


























প্রাসঙ্গিক দস্যুরা সিদ্ধান্ত নেওয়ার মডেলগুলিতে ব্যবহৃত শক্তিবৃদ্ধি শেখার অ্যালগরিদমের একটি শ্রেণী যেখানে একজন শিক্ষার্থীকে অবশ্যই এমন ক্রিয়াগুলি বেছে নিতে হবে যা সর্বাধিক পুরষ্কার দেয়। তাদের নামকরণ করা হয়েছে জুয়া খেলার ধ্রুপদী "এক-সশস্ত্র দস্যু" সমস্যা থেকে, যেখানে একজন খেলোয়াড়কে কোন স্লট মেশিন খেলতে হবে, প্রতিটি মেশিন কতবার খেলতে হবে এবং কোন ক্রমে সেগুলি খেলতে হবে তা নির্ধারণ করতে হবে।


প্রাসঙ্গিক দস্যুদের যা আলাদা করে তা হল সিদ্ধান্ত গ্রহণের প্রক্রিয়াটি প্রসঙ্গ দ্বারা অবহিত করা হয়। প্রসঙ্গ, এই ক্ষেত্রে, পর্যবেক্ষণযোগ্য ভেরিয়েবলের একটি সেট বোঝায় যা কর্মের ফলাফলকে প্রভাবিত করতে পারে। এই সংযোজন দস্যু সমস্যাটিকে বাস্তব-বিশ্বের অ্যাপ্লিকেশনগুলির কাছাকাছি করে তোলে, যেমন ব্যক্তিগতকৃত সুপারিশ, ক্লিনিকাল ট্রায়াল বা বিজ্ঞাপন বসানো, যেখানে সিদ্ধান্ত নির্দিষ্ট পরিস্থিতিতে নির্ভর করে।
প্রাসঙ্গিক দস্যু সমস্যা প্রণয়ন
প্রাসঙ্গিক দস্যু সমস্যা বিভিন্ন অ্যালগরিদম ব্যবহার করে বাস্তবায়ন করা যেতে পারে। নীচে, আমি প্রাসঙ্গিক দস্যু সমস্যার জন্য অ্যালগরিদমিক কাঠামোর একটি সাধারণ উচ্চ-স্তরের ওভারভিউ প্রদান করছি:

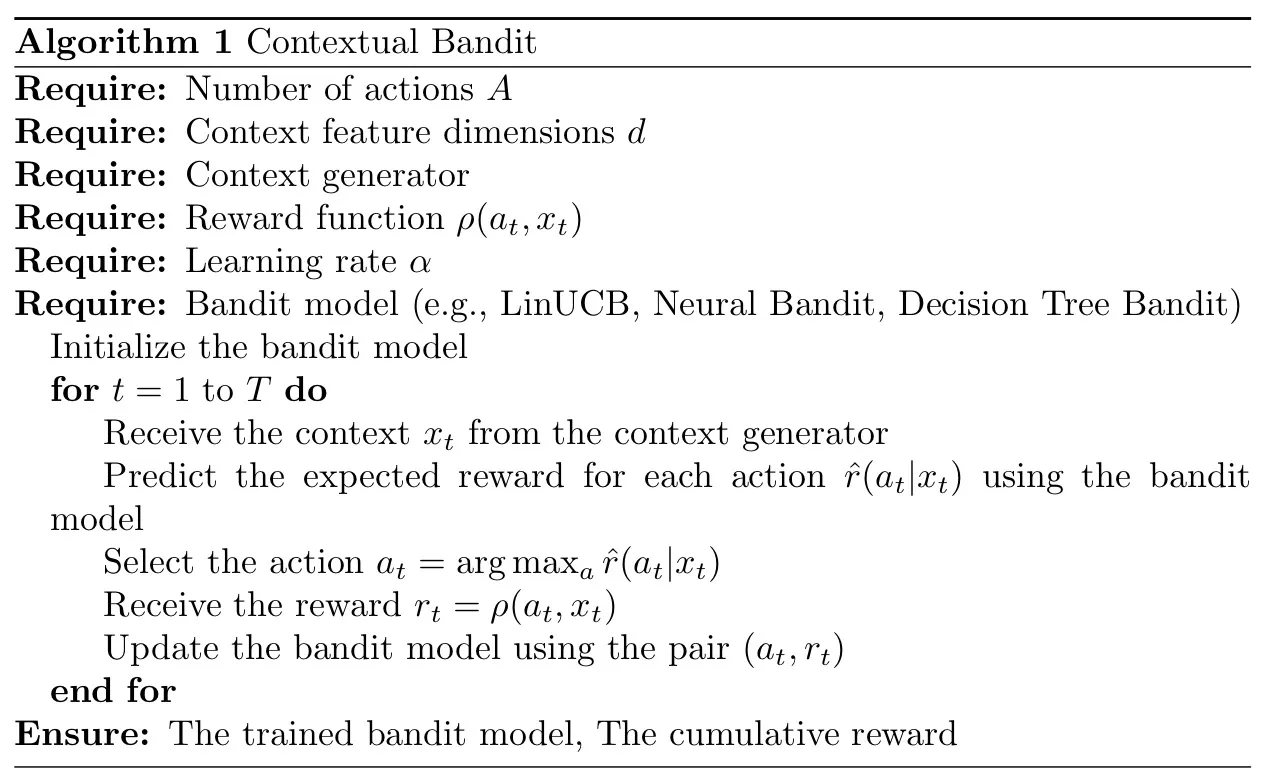
এবং নিম্নলিখিত অ্যালগরিদম এখানে প্রাসঙ্গিক দস্যু সমস্যার অন্তর্নিহিত গণিত:


উপরের সবগুলোকে সংক্ষেপে বলতে গেলে সাধারণত অ্যালগরিদমের লক্ষ্য হল কিছু সময়ের দিগন্তে ক্রমবর্ধমান পুরষ্কার বাড়ানো। মনে রাখবেন যে প্রতিটি রাউন্ডে, শুধুমাত্র নির্বাচিত কর্মের জন্য পুরস্কার পরিলক্ষিত হয়। এটি আংশিক প্রতিক্রিয়া হিসাবে পরিচিত, যা তত্ত্বাবধানে শিক্ষার থেকে দস্যু সমস্যাগুলিকে আলাদা করে।
একটি প্রাসঙ্গিক দস্যু সমস্যা সমাধানের জন্য সবচেয়ে সাধারণ পদ্ধতির মধ্যে অন্বেষণ এবং শোষণের ভারসাম্য জড়িত। শোষণ মানে সর্বোত্তম সিদ্ধান্ত নেওয়ার জন্য বর্তমান জ্ঞান ব্যবহার করা, যখন অন্বেষণে আরও তথ্য সংগ্রহের জন্য কম নির্দিষ্ট পদক্ষেপ নেওয়া জড়িত।
অন্বেষণ এবং শোষণের মধ্যকার লেনদেন বিভিন্ন অ্যালগরিদমে প্রকাশ পায় যা কনটেক্সচুয়াল ব্যান্ডিট সমস্যা সমাধানের জন্য ডিজাইন করা হয়েছে, যেমন LinUCB, নিউরাল ব্যান্ডিট, বা ডিসিশন ট্রি ব্যান্ডিট। এই সমস্ত অ্যালগরিদম এই ট্রেড-অফ মোকাবেলার জন্য তাদের অনন্য কৌশল নিযুক্ত করে।
দস্যুদের জন্য এই ধারণার কোড উপস্থাপনা হল:
class Bandit: def __init__(self, n_actions, n_features): self.n_actions = n_actions self.n_features = n_features self.theta = np.random.randn(n_actions, n_features) def get_reward(self, action, x): return x @ self.theta[action] + np.random.normal() def get_optimal_reward(self, x): return np.max(x @ self.theta.T) # Usage example # Define the bandit environment n_actions = 10 n_features = 5 bandit = Bandit(n_actions, n_features) # Define the model agent model_agent = model(n_features, *args) # Define the context (features) x = np.random.randn(n_features) # The agent makes a prediction pred_rewards = np.array([model_agent.predict(x) for _ in range(n_actions)]) # The agent chooses an action action = np.argmax(pred_rewards) # The agent gets a reward reward = bandit.get_reward(action, x) # The agent updates its parameters model_agent.update(x, reward)LinUCB অ্যালগরিদম
LinUCB অ্যালগরিদম হল একটি প্রাসঙ্গিক দস্যু অ্যালগরিদম যা একটি কর্মের প্রত্যাশিত পুরষ্কারকে একটি রৈখিক ফাংশন হিসাবে প্রেক্ষাপটে মডেল করে, এবং এটি অনুসন্ধান এবং শোষণের ভারসাম্য বজায় রাখার জন্য আপার কনফিডেন্স বাউন্ড (UCB) নীতির উপর ভিত্তি করে কর্ম নির্বাচন করে। এটি বর্তমান মডেল (যা একটি রৈখিক মডেল) অনুযায়ী উপলব্ধ সেরা বিকল্পটি ব্যবহার করে, তবে এটি এমন বিকল্পগুলিও অন্বেষণ করে যা মডেলের অনুমানে অনিশ্চয়তা বিবেচনা করে সম্ভাব্যভাবে উচ্চতর পুরষ্কার প্রদান করতে পারে। গাণিতিকভাবে এটি উপস্থাপন করা যেতে পারে:


এই পদ্ধতিটি নিশ্চিত করে যে অ্যালগরিদম এমন কাজগুলি অন্বেষণ করে যার জন্য এটির উচ্চ অনিশ্চয়তা রয়েছে।
একটি অ্যাকশন বাছাই করার পর এবং পুরস্কার পাওয়ার পর, LinUCB নিম্নরূপ পরামিতি আপডেট করে:


এবং এখানে পাইথনে কোড বাস্তবায়ন হল:
import numpy as np class LinUCB: def __init__(self, n_actions, n_features, alpha=1.0): self.n_actions = n_actions self.n_features = n_features self.alpha = alpha # Initialize parameters self.A = np.array( [np.identity(n_features) for _ in range(n_actions)] ) # action covariance matrix self.b = np.array( [np.zeros(n_features) for _ in range(n_actions)] ) # action reward vector self.theta = np.array( [np.zeros(n_features) for _ in range(n_actions)] ) # action parameter vector def predict(self, context): context = np.array(context) # Convert list to ndarray context = context.reshape( -1, 1 ) # reshape the context to a single-column matrix p = np.zeros(self.n_actions) for a in range(self.n_actions): theta = np.dot( np.linalg.inv(self.A[a]), self.b[a] ) # theta_a = A_a^-1 * b_a theta = theta.reshape(-1, 1) # Explicitly reshape theta p[a] = np.dot(theta.T, context) + self.alpha * np.sqrt( np.dot(context.T, np.dot(np.linalg.inv(self.A[a]), context)) ) # p_t(a|x_t) = theta_a^T * x_t + alpha * sqrt(x_t^T * A_a^-1 * x_t) return p def update(self, action, context, reward): self.A[action] += np.outer(context, context) # A_a = A_a + x_t * x_t^T self.b[action] += reward * context # b_a = b_a + r_t * x_txডিসিশন ট্রি অ্যালগরিদম
ডিসিশন ট্রি দস্যু একটি ডিসিশন ট্রি হিসাবে পুরষ্কার ফাংশনকে মডেল করে, যেখানে প্রতিটি লিফ নোড একটি অ্যাকশনের সাথে মিলে যায় এবং মূল থেকে লিফ নোড পর্যন্ত প্রতিটি পথ প্রেক্ষাপটের উপর ভিত্তি করে একটি সিদ্ধান্তের নিয়ম উপস্থাপন করে। এটি পরিসংখ্যানগত তাত্পর্য পরীক্ষার উপর ভিত্তি করে সিদ্ধান্তের গাছে বিভক্ত এবং একীভূত করে একটি পরিসংখ্যান কাঠামোর মাধ্যমে অনুসন্ধান এবং শোষণ করে।


উদ্দেশ্য হল সর্বোত্তম সিদ্ধান্তের গাছটি শেখা যা প্রত্যাশিত ক্রমবর্ধমান পুরস্কারকে সর্বাধিক করে তোলে:


সিদ্ধান্ত গাছ শিক্ষা সাধারণত দুটি ধাপ জড়িত:
- ট্রি গ্রোয়িং : একটি একক নোড (রুট) দিয়ে শুরু করে, একটি বৈশিষ্ট্য এবং একটি থ্রেশহোল্ডের উপর ভিত্তি করে প্রতিটি নোডকে পুনরাবৃত্তিমূলকভাবে বিভক্ত করুন যা প্রত্যাশিত পুরস্কারকে সর্বাধিক করে তোলে। এই প্রক্রিয়াটি চলতে থাকে যতক্ষণ না কিছু থামার শর্ত পূরণ না হয়, যেমন সর্বোচ্চ গভীরতায় পৌঁছানো বা প্রতি পাতায় নমুনার ন্যূনতম সংখ্যা।
- বৃক্ষ ছাঁটাই : পূর্ণ বয়স্ক গাছ থেকে শুরু করে, প্রতিটি নোডের বাচ্চাদের পুনরাবৃত্তভাবে একত্রিত করুন যদি এটি প্রত্যাশিত পুরষ্কার উল্লেখযোগ্যভাবে বৃদ্ধি বা হ্রাস না করে। এই প্রক্রিয়াটি চলতে থাকে যতক্ষণ না আর কোন একত্রীকরণ সঞ্চালিত না হয়।
উন্নতির পরিসংখ্যানগত তাৎপর্য নিশ্চিত করার জন্য বিভক্ত করার মানদণ্ড এবং একত্রিতকরণের মানদণ্ড সাধারণত পরিসংখ্যানগত পরীক্ষার উপর ভিত্তি করে সংজ্ঞায়িত করা হয়।
from sklearn.tree import DecisionTreeRegressor class DecisionTreeBandit: def __init__(self, n_actions, n_features, max_depth=5): self.n_actions = n_actions self.n_features = n_features self.max_depth = max_depth # Initialize the decision tree model for each action self.models = [ DecisionTreeRegressor(max_depth=self.max_depth) for _ in range(n_actions) ] self.data = [[] for _ in range(n_actions)] def predict(self, context): return np.array( [self._predict_for_action(a, context) for a in range(self.n_actions)] ) def _predict_for_action(self, action, context): if not self.data[action]: return 0.0 X, y = zip(*self.data[action]) self.models[action].fit(np.array(X), np.array(y)) context_np = np.array(context).reshape( 1, -1 ) # convert list to NumPy array and reshape return self.models[action].predict(context_np)[0] def update(self, action, context, reward): self.data[action].append((context, reward)) DecisionTreeBandit-এর জন্য, predict পদ্ধতি বর্তমান মডেল প্যারামিটার ব্যবহার করে একটি প্রেক্ষাপটে দেওয়া প্রতিটি কর্মের জন্য প্রত্যাশিত পুরস্কারের পূর্বাভাস দেয়। update পদ্ধতি নির্বাচিত অ্যাকশন থেকে পর্যবেক্ষণ করা পুরষ্কারের উপর ভিত্তি করে মডেল প্যারামিটার আপডেট করে। এই বাস্তবায়ন ডিসিশনট্রিব্যান্ডিটের জন্য scikit-learn ব্যবহার করে।
নিউরাল নেটওয়ার্কের সাথে প্রাসঙ্গিক দস্যু
উচ্চ-মাত্রিক বা নন-লিনিয়ার ক্ষেত্রে পুরষ্কার ফাংশন আনুমানিক করতে গভীর শিক্ষার মডেলগুলি ব্যবহার করা যেতে পারে। নীতিটি সাধারণত একটি নিউরাল নেটওয়ার্ক যা প্রসঙ্গ এবং উপলব্ধ ক্রিয়াগুলিকে ইনপুট হিসাবে গ্রহণ করে এবং প্রতিটি পদক্ষেপ নেওয়ার সম্ভাবনাকে আউটপুট করে৷
একটি জনপ্রিয় গভীর শিক্ষার পদ্ধতি হল একজন অভিনেতা-সমালোচক আর্কিটেকচার ব্যবহার করা, যেখানে একটি নেটওয়ার্ক (অভিনেতা) সিদ্ধান্ত নেয় কোন পদক্ষেপ নেবে এবং অন্য নেটওয়ার্ক (সমালোচক) অভিনেতার গৃহীত পদক্ষেপের মূল্যায়ন করে।
আরও জটিল পরিস্থিতিতে যেখানে প্রসঙ্গ এবং পুরস্কারের মধ্যে সম্পর্ক রৈখিক নয়, আমরা পুরস্কার ফাংশন মডেল করতে একটি নিউরাল নেটওয়ার্ক ব্যবহার করতে পারি। একটি জনপ্রিয় পদ্ধতি হল একটি নীতি গ্রেডিয়েন্ট পদ্ধতি ব্যবহার করা, যেমন REINFORCE বা অভিনেতা-সমালোচক।


নিম্নলিখিত নিউরাল ব্যান্ডিট পুরষ্কার ফাংশন মডেল করার জন্য নিউরাল নেটওয়ার্ক ব্যবহার করে, নিউরাল নেটওয়ার্কের প্যারামিটারের অনিশ্চয়তা বিবেচনা করে। এটি নীতি গ্রেডিয়েন্টের মাধ্যমে অন্বেষণের প্রবর্তন করে যেখানে এটি উচ্চতর পুরষ্কারের দিকে নীতি আপডেট করে। অন্বেষণের এই ফর্মটি আরও নির্দেশিত, যা বড় অ্যাকশন স্পেসগুলিতে উপকারী হতে পারে।
সবচেয়ে সহজ কোড বাস্তবায়ন নিম্নলিখিত:
import torch import torch.nn as nn import torch.optim as optim class NeuralNetwork(nn.Module): def __init__(self, n_features): super(NeuralNetwork, self).__init__() self.layer = nn.Sequential( nn.Linear(n_features, 32), nn.ReLU(), nn.Linear(32, 1) ) def forward(self, x): return self.layer(x) class NeuralBandit: def __init__(self, n_actions, n_features, learning_rate=0.01): self.n_actions = n_actions self.n_features = n_features self.learning_rate = learning_rate # Initialize the neural network model for each action self.models = [NeuralNetwork(n_features) for _ in range(n_actions)] self.optimizers = [ optim.Adam(model.parameters(), lr=self.learning_rate) for model in self.models ] self.criterion = nn.MSELoss() def predict(self, context): context_tensor = torch.tensor(context, dtype=torch.float32) # Convert to tensor with torch.no_grad(): return torch.cat( [model(context_tensor).reshape(1) for model in self.models] ) def update(self, action, context, reward): self.optimizers[action].zero_grad() context_tensor = torch.tensor(context, dtype=torch.float32) # Convert to tensor reward_tensor = torch.tensor(reward, dtype=torch.float32) # Convert to tensor pred_reward = self.models[action](context_tensor) loss = self.criterion(pred_reward, reward_tensor) loss.backward() self.optimizers[action].step() NeuralBandit-এর জন্য predict পদ্ধতি এবং update পদ্ধতি সহ একই ছবি যা বর্তমান মডেল প্যারামিটার ব্যবহার করে একটি প্রেক্ষাপট দেওয়া প্রতিটি ক্রিয়াকলাপের জন্য প্রত্যাশিত পুরষ্কারের ভবিষ্যদ্বাণী করে এবং নির্বাচিত অ্যাকশন থেকে পর্যবেক্ষণ করা পুরষ্কারের উপর ভিত্তি করে মডেল প্যারামিটারগুলি আপডেট করে। এই বাস্তবায়ন নিউরালব্যান্ডিটের জন্য PyTorch ব্যবহার করে।
মডেলের তুলনামূলক কর্মক্ষমতা
প্রতিটি মডেল তার অনন্য সুবিধা এবং অসুবিধা নিয়ে আসে, এবং মডেলের পছন্দ হাতের সমস্যার নির্দিষ্ট প্রয়োজনীয়তার উপর নির্ভর করে। আসুন এই মডেলগুলির মধ্যে কয়েকটির সুনির্দিষ্ট বিষয়ে অনুসন্ধান করি এবং তারপরে তাদের পারফরম্যান্সের তুলনা করি।
লিনইউসিবি
লিনিয়ার আপার কনফিডেন্স বাউন্ড (LinUCB) মডেল একটি প্রেক্ষাপটে দেওয়া প্রতিটি কর্মের জন্য প্রত্যাশিত পুরষ্কার অনুমান করতে লিনিয়ার রিগ্রেশন ব্যবহার করে। এটি এই অনুমানের অনিশ্চয়তার উপর নজর রাখে এবং অনুসন্ধানকে উত্সাহিত করতে এটি ব্যবহার করে।
সুবিধাদি:
এটি সহজ এবং গণনাগতভাবে দক্ষ।
এটা তার অনুশোচনা আবদ্ধ জন্য তাত্ত্বিক গ্যারান্টি প্রদান করে.
অসুবিধা:
- এটি অনুমান করে যে পুরস্কার ফাংশনটি প্রসঙ্গ এবং কর্মের একটি রৈখিক ফাংশন, যা আরও জটিল সমস্যার জন্য নাও থাকতে পারে।
সিদ্ধান্ত গাছ দস্যু
ডিসিশন ট্রি দস্যু মডেল একটি সিদ্ধান্ত গাছ হিসাবে পুরস্কার ফাংশন প্রতিনিধিত্ব করে। প্রতিটি লিফ নোড একটি কর্মের সাথে মিলে যায়, এবং মূল থেকে একটি পাতার নোডের প্রতিটি পথ প্রসঙ্গের উপর ভিত্তি করে একটি সিদ্ধান্তের নিয়ম উপস্থাপন করে।
সুবিধাদি:
এটি ব্যাখ্যাযোগ্য সিদ্ধান্তের নিয়ম প্রদান করে।
এটি জটিল পুরষ্কার ফাংশন পরিচালনা করতে পারে।
অসুবিধা:
- এটি ওভারফিটিং থেকে ভুগতে পারে, বিশেষ করে বড় গাছের জন্য।
- এটি টিউনিং হাইপারপ্যারামিটার যেমন গাছের সর্বোচ্চ গভীরতা প্রয়োজন।
নিউরাল দস্যু
নিউরাল ব্যান্ডিট মডেল একটি প্রেক্ষাপট দেওয়া প্রতিটি কর্মের জন্য প্রত্যাশিত পুরষ্কার অনুমান করতে একটি নিউরাল নেটওয়ার্ক ব্যবহার করে। এটি অন্বেষণকে উত্সাহিত করার জন্য নীতি গ্রেডিয়েন্ট পদ্ধতি ব্যবহার করে।
সুবিধাদি:
এটি জটিল, অ-রৈখিক পুরস্কার ফাংশন পরিচালনা করতে পারে।
এটি নির্দেশিত অন্বেষণ করতে পারে, যা বড় অ্যাকশন স্পেসগুলিতে উপকারী।
অসুবিধা:
- এটি নিউরাল নেটওয়ার্কের আর্কিটেকচার এবং শেখার হারের মতো টিউনিং হাইপারপ্যারামিটারের প্রয়োজন।
- এটি গণনাগতভাবে ব্যয়বহুল হতে পারে, বিশেষ করে বড় নেটওয়ার্ক এবং বড় অ্যাকশন স্পেসের জন্য।
কোড তুলনা এবং সাধারণ চলমান উদাহরণ:
প্রতিটি মডেলের জন্য একটি সিমুলেশন চালানোর সাথে আগে উল্লেখিত এবং সংজ্ঞায়িত এই সমস্ত মডেলের দস্যুদের পারফরম্যান্সের তুলনা করার জন্য এখানে পাইথন কোড রয়েছে।
import matplotlib.pyplot as plt # Define the bandit environment n_actions = 10 n_features = 5 bandit = Bandit(n_actions, n_features) # Define the agents linucb_agent = LinUCB(n_actions, n_features, alpha=0.1) neural_agent = NeuralBandit(n_actions, n_features, learning_rate=0.01) tree_agent = DecisionTreeBandit(n_actions, n_features, max_depth=5) # Run the simulation for each agent n_steps = 1000 agents = [linucb_agent, tree_agent, neural_agent] cumulative_rewards = {agent.__class__.__name__: np.zeros(n_steps) for agent in agents} cumulative_regrets = {agent.__class__.__name__: np.zeros(n_steps) for agent in agents} for agent in agents: print(agent) for t in range(n_steps): x = np.random.randn(n_features) pred_rewards = agent.predict([x]) action = np.argmax(pred_rewards) reward = bandit.get_reward(action, x) optimal_reward = bandit.get_optimal_reward(x) agent.update(action, x, reward) cumulative_rewards[agent.__class__.__name__][t] = ( reward if t == 0 else cumulative_rewards[agent.__class__.__name__][t - 1] + reward ) cumulative_regrets[agent.__class__.__name__][t] = ( optimal_reward - reward if t == 0 else cumulative_regrets[agent.__class__.__name__][t - 1] + optimal_reward - reward ) # Plot the results plt.figure(figsize=(12, 6)) plt.subplot(121) for agent_name, rewards in cumulative_rewards.items(): plt.plot(rewards, label=agent_name) plt.xlabel("Steps") plt.ylabel("Cumulative Rewards") plt.legend() plt.subplot(122) for agent_name, regrets in cumulative_regrets.items(): plt.plot(regrets, label=agent_name) plt.xlabel("Steps") plt.ylabel("Cumulative Regrets") plt.legend() plt.show() 

অ্যাপ্লিকেশন দৃশ্যকল্প
- ব্যক্তিগতকৃত সুপারিশ : এই পরিস্থিতিতে, প্রসঙ্গটি ব্যবহারকারীর তথ্য (যেমন বয়স, লিঙ্গ, অতীতের কেনাকাটা) এবং আইটেম তথ্য (যেমন আইটেম বিভাগ, মূল্য) হতে পারে। অ্যাকশন হল সুপারিশ করার জন্য আইটেম, এবং পুরস্কার হল ব্যবহারকারী আইটেমটিতে ক্লিক করেছেন বা কিনেছেন কিনা। একটি প্রাসঙ্গিক দস্যু অ্যালগরিদম একটি ব্যক্তিগতকৃত সুপারিশ নীতি শিখতে ব্যবহার করা যেতে পারে যা ক্লিক-থ্রু রেট বা আয়কে সর্বাধিক করে।
- ক্লিনিকাল ট্রায়ালস : ক্লিনিকাল ট্রায়ালগুলিতে, প্রসঙ্গটি রোগীর তথ্য হতে পারে (যেমন বয়স, লিঙ্গ, চিকিৎসা ইতিহাস), ক্রিয়াগুলি হল বিভিন্ন চিকিত্সা এবং পুরস্কার হল স্বাস্থ্যের ফলাফল। একটি প্রাসঙ্গিক দস্যু অ্যালগরিদম একটি চিকিত্সা নীতি শিখতে পারে যা রোগীর স্বাস্থ্যের ফলাফলকে সর্বাধিক করে তোলে, চিকিত্সার প্রভাব এবং পার্শ্ব প্রতিক্রিয়াগুলির ভারসাম্য বজায় রাখে।
- অনলাইন বিজ্ঞাপন : অনলাইন বিজ্ঞাপনে, প্রসঙ্গটি ব্যবহারকারীর তথ্য এবং বিজ্ঞাপনের তথ্য হতে পারে, ক্রিয়াগুলি হল বিজ্ঞাপনগুলি প্রদর্শন করা এবং পুরস্কার হল ব্যবহারকারী বিজ্ঞাপনটিতে ক্লিক করেছে কিনা। একটি প্রাসঙ্গিক দস্যু অ্যালগরিদম এমন একটি নীতি শিখতে পারে যা বিজ্ঞাপনের প্রাসঙ্গিকতা এবং ব্যবহারকারীর পছন্দগুলি বিবেচনা করে ক্লিক-থ্রু রেট বা আয়কে সর্বাধিক করে।
এই প্রতিটি অ্যাপ্লিকেশনে, অনুসন্ধান এবং শোষণের ভারসাম্য বজায় রাখা অত্যন্ত গুরুত্বপূর্ণ। শোষণ বর্তমান জ্ঞানের উপর ভিত্তি করে সর্বোত্তম ক্রিয়া বেছে নিচ্ছে, যখন অন্বেষণ আরও জ্ঞান অর্জনের জন্য বিভিন্ন ক্রিয়াকলাপের চেষ্টা করছে। প্রাসঙ্গিক দস্যু অ্যালগরিদমগুলি এই অন্বেষণ-শোষণ বাণিজ্য বন্ধকে আনুষ্ঠানিককরণ এবং সমাধান করার জন্য একটি কাঠামো প্রদান করে।
উপসংহার
প্রাসঙ্গিক দস্যুরা সীমিত প্রতিক্রিয়া সহ পরিবেশে সিদ্ধান্ত নেওয়ার জন্য একটি শক্তিশালী হাতিয়ার। সিদ্ধান্ত গ্রহণের ক্ষেত্রে প্রেক্ষাপটের সুবিধা নেওয়ার ক্ষমতা ঐতিহ্যগত দস্যু অ্যালগরিদমের চেয়ে আরও জটিল এবং সংক্ষিপ্ত সিদ্ধান্ত নেওয়ার অনুমতি দেয়।
যদিও আমরা স্পষ্টভাবে কর্মক্ষমতা তুলনা করিনি, আমরা লক্ষ্য করেছি যে অ্যালগরিদমের পছন্দ সমস্যা বৈশিষ্ট্য দ্বারা প্রভাবিত হওয়া উচিত। সহজ সম্পর্কের জন্য, LinUCB এবং ডিসিশন ট্রি পারদর্শী হতে পারে, অন্যদিকে নিউরাল নেটওয়ার্কগুলি জটিল পরিস্থিতিতে ছাড়িয়ে যেতে পারে৷ প্রতিটি পদ্ধতি অনন্য শক্তির প্রস্তাব দেয়: LinUCB এর গাণিতিক সরলতার জন্য, ডিসিশন ট্রিস তাদের ব্যাখ্যাযোগ্যতার জন্য এবং নিউরাল নেটওয়ার্কগুলি জটিল সম্পর্কগুলি পরিচালনা করার ক্ষমতার জন্য৷ এই উত্তেজনাপূর্ণ ডোমেনে কার্যকর সমস্যা সমাধানের চাবিকাঠি হল সঠিক পদ্ধতি বেছে নেওয়া।
সামগ্রিকভাবে, প্রসঙ্গ-ভিত্তিক দস্যু সমস্যাগুলি শক্তিশালীকরণ শিক্ষার মধ্যে একটি আকর্ষক ক্ষেত্র উপস্থাপন করে, তাদের মোকাবেলা করার জন্য বিভিন্ন অ্যালগরিদম উপলব্ধ এবং আমরা এই শক্তিশালী মডেলগুলির আরও উদ্ভাবনী ব্যবহার দেখার আশা করতে পারি।









