

























Les bandits contextuels sont une classe d'algorithmes d'apprentissage par renforcement utilisés dans les modèles de prise de décision où un apprenant doit choisir les actions qui génèrent le plus de récompenses. Ils portent le nom du problème classique du "bandit manchot" du jeu, où un joueur doit décider quelles machines à sous jouer, combien de fois jouer à chaque machine et dans quel ordre les jouer.


Ce qui distingue les bandits contextuels, c'est que le processus de prise de décision est informé par le contexte. Le contexte, dans ce cas, fait référence à un ensemble de variables observables qui peuvent avoir un impact sur le résultat de l'action. Cet ajout rapproche le problème des bandits des applications du monde réel, telles que les recommandations personnalisées, les essais cliniques ou le placement d'annonces, où la décision dépend de circonstances spécifiques.
La formulation des problèmes de bandits contextuels
Le problème de bandit contextuel peut être implémenté à l'aide de divers algorithmes. Ci-dessous, je donne un aperçu général de haut niveau de la structure algorithmique des problèmes de bandits contextuels :

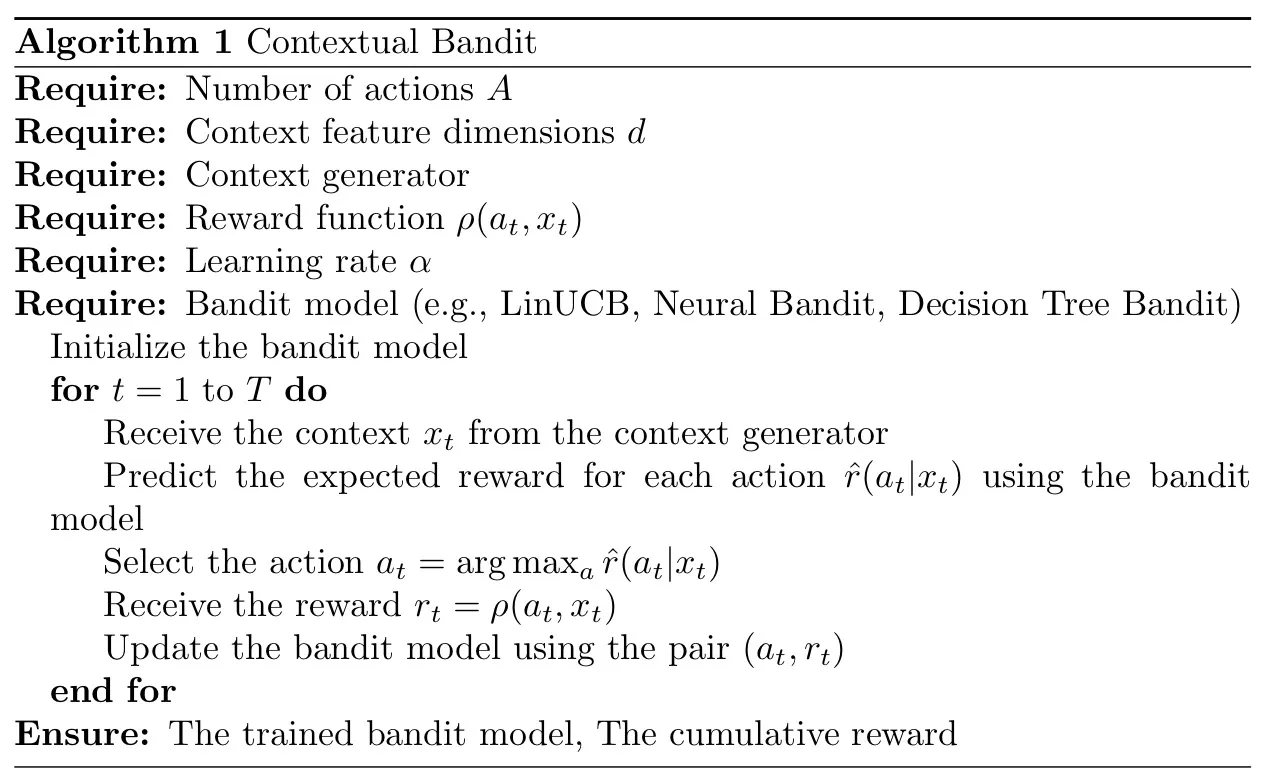
Et l'algorithme suivant, voici les mathématiques sous-jacentes du problème de bandit contextuel :


Pour résumer tout ce qui précède, d'une manière générale, l'objectif de l'algorithme est de maximiser la récompense cumulée sur un certain horizon temporel. Notez qu'à chaque tour, seule la récompense de l'action choisie est observée. C'est ce qu'on appelle la rétroaction partielle, qui différencie les problèmes de bandit de l'apprentissage supervisé.
L'approche la plus courante pour résoudre un problème de bandit contextuel consiste à équilibrer l'exploration et l'exploitation. L'exploitation consiste à utiliser les connaissances actuelles pour prendre la meilleure décision, tandis que l'exploration consiste à prendre des mesures moins certaines pour recueillir plus d'informations.
Le compromis entre exploration et exploitation se manifeste dans divers algorithmes conçus pour résoudre le problème Contextual Bandit, tels que LinUCB, Neural Bandit ou Decision Tree Bandit. Tous ces algorithmes utilisent leurs stratégies uniques pour résoudre ce compromis.
La représentation du code de cette idée pour Bandit est :
class Bandit: def __init__(self, n_actions, n_features): self.n_actions = n_actions self.n_features = n_features self.theta = np.random.randn(n_actions, n_features) def get_reward(self, action, x): return x @ self.theta[action] + np.random.normal() def get_optimal_reward(self, x): return np.max(x @ self.theta.T) # Usage example # Define the bandit environment n_actions = 10 n_features = 5 bandit = Bandit(n_actions, n_features) # Define the model agent model_agent = model(n_features, *args) # Define the context (features) x = np.random.randn(n_features) # The agent makes a prediction pred_rewards = np.array([model_agent.predict(x) for _ in range(n_actions)]) # The agent chooses an action action = np.argmax(pred_rewards) # The agent gets a reward reward = bandit.get_reward(action, x) # The agent updates its parameters model_agent.update(x, reward)Algorithme LinUCB
L'algorithme LinUCB est un algorithme de bandit contextuel qui modélise la récompense attendue d'une action dans un contexte donné comme une fonction linéaire, et il sélectionne des actions basées sur le principe de la limite de confiance supérieure (UCB) pour équilibrer l'exploration et l'exploitation. Il exploite la meilleure option disponible selon le modèle actuel (qui est un modèle linéaire), mais il explore également les options qui pourraient potentiellement offrir des récompenses plus élevées, compte tenu de l'incertitude des estimations du modèle. Mathématiquement, il peut être présenté comme suit :


Cette approche garantit que l'algorithme explore les actions pour lesquelles il a une forte incertitude.
Après avoir sélectionné une action et reçu une récompense, LinUCB met à jour les paramètres comme suit :


Et voici l'implémentation du code en Python :
import numpy as np class LinUCB: def __init__(self, n_actions, n_features, alpha=1.0): self.n_actions = n_actions self.n_features = n_features self.alpha = alpha # Initialize parameters self.A = np.array( [np.identity(n_features) for _ in range(n_actions)] ) # action covariance matrix self.b = np.array( [np.zeros(n_features) for _ in range(n_actions)] ) # action reward vector self.theta = np.array( [np.zeros(n_features) for _ in range(n_actions)] ) # action parameter vector def predict(self, context): context = np.array(context) # Convert list to ndarray context = context.reshape( -1, 1 ) # reshape the context to a single-column matrix p = np.zeros(self.n_actions) for a in range(self.n_actions): theta = np.dot( np.linalg.inv(self.A[a]), self.b[a] ) # theta_a = A_a^-1 * b_a theta = theta.reshape(-1, 1) # Explicitly reshape theta p[a] = np.dot(theta.T, context) + self.alpha * np.sqrt( np.dot(context.T, np.dot(np.linalg.inv(self.A[a]), context)) ) # p_t(a|x_t) = theta_a^T * x_t + alpha * sqrt(x_t^T * A_a^-1 * x_t) return p def update(self, action, context, reward): self.A[action] += np.outer(context, context) # A_a = A_a + x_t * x_t^T self.b[action] += reward * context # b_a = b_a + r_t * x_txAlgorithme d'arbre de décision
Decision Tree Bandit modélise la fonction de récompense sous la forme d'un arbre de décision, où chaque nœud feuille correspond à une action et chaque chemin de la racine à un nœud feuille représente une règle de décision basée sur le contexte. Il effectue l'exploration et l'exploitation à travers un cadre statistique, en effectuant des scissions et des fusions dans l'arbre de décision sur la base de tests de signification statistique.


L'objectif est d'apprendre le meilleur arbre de décision qui maximise la récompense cumulée attendue :


L'apprentissage de l'arbre de décision comprend généralement deux étapes :
- Tree Growing : en commençant par un seul nœud (racine), divisez de manière récursive chaque nœud en fonction d'une caractéristique et d'un seuil qui maximise la récompense attendue. Ce processus se poursuit jusqu'à ce qu'une condition d'arrêt soit remplie, comme atteindre une profondeur maximale ou un nombre minimal d'échantillons par feuille.
- Élagage de l'arbre : à partir de l'arbre entièrement développé, fusionnez récursivement les enfants de chaque nœud s'il augmente ou ne diminue pas la récompense attendue de manière significative. Ce processus se poursuit jusqu'à ce qu'aucune autre fusion ne puisse être effectuée.
Le critère de séparation et le critère de fusion sont généralement définis sur la base de tests statistiques pour garantir la signification statistique de l'amélioration.
from sklearn.tree import DecisionTreeRegressor class DecisionTreeBandit: def __init__(self, n_actions, n_features, max_depth=5): self.n_actions = n_actions self.n_features = n_features self.max_depth = max_depth # Initialize the decision tree model for each action self.models = [ DecisionTreeRegressor(max_depth=self.max_depth) for _ in range(n_actions) ] self.data = [[] for _ in range(n_actions)] def predict(self, context): return np.array( [self._predict_for_action(a, context) for a in range(self.n_actions)] ) def _predict_for_action(self, action, context): if not self.data[action]: return 0.0 X, y = zip(*self.data[action]) self.models[action].fit(np.array(X), np.array(y)) context_np = np.array(context).reshape( 1, -1 ) # convert list to NumPy array and reshape return self.models[action].predict(context_np)[0] def update(self, action, context, reward): self.data[action].append((context, reward)) Pour DecisionTreeBandit, la méthode predict utilise les paramètres de modèle actuels pour prédire la récompense attendue pour chaque action dans un contexte donné. Le procédé update met à jour les paramètres du modèle sur la base de la récompense observée à partir de l'action sélectionnée. Cette implémentation utilise scikit-learn pour DecisionTreeBandit.
Bandits contextuels avec réseaux de neurones
Les modèles d'apprentissage en profondeur peuvent être utilisés pour approximer la fonction de récompense dans des cas de grande dimension ou non linéaires. La politique est généralement un réseau de neurones qui prend le contexte et les actions disponibles en entrée et produit les probabilités d'entreprendre chaque action.
Une approche populaire d'apprentissage en profondeur consiste à utiliser une architecture acteur-critique, où un réseau (l'acteur) décide de l'action à entreprendre, et l'autre réseau (le critique) évalue l'action entreprise par l'acteur.
Pour des scénarios plus complexes où la relation entre le contexte et la récompense n'est pas linéaire, nous pouvons utiliser un réseau de neurones pour modéliser la fonction de récompense. Une méthode populaire consiste à utiliser une méthode de gradient de politique, telle que REINFORCE ou critique d'acteur.


Pour résumer ce qui suit, Neural Bandit utilise des réseaux de neurones pour modéliser la fonction de récompense, en tenant compte de l'incertitude des paramètres du réseau de neurones. Il introduit en outre l'exploration à travers des gradients de politique où il met à jour la politique dans le sens de récompenses plus élevées. Cette forme d'exploration est plus dirigée, ce qui peut être bénéfique dans les grands espaces d'action.
L'implémentation de code la plus simple est la suivante :
import torch import torch.nn as nn import torch.optim as optim class NeuralNetwork(nn.Module): def __init__(self, n_features): super(NeuralNetwork, self).__init__() self.layer = nn.Sequential( nn.Linear(n_features, 32), nn.ReLU(), nn.Linear(32, 1) ) def forward(self, x): return self.layer(x) class NeuralBandit: def __init__(self, n_actions, n_features, learning_rate=0.01): self.n_actions = n_actions self.n_features = n_features self.learning_rate = learning_rate # Initialize the neural network model for each action self.models = [NeuralNetwork(n_features) for _ in range(n_actions)] self.optimizers = [ optim.Adam(model.parameters(), lr=self.learning_rate) for model in self.models ] self.criterion = nn.MSELoss() def predict(self, context): context_tensor = torch.tensor(context, dtype=torch.float32) # Convert to tensor with torch.no_grad(): return torch.cat( [model(context_tensor).reshape(1) for model in self.models] ) def update(self, action, context, reward): self.optimizers[action].zero_grad() context_tensor = torch.tensor(context, dtype=torch.float32) # Convert to tensor reward_tensor = torch.tensor(reward, dtype=torch.float32) # Convert to tensor pred_reward = self.models[action](context_tensor) loss = self.criterion(pred_reward, reward_tensor) loss.backward() self.optimizers[action].step() Pour NeuralBandit, la même image avec la méthode predict et la méthode update qui utilisent les paramètres du modèle actuel pour prédire la récompense attendue pour chaque action dans un contexte et met à jour les paramètres du modèle en fonction de la récompense observée à partir de l'action sélectionnée. Cette implémentation utilise PyTorch pour NeuralBandit.
Performances comparatives des modèles
Chaque modèle est livré avec ses avantages et ses inconvénients uniques, et le choix du modèle dépend des exigences spécifiques du problème à résoudre. Plongeons dans les spécificités de certains de ces modèles puis comparons leurs performances.
LinUCB
Le modèle LinUCB (Linear Upper Confidence Bound) utilise une régression linéaire pour estimer la récompense attendue pour chaque action dans un contexte donné. Il garde également une trace de l'incertitude de ces estimations et l'utilise pour encourager l'exploration.
Avantages :
Il est simple et efficace en termes de calcul.
Il apporte des garanties théoriques à son regret lié.
Désavantages:
- Il suppose que la fonction de récompense est une fonction linéaire du contexte et de l'action, ce qui peut ne pas tenir pour des problèmes plus complexes.
Bandit de l'arbre de décision
Le modèle Decision Tree Bandit représente la fonction de récompense sous la forme d'un arbre de décision. Chaque nœud feuille correspond à une action, et chaque chemin de la racine à un nœud feuille représente une règle de décision basée sur le contexte.
Avantages :
Il fournit des règles de décision interprétables.
Il peut gérer des fonctions de récompense complexes.
Désavantages:
- Il peut souffrir de surajustement, en particulier pour les grands arbres.
- Cela nécessite de régler des hyperparamètres tels que la profondeur maximale de l'arbre.
Bandit neuronal
Le modèle Neural Bandit utilise un réseau de neurones pour estimer la récompense attendue pour chaque action dans un contexte donné. Il utilise des méthodes de gradient politique pour encourager l'exploration.
Avantages :
Il peut gérer des fonctions de récompense complexes et non linéaires.
Il peut effectuer une exploration dirigée, ce qui est bénéfique dans les grands espaces d'action.
Désavantages:
- Cela nécessite de régler des hyperparamètres tels que l'architecture et le taux d'apprentissage du réseau de neurones.
- Cela peut être coûteux en calcul, en particulier pour les grands réseaux et les grands espaces d'action.
Comparaison de code et exemple d'exécution général :
Voici du code Python pour comparer les performances de tous les bandits de ces modèles mentionnés et définis précédemment avec l'exécution d'une simulation pour chaque modèle.
import matplotlib.pyplot as plt # Define the bandit environment n_actions = 10 n_features = 5 bandit = Bandit(n_actions, n_features) # Define the agents linucb_agent = LinUCB(n_actions, n_features, alpha=0.1) neural_agent = NeuralBandit(n_actions, n_features, learning_rate=0.01) tree_agent = DecisionTreeBandit(n_actions, n_features, max_depth=5) # Run the simulation for each agent n_steps = 1000 agents = [linucb_agent, tree_agent, neural_agent] cumulative_rewards = {agent.__class__.__name__: np.zeros(n_steps) for agent in agents} cumulative_regrets = {agent.__class__.__name__: np.zeros(n_steps) for agent in agents} for agent in agents: print(agent) for t in range(n_steps): x = np.random.randn(n_features) pred_rewards = agent.predict([x]) action = np.argmax(pred_rewards) reward = bandit.get_reward(action, x) optimal_reward = bandit.get_optimal_reward(x) agent.update(action, x, reward) cumulative_rewards[agent.__class__.__name__][t] = ( reward if t == 0 else cumulative_rewards[agent.__class__.__name__][t - 1] + reward ) cumulative_regrets[agent.__class__.__name__][t] = ( optimal_reward - reward if t == 0 else cumulative_regrets[agent.__class__.__name__][t - 1] + optimal_reward - reward ) # Plot the results plt.figure(figsize=(12, 6)) plt.subplot(121) for agent_name, rewards in cumulative_rewards.items(): plt.plot(rewards, label=agent_name) plt.xlabel("Steps") plt.ylabel("Cumulative Rewards") plt.legend() plt.subplot(122) for agent_name, regrets in cumulative_regrets.items(): plt.plot(regrets, label=agent_name) plt.xlabel("Steps") plt.ylabel("Cumulative Regrets") plt.legend() plt.show() 

Scénarios d'application
- Recommandation personnalisée : dans ce scénario, le contexte peut être des informations sur l'utilisateur (comme l'âge, le sexe, les achats antérieurs) et des informations sur l'article (comme la catégorie d'article, le prix). Les actions sont les éléments à recommander, et la récompense est de savoir si l'utilisateur a cliqué ou acheté l'élément. Un algorithme de bandit contextuel peut être utilisé pour apprendre une politique de recommandation personnalisée qui maximise le taux de clics ou les revenus.
- Essais cliniques : Dans les essais cliniques, le contexte peut être l'information du patient (comme l'âge, le sexe, les antécédents médicaux), les actions sont les différents traitements et la récompense est le résultat pour la santé. Un algorithme de bandit contextuel peut apprendre une politique de traitement qui maximise les résultats de santé du patient, en équilibrant l'effet du traitement et les effets secondaires.
- Publicité en ligne : dans la publicité en ligne, le contexte peut être les informations sur l'utilisateur et les informations sur l'annonce, les actions sont les annonces à afficher et la récompense est de savoir si l'utilisateur a cliqué sur l'annonce. Un algorithme de bandit contextuel peut apprendre une politique qui maximise le taux de clics ou les revenus, en tenant compte de la pertinence de l'annonce et des préférences de l'utilisateur.
Dans chacune de ces applications, il est crucial d'équilibrer l'exploration et l'exploitation. L'exploitation consiste à choisir la meilleure action en fonction des connaissances actuelles, tandis que l'exploration consiste à essayer différentes actions pour acquérir plus de connaissances. Les algorithmes contextuels de bandit fournissent un cadre pour formaliser et résoudre ce compromis exploration-exploitation.
Conclusion
Les bandits contextuels sont un outil puissant pour la prise de décision dans des environnements avec peu de rétroaction. La capacité à tirer parti du contexte dans la prise de décision permet des décisions plus complexes et nuancées que les algorithmes de bandit traditionnels.
Bien que nous n'ayons pas comparé explicitement les performances, nous avons noté que le choix de l'algorithme devrait être influencé par les caractéristiques du problème. Pour des relations plus simples, LinUCB et les arbres de décision pourraient exceller, tandis que les réseaux de neurones peuvent surpasser les performances dans des scénarios complexes.Chaque méthode offrait des atouts uniques : LinUCB pour sa simplicité mathématique, les arbres de décision pour leur interprétabilité et les réseaux de neurones pour leur capacité à gérer des relations complexes. Choisir la bonne approche est la clé d'une résolution efficace des problèmes dans ce domaine passionnant.
Dans l'ensemble, les problèmes de bandit basés sur le contexte présentent un domaine engageant dans l'apprentissage par renforcement, avec divers algorithmes disponibles pour les résoudre et nous pouvons nous attendre à voir des utilisations encore plus innovantes de ces modèles puissants.








