model_agent.update(x, reward)LinUCB 알고리즘
LinUCB 알고리즘은 상황에 따라 예상되는 행동 보상을 선형 함수로 모델링하는 상황별 밴딧(Contextual Bandit) 알고리즘으로, 탐색과 활용의 균형을 맞추기 위해 UCB(상한 신뢰 한계) 원리에 따라 행동을 선택합니다. 현재 모델(선형 모델)에 따라 사용할 수 있는 최상의 옵션을 활용하지만 모델 추정의 불확실성을 고려하여 잠재적으로 더 높은 보상을 제공할 수 있는 옵션도 탐색합니다. 수학적으로는 다음과 같이 표현될 수 있습니다.


이 접근 방식을 사용하면 알고리즘이 불확실성이 높은 작업을 탐색할 수 있습니다.
작업을 선택하고 보상을 받은 후 LinUCB는 다음과 같이 매개변수를 업데이트합니다.


Python의 코드 구현은 다음과 같습니다.
import numpy as np class LinUCB: def __init__(self, n_actions, n_features, alpha=1.0): self.n_actions = n_actions self.n_features = n_features self.alpha = alpha # Initialize parameters self.A = np.array( [np.identity(n_features) for _ in range(n_actions)] ) # action covariance matrix self.b = np.array( [np.zeros(n_features) for _ in range(n_actions)] ) # action reward vector self.theta = np.array( [np.zeros(n_features) for _ in range(n_actions)] ) # action parameter vector def predict(self, context): context = np.array(context) # Convert list to ndarray context = context.reshape( -1, 1 ) # reshape the context to a single-column matrix p = np.zeros(self.n_actions) for a in range(self.n_actions): theta = np.dot( np.linalg.inv(self.A[a]), self.b[a] ) # theta_a = A_a^-1 * b_a theta = theta.reshape(-1, 1) # Explicitly reshape theta p[a] = np.dot(theta.T, context) + self.alpha * np.sqrt( np.dot(context.T, np.dot(np.linalg.inv(self.A[a]), context)) ) # p_t(a|x_t) = theta_a^T * x_t + alpha * sqrt(x_t^T * A_a^-1 * x_t) return p def update(self, action, context, reward): self.A[action] += np.outer(context, context) # A_a = A_a + x_t * x_t^T self.b[action] += reward * context # b_a = b_a + r_t * x_tx의사결정 트리 알고리즘
Decision Tree Bandit은 보상 함수를 결정 트리로 모델링합니다. 여기서 각 리프 노드는 작업에 해당하고 루트에서 리프 노드까지의 각 경로는 컨텍스트를 기반으로 한 결정 규칙을 나타냅니다. 통계 프레임워크를 통해 탐색 및 활용을 수행하고 통계적 유의성 테스트를 기반으로 의사결정 트리에서 분할 및 병합을 수행합니다.


목표는 예상되는 누적 보상을 최대화하는 최상의 의사결정 트리를 학습하는 것입니다.


의사결정 트리 학습에는 일반적으로 두 단계가 포함됩니다.
- 트리 성장 : 단일 노드(루트)부터 시작하여 예상 보상을 최대화하는 기능 및 임계값을 기반으로 각 노드를 재귀적으로 분할합니다. 이 프로세스는 최대 깊이 또는 리프당 최소 샘플 수에 도달하는 등 일부 중지 조건이 충족될 때까지 계속됩니다.
- 트리 가지치기(Tree Pruning) : 완전히 성장한 트리부터 시작하여 예상 보상이 크게 증가하거나 감소하지 않는 경우 각 노드의 하위 노드를 재귀적으로 병합합니다. 이 프로세스는 더 이상 병합을 수행할 수 없을 때까지 계속됩니다.
분할 기준과 병합 기준은 일반적으로 개선의 통계적 유의성을 확인하기 위해 통계적 테스트를 기반으로 정의됩니다.
from sklearn.tree import DecisionTreeRegressor class DecisionTreeBandit: def __init__(self, n_actions, n_features, max_depth=5): self.n_actions = n_actions self.n_features = n_features self.max_depth = max_depth # Initialize the decision tree model for each action self.models = [ DecisionTreeRegressor(max_depth=self.max_depth) for _ in range(n_actions) ] self.data = [[] for _ in range(n_actions)] def predict(self, context): return np.array( [self._predict_for_action(a, context) for a in range(self.n_actions)] ) def _predict_for_action(self, action, context): if not self.data[action]: return 0.0 X, y = zip(*self.data[action]) self.models[action].fit(np.array(X), np.array(y)) context_np = np.array(context).reshape( 1, -1 ) # convert list to NumPy array and reshape return self.models[action].predict(context_np)[0] def update(self, action, context, reward): self.data[action].append((context, reward)) DecisionTreeBandit의 경우 predict 방법은 현재 모델 매개변수를 사용하여 주어진 상황에서 각 행동에 대해 예상되는 보상을 예측합니다. update 방법은 선택한 작업에서 관찰된 보상을 기반으로 모델 매개변수를 업데이트합니다. 이 구현에서는 DecisionTreeBandit에 scikit-learn 사용합니다.
신경망을 이용한 상황별 도적
딥 러닝 모델은 고차원 또는 비선형 사례에서 보상 함수를 근사화하는 데 사용할 수 있습니다. 정책은 일반적으로 컨텍스트와 사용 가능한 작업을 입력으로 사용하고 각 작업을 수행할 확률을 출력하는 신경망입니다.
인기 있는 딥 러닝 접근 방식은 행위자-비평 아키텍처를 사용하는 것입니다. 여기서 한 네트워크(행위자)는 어떤 조치를 취할지 결정하고 다른 네트워크(비평가)는 행위자가 취한 조치를 평가합니다.
컨텍스트와 보상 간의 관계가 선형이 아닌 보다 복잡한 시나리오의 경우 신경망을 사용하여 보상 함수를 모델링할 수 있습니다. 널리 사용되는 방법 중 하나는 REINFORCE 또는 actor-critic과 같은 정책 그라데이션 방법을 사용하는 것입니다.


다음을 요약하면 Neural Bandit은 신경망 매개변수의 불확실성을 고려하여 신경망을 사용하여 보상 함수를 모델링합니다. 더 높은 보상 방향으로 정책을 업데이트하는 정책 그라데이션을 통한 탐색을 추가로 도입합니다. 이러한 형태의 탐색은 보다 방향성이 높기 때문에 대규모 작업 공간에서 유리할 수 있습니다.
가장 간단한 코드 구현은 다음과 같습니다.
import torch import torch.nn as nn import torch.optim as optim class NeuralNetwork(nn.Module): def __init__(self, n_features): super(NeuralNetwork, self).__init__() self.layer = nn.Sequential( nn.Linear(n_features, 32), nn.ReLU(), nn.Linear(32, 1) ) def forward(self, x): return self.layer(x) class NeuralBandit: def __init__(self, n_actions, n_features, learning_rate=0.01): self.n_actions = n_actions self.n_features = n_features self.learning_rate = learning_rate # Initialize the neural network model for each action self.models = [NeuralNetwork(n_features) for _ in range(n_actions)] self.optimizers = [ optim.Adam(model.parameters(), lr=self.learning_rate) for model in self.models ] self.criterion = nn.MSELoss() def predict(self, context): context_tensor = torch.tensor(context, dtype=torch.float32) # Convert to tensor with torch.no_grad(): return torch.cat( [model(context_tensor).reshape(1) for model in self.models] ) def update(self, action, context, reward): self.optimizers[action].zero_grad() context_tensor = torch.tensor(context, dtype=torch.float32) # Convert to tensor reward_tensor = torch.tensor(reward, dtype=torch.float32) # Convert to tensor pred_reward = self.models[action](context_tensor) loss = self.criterion(pred_reward, reward_tensor) loss.backward() self.optimizers[action].step() NeuralBandit의 경우 현재 모델 매개변수를 사용하여 주어진 상황에 따라 각 행동에 대한 예상 보상을 예측하고 선택한 행동에서 관찰된 보상을 기반으로 모델 매개변수를 업데이트하는 predict 방법 및 update 방법이 포함된 동일한 그림입니다. 이 구현에서는 NeuralBandit용 PyTorch를 사용합니다.
모델의 비교 성능
각 모델에는 고유한 장점과 단점이 있으며 모델 선택은 당면한 문제의 특정 요구 사항에 따라 달라집니다. 이러한 모델 중 일부의 세부 사항을 살펴보고 성능을 비교해 보겠습니다.
린UCB
LinUCB(선형 상한 신뢰 한계) 모델은 선형 회귀를 사용하여 주어진 상황에서 각 행동에 대해 예상되는 보상을 추정합니다. 또한 이러한 추정치의 불확실성을 추적하고 이를 사용하여 탐색을 장려합니다.
장점:
간단하고 계산적으로 효율적입니다.
그것은 후회에 대한 이론적 보증을 제공합니다.
단점:
- 보상 함수는 상황과 행동의 선형 함수라고 가정하며, 이는 더 복잡한 문제에는 적용되지 않을 수 있습니다.
의사결정나무 도적
Decision Tree Bandit 모델은 보상 함수를 의사결정 트리로 표현합니다. 각 리프 노드는 작업에 해당하며, 루트에서 리프 노드까지의 각 경로는 컨텍스트에 따른 결정 규칙을 나타냅니다.
장점:
해석 가능한 결정 규칙을 제공합니다.
복잡한 보상 기능을 처리할 수 있습니다.
단점:
- 특히 큰 나무의 경우 과적합으로 인해 문제가 발생할 수 있습니다.
- 트리의 최대 깊이와 같은 하이퍼파라미터 조정이 필요합니다.
신경 도둑
Neural Bandit 모델은 신경망을 사용하여 주어진 상황에서 각 행동에 대한 예상 보상을 추정합니다. 탐색을 장려하기 위해 정책 그라데이션 방법을 사용합니다.
장점:
복잡하고 비선형적인 보상 기능을 처리할 수 있습니다.
방향성 탐색을 수행할 수 있으며 이는 대규모 작업 공간에서 유용합니다.
단점:
- 이를 위해서는 신경망의 아키텍처 및 학습 속도와 같은 하이퍼파라미터를 조정해야 합니다.
- 특히 대규모 네트워크와 대규모 작업 공간의 경우 계산 비용이 많이 들 수 있습니다.
코드 비교 및 일반 실행 예:
다음은 앞서 언급하고 정의한 모든 모델의 도적들의 성능을 각 모델에 대한 시뮬레이션을 실행하여 비교하는 Python 코드입니다.
import matplotlib.pyplot as plt # Define the bandit environment n_actions = 10 n_features = 5 bandit = Bandit(n_actions, n_features) # Define the agents linucb_agent = LinUCB(n_actions, n_features, alpha=0.1) neural_agent = NeuralBandit(n_actions, n_features, learning_rate=0.01) tree_agent = DecisionTreeBandit(n_actions, n_features, max_depth=5) # Run the simulation for each agent n_steps = 1000 agents = [linucb_agent, tree_agent, neural_agent] cumulative_rewards = {agent.__class__.__name__: np.zeros(n_steps) for agent in agents} cumulative_regrets = {agent.__class__.__name__: np.zeros(n_steps) for agent in agents} for agent in agents: print(agent) for t in range(n_steps): x = np.random.randn(n_features) pred_rewards = agent.predict([x]) action = np.argmax(pred_rewards) reward = bandit.get_reward(action, x) optimal_reward = bandit.get_optimal_reward(x) agent.update(action, x, reward) cumulative_rewards[agent.__class__.__name__][t] = ( reward if t == 0 else cumulative_rewards[agent.__class__.__name__][t - 1] + reward ) cumulative_regrets[agent.__class__.__name__][t] = ( optimal_reward - reward if t == 0 else cumulative_regrets[agent.__class__.__name__][t - 1] + optimal_reward - reward ) # Plot the results plt.figure(figsize=(12, 6)) plt.subplot(121) for agent_name, rewards in cumulative_rewards.items(): plt.plot(rewards, label=agent_name) plt.xlabel("Steps") plt.ylabel("Cumulative Rewards") plt.legend() plt.subplot(122) for agent_name, regrets in cumulative_regrets.items(): plt.plot(regrets, label=agent_name) plt.xlabel("Steps") plt.ylabel("Cumulative Regrets") plt.legend() plt.show() 

응용 시나리오
- 개인화된 추천 : 이 시나리오에서 컨텍스트는 사용자 정보(나이, 성별, 과거 구매 내역 등) 및 항목 정보(항목 카테고리, 가격 등)일 수 있습니다. 액션은 추천할 아이템이고, 보상은 사용자가 아이템을 클릭했는지, 구매했는지를 나타냅니다. 상황별 밴딧(Contextual Bandit) 알고리즘을 활용하면 클릭률이나 수익을 극대화하는 개인화된 추천 정책을 학습할 수 있습니다.
- 임상 시험 : 임상 시험에서 맥락은 환자 정보(예: 연령, 성별, 병력)일 수 있고, 조치는 다양한 치료법이며, 보상은 건강 결과입니다. 상황별 밴딧(Contextual Bandit) 알고리즘은 치료 효과와 부작용의 균형을 유지하면서 환자의 건강 결과를 극대화하는 치료 정책을 학습할 수 있습니다.
- 온라인 광고 : 온라인 광고에서 맥락은 사용자 정보와 광고 정보일 수 있고, 행동은 표시할 광고이며, 보상은 사용자가 광고를 클릭했는지 여부입니다. Contextual Bandit 알고리즘은 광고 관련성과 사용자 선호도를 고려하여 클릭률이나 수익을 극대화하는 정책을 학습할 수 있습니다.
이러한 각 애플리케이션에서는 탐색과 활용의 균형을 맞추는 것이 중요합니다. 착취는 현재 지식을 바탕으로 최선의 행동을 선택하는 것이고, 탐색은 더 많은 지식을 얻기 위해 다양한 행동을 시도하는 것입니다. 상황별 밴딧 알고리즘은 이러한 탐색-이용 트레이드오프를 공식화하고 해결하기 위한 프레임워크를 제공합니다.
결론
상황별 도적은 피드백이 제한된 환경에서 의사 결정을 내리는 강력한 도구입니다. 의사 결정에서 컨텍스트를 활용하는 기능을 통해 기존 밴디트 알고리즘보다 더 복잡하고 미묘한 결정을 내릴 수 있습니다.
성능을 명시적으로 비교하지는 않았지만 알고리즘 선택은 문제 특성의 영향을 받아야 한다는 점에 주목했습니다. 단순한 관계의 경우 LinUCB와 의사결정 트리가 탁월한 성능을 발휘할 수 있고 복잡한 시나리오에서는 신경망이 탁월한 성능을 발휘할 수 있습니다. 각 방법은 수학적 단순성을 위한 LinUCB, 해석 가능성을 위한 의사결정 트리, 복잡한 관계를 처리하는 기능을 위한 신경망 등 고유한 장점을 제공했습니다. 올바른 접근 방식을 선택하는 것은 이 흥미로운 영역에서 효과적인 문제 해결의 핵심입니다.
전반적으로 상황 기반 적기 문제는 이를 해결하는 데 사용할 수 있는 다양한 알고리즘을 통해 강화 학습 내에서 매력적인 영역을 제시하며 이러한 강력한 모델의 훨씬 더 혁신적인 사용을 기대할 수 있습니다.









