
























Hola gente hermosa! Espero que el 2025 los esté tratando bien, aunque a mí me ha ido bastante mal hasta ahora.
Bienvenido al blog de Doodles y Programación y hoy vamos a construir: Un modelo de análisis de sentimientos usando TensorFlow + Python.


En este tutorial, también aprenderemos los conceptos básicos del aprendizaje automático con Python y, como se mencionó anteriormente, podremos crear nuestro propio modelo de aprendizaje automático con Tensorflow, una biblioteca de Python. Este modelo podrá detectar el tono/emoción del texto de entrada , estudiando y aprendiendo del conjunto de datos de muestra proporcionado.
Prerrequisitos
Todo lo que necesitamos es algún conocimiento de Python (lo más básico, por supuesto) y también asegurarnos de tener Python instalado en nuestro sistema (se recomienda Python 3.9+).
Sin embargo, si te resulta difícil seguir este tutorial, ¡no te preocupes! Envíame un correo electrónico o un mensaje. Te responderé lo antes posible.
Por si no lo sabes, ¿qué es el aprendizaje automático?
En términos simples, el aprendizaje automático (ML) hace que la computadora aprenda y haga predicciones mediante el estudio de datos y estadísticas. Al estudiar los datos proporcionados, la computadora puede identificar y extraer patrones y luego hacer predicciones basadas en ellos. La identificación de correos electrónicos no deseados, el reconocimiento de voz y la predicción del tráfico son algunos casos de uso de la vida real del aprendizaje automático.
Para dar un mejor ejemplo, imaginemos que queremos enseñarle a una computadora a reconocer gatos en fotografías. Le mostraríamos muchas fotografías de gatos y le diríamos: "Oye, computadora, ¡estos son gatos!". La computadora observa las fotografías y comienza a notar patrones, como orejas puntiagudas, bigotes y pelo. Después de ver suficientes ejemplos, puede reconocer un gato en una nueva fotografía que no haya visto antes.


Uno de esos sistemas que utilizamos a diario son los filtros antispam. La siguiente imagen muestra cómo se hace.


¿Por qué utilizar Python?
Si bien el lenguaje de programación Python no está diseñado específicamente para el aprendizaje automático o la ciencia de datos, se lo considera un excelente lenguaje de programación para el aprendizaje automático debido a su adaptabilidad. Con cientos de bibliotecas disponibles para descarga gratuita, cualquiera puede crear fácilmente modelos de aprendizaje automático utilizando una biblioteca preconstruida sin la necesidad de programar el procedimiento completo desde cero.
TensorFlow es una de esas bibliotecas creadas por Google para el aprendizaje automático y la inteligencia artificial. Los científicos de datos, los ingenieros de datos y otros desarrolladores suelen utilizar TensorFlow para crear modelos de aprendizaje automático fácilmente, ya que consta de una variedad de algoritmos de aprendizaje automático e inteligencia artificial.
Visita el sitio web oficial de TensorFlow
Instalación
Para instalar Tensorflow, ejecute el siguiente comando en su terminal:
pip install tensorflowY para instalar Pandas y Numpy,
pip install pandas numpyDescargue el archivo CSV de muestra de este repositorio: Repositorio de Github: modelo TensorFlow ML
Comprender los datos
Regla n.° 1 del análisis de datos y de cualquier cosa que se base en datos: primero, comprenda los datos que tiene.
En este caso, el conjunto de datos tiene dos columnas: Texto y Sentimiento. Mientras que la columna “texto” tiene una variedad de afirmaciones sobre películas, libros, etc., la columna “sentimiento” muestra si el texto es positivo, neutral o negativo, utilizando los números 1, 2 y 0, respectivamente.
Preparación de datos
La siguiente regla general es limpiar los duplicados y eliminar los valores nulos de los datos de muestra. Pero en este caso, dado que el conjunto de datos dado es bastante pequeño y no contiene duplicados ni valores nulos, podemos omitir el proceso de limpieza de datos.


Para comenzar a construir el modelo, debemos reunir y preparar el conjunto de datos para entrenar el modelo de análisis de sentimientos. Pandas, una biblioteca popular para el análisis y la manipulación de datos, se puede utilizar para esta tarea.
import pandas as pd # Load data from CSV data = pd.read_csv('sentiment.csv') # Change the path of downloaded CSV File accordingly # Text data and labels texts = data['text'].tolist() labels = data['sentiment'].values El código anterior convierte el archivo CSV en un marco de datos mediante la función pandas.read_csv() . A continuación, asigna los valores de la columna “sentimiento” a una lista de Python mediante la función tolist() y crea una matriz Numpy con los valores.
¿Por qué utilizar una matriz Numpy?
Como ya sabrás, Numpy está diseñado básicamente para la manipulación de datos. Las matrices de Numpy manejan de manera eficiente las etiquetas numéricas para tareas de aprendizaje automático, lo que ofrece flexibilidad en la organización de datos. Por eso, en este caso, usamos Numpy.
Procesando texto
Después de preparar los datos de muestra, necesitamos reprocesar el texto, lo que implica la tokenización.
La tokenización es el proceso de dividir cada muestra de texto en palabras individuales o tokens, de modo que podamos convertir los datos de texto sin procesar en un formato que pueda ser procesado por el modelo , lo que le permitirá comprender y aprender de las palabras individuales en las muestras de texto.
Consulte la siguiente imagen para saber cómo funciona la tokenización.
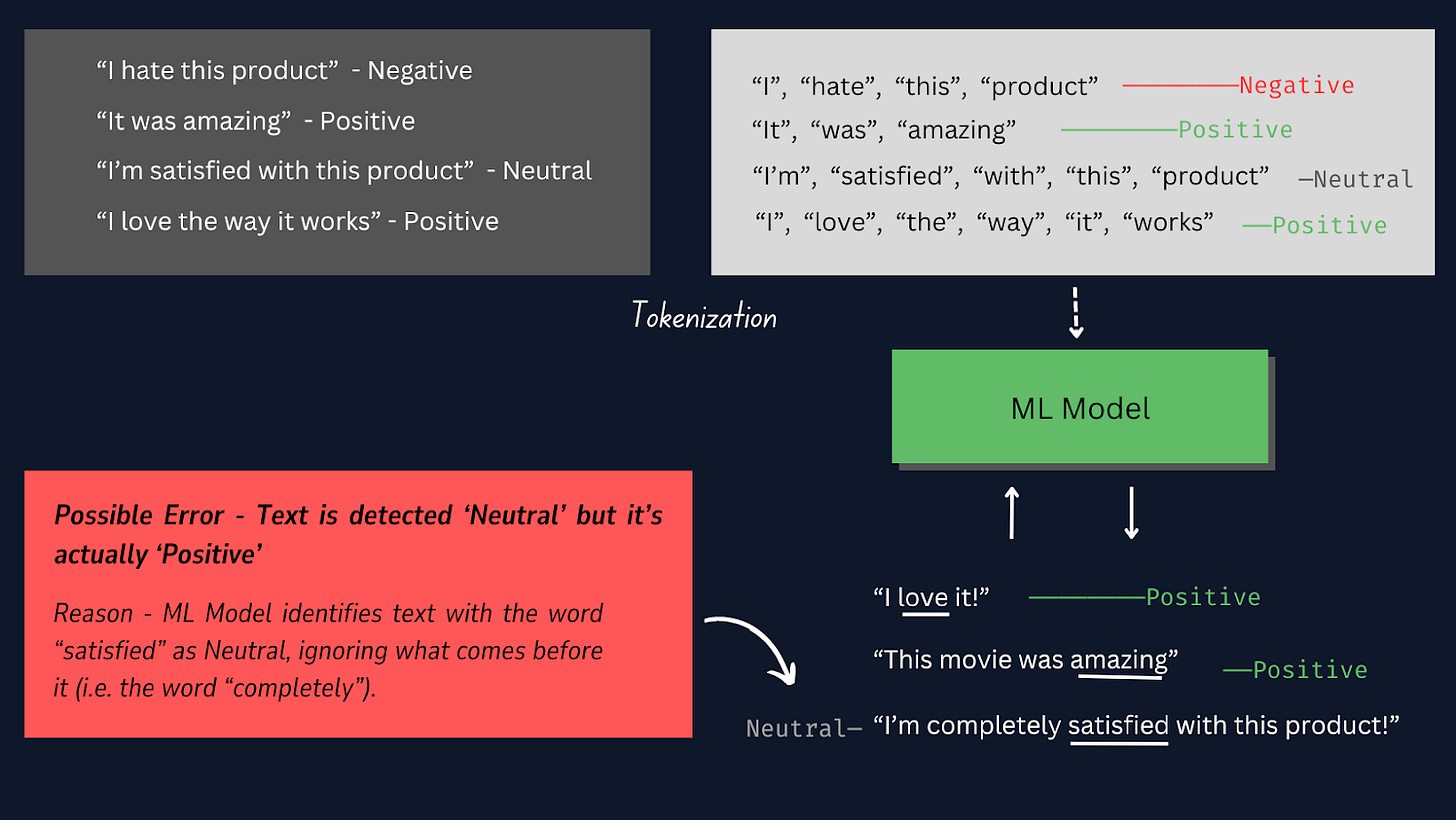
En este proyecto, es mejor utilizar la tokenización manual en lugar de otros tokenizadores prediseñados, ya que nos proporciona más control sobre el proceso de tokenización, garantiza la compatibilidad con formatos de datos específicos y permite pasos de preprocesamiento personalizados.
Nota: En la tokenización manual, escribimos código para dividir el texto en palabras, lo cual es altamente personalizable según las necesidades del proyecto. Sin embargo, otros métodos, como el uso del tokenizador Keras de TensorFlow, vienen con herramientas y funciones listas para usar para dividir el texto automáticamente, lo cual es más fácil de implementar pero menos personalizable.
A continuación se muestra el fragmento de código que podemos usar para la tokenización de datos de muestra.
word_index = {} sequences = [] for text in texts: words = text.lower().split() sequence = [] for word in words: if word not in word_index: word_index[word] = len(word_index) + 1 sequence.append(word_index[word]) sequences.append(sequence)En el código anterior,
-
word_index: un diccionario vacío creado para almacenar cada palabra única en el conjunto de datos, junto con su valor. -
sequences: Una lista vacía que almacena las secuencias de representación numérica de palabras para cada muestra de texto. -
for text in texts: recorre cada muestra de texto en la lista “textos” (creada anteriormente). -
words = text.lower().split(): Convierte cada muestra de texto a minúsculas y la divide en palabras individuales, según los espacios en blanco. -
for word in words: un bucle anidado que itera sobre cada palabra en la lista “palabras”, que contiene palabras tokenizadas de las muestras de texto actuales. -
if word not in word_index: si la palabra no está presente actualmente en el diccionario word_index, se agrega junto con un índice único, que se obtiene sumando 1 a la longitud actual del diccionario. -
sequence. append (word_index[word]): después de determinar el índice de la palabra actual, se agrega a la lista “secuencia”. Esto convierte cada palabra en la muestra de texto a su índice correspondiente según el diccionario “word_index”. -
sequence.append(sequence): después de que todas las palabras en la muestra de texto se convierten en índices numéricos y se almacenan en la lista “secuencia”, esta lista se agrega a la lista “secuencias”.
En resumen, el código anterior convierte los datos de texto en tokens al convertir cada palabra en su representación numérica basada en el diccionario word_index , que asigna las palabras a índices únicos. Crea secuencias de representaciones numéricas para cada muestra de texto, que se pueden usar como datos de entrada para el modelo.
Arquitectura del modelo
La arquitectura de un determinado modelo es la disposición de capas, componentes y conexiones que determinan cómo fluyen los datos a través de él . La arquitectura del modelo tiene un impacto significativo en la velocidad de entrenamiento, el rendimiento y la capacidad de generalización del modelo.
Después de procesar los datos de entrada, podemos definir la arquitectura del modelo como en el siguiente ejemplo:
model = tf.keras.Sequential([ tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length), tf.keras.layers.LSTM(64), tf.keras.layers.Dense(3, activation='softmax') ])
En el código anterior, utilizamos TensorFlow Keras, que es una API de redes neuronales de alto nivel creada para la experimentación y creación de prototipos rápidos de modelos de aprendizaje profundo, simplificando el proceso de construcción y compilación de modelos de aprendizaje automático.
-
tf. keras.Sequential(): Definición de un modelo secuencial, que es una pila lineal de capas. Los datos fluyen desde la primera capa hasta la última, en orden. -
tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length): esta capa se utiliza para la incrustación de palabras, que convierte las palabras en vectores densos de tamaño fijo. len(word_index) + 1 especifica el tamaño del vocabulario, 16 es la dimensionalidad de la incrustación y input_length=max_length establece la longitud de entrada para cada secuencia. -
tf.keras.layers.LSTM(64): Esta capa es una capa de memoria a corto y largo plazo (LSTM), que es un tipo de red neuronal recurrente (RNN). Procesa la secuencia de incrustaciones de palabras y puede "recordar" patrones o dependencias importantes en los datos. Tiene 64 unidades, que determinan la dimensionalidad del espacio de salida. -
tf.keras.layers.Dense(3, activation='softmax'): Esta es una capa densamente conectada con 3 unidades y una función de activación softmax. Es la capa de salida del modelo, que produce una distribución de probabilidad sobre las tres clases posibles (suponiendo un problema de clasificación de múltiples clases).


Compilación
En Machine Learning con TensorFlow, la compilación se refiere al proceso de configurar el modelo para el entrenamiento especificando tres componentes clave : función de pérdida, optimizador y métricas.
Función de pérdida : mide el error entre las predicciones del modelo y los objetivos reales, lo que ayuda a guiar los ajustes del modelo.
Optimizador : ajusta los parámetros del modelo para minimizar la función de pérdida, lo que permite un aprendizaje eficiente.
Métricas : proporciona una evaluación del rendimiento más allá de la pérdida, como la precisión o exactitud, lo que ayuda en la evaluación del modelo.

El siguiente código se puede utilizar para compilar el modelo de análisis de sentimientos:
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])Aquí,
loss='sparse_categorical_crossentropy': una función de pérdida se utiliza generalmente para tareas de clasificación, independientemente de si las etiquetas de destino son números enteros y el resultado del modelo es una distribución de probabilidad sobre varias clases. Mide la diferencia entre las etiquetas verdaderas y las predicciones , con el objetivo de minimizarla durante el entrenamiento.optimizer='adam': Adam es un algoritmo de optimización que adapta la tasa de aprendizaje de forma dinámica durante el entrenamiento. Se utiliza ampliamente en la práctica debido a su eficiencia, solidez y eficacia en una amplia gama de tareas en comparación con otros optimizadores.metrics = ['accuracy']: La precisión es una métrica común que se utiliza a menudo para evaluar los modelos de clasificación. Proporciona una medida sencilla del rendimiento general del modelo en la tarea, como el porcentaje de muestras para las que las predicciones del modelo coinciden con las etiquetas verdaderas.

Entrenando el modelo
Ahora que los datos de entrada están procesados y listos y la arquitectura del modelo también está definida, podemos entrenar el modelo usando el método model.fit() .
model.fit(padded_sequences, labels, epochs=15, verbose=1)padded_sequences: los datos de entrada para entrenar el modelo, que consisten en secuencias de las mismas dimensiones (el relleno se analizará más adelante en el tutorial).labels: etiquetas de destino correspondientes a los datos de entrada (es decir, categorías de sentimiento asignadas a cada muestra de texto)epochs=15: Una época es un recorrido completo por el conjunto de datos de entrenamiento completo durante el proceso de entrenamiento. Por lo tanto, en este programa, el modelo itera sobre el conjunto de datos completo 15 veces durante el entrenamiento.
Cuando se aumenta el número de épocas, es posible que mejore el rendimiento, ya que aprende patrones más complejos a través de las muestras de datos. Sin embargo, si se utilizan demasiadas épocas, el modelo puede memorizar los datos de entrenamiento, lo que lleva (a lo que se denomina "sobreajuste") a una generalización deficiente de los nuevos datos. El tiempo consumido para el entrenamiento también aumentará con el aumento del número de épocas y viceversa.


verbose=1: este es un parámetro para controlar la cantidad de resultados que produce el método de ajuste del modelo durante el entrenamiento. Un valor de 1 significa que se mostrarán barras de progreso en la consola a medida que se entrena el modelo, 0 significa que no hay resultados y 2 significa una línea por época. Dado que sería bueno ver los valores de precisión y pérdida y el tiempo que lleva cada época, lo estableceremos en 1.
Haciendo predicciones
Después de compilar y entrenar el modelo, este puede finalmente hacer predicciones basadas en nuestros datos de muestra, simplemente usando la función predict(). Sin embargo, necesitamos ingresar datos de entrada para probar el modelo y recibir el resultado. Para ello, debemos ingresar algunas declaraciones de texto y luego pedirle al modelo que prediga el sentimiento de los datos de entrada.
test_texts = ["The price was too high for the quality", "The interface is user-friendly", "I'm satisfied"] test_sequences = [] for text in test_texts: words = text.lower().split() sequence = [] for word in words: if word in word_index: sequence.append(word_index[word]) test_sequences.append(sequence) Aquí, test_texts almacena algunos datos de entrada mientras que la lista test_sequences se utiliza para almacenar datos de prueba tokenizados, que son palabras divididas por espacios en blanco después de convertirse en minúsculas. Pero aun así, test_sequences no podrá actuar como datos de entrada para el modelo.
La razón es que muchos marcos de aprendizaje profundo, incluido Tensorflow, generalmente requieren que los datos de entrada tengan una dimensión uniforme (lo que significa que la longitud de cada secuencia debe ser igual) para procesar lotes de datos de manera eficiente. Para lograr esto, puede usar técnicas como el relleno, donde las secuencias se extienden para que coincidan con la longitud de las secuencias más largas del conjunto de datos, mediante un token especial como # o 0 (0, en este ejemplo).
import numpy as np padded_test_sequences = [] for sequence in test_sequences: padded_sequence = sequence[:max_length] + [0] * (max_length - len(sequence)) padded_test_sequences.append(padded_sequence) # Convert to numpy array padded_test_sequences = np.array(padded_test_sequences)En el código dado,
-
padded_test_sequences: una lista vacía para almacenar las secuencias rellenas que se utilizarán para probar el modelo. -
for sequence in sequences: recorre cada secuencia en la lista “secuencias”. -
padded_sequence: crea una nueva secuencia con relleno para cada secuencia, truncando la secuencia original hasta los primeros elementos max_length para garantizar la coherencia. Luego, rellenamos la secuencia con ceros para que coincida con max_length si es más corta, lo que hace que todas las secuencias tengan la misma longitud. -
padded_test_sequences.append(): agrega una secuencia rellena a la lista que se usará para las pruebas. -
padded_sequences = np.array(): convierte la lista de secuencias rellenas en una matriz Numpy.


Ahora, como los datos de entrada están listos para usarse, el modelo finalmente puede predecir el sentimiento de los textos de entrada.
predictions = model.predict(padded_test_sequences) # Print predicted sentiments for i, text in enumerate(test_texts): print(f"Text: {text}, Predicted Sentiment: {np.argmax(predictions[i])}") En el código anterior, el método model.predict() genera predicciones para cada secuencia de prueba, lo que produce una matriz de probabilidades predichas para cada categoría de sentimiento. Luego, itera a través de cada elemento test_texts y np.argmax(predictions[i]) devuelve el índice de la probabilidad más alta en la matriz de probabilidades predichas para la i-ésima muestra de prueba. Este índice corresponde a la categoría de sentimiento predicha con la probabilidad predicha más alta para cada muestra de prueba, lo que significa que se extrae la mejor predicción realizada y se muestra como el resultado principal.
Notas especiales : *:* np.argmax() es una función NumPy que encuentra el índice del valor máximo en una matriz. En este contexto, np.argmax(predictions[i]) ayuda a determinar la categoría de sentimiento con la probabilidad predicha más alta para cada muestra de prueba.
El programa ya está listo para ejecutarse. Después de compilar y entrenar el modelo, el modelo de aprendizaje automático imprimirá sus predicciones para los datos de entrada.


En la salida del modelo, podemos ver los valores como “Precisión” y “Pérdida” para cada época. Como se mencionó anteriormente, la Precisión es el porcentaje de predicciones correctas del total de predicciones. Cuanto mayor sea la precisión, mejor. Si la precisión es 1,0, lo que significa 100 %, significa que el modelo realizó predicciones correctas en todos los casos. De manera similar, 0,5 significa que el modelo realizó predicciones correctas la mitad del tiempo, 0,25 significa predicciones correctas un cuarto del tiempo, y así sucesivamente.
Por otro lado, la pérdida muestra en qué medida las predicciones del modelo coinciden con los valores reales. Cuanto menor sea el valor de pérdida, mejor será el modelo, con menos errores. El valor 0 es el valor de pérdida perfecto, ya que significa que no se cometen errores.
Sin embargo, no podemos determinar la precisión y la pérdida generales del modelo con los datos anteriores que se muestran para cada época. Para ello, podemos evaluar el modelo utilizando el método evaluating() e imprimir su precisión y pérdida.
evaluation = model.evaluate(padded_sequences, labels, verbose=0) # Extract loss and accuracy loss = evaluation[0] accuracy = evaluation[1] # Print loss and accuracy print("Loss:", loss) print("Accuracy:", accuracy)Producción:
Loss: 0.6483516097068787 Accuracy: 0.7058823704719543En consecuencia, en este modelo, el valor de pérdida es 0,6483, lo que significa que el modelo ha cometido algunos errores. La precisión del modelo es de alrededor del 70 %, lo que significa que las predicciones realizadas por el modelo son correctas más de la mitad de las veces. En general, este modelo puede considerarse un modelo "ligeramente bueno"; sin embargo, tenga en cuenta que los valores de pérdida y precisión "buenos" dependen en gran medida del tipo de modelo, el tamaño del conjunto de datos y el propósito de un determinado modelo de aprendizaje automático.
Y sí, podemos y debemos mejorar las métricas anteriores del modelo mediante el ajuste de los procesos y mejores conjuntos de datos de muestra. Sin embargo, por el bien de este tutorial, detengámonos aquí. Si desea una segunda parte de este tutorial, ¡hágamelo saber!
Resumen
En este tutorial, construimos un modelo de aprendizaje automático de TensorFlow con la capacidad de predecir el sentimiento de un determinado texto, después de analizar el conjunto de datos de muestra.
El código completo y el archivo CSV de muestra se pueden descargar y ver en el repositorio de GitHub: GitHub - Buzzpy/Tensorflow-ML-Model








