

























Los bandidos contextuales son una clase de algoritmos de aprendizaje por refuerzo que se utilizan en modelos de toma de decisiones en los que un alumno debe elegir acciones que resulten en la mayor recompensa. Reciben su nombre del clásico problema de los juegos de azar del "bandido manco", en el que un jugador debe decidir a qué máquinas tragamonedas jugar, cuántas veces jugar en cada máquina y en qué orden jugarlas.


Lo que distingue a los bandidos contextuales es que el proceso de toma de decisiones está informado por el contexto. El contexto, en este caso, se refiere a un conjunto de variables observables que pueden impactar en el resultado de la acción. Esta adición acerca el problema de los bandidos a las aplicaciones del mundo real, como recomendaciones personalizadas, ensayos clínicos o colocación de anuncios, donde la decisión depende de circunstancias específicas.
La formulación de los problemas de bandidos contextuales
El problema del bandido contextual se puede implementar utilizando varios algoritmos. A continuación, proporciono una descripción general de alto nivel de la estructura algorítmica para problemas de bandidos contextuales:

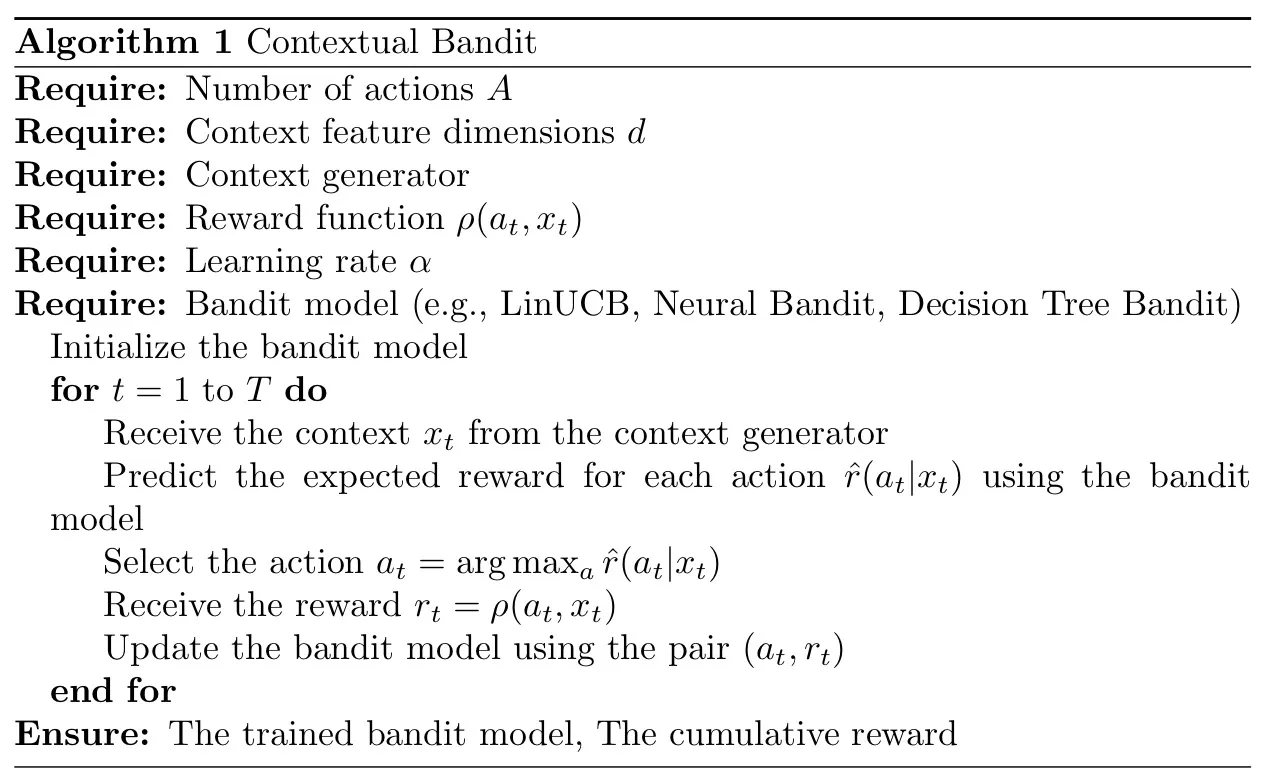
Y el siguiente algoritmo aquí es la matemática subyacente del problema del bandido contextual:


Para resumir todo lo anterior, en términos generales, el objetivo del algoritmo es maximizar la recompensa acumulada en un horizonte de tiempo. Tenga en cuenta que en cada ronda, se observa la recompensa solo por la acción elegida. Esto se conoce como retroalimentación parcial, que diferencia los problemas de bandido del aprendizaje supervisado.
El enfoque más común para resolver un problema de bandido contextual implica equilibrar la exploración y la explotación. La explotación significa usar el conocimiento actual para tomar la mejor decisión, mientras que la exploración implica tomar acciones menos seguras para recopilar más información.
El equilibrio entre exploración y explotación se manifiesta en varios algoritmos diseñados para resolver el problema de Contextual Bandit, como LinUCB, Neural Bandit o Decision Tree Bandit. Todos estos algoritmos emplean sus estrategias únicas para abordar esta compensación.
La representación en código de esta idea para Bandit es:
class Bandit: def __init__(self, n_actions, n_features): self.n_actions = n_actions self.n_features = n_features self.theta = np.random.randn(n_actions, n_features) def get_reward(self, action, x): return x @ self.theta[action] + np.random.normal() def get_optimal_reward(self, x): return np.max(x @ self.theta.T) # Usage example # Define the bandit environment n_actions = 10 n_features = 5 bandit = Bandit(n_actions, n_features) # Define the model agent model_agent = model(n_features, *args) # Define the context (features) x = np.random.randn(n_features) # The agent makes a prediction pred_rewards = np.array([model_agent.predict(x) for _ in range(n_actions)]) # The agent chooses an action action = np.argmax(pred_rewards) # The agent gets a reward reward = bandit.get_reward(action, x) # The agent updates its parameters model_agent.update(x, reward)Algoritmo LinUCB
El algoritmo LinUCB es un algoritmo bandido contextual que modela la recompensa esperada de una acción dado un contexto como una función lineal, y selecciona acciones basadas en el principio del límite de confianza superior (UCB) para equilibrar la exploración y la explotación. Explota la mejor opción disponible según el modelo actual (que es un modelo lineal), pero también explora opciones que potencialmente podrían proporcionar mayores recompensas, considerando la incertidumbre en las estimaciones del modelo. Matemáticamente se puede presentar como:


Este enfoque asegura que el algoritmo explore acciones para las cuales tiene una alta incertidumbre.
Después de seleccionar una acción y recibir una recompensa, LinUCB actualiza los parámetros de la siguiente manera:


Y aquí está la implementación del código en Python:
import numpy as np class LinUCB: def __init__(self, n_actions, n_features, alpha=1.0): self.n_actions = n_actions self.n_features = n_features self.alpha = alpha # Initialize parameters self.A = np.array( [np.identity(n_features) for _ in range(n_actions)] ) # action covariance matrix self.b = np.array( [np.zeros(n_features) for _ in range(n_actions)] ) # action reward vector self.theta = np.array( [np.zeros(n_features) for _ in range(n_actions)] ) # action parameter vector def predict(self, context): context = np.array(context) # Convert list to ndarray context = context.reshape( -1, 1 ) # reshape the context to a single-column matrix p = np.zeros(self.n_actions) for a in range(self.n_actions): theta = np.dot( np.linalg.inv(self.A[a]), self.b[a] ) # theta_a = A_a^-1 * b_a theta = theta.reshape(-1, 1) # Explicitly reshape theta p[a] = np.dot(theta.T, context) + self.alpha * np.sqrt( np.dot(context.T, np.dot(np.linalg.inv(self.A[a]), context)) ) # p_t(a|x_t) = theta_a^T * x_t + alpha * sqrt(x_t^T * A_a^-1 * x_t) return p def update(self, action, context, reward): self.A[action] += np.outer(context, context) # A_a = A_a + x_t * x_t^T self.b[action] += reward * context # b_a = b_a + r_t * x_txAlgoritmo de árbol de decisión
Decision Tree Bandit modela la función de recompensa como un árbol de decisiones, donde cada nodo de hoja corresponde a una acción y cada ruta desde la raíz hasta un nodo de hoja representa una regla de decisión basada en el contexto. Realiza exploración y explotación a través de un marco estadístico, realizando divisiones y fusiones en el árbol de decisión en función de pruebas de significación estadística.


El objetivo es aprender el mejor árbol de decisión que maximice la recompensa acumulada esperada:


El aprendizaje del árbol de decisiones generalmente implica dos pasos:
- Tree Growing : comenzando con un solo nodo (raíz), divida recursivamente cada nodo en función de una característica y un umbral que maximice la recompensa esperada. Este proceso continúa hasta que se cumple alguna condición de parada, como alcanzar una profundidad máxima o un número mínimo de muestras por hoja.
- Poda de árboles : a partir del árbol completamente desarrollado, combine recursivamente los elementos secundarios de cada nodo si aumenta o no disminuye significativamente la recompensa esperada. Este proceso continúa hasta que no se pueden realizar más fusiones.
El criterio de división y el criterio de fusión generalmente se definen en base a pruebas estadísticas para garantizar la importancia estadística de la mejora.
from sklearn.tree import DecisionTreeRegressor class DecisionTreeBandit: def __init__(self, n_actions, n_features, max_depth=5): self.n_actions = n_actions self.n_features = n_features self.max_depth = max_depth # Initialize the decision tree model for each action self.models = [ DecisionTreeRegressor(max_depth=self.max_depth) for _ in range(n_actions) ] self.data = [[] for _ in range(n_actions)] def predict(self, context): return np.array( [self._predict_for_action(a, context) for a in range(self.n_actions)] ) def _predict_for_action(self, action, context): if not self.data[action]: return 0.0 X, y = zip(*self.data[action]) self.models[action].fit(np.array(X), np.array(y)) context_np = np.array(context).reshape( 1, -1 ) # convert list to NumPy array and reshape return self.models[action].predict(context_np)[0] def update(self, action, context, reward): self.data[action].append((context, reward)) Para DecisionTreeBandit, el método predict usa los parámetros del modelo actual para predecir la recompensa esperada para cada acción en un contexto determinado. El método update actualiza los parámetros del modelo en función de la recompensa observada de la acción seleccionada. Esta implementación usa scikit-learn para DecisionTreeBandit.
Bandidos contextuales con redes neuronales
Los modelos de aprendizaje profundo se pueden utilizar para aproximar la función de recompensa en casos no lineales o de alta dimensión. La política suele ser una red neuronal que toma el contexto y las acciones disponibles como entrada y genera las probabilidades de realizar cada acción.
Un enfoque popular de aprendizaje profundo es utilizar una arquitectura actor-crítico, donde una red (el actor) decide qué acción tomar y la otra red (el crítico) evalúa la acción realizada por el actor.
Para escenarios más complejos donde la relación entre el contexto y la recompensa no es lineal, podemos usar una red neuronal para modelar la función de recompensa. Un método popular es utilizar un método de gradiente de políticas, como REINFORCE o actor-crítico.


En resumen, Neural Bandit utiliza redes neuronales para modelar la función de recompensa, teniendo en cuenta la incertidumbre en los parámetros de la red neuronal. Además, introduce la exploración a través de gradientes de políticas donde actualiza la política en la dirección de mayores recompensas. Esta forma de exploración es más dirigida, lo que puede ser beneficioso en grandes espacios de acción.
La implementación de código más simple es la siguiente:
import torch import torch.nn as nn import torch.optim as optim class NeuralNetwork(nn.Module): def __init__(self, n_features): super(NeuralNetwork, self).__init__() self.layer = nn.Sequential( nn.Linear(n_features, 32), nn.ReLU(), nn.Linear(32, 1) ) def forward(self, x): return self.layer(x) class NeuralBandit: def __init__(self, n_actions, n_features, learning_rate=0.01): self.n_actions = n_actions self.n_features = n_features self.learning_rate = learning_rate # Initialize the neural network model for each action self.models = [NeuralNetwork(n_features) for _ in range(n_actions)] self.optimizers = [ optim.Adam(model.parameters(), lr=self.learning_rate) for model in self.models ] self.criterion = nn.MSELoss() def predict(self, context): context_tensor = torch.tensor(context, dtype=torch.float32) # Convert to tensor with torch.no_grad(): return torch.cat( [model(context_tensor).reshape(1) for model in self.models] ) def update(self, action, context, reward): self.optimizers[action].zero_grad() context_tensor = torch.tensor(context, dtype=torch.float32) # Convert to tensor reward_tensor = torch.tensor(reward, dtype=torch.float32) # Convert to tensor pred_reward = self.models[action](context_tensor) loss = self.criterion(pred_reward, reward_tensor) loss.backward() self.optimizers[action].step() Para NeuralBandit, la misma imagen con el método predict y el método update que utilizan los parámetros del modelo actual para predecir la recompensa esperada para cada acción dado un contexto y actualiza los parámetros del modelo en función de la recompensa observada de la acción seleccionada. Esta implementación usa PyTorch para NeuralBandit.
Rendimiento comparativo de los modelos
Cada modelo viene con sus ventajas y desventajas únicas, y la elección del modelo depende de los requisitos específicos del problema en cuestión. Profundicemos en los detalles de algunos de estos modelos y luego comparemos sus prestaciones.
LinUCB
El modelo Linear Upper Confidence Bound (LinUCB) utiliza la regresión lineal para estimar la recompensa esperada para cada acción en un contexto. También realiza un seguimiento de la incertidumbre de estas estimaciones y la utiliza para fomentar la exploración.
ventajas:
Es simple y computacionalmente eficiente.
Proporciona garantías teóricas para su límite de arrepentimiento.
Desventajas:
- Asume que la función de recompensa es una función lineal del contexto y la acción, lo que puede no ser válido para problemas más complejos.
Bandido del árbol de decisiones
El modelo Decision Tree Bandit representa la función de recompensa como un árbol de decisiones. Cada nodo hoja corresponde a una acción, y cada ruta desde la raíz hasta un nodo hoja representa una regla de decisión basada en el contexto.
ventajas:
Proporciona reglas de decisión interpretables.
Puede manejar funciones de recompensa complejas.
Desventajas:
- Puede sufrir de sobreajuste, especialmente para árboles grandes.
- Requiere ajustar hiperparámetros como la profundidad máxima del árbol.
Bandido neural
El modelo Neural Bandit utiliza una red neuronal para estimar la recompensa esperada por cada acción dada un contexto. Utiliza métodos de gradiente de políticas para fomentar la exploración.
ventajas:
Puede manejar funciones de recompensa complejas y no lineales.
Puede realizar exploración dirigida, lo que es beneficioso en grandes espacios de acción.
Desventajas:
- Requiere ajustar hiperparámetros como la arquitectura y la tasa de aprendizaje de la red neuronal.
- Puede ser computacionalmente costoso, especialmente para grandes redes y grandes espacios de acción.
Comparación de código y ejemplo general de ejecución:
Aquí está el código de Python para comparar las actuaciones de todos los bandidos de estos modelos mencionados y definidos antes con la ejecución de una simulación para cada modelo.
import matplotlib.pyplot as plt # Define the bandit environment n_actions = 10 n_features = 5 bandit = Bandit(n_actions, n_features) # Define the agents linucb_agent = LinUCB(n_actions, n_features, alpha=0.1) neural_agent = NeuralBandit(n_actions, n_features, learning_rate=0.01) tree_agent = DecisionTreeBandit(n_actions, n_features, max_depth=5) # Run the simulation for each agent n_steps = 1000 agents = [linucb_agent, tree_agent, neural_agent] cumulative_rewards = {agent.__class__.__name__: np.zeros(n_steps) for agent in agents} cumulative_regrets = {agent.__class__.__name__: np.zeros(n_steps) for agent in agents} for agent in agents: print(agent) for t in range(n_steps): x = np.random.randn(n_features) pred_rewards = agent.predict([x]) action = np.argmax(pred_rewards) reward = bandit.get_reward(action, x) optimal_reward = bandit.get_optimal_reward(x) agent.update(action, x, reward) cumulative_rewards[agent.__class__.__name__][t] = ( reward if t == 0 else cumulative_rewards[agent.__class__.__name__][t - 1] + reward ) cumulative_regrets[agent.__class__.__name__][t] = ( optimal_reward - reward if t == 0 else cumulative_regrets[agent.__class__.__name__][t - 1] + optimal_reward - reward ) # Plot the results plt.figure(figsize=(12, 6)) plt.subplot(121) for agent_name, rewards in cumulative_rewards.items(): plt.plot(rewards, label=agent_name) plt.xlabel("Steps") plt.ylabel("Cumulative Rewards") plt.legend() plt.subplot(122) for agent_name, regrets in cumulative_regrets.items(): plt.plot(regrets, label=agent_name) plt.xlabel("Steps") plt.ylabel("Cumulative Regrets") plt.legend() plt.show() 

Escenarios de aplicación
- Recomendación personalizada : en este escenario, el contexto podría ser información del usuario (como edad, género, compras anteriores) e información del artículo (como categoría del artículo, precio). Las acciones son los artículos a recomendar, y la recompensa es si el usuario hizo clic o compró el artículo. Se puede usar un algoritmo de bandido contextual para aprender una política de recomendación personalizada que maximice la tasa de clics o los ingresos.
- Ensayos clínicos : en los ensayos clínicos, el contexto podría ser información del paciente (como edad, sexo, historial médico), las acciones son los diferentes tratamientos y la recompensa es el resultado de salud. Un algoritmo de bandido contextual puede aprender una política de tratamiento que maximice el resultado de salud del paciente, equilibrando el efecto del tratamiento y los efectos secundarios.
- Publicidad en línea : en la publicidad en línea, el contexto podría ser la información del usuario y la información del anuncio, las acciones son los anuncios que se muestran y la recompensa es si el usuario hizo clic en el anuncio. Un algoritmo de bandido contextual puede aprender una política que maximiza la tasa de clics o los ingresos, teniendo en cuenta la relevancia del anuncio y las preferencias del usuario.
En cada una de estas aplicaciones, es fundamental equilibrar la exploración y la explotación. La explotación es elegir la mejor acción basada en el conocimiento actual, mientras que la exploración es probar diferentes acciones para obtener más conocimiento. Los algoritmos de bandidos contextuales proporcionan un marco para formalizar y resolver este equilibrio entre exploración y explotación.
Conclusión
Los bandidos contextuales son una herramienta poderosa para la toma de decisiones en entornos con retroalimentación limitada. La capacidad de aprovechar el contexto en la toma de decisiones permite tomar decisiones más complejas y matizadas que los algoritmos bandit tradicionales.
Si bien no comparamos el rendimiento explícitamente, notamos que la elección del algoritmo debe estar influenciada por las características del problema. Para relaciones más simples, LinUCB y Decision Trees podrían sobresalir, mientras que Neural Networks puede superar en escenarios complejos. Cada método ofreció fortalezas únicas: LinUCB por su simplicidad matemática, Decision Trees por su interpretabilidad y Neural Networks por su capacidad para manejar relaciones complejas. Elegir el enfoque correcto es clave para la resolución efectiva de problemas en este apasionante campo.
En general, los problemas de bandidos basados en el contexto presentan un área atractiva dentro del aprendizaje por refuerzo, con diversos algoritmos disponibles para abordarlos y podemos esperar ver usos aún más innovadores de estos poderosos modelos.








