
























Salut oameni frumosi! Sper că 2025 te tratează bine, deși până acum mi-a făcut probleme.
Bun venit pe blogul Doodles and Programming și astăzi vom construi: Un model de analiză a sentimentelor folosind TensorFlow + Python.


În acest tutorial, vom afla, de asemenea, despre elementele de bază ale învățării automate cu Python și, așa cum am menționat anterior, vom putea construi propriul model de învățare automată cu Tensorflow, o bibliotecă Python. Acest model va putea detecta tonul/emoția textului introdus , studiind și învățând din setul de date eșantion furnizat.
Cerințe preliminare
Tot ce avem nevoie este niște cunoștințe despre Python (cele mai de bază, desigur) și, de asemenea, să ne asigurăm că ai instalat Python în sistemul tău (se recomandă Python 3.9+).
Cu toate acestea, dacă vă este greu să parcurgeți acest tutorial, nu vă faceți griji! Trageți-mi un e-mail sau un mesaj; O să revin la tine cât de curând.
În cazul în care nu știți, ce este Machine Learning?
În termeni simpli, Machine Learning (ML) face ca computerul să învețe și să facă predicții, studiind date și statistici. Studiind datele furnizate, computerul poate identifica și extrage tipare și apoi poate face predicții pe baza acestora. Identificarea e-mailurilor spam, recunoașterea vorbirii și predicția traficului sunt câteva cazuri reale de utilizare a învățării automate.
Pentru un exemplu mai bun, imaginați-vă că vrem să învățăm un computer să recunoască pisicile în fotografii. Ai arăta o mulțime de poze cu pisici și ai spune: "Hei, computer, acestea sunt pisici!" Computerul se uită la imagini și începe să observe modele - cum ar fi urechi ascuțite, mustăți și blană. După ce a văzut suficiente exemple, poate recunoaște o pisică într-o fotografie nouă pe care nu a văzut-o până acum.


Un astfel de sistem de care profităm în fiecare zi este filtrele de spam prin e-mail. Următoarea imagine arată cum se face.


De ce să folosiți Python?
Chiar dacă limbajul de programare Python nu este construit special pentru ML sau Data Science, este considerat un limbaj de programare excelent pentru ML datorită adaptabilității sale. Cu sute de biblioteci disponibile pentru descărcare gratuită, oricine poate construi cu ușurință modele ML folosind o bibliotecă pre-construită, fără a fi nevoie să programeze procedura completă de la zero.
TensorFlow este o astfel de bibliotecă construită de Google pentru învățare automată și inteligență artificială. TensorFlow este adesea folosit de oamenii de știință de date, inginerii de date și alți dezvoltatori pentru a construi cu ușurință modele de învățare automată, deoarece constă dintr-o varietate de algoritmi de învățare automată și AI.
Vizitați site-ul oficial TensorFlow
Instalare
Pentru a instala Tensorflow, rulați următoarea comandă în terminal:
pip install tensorflowȘi pentru a instala Pandas și Numpy,
pip install pandas numpyVă rugăm să descărcați exemplul de fișier CSV din acest depozit: Github Repository - TensorFlow ML Model
Înțelegerea datelor
Regula nr. 1 a analizei datelor și orice se bazează pe date: înțelegeți mai întâi datele pe care le aveți.
În acest caz, setul de date are două coloane: Text și Sentiment. În timp ce coloana „text” are o varietate de afirmații făcute pe filme, cărți etc., coloana „sentiment” arată dacă textul este pozitiv, neutru sau negativ, folosind numerele 1, 2 și, respectiv, 0.
Pregătirea datelor
Următoarea regulă generală este să curățați duplicatele și să eliminați valorile nule din datele eșantionului. Dar în acest caz, deoarece setul de date dat este destul de mic și nu conține duplicate sau valori nule, putem sări peste procesul de curățare a datelor.


Pentru a începe construirea modelului, ar trebui să adunăm și să pregătim setul de date pentru a antrena modelul de analiză a sentimentelor. Pandas, o bibliotecă populară pentru analiza și manipularea datelor, poate fi folosită pentru această sarcină.
import pandas as pd # Load data from CSV data = pd.read_csv('sentiment.csv') # Change the path of downloaded CSV File accordingly # Text data and labels texts = data['text'].tolist() labels = data['sentiment'].values Codul de mai sus convertește fișierul CSV într-un cadru de date, folosind o funcție pandas.read_csv() . Apoi, atribuie valorile coloanei „sentiment” unei liste Python folosind funcția tolist() și creează o matrice Numpy cu valorile.
De ce să folosiți o matrice Numpy?
După cum probabil știți deja, Numpy este construit practic pentru manipularea datelor. Matricele Numpy gestionează eficient etichetele numerice pentru sarcinile de învățare automată, ceea ce oferă flexibilitate în organizarea datelor. De aceea folosim Numpy în acest caz.
Procesarea textului
După pregătirea datelor eșantion, trebuie să reprocesăm textul, ceea ce implică tokenizarea.
Tokenizarea este procesul de împărțire a fiecărui eșantion de text în cuvinte sau simboluri individuale, astfel încât să putem converti datele text brute într-un format care poate fi procesat de model , permițându-i să înțeleagă și să învețe din cuvintele individuale din eșantioanele de text. .
Consultați imaginea de mai jos pentru a afla cum funcționează tokenizarea.
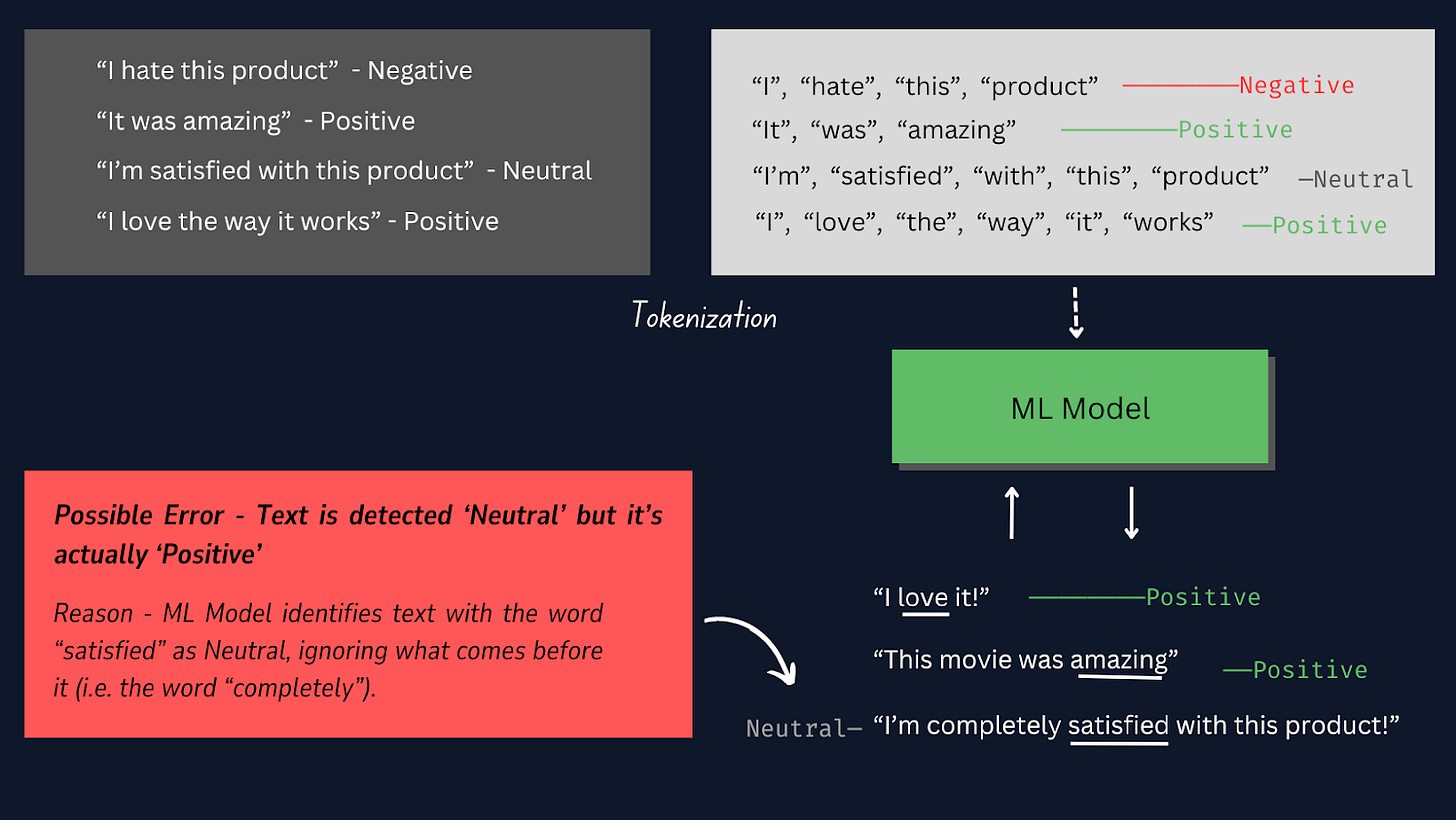
În acest proiect, cel mai bine este să folosiți tokenizarea manuală în locul altor tokenizatoare pre-construite, deoarece ne oferă mai mult control asupra procesului de tokenizare, asigură compatibilitatea cu formate specifice de date și permite pași personalizați de preprocesare.
Notă: În tokenizarea manuală, scriem cod pentru a împărți textul în cuvinte, care este foarte personalizabil în funcție de nevoile proiectului. Cu toate acestea, alte metode, cum ar fi utilizarea TensorFlow Keras Tokenizer, vin cu instrumente și funcții gata făcute pentru împărțirea automată a textului, ceea ce este mai ușor de implementat, dar mai puțin personalizabil.
În continuare este fragmentul de cod pe care îl putem folosi pentru tokenizarea datelor eșantionului.
word_index = {} sequences = [] for text in texts: words = text.lower().split() sequence = [] for word in words: if word not in word_index: word_index[word] = len(word_index) + 1 sequence.append(word_index[word]) sequences.append(sequence)În codul de mai sus,
-
word_index: un dicționar gol creat pentru a stoca fiecare cuvânt unic din setul de date, împreună cu valoarea acestuia. -
sequences: o listă goală care stochează secvențele de reprezentare numerică a cuvintelor pentru fiecare eșantion de text. -
for text in texts: parcurge fiecare probă de text din lista „texte” (creată mai devreme). -
words = text.lower().split(): Convertește fiecare eșantion de text în litere mici și îl împarte în cuvinte individuale, pe baza spațiilor albe. -
for word in words: o buclă imbricată care iterează peste fiecare cuvânt din lista „cuvinte”, care conține cuvinte simbolizate din exemplele de text curente. -
if word not in word_index: Dacă cuvântul nu este prezent în dicționarul word_index, acesta este adăugat la acesta împreună cu un index unic, care se obține prin adăugarea 1 la lungimea curentă a dicționarului. -
sequence. append (word_index[word]): După determinarea indexului cuvântului curent, acesta este atașat la lista „secvență”. Acest lucru transformă fiecare cuvânt din eșantionul de text în indexul corespunzător pe baza dicționarului „word_index”. -
sequence.append(sequence): După ce toate cuvintele din eșantionul de text sunt convertite în indici numerici și stocate în lista „secvență”, această listă este atașată la lista „secvențe”.
În rezumat, codul de mai sus tokenizează datele text prin conversia fiecărui cuvânt în reprezentarea sa numerică pe baza dicționarului word_index , care mapează cuvintele la indici unici. Acesta creează secvențe de reprezentări numerice pentru fiecare eșantion de text, care pot fi folosite ca date de intrare pentru model.
Arhitectura modelului
Arhitectura unui anumit model este aranjarea straturilor, componentelor și conexiunilor care determină modul în care datele circulă prin el . Arhitectura modelului are un impact semnificativ asupra vitezei de antrenament, a performanței și a capacității de generalizare a modelului.
După procesarea datelor de intrare, putem defini arhitectura modelului ca în exemplul de mai jos:
model = tf.keras.Sequential([ tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length), tf.keras.layers.LSTM(64), tf.keras.layers.Dense(3, activation='softmax') ])
În codul de mai sus, folosim TensorFlow Keras, care este un API de rețele neuronale de nivel înalt, construit pentru experimentarea rapidă și prototiparea modelelor Deep Learning, prin simplificarea procesului de construire și compilare a modelelor de învățare automată.
-
tf. keras.Sequential(): Definirea unui model secvenţial, care este o stivă liniară de straturi. Datele curg de la primul strat la ultimul, în ordine. -
tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length): Acest strat este folosit pentru încorporarea cuvintelor, care convertește cuvintele în vectori denși de dimensiune fixă. Len(index_cuvânt) + 1 specifică dimensiunea vocabularului, 16 este dimensionalitatea înglobării și input_length=max_length setează lungimea de intrare pentru fiecare secvență. -
tf.keras.layers.LSTM(64): Acest strat este un strat de memorie pe termen lung (LSTM), care este un tip de rețea neuronală recurentă (RNN). Procesează secvența înglobărilor de cuvinte și își poate „aminti” modele sau dependențe importante în date. Are 64 de unități, care determină dimensionalitatea spațiului de ieșire. -
tf.keras.layers.Dense(3, activation='softmax'): Acesta este un strat dens conectat cu 3 unități și o funcție de activare softmax. Este stratul de ieșire al modelului, producând o distribuție de probabilitate pe cele trei clase posibile (presupunând o problemă de clasificare cu mai multe clase).


Compilare
În Machine Learning cu TensorFlow, compilarea se referă la procesul de configurare a modelului pentru antrenament prin specificarea a trei componente cheie — Funcția de pierdere, Optimizer și Metrics.
Funcția de pierdere : Măsoară eroarea dintre predicțiile modelului și obiectivele reale, ajutând la ghidarea ajustărilor modelului.
Optimizer : ajustează parametrii modelului pentru a minimiza funcția de pierdere, permițând o învățare eficientă.
Valori : oferă o evaluare a performanței dincolo de pierderi, cum ar fi acuratețea sau precizia, ajutând la evaluarea modelului.

Codul de mai jos poate fi folosit pentru a compila modelul de analiză a sentimentelor:
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])Aici,
loss='sparse_categorical_crossentropy': O funcție de pierdere este utilizată în general pentru sarcinile de clasificare, indiferent dacă etichetele țintă sunt numere întregi și rezultatul modelului este o distribuție de probabilitate pe mai multe clase. Măsoară diferența dintre etichetele adevărate și predicții , urmărind să o minimizeze în timpul antrenamentului.optimizer='adam': Adam este un algoritm de optimizare care adaptează dinamic rata de învățare în timpul antrenamentului. Este utilizat pe scară largă în practică datorită eficienței, robusteței și eficacității sale într-o gamă largă de sarcini în comparație cu alte optimizatoare.metrics = ['accuracy']: acuratețea este o măsură comună folosită adesea pentru a evalua modelele de clasificare. Oferă o măsură simplă a performanței generale a modelului la sarcină, ca procent de eșantioane pentru care predicțiile modelului se potrivesc cu etichetele adevărate.

Antrenarea modelului
Acum că datele de intrare sunt procesate și gata și arhitectura modelului este de asemenea definită, putem antrena modelul folosind metoda model.fit() .
model.fit(padded_sequences, labels, epochs=15, verbose=1)padded_sequences: Datele de intrare pentru antrenarea modelului, care constă din secvențe de aceleași dimensiuni (padding-ul va fi discutat mai târziu în tutorial).labels: etichete țintă corespunzătoare datelor de intrare (adică categorii de sentimente atribuite fiecărui eșantion de text)epochs=15: O epocă este o trecere completă prin setul complet de date de antrenament în timpul procesului de antrenament. În consecință, în acest program, modelul iterează peste setul de date complet de 15 ori în timpul antrenamentului.
Când numărul de epoci crește, va îmbunătăți potențial performanța, deoarece învață modele mai complexe prin eșantioanele de date. Cu toate acestea, dacă sunt folosite prea multe epoci, modelul poate memora datele de antrenament care duc (care se numește „suprafitting”) la o generalizare slabă a datelor noi. Timpul consumat pentru antrenament va crește și el odată cu creșterea numărului de epoci și invers.


verbose=1: Acesta este un parametru pentru controlul cât de multă ieșire produce metoda de potrivire a modelului în timpul antrenamentului. O valoare de 1 înseamnă că barele de progres vor fi afișate în consolă pe măsură ce modelul se antrenează, 0 înseamnă lipsă de ieșire și 2 înseamnă o linie pe epocă. Deoarece ar fi bine să vedem acuratețea și valorile pierderilor și timpul necesar pentru fiecare epocă, îl vom seta la 1.
Efectuarea de predicții
După compilarea și antrenamentul modelului, acesta poate face în sfârșit predicții pe baza datelor noastre eșantion, pur și simplu folosind funcția predict(). Cu toate acestea, trebuie să introducem date de intrare pentru a testa modelul și a primi rezultate. Pentru a face acest lucru, ar trebui să introducem câteva instrucțiuni text și apoi să cerem modelului să prezică sentimentul datelor de intrare.
test_texts = ["The price was too high for the quality", "The interface is user-friendly", "I'm satisfied"] test_sequences = [] for text in test_texts: words = text.lower().split() sequence = [] for word in words: if word in word_index: sequence.append(word_index[word]) test_sequences.append(sequence) Aici, test_texts stochează unele date de intrare, în timp ce lista test_sequences este folosită pentru a stoca date de testare tokenizate, care sunt cuvinte împărțite prin spații albe după ce s-au transformat în litere mici. Dar totuși, test_sequences nu va putea acționa ca date de intrare pentru model.
Motivul este că multe cadre de învățare profundă, inclusiv Tensorflow, necesită de obicei ca datele de intrare să aibă o dimensiune uniformă (ceea ce înseamnă că lungimea fiecărei secvențe ar trebui să fie egală), pentru a procesa loturi de date în mod eficient. Pentru a realiza acest lucru, puteți utiliza tehnici precum padding, în care secvențele sunt extinse pentru a se potrivi cu lungimea celor mai lungi secvențe din setul de date, folosind un simbol special, cum ar fi # sau 0 (0, în acest exemplu).
import numpy as np padded_test_sequences = [] for sequence in test_sequences: padded_sequence = sequence[:max_length] + [0] * (max_length - len(sequence)) padded_test_sequences.append(padded_sequence) # Convert to numpy array padded_test_sequences = np.array(padded_test_sequences)În codul dat,
-
padded_test_sequences: O listă goală pentru a stoca secvențele padded care vor fi folosite pentru a testa modelul. -
for sequence in sequences: parcurge fiecare secvență din lista „secvențe”. -
padded_sequence: creează o nouă secvență căptușită pentru fiecare secvență, trunchiind secvența originală la primele elemente max_length pentru a asigura consistența. Apoi, completăm secvența cu zerouri pentru a se potrivi cu max_length dacă este mai scurtă, făcând efectiv toate secvențele de aceeași lungime. -
padded_test_sequences.append(): Adăugați o secvență completată la lista care va fi folosită pentru testare. -
padded_sequences = np.array(): Conversia listei de secvențe padded într-o matrice Numpy.


Acum, deoarece datele de intrare sunt gata de utilizare, modelul poate prezice în sfârșit sentimentul textelor introduse.
predictions = model.predict(padded_test_sequences) # Print predicted sentiments for i, text in enumerate(test_texts): print(f"Text: {text}, Predicted Sentiment: {np.argmax(predictions[i])}") În codul de mai sus, metoda model.predict() generează predicții pentru fiecare secvență de testare, producând o serie de probabilități prezise pentru fiecare categorie de sentimente. Apoi iterează prin fiecare element test_texts și np.argmax(predictions[i]) returnează indicele celei mai mari probabilități din matricea probabilităților prezise pentru eșantionul de test i-a. Acest indice corespunde categoriei de sentimente prezise cu cea mai mare probabilitate prezisă pentru fiecare eșantion de testare, ceea ce înseamnă că cea mai bună predicție realizată este extrasă și afișată ca rezultat principal.
Note speciale *:* np.argmax() este o funcție NumPy care găsește indexul valorii maxime într-o matrice. În acest context, np.argmax(predictions[i]) ajută la determinarea categoriei de sentiment cu cea mai mare probabilitate prezisă pentru fiecare eșantion de testare.
Programul este acum gata de rulare. După compilarea și instruirea modelului, Modelul de învățare automată își va tipări predicțiile pentru datele de intrare.


În rezultatul modelului, putem vedea valorile „Acuratețe” și „Pierdere” pentru fiecare Epocă. După cum am menționat anterior, acuratețea este procentul de predicții corecte din totalul predicțiilor. Cu cât precizia este mai mare este mai bună. Dacă acuratețea este 1.0, ceea ce înseamnă 100%, înseamnă că modelul a făcut predicții corecte în toate cazurile. În mod similar, 0,5 înseamnă că modelul a făcut predicții corecte jumătate din timp, 0,25 înseamnă predicție corectă un sfert din timp și așa mai departe.
Pierderea , pe de altă parte, arată cât de prost se potrivesc predicțiile modelului cu valorile adevărate. Valoarea mai mică a pierderii înseamnă un model mai bun, cu un număr mai mic de erori, valoarea 0 fiind valoarea pierderii perfecte, deoarece aceasta înseamnă că nu se comite erori.
Cu toate acestea, nu putem determina acuratețea generală și pierderea modelului cu datele de mai sus afișate pentru fiecare Epocă. Pentru a face acest lucru, putem evalua modelul folosind metoda evaluate() și imprimăm acuratețea și pierderea acestuia.
evaluation = model.evaluate(padded_sequences, labels, verbose=0) # Extract loss and accuracy loss = evaluation[0] accuracy = evaluation[1] # Print loss and accuracy print("Loss:", loss) print("Accuracy:", accuracy)Ieșire:
Loss: 0.6483516097068787 Accuracy: 0.7058823704719543În consecință, în acest model, valoarea Pierderii este 0,6483, ceea ce înseamnă că Modelul a făcut unele erori. Precizia modelului este de aproximativ 70%, ceea ce înseamnă că predicțiile făcute de model sunt corecte mai mult de jumătate din timp. În general, acest model poate fi considerat un model „puțin bun”; totuși, rețineți că valorile „bune” de pierdere și acuratețe depind în mare măsură de tipul de model, de dimensiunea setului de date și de scopul unui anumit model de învățare automată.
Și da, putem și ar trebui să îmbunătățim valorile de mai sus ale modelului prin procese de reglare fină și seturi de date eșantionare mai bune. Cu toate acestea, de dragul acestui tutorial, să ne oprim de aici. Dacă doriți o a doua parte a acestui tutorial, vă rog să-mi spuneți!
Rezumat
În acest tutorial, am construit un model de învățare automată TensorFlow cu capacitatea de a prezice sentimentul unui anumit text, după analiza setului de date eșantion.
Codul complet și fișierul CSV exemplu pot fi descărcate și văzute în Depozitul GitHub - GitHub - Buzzpy/Tensorflow-ML-Model








