


























Contextual bandits are a class of reinforcement learning algorithms used in decision-making models where a learner must choose actions that result in the most reward. They are named after the classical "one-armed bandit" problem of gambling, where a player needs to decide which slot machines to play, how many times to play each machine, and in what order to play them.


What sets contextual bandits apart is that the decision-making process is informed by the context. The context, in this case, refers to a set of observable variables that can impact the result of the action. This addition makes the bandit problem closer to real-world applications, such as personalized recommendations, clinical trials, or ad placement, where the decision depends on specific circumstances.
The Formulation of the Contextual Bandit Problems
The contextual bandit problem can be implemented using various algorithms. Below, I provide a general high-level overview of the algorithmic structure for contextual bandit problems:

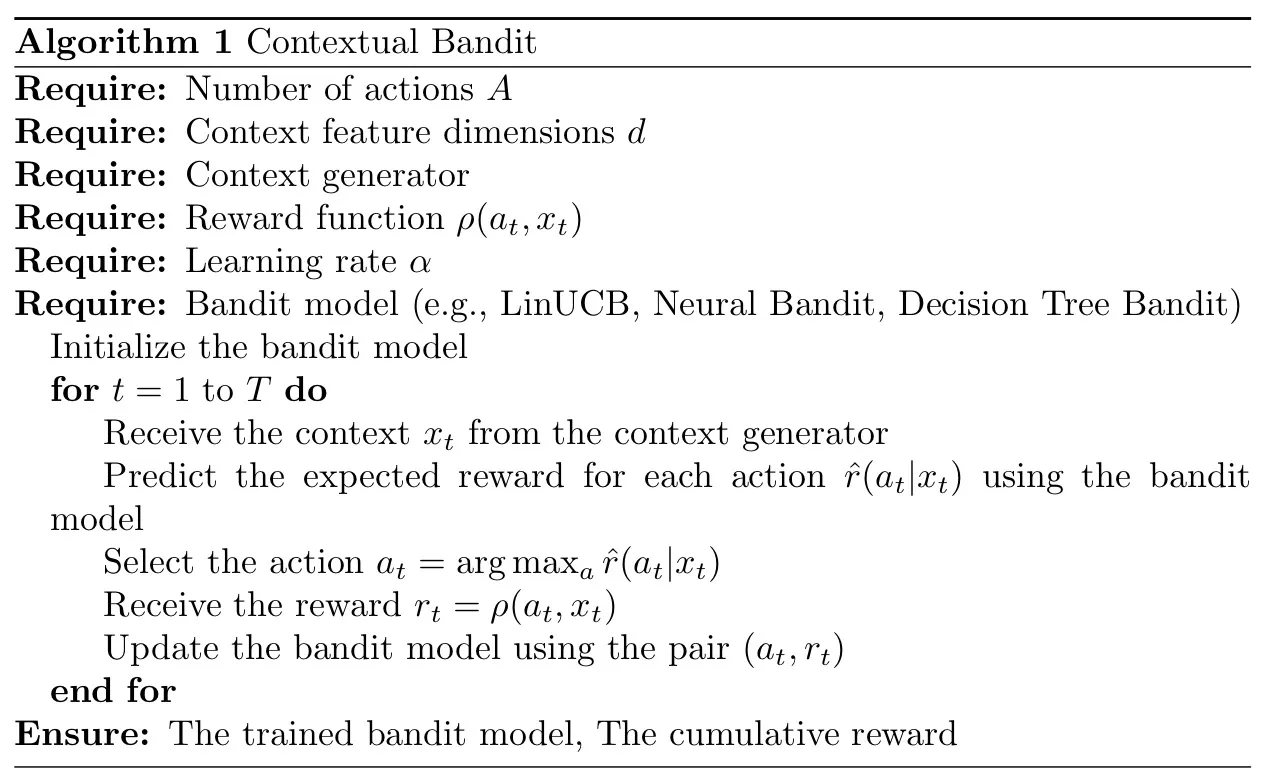
And following algorithm here is the underlying math of the contextual bandit problem:


To sum up all above generally speaking the goal of the algorithm is to maximize the cumulative reward over some time horizon. Note that in each round, the reward for only the chosen action is observed. This is known as partial feedback, which differentiates bandit problems from supervised learning.
The most common approach for solving a contextual bandit problem involves balancing exploration and exploitation . Exploitation means using the current knowledge to make the best decision, while exploration involves taking less certain actions to gather more information.
The trade-off between exploration and exploitation is manifested in various algorithms designed to solve the Contextual Bandit problem, such as LinUCB, Neural Bandit, or Decision Tree Bandit. All of these algorithms employ their unique strategies to address this trade-off.
The code representation of this idea for Bandit is:
class Bandit:
def __init__(self, n_actions, n_features):
self.n_actions = n_actions
self.n_features = n_features
self.theta = np.random.randn(n_actions, n_features)
def get_reward(self, action, x):
return x @ self.theta[action] + np.random.normal()
def get_optimal_reward(self, x):
return np.max(x @ self.theta.T)
# Usage example
# Define the bandit environment
n_actions = 10
n_features = 5
bandit = Bandit(n_actions, n_features)
# Define the model agent
model_agent = model(n_features, *args)
# Define the context (features)
x = np.random.randn(n_features)
# The agent makes a prediction
pred_rewards = np.array([model_agent.predict(x) for _ in range(n_actions)])
# The agent chooses an action
action = np.argmax(pred_rewards)
# The agent gets a reward
reward = bandit.get_reward(action, x)
# The agent updates its parameters
model_agent.update(x, reward)
LinUCB Algorithm
The LinUCB algorithm is a contextual bandit algorithm that models the expected reward of an action given a context as a linear function, and it selects actions based on the Upper Confidence Bound (UCB) principle to balance exploration and exploitation. It exploits the best option available according to the current model (which is a linear model), but it also explores options that could potentially provide higher rewards, considering the uncertainty in the model's estimates. Mathematically it can be presented as:


This approach ensures that the algorithm explores actions for which it has high uncertainty.
After selecting an action and receiving a reward, LinUCB updates the parameters as follows:


And here is the code implementation in Python:
import numpy as np
class LinUCB:
def __init__(self, n_actions, n_features, alpha=1.0):
self.n_actions = n_actions
self.n_features = n_features
self.alpha = alpha
# Initialize parameters
self.A = np.array(
[np.identity(n_features) for _ in range(n_actions)]
) # action covariance matrix
self.b = np.array(
[np.zeros(n_features) for _ in range(n_actions)]
) # action reward vector
self.theta = np.array(
[np.zeros(n_features) for _ in range(n_actions)]
) # action parameter vector
def predict(self, context):
context = np.array(context) # Convert list to ndarray
context = context.reshape(
-1, 1
) # reshape the context to a single-column matrix
p = np.zeros(self.n_actions)
for a in range(self.n_actions):
theta = np.dot(
np.linalg.inv(self.A[a]), self.b[a]
) # theta_a = A_a^-1 * b_a
theta = theta.reshape(-1, 1) # Explicitly reshape theta
p[a] = np.dot(theta.T, context) + self.alpha * np.sqrt(
np.dot(context.T, np.dot(np.linalg.inv(self.A[a]), context))
) # p_t(a|x_t) = theta_a^T * x_t + alpha * sqrt(x_t^T * A_a^-1 * x_t)
return p
def update(self, action, context, reward):
self.A[action] += np.outer(context, context) # A_a = A_a + x_t * x_t^T
self.b[action] += reward * context # b_a = b_a + r_t * x_tx
Decision Tree Algorithm
Decision Tree Bandit models the reward function as a decision tree, where each leaf node corresponds to an action and each path from the root to a leaf node represents a decision rule based on the context. It performs exploration and exploitation through a statistical framework, making splits and merges in the decision tree based on statistical significance tests.


The objective is to learn the best decision tree that maximizes the expected cumulative reward:


Decision tree learning usually involves two steps:
- Tree Growing: Starting with a single node (root), recursively split each node based on a feature and a threshold that maximizes the expected reward. This process continues until some stopping condition is met, such as reaching a maximum depth or minimum number of samples per leaf.
- Tree Pruning: Starting from the fully grown tree, recursively merge the children of each node if it increases or does not decrease the expected reward significantly. This process continues until no further merging can be performed.
The splitting criterion and merging criterion are usually defined based on statistical tests to ensure the statistical significance of the improvement.
from sklearn.tree import DecisionTreeRegressor
class DecisionTreeBandit:
def __init__(self, n_actions, n_features, max_depth=5):
self.n_actions = n_actions
self.n_features = n_features
self.max_depth = max_depth
# Initialize the decision tree model for each action
self.models = [
DecisionTreeRegressor(max_depth=self.max_depth) for _ in range(n_actions)
]
self.data = [[] for _ in range(n_actions)]
def predict(self, context):
return np.array(
[self._predict_for_action(a, context) for a in range(self.n_actions)]
)
def _predict_for_action(self, action, context):
if not self.data[action]:
return 0.0
X, y = zip(*self.data[action])
self.models[action].fit(np.array(X), np.array(y))
context_np = np.array(context).reshape(
1, -1
) # convert list to NumPy array and reshape
return self.models[action].predict(context_np)[0]
def update(self, action, context, reward):
self.data[action].append((context, reward))
For DecisionTreeBandit, the predict method uses the current model parameters to predict the expected reward for each action given a context. The update method updates the model parameters based on the observed reward from the selected action. This implementation use scikit-learn for DecisionTreeBandit.
Contextual Bandits with Neural Networks
Deep learning models can be used to approximate the reward function in high-dimensional or non-linear cases. The policy is typically a neural network that takes the context and available actions as input and outputs the probabilities of taking each action.
A popular deep learning approach is to use an actor-critic architecture, where one network (the actor) decides which action to take, and the other network (the critic) evaluates the action taken by the actor.
For more complex scenarios where the relationship between the context and the reward is not linear, we can use a neural network to model the reward function. One popular method is to use a policy gradient method, such as REINFORCE or actor-critic.


To sum up the following Neural Bandit uses neural networks to model the reward function, taking into account the uncertainty in the parameters of the neural network. It further introduces exploration through policy gradients where it updates the policy in the direction of higher rewards. This form of exploration is more directed, which can be beneficial in large action spaces.
Simplest code implementation is the following:
import torch
import torch.nn as nn
import torch.optim as optim
class NeuralNetwork(nn.Module):
def __init__(self, n_features):
super(NeuralNetwork, self).__init__()
self.layer = nn.Sequential(
nn.Linear(n_features, 32), nn.ReLU(), nn.Linear(32, 1)
)
def forward(self, x):
return self.layer(x)
class NeuralBandit:
def __init__(self, n_actions, n_features, learning_rate=0.01):
self.n_actions = n_actions
self.n_features = n_features
self.learning_rate = learning_rate
# Initialize the neural network model for each action
self.models = [NeuralNetwork(n_features) for _ in range(n_actions)]
self.optimizers = [
optim.Adam(model.parameters(), lr=self.learning_rate)
for model in self.models
]
self.criterion = nn.MSELoss()
def predict(self, context):
context_tensor = torch.tensor(context, dtype=torch.float32) # Convert to tensor
with torch.no_grad():
return torch.cat(
[model(context_tensor).reshape(1) for model in self.models]
)
def update(self, action, context, reward):
self.optimizers[action].zero_grad()
context_tensor = torch.tensor(context, dtype=torch.float32) # Convert to tensor
reward_tensor = torch.tensor(reward, dtype=torch.float32) # Convert to tensor
pred_reward = self.models[action](context_tensor)
loss = self.criterion(pred_reward, reward_tensor)
loss.backward()
self.optimizers[action].step()
For NeuralBandit the same picture with predict method and update method that use the current model parameters to predict the expected reward for each action given a context and updates the model parameters based on the observed reward from the selected action. This implementation use PyTorch for NeuralBandit.
Comparative performance of Models
Each model comes with its unique advantages and disadvantages, and the choice of model depends on the specific requirements of the problem at hand. Let's delve into the specifics of some of these models and then compare their performances.
LinUCB
The Linear Upper Confidence Bound (LinUCB) model uses linear regression to estimate the expected reward for each action given a context. It also keeps track of the uncertainty of these estimates and uses it to encourage exploration.
Advantages:
-
It is simple and computationally efficient.
-
It provides theoretical guarantees for its regret bound.
Disadvantages:
- It assumes the reward function is a linear function of the context and action, which may not hold for more complex problems.
Decision Tree Bandit
The Decision Tree Bandit model represents the reward function as a decision tree. Each leaf node corresponds to an action, and each path from the root to a leaf node represents a decision rule based on the context.
Advantages:
-
It provides interpretable decision rules.
-
It can handle complex reward functions.
Disadvantages:
- It may suffer from overfitting, especially for large trees.
- It requires tuning hyperparameters such as the maximum depth of the tree.
Neural Bandit
The Neural Bandit model uses a neural network to estimate the expected reward for each action given a context. It uses policy gradient methods to encourage exploration.
Advantages:
-
It can handle complex, non-linear reward functions.
-
It can perform directed exploration, which is beneficial in large action spaces.
Disadvantages:
- It requires tuning hyperparameters such as the architecture and learning rate of the neural network.
- It may be computationally expensive, especially for large networks and large action spaces.
Code comparison and general running example:
Here is Python code to compare the performances of all these model’s bandits mentioned and defined before with running a simulation for each model.
import matplotlib.pyplot as plt
# Define the bandit environment
n_actions = 10
n_features = 5
bandit = Bandit(n_actions, n_features)
# Define the agents
linucb_agent = LinUCB(n_actions, n_features, alpha=0.1)
neural_agent = NeuralBandit(n_actions, n_features, learning_rate=0.01)
tree_agent = DecisionTreeBandit(n_actions, n_features, max_depth=5)
# Run the simulation for each agent
n_steps = 1000
agents = [linucb_agent, tree_agent, neural_agent]
cumulative_rewards = {agent.__class__.__name__: np.zeros(n_steps) for agent in agents}
cumulative_regrets = {agent.__class__.__name__: np.zeros(n_steps) for agent in agents}
for agent in agents:
print(agent)
for t in range(n_steps):
x = np.random.randn(n_features)
pred_rewards = agent.predict([x])
action = np.argmax(pred_rewards)
reward = bandit.get_reward(action, x)
optimal_reward = bandit.get_optimal_reward(x)
agent.update(action, x, reward)
cumulative_rewards[agent.__class__.__name__][t] = (
reward
if t == 0
else cumulative_rewards[agent.__class__.__name__][t - 1] + reward
)
cumulative_regrets[agent.__class__.__name__][t] = (
optimal_reward - reward
if t == 0
else cumulative_regrets[agent.__class__.__name__][t - 1]
+ optimal_reward
- reward
)
# Plot the results
plt.figure(figsize=(12, 6))
plt.subplot(121)
for agent_name, rewards in cumulative_rewards.items():
plt.plot(rewards, label=agent_name)
plt.xlabel("Steps")
plt.ylabel("Cumulative Rewards")
plt.legend()
plt.subplot(122)
for agent_name, regrets in cumulative_regrets.items():
plt.plot(regrets, label=agent_name)
plt.xlabel("Steps")
plt.ylabel("Cumulative Regrets")
plt.legend()
plt.show()


Application Scenarios
- Personalized Recommendation: In this scenario, the context could be user information (like age, gender, past purchases) and item information (like item category, price). The actions are the items to recommend, and the reward is whether the user clicked on or bought the item. A contextual bandit algorithm can be used to learn a personalized recommendation policy that maximizes the click-through rate or revenue.
- Clinical Trials: In clinical trials, the context could be patient information (like age, gender, medical history), the actions are the different treatments, and the reward is the health outcome. A contextual bandit algorithm can learn a treatment policy that maximizes the patient's health outcome, balancing the treatment effect and side effects.
- Online Advertising: In online advertising, the context could be user information and ad information, the actions are the ads to display, and the reward is whether the user clicked on the ad. A contextual bandit algorithm can learn a policy that maximizes the click-through rate or revenue, considering the ad relevance and user preferences.
In each of these applications, it's crucial to balance exploration and exploitation. Exploitation is choosing the best action based on current knowledge, while exploration is trying out different actions to gain more knowledge. Contextual bandit algorithms provide a framework to formalize and solve this exploration-exploitation trade-off.
Conclusion
Contextual bandits are a powerful tool for decision-making in environments with limited feedback. The ability to leverage context in decision-making allows for more complex and nuanced decisions than traditional bandit algorithms.
While we didn't compare performance explicitly, we noted that the choice of algorithm should be influenced by the problem characteristics. For simpler relationships, LinUCB and Decision Trees could excel, while Neural Networks may outperform in complex scenarios.Each method offered unique strengths: LinUCB for its mathematical simplicity, Decision Trees for their interpretability, and Neural Networks for their ability to handle complex relationships. Choosing the right approach is key to effective problem-solving in this exciting domain.
Overall, context-based bandit problems present an engaging area within reinforcement learning, with diverse algorithms available to tackle them and we can expect to see even more innovative uses of these powerful models.











