























































Jan 01, 1970
11,297 Lesungen
Kontextuelle mehrarmige Banditenprobleme beim Reinforcement Learning
Zu lang; Lesen
Dieser Artikel befasst sich mit kontextbasierten mehrarmigen Banditenproblemen beim Reinforcement Learning, bei denen die Belohnung vom Kontext abhängt. Wir haben drei verschiedene Algorithmen diskutiert und implementiert: LinUCB, Entscheidungsbäume und neuronale Netze, um diese Probleme zu lösen, und ihre einzigartigen Stärken und Überlegungen hervorgehoben. Obwohl wir ihre Leistung nicht explizit verglichen haben, haben wir betont, wie wichtig es ist, den richtigen Ansatz basierend auf den Merkmalen des vorliegenden Problems zu wählen.Kontextuelle Banditen sind eine Klasse von Reinforcement-Learning-Algorithmen, die in Entscheidungsmodellen verwendet werden, bei denen ein Lernender Aktionen auswählen muss, die zu der größten Belohnung führen. Sie sind nach dem klassischen Problem des „einarmigen Banditen“ des Glücksspiels benannt, bei dem ein Spieler entscheiden muss, an welchen Spielautomaten er spielt, wie oft er jeden Automaten spielt und in welcher Reihenfolge er sie spielt.
Das Besondere an kontextuellen Banditen ist, dass der Entscheidungsprozess vom Kontext abhängt. Der Kontext bezieht sich in diesem Fall auf eine Reihe beobachtbarer Variablen, die das Ergebnis der Aktion beeinflussen können. Dieser Zusatz rückt das Bandit-Problem näher an reale Anwendungen heran, beispielsweise personalisierte Empfehlungen, klinische Studien oder Anzeigenplatzierung, bei denen die Entscheidung von bestimmten Umständen abhängt.
Die Formulierung der kontextuellen Banditenprobleme
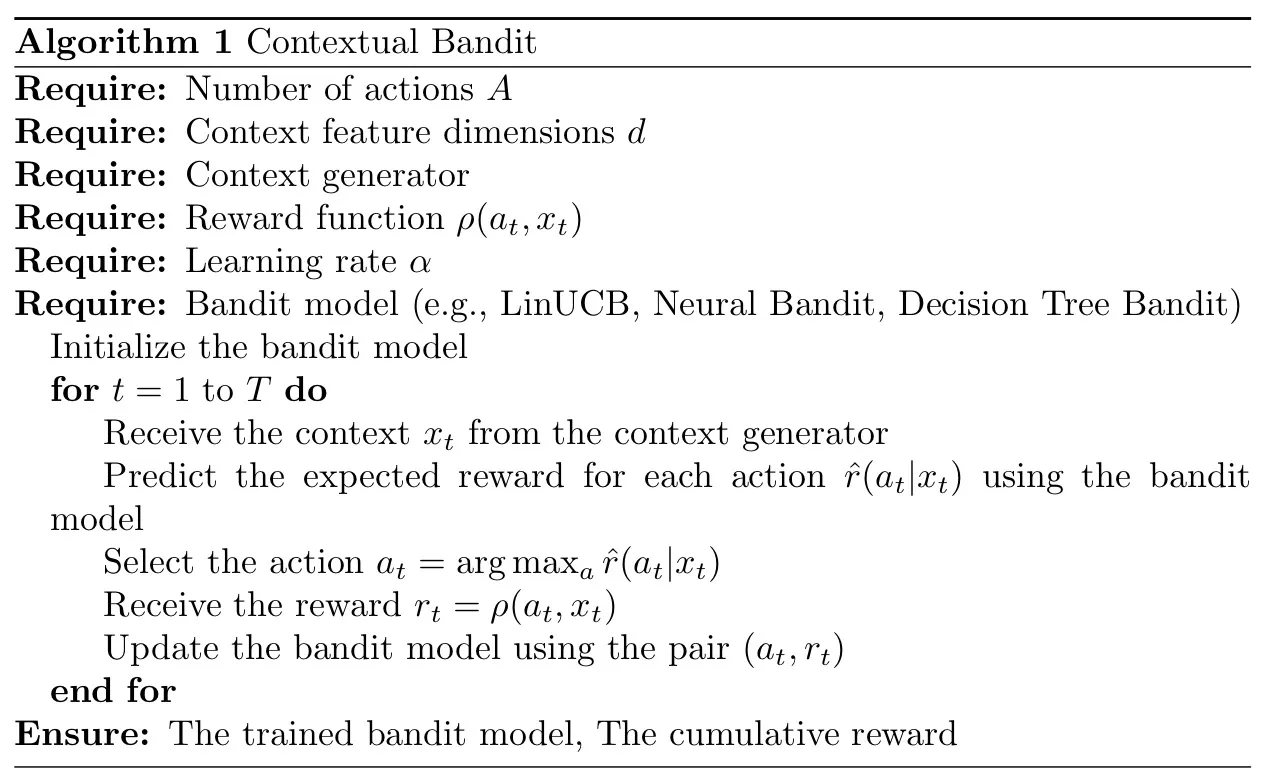
Das kontextuelle Banditenproblem kann mit verschiedenen Algorithmen implementiert werden. Im Folgenden gebe ich einen allgemeinen Überblick über die algorithmische Struktur für kontextbezogene Bandit-Probleme:
Und der folgende Algorithmus hier ist die zugrunde liegende Mathematik des kontextuellen Banditenproblems:
Zusammenfassend lässt sich sagen, dass das Ziel des Algorithmus im Allgemeinen darin besteht, die kumulative Belohnung über einen bestimmten Zeithorizont zu maximieren. Beachten Sie, dass in jeder Runde nur die Belohnung für die gewählte Aktion berücksichtigt wird. Dies wird als partielles Feedback bezeichnet und unterscheidet Bandit-Probleme von überwachtem Lernen.
Der gebräuchlichste Ansatz zur Lösung eines kontextuellen Banditenproblems besteht darin, Erkundung und Ausbeutung in Einklang zu bringen. Ausbeutung bedeutet, das aktuelle Wissen zu nutzen, um die beste Entscheidung zu treffen, während bei der Erkundung weniger sichere Maßnahmen ergriffen werden, um mehr Informationen zu sammeln.
Der Kompromiss zwischen Exploration und Exploitation manifestiert sich in verschiedenen Algorithmen zur Lösung des Contextual Bandit-Problems, wie z. B. LinUCB, Neural Bandit oder Decision Tree Bandit. Alle diese Algorithmen nutzen ihre einzigartigen Strategien, um diesen Kompromiss anzugehen.
Die Codedarstellung dieser Idee für Bandit lautet:
class Bandit: def __init__(self, n_actions, n_features): self.n_actions = n_actions self.n_features = n_features self.theta = np.random.randn(n_actions, n_features) def get_reward(self, action, x): return x @ self.theta[action] + np.random.normal() def get_optimal_reward(self, x): return np.max(x @ self.theta.T) # Usage example # Define the bandit environment n_actions = 10 n_features = 5 bandit = Bandit(n_actions, n_features) # Define the model agent model_agent = model(n_features, *args) # Define the context (features) x = np.random.randn(n_features) # The agent makes a prediction pred_rewards = np.array([model_agent.predict(x) for _ in range(n_actions)]) # The agent chooses an action action = np.argmax(pred_rewards) # The agent gets a reward reward = bandit.get_reward(action, x) # The agent updates its parameters model_agent.update(x, reward)LinUCB-Algorithmus
Der LinUCB-Algorithmus ist ein kontextbezogener Bandit-Algorithmus, der die erwartete Belohnung einer Aktion in einem gegebenen Kontext als lineare Funktion modelliert und Aktionen auf der Grundlage des Upper Confidence Bound (UCB)-Prinzips auswählt, um Exploration und Exploitation auszubalancieren. Es nutzt die beste verfügbare Option gemäß dem aktuellen Modell (bei dem es sich um ein lineares Modell handelt), prüft aber auch Optionen, die angesichts der Unsicherheit in den Schätzungen des Modells potenziell höhere Erträge bieten könnten. Mathematisch lässt es sich wie folgt darstellen:
Dieser Ansatz stellt sicher, dass der Algorithmus Aktionen untersucht, für die er eine hohe Unsicherheit aufweist.
Nach Auswahl einer Aktion und Erhalt einer Belohnung aktualisiert LinUCB die Parameter wie folgt:
Und hier ist die Code-Implementierung in Python:
import numpy as np class LinUCB: def __init__(self, n_actions, n_features, alpha=1.0): self.n_actions = n_actions self.n_features = n_features self.alpha = alpha # Initialize parameters self.A = np.array( [np.identity(n_features) for _ in range(n_actions)] ) # action covariance matrix self.b = np.array( [np.zeros(n_features) for _ in range(n_actions)] ) # action reward vector self.theta = np.array( [np.zeros(n_features) for _ in range(n_actions)] ) # action parameter vector def predict(self, context): context = np.array(context) # Convert list to ndarray context = context.reshape( -1, 1 ) # reshape the context to a single-column matrix p = np.zeros(self.n_actions) for a in range(self.n_actions): theta = np.dot( np.linalg.inv(self.A[a]), self.b[a] ) # theta_a = A_a^-1 * b_a theta = theta.reshape(-1, 1) # Explicitly reshape theta p[a] = np.dot(theta.T, context) + self.alpha * np.sqrt( np.dot(context.T, np.dot(np.linalg.inv(self.A[a]), context)) ) # p_t(a|x_t) = theta_a^T * x_t + alpha * sqrt(x_t^T * A_a^-1 * x_t) return p def update(self, action, context, reward): self.A[action] += np.outer(context, context) # A_a = A_a + x_t * x_t^T self.b[action] += reward * context # b_a = b_a + r_t * x_txEntscheidungsbaum-Algorithmus
Decision Tree Bandit modelliert die Belohnungsfunktion als Entscheidungsbaum, bei dem jeder Blattknoten einer Aktion entspricht und jeder Pfad von der Wurzel zu einem Blattknoten eine Entscheidungsregel basierend auf dem Kontext darstellt. Es führt die Erkundung und Nutzung über ein statistisches Framework durch und nimmt Aufteilungen und Zusammenführungen im Entscheidungsbaum auf der Grundlage statistischer Signifikanztests vor.
Das Ziel besteht darin, den besten Entscheidungsbaum zu lernen, der die erwartete kumulative Belohnung maximiert:
Das Lernen von Entscheidungsbäumen umfasst normalerweise zwei Schritte:
- Baumwachstum : Beginnen Sie mit einem einzelnen Knoten (Wurzel) und teilen Sie jeden Knoten rekursiv auf, basierend auf einer Funktion und einem Schwellenwert, der die erwartete Belohnung maximiert. Dieser Vorgang wird fortgesetzt, bis eine Stoppbedingung erfüllt ist, z. B. das Erreichen einer maximalen Tiefe oder einer minimalen Anzahl von Proben pro Blatt.
- Baumbeschneidung : Beginnen Sie mit dem ausgewachsenen Baum und führen Sie die untergeordneten Knoten jedes Knotens rekursiv zusammen, wenn dadurch die erwartete Belohnung erheblich erhöht oder nicht verringert wird. Dieser Vorgang wird so lange fortgesetzt, bis keine weitere Zusammenführung mehr möglich ist.
Das Aufteilungskriterium und das Zusammenführungskriterium werden normalerweise auf der Grundlage statistischer Tests definiert, um die statistische Signifikanz der Verbesserung sicherzustellen.
from sklearn.tree import DecisionTreeRegressor class DecisionTreeBandit: def __init__(self, n_actions, n_features, max_depth=5): self.n_actions = n_actions self.n_features = n_features self.max_depth = max_depth # Initialize the decision tree model for each action self.models = [ DecisionTreeRegressor(max_depth=self.max_depth) for _ in range(n_actions) ] self.data = [[] for _ in range(n_actions)] def predict(self, context): return np.array( [self._predict_for_action(a, context) for a in range(self.n_actions)] ) def _predict_for_action(self, action, context): if not self.data[action]: return 0.0 X, y = zip(*self.data[action]) self.models[action].fit(np.array(X), np.array(y)) context_np = np.array(context).reshape( 1, -1 ) # convert list to NumPy array and reshape return self.models[action].predict(context_np)[0] def update(self, action, context, reward): self.data[action].append((context, reward)) Für DecisionTreeBandit verwendet die predict die aktuellen Modellparameter, um die erwartete Belohnung für jede Aktion in einem gegebenen Kontext vorherzusagen. Die update aktualisiert die Modellparameter basierend auf der beobachteten Belohnung der ausgewählten Aktion. Diese Implementierung verwendet scikit-learn für DecisionTreeBandit.
Kontextuelle Banditen mit neuronalen Netzen
Deep-Learning-Modelle können verwendet werden, um die Belohnungsfunktion in hochdimensionalen oder nichtlinearen Fällen anzunähern. Bei der Richtlinie handelt es sich in der Regel um ein neuronales Netzwerk, das den Kontext und die verfügbaren Aktionen als Eingabe verwendet und die Wahrscheinlichkeiten für die Durchführung jeder Aktion ausgibt.
Ein beliebter Deep-Learning-Ansatz ist die Verwendung einer Akteur-Kritiker-Architektur, bei der ein Netzwerk (der Akteur) entscheidet, welche Maßnahmen ergriffen werden sollen, und das andere Netzwerk (der Kritiker) die vom Akteur ergriffenen Maßnahmen bewertet.
Für komplexere Szenarien, in denen die Beziehung zwischen Kontext und Belohnung nicht linear ist, können wir ein neuronales Netzwerk verwenden, um die Belohnungsfunktion zu modellieren. Eine beliebte Methode ist die Verwendung einer Policy-Gradienten-Methode wie REINFORCE oder Actor-Critic.
Um das Folgende zusammenzufassen: Neural Bandit verwendet neuronale Netze, um die Belohnungsfunktion zu modellieren, wobei die Unsicherheit in den Parametern des neuronalen Netzes berücksichtigt wird. Darüber hinaus führt es die Erkundung durch Richtliniengradienten ein, bei denen die Richtlinie in Richtung höherer Belohnungen aktualisiert wird. Diese Form der Erkundung ist gezielter, was in großen Aktionsräumen von Vorteil sein kann.
Die einfachste Code-Implementierung ist die folgende:
import torch import torch.nn as nn import torch.optim as optim class NeuralNetwork(nn.Module): def __init__(self, n_features): super(NeuralNetwork, self).__init__() self.layer = nn.Sequential( nn.Linear(n_features, 32), nn.ReLU(), nn.Linear(32, 1) ) def forward(self, x): return self.layer(x) class NeuralBandit: def __init__(self, n_actions, n_features, learning_rate=0.01): self.n_actions = n_actions self.n_features = n_features self.learning_rate = learning_rate # Initialize the neural network model for each action self.models = [NeuralNetwork(n_features) for _ in range(n_actions)] self.optimizers = [ optim.Adam(model.parameters(), lr=self.learning_rate) for model in self.models ] self.criterion = nn.MSELoss() def predict(self, context): context_tensor = torch.tensor(context, dtype=torch.float32) # Convert to tensor with torch.no_grad(): return torch.cat( [model(context_tensor).reshape(1) for model in self.models] ) def update(self, action, context, reward): self.optimizers[action].zero_grad() context_tensor = torch.tensor(context, dtype=torch.float32) # Convert to tensor reward_tensor = torch.tensor(reward, dtype=torch.float32) # Convert to tensor pred_reward = self.models[action](context_tensor) loss = self.criterion(pred_reward, reward_tensor) loss.backward() self.optimizers[action].step() Für NeuralBandit dasselbe Bild mit predict und update , die die aktuellen Modellparameter verwenden, um die erwartete Belohnung für jede Aktion in einem gegebenen Kontext vorherzusagen, und die Modellparameter basierend auf der beobachteten Belohnung der ausgewählten Aktion aktualisiert. Diese Implementierung verwendet PyTorch für NeuralBandit.
Vergleichende Leistung von Modellen
Jedes Modell bringt seine einzigartigen Vor- und Nachteile mit sich und die Wahl des Modells hängt von den spezifischen Anforderungen des jeweiligen Problems ab. Schauen wir uns die Besonderheiten einiger dieser Modelle genauer an und vergleichen dann ihre Leistungen.
LinUCB
Das LinUCB-Modell (Linear Upper Confidence Bound) verwendet eine lineare Regression, um die erwartete Belohnung für jede Aktion in einem gegebenen Kontext zu schätzen. Es verfolgt auch die Unsicherheit dieser Schätzungen und nutzt sie, um die Erkundung zu fördern.
Vorteile:
Es ist einfach und recheneffizient.
Es bietet theoretische Garantien für seine Reuegrenze.
Nachteile:
- Es wird davon ausgegangen, dass die Belohnungsfunktion eine lineare Funktion des Kontexts und der Aktion ist, was für komplexere Probleme möglicherweise nicht gilt.
Entscheidungsbaum-Bandit
Das Decision Tree Bandit-Modell stellt die Belohnungsfunktion als Entscheidungsbaum dar. Jeder Blattknoten entspricht einer Aktion, und jeder Pfad von der Wurzel zu einem Blattknoten stellt eine Entscheidungsregel basierend auf dem Kontext dar.
Vorteile:
Es liefert interpretierbare Entscheidungsregeln.
Es kann komplexe Belohnungsfunktionen verarbeiten.
Nachteile:
- Insbesondere bei großen Bäumen kann es zu einer Überanpassung kommen.
- Es erfordert die Optimierung von Hyperparametern wie der maximalen Tiefe des Baums.
Neuronaler Bandit
Das Neural Bandit-Modell verwendet ein neuronales Netzwerk, um die erwartete Belohnung für jede Aktion in einem bestimmten Kontext abzuschätzen. Es verwendet Richtliniengradientenmethoden, um die Erkundung zu fördern.
Vorteile:
Es kann komplexe, nichtlineare Belohnungsfunktionen verarbeiten.
Es kann eine gezielte Erkundung durchführen, was in großen Aktionsräumen von Vorteil ist.
Nachteile:
- Es erfordert die Abstimmung von Hyperparametern wie der Architektur und der Lernrate des neuronalen Netzwerks.
- Dies kann rechenintensiv sein, insbesondere bei großen Netzwerken und großen Aktionsräumen.
Codevergleich und allgemeines Laufbeispiel:
Hier ist Python-Code, um die Leistungen aller dieser zuvor erwähnten und definierten Modellbanditen zu vergleichen, indem für jedes Modell eine Simulation ausgeführt wird.
import matplotlib.pyplot as plt # Define the bandit environment n_actions = 10 n_features = 5 bandit = Bandit(n_actions, n_features) # Define the agents linucb_agent = LinUCB(n_actions, n_features, alpha=0.1) neural_agent = NeuralBandit(n_actions, n_features, learning_rate=0.01) tree_agent = DecisionTreeBandit(n_actions, n_features, max_depth=5) # Run the simulation for each agent n_steps = 1000 agents = [linucb_agent, tree_agent, neural_agent] cumulative_rewards = {agent.__class__.__name__: np.zeros(n_steps) for agent in agents} cumulative_regrets = {agent.__class__.__name__: np.zeros(n_steps) for agent in agents} for agent in agents: print(agent) for t in range(n_steps): x = np.random.randn(n_features) pred_rewards = agent.predict([x]) action = np.argmax(pred_rewards) reward = bandit.get_reward(action, x) optimal_reward = bandit.get_optimal_reward(x) agent.update(action, x, reward) cumulative_rewards[agent.__class__.__name__][t] = ( reward if t == 0 else cumulative_rewards[agent.__class__.__name__][t - 1] + reward ) cumulative_regrets[agent.__class__.__name__][t] = ( optimal_reward - reward if t == 0 else cumulative_regrets[agent.__class__.__name__][t - 1] + optimal_reward - reward ) # Plot the results plt.figure(figsize=(12, 6)) plt.subplot(121) for agent_name, rewards in cumulative_rewards.items(): plt.plot(rewards, label=agent_name) plt.xlabel("Steps") plt.ylabel("Cumulative Rewards") plt.legend() plt.subplot(122) for agent_name, regrets in cumulative_regrets.items(): plt.plot(regrets, label=agent_name) plt.xlabel("Steps") plt.ylabel("Cumulative Regrets") plt.legend() plt.show() Anwendungsszenarien
- Personalisierte Empfehlung : In diesem Szenario könnte der Kontext Benutzerinformationen (wie Alter, Geschlecht, frühere Käufe) und Artikelinformationen (wie Artikelkategorie, Preis) sein. Bei den Aktionen handelt es sich um die zu empfehlenden Artikel, und die Belohnung besteht darin, ob der Benutzer auf den Artikel geklickt oder ihn gekauft hat. Mithilfe eines kontextbezogenen Bandit-Algorithmus kann eine personalisierte Empfehlungsrichtlinie erlernt werden, die die Klickrate oder den Umsatz maximiert.
- Klinische Studien : Bei klinischen Studien könnte der Kontext Patienteninformationen (z. B. Alter, Geschlecht, Krankengeschichte) sein, die Maßnahmen sind die verschiedenen Behandlungen und die Belohnung ist das Gesundheitsergebnis. Ein kontextueller Bandit-Algorithmus kann eine Behandlungsrichtlinie erlernen, die das Gesundheitsergebnis des Patienten maximiert und dabei den Behandlungseffekt und die Nebenwirkungen in Einklang bringt.
- Online-Werbung : Bei der Online-Werbung könnte der Kontext Benutzerinformationen und Anzeigeninformationen sein, die Aktionen sind die anzuzeigenden Anzeigen und die Belohnung besteht darin, ob der Benutzer auf die Anzeige geklickt hat. Ein kontextbezogener Bandit-Algorithmus kann eine Richtlinie erlernen, die unter Berücksichtigung der Anzeigenrelevanz und der Benutzerpräferenzen die Klickrate oder den Umsatz maximiert.
Bei jeder dieser Anwendungen ist es von entscheidender Bedeutung, ein Gleichgewicht zwischen Erkundung und Nutzung herzustellen. Bei der Ausbeutung wird die beste Aktion auf der Grundlage des aktuellen Wissens ausgewählt, während bei der Erkundung verschiedene Aktionen ausprobiert werden, um mehr Wissen zu gewinnen. Kontextuelle Bandit-Algorithmen bieten einen Rahmen zur Formalisierung und Lösung dieses Kompromisses zwischen Exploration und Ausbeutung.
Abschluss
Kontextuelle Banditen sind ein leistungsstarkes Werkzeug für die Entscheidungsfindung in Umgebungen mit begrenztem Feedback. Die Fähigkeit, den Kontext bei der Entscheidungsfindung zu nutzen, ermöglicht komplexere und differenziertere Entscheidungen als herkömmliche Bandit-Algorithmen.
Obwohl wir die Leistung nicht explizit verglichen haben, stellten wir fest, dass die Wahl des Algorithmus von den Problemmerkmalen beeinflusst werden sollte. Bei einfacheren Beziehungen könnten sich LinUCB und Entscheidungsbäume auszeichnen, während neuronale Netze in komplexen Szenarien überlegen sein könnten. Jede Methode bot einzigartige Stärken: LinUCB wegen seiner mathematischen Einfachheit, Entscheidungsbäume wegen ihrer Interpretierbarkeit und neuronale Netze wegen ihrer Fähigkeit, komplexe Beziehungen zu handhaben. Die Wahl des richtigen Ansatzes ist der Schlüssel zur effektiven Problemlösung in diesem spannenden Bereich.
Insgesamt stellen kontextbasierte Bandit-Probleme einen spannenden Bereich innerhalb des verstärkenden Lernens dar, für dessen Bewältigung verschiedene Algorithmen zur Verfügung stehen, und wir können mit noch innovativeren Anwendungen dieser leistungsstarken Modelle rechnen.
L O A D I N G
. . . comments & more!
. . . comments & more!



