
























Здравейте красиви хора! Надяваме се, че 2025 г. се отнася добре с вас, въпреки че досега беше бъгово за мен.
Добре дошли в блога за драскулки и програмиране и днес ще изградим: Модел за анализ на настроението с помощта на TensorFlow + Python.


В този урок ще научим и за основите на машинното обучение с Python и както споменахме по-рано, ще можем да изградим наш собствен модел на машинно обучение с Tensorflow, библиотека на Python. Този модел ще може да открие тона/емоцията на въведения текст чрез изучаване и обучение от предоставения примерен набор от данни.
Предпоставки
Всичко, от което се нуждаем, е известно познаване на Python (най-основните неща, разбира се), а също така се уверете, че имате инсталиран Python във вашата система (препоръчва се Python 3.9+).
Въпреки това, ако ви е трудно да преминете през този урок, не се притеснявайте! Изпратете ми имейл или съобщение; Ще се свържа с вас възможно най-скоро.
В случай, че не сте наясно, какво е машинно обучение?
С прости думи, машинното обучение (ML) кара компютъра да учи и да прави прогнози, като изучава данни и статистики. Чрез изучаване на предоставените данни компютърът може да идентифицира и извлече модели и след това да направи прогнози въз основа на тях. Идентифицирането на спам имейли, разпознаването на реч и прогнозирането на трафика са някои реални случаи на използване на машинното обучение.
За по-добър пример, представете си, че искаме да научим компютър да разпознава котки на снимки. Ще му покажеш много снимки на котки и ще кажеш: „Хей, компютър, това са котки!“ Компютърът разглежда снимките и започва да забелязва модели - като заострени уши, мустаци и козина. След като види достатъчно примери, то може да разпознае котка на нова снимка, която не е виждало преди.


Една такава система, от която се възползваме всеки ден, са филтрите за спам по имейл. Следното изображение показва как се прави.


Защо да използвате Python?
Въпреки че езикът за програмиране Python не е създаден специално за ML или Data Science, той се смята за чудесен език за програмиране за ML поради своята адаптивност. Със стотици библиотеки, достъпни за безплатно изтегляне, всеки може лесно да създава ML модели, като използва предварително изградена библиотека, без да е необходимо да програмира цялата процедура от нулата.
TensorFlow е една такава библиотека, създадена от Google за машинно обучение и изкуствен интелект. TensorFlow често се използва от специалисти по данни, инженери по данни и други разработчици за лесно изграждане на модели за машинно обучение, тъй като се състои от различни алгоритми за машинно обучение и AI.
Посетете официалния уебсайт на TensorFlow
Монтаж
За да инсталирате Tensorflow, изпълнете следната команда във вашия терминал:
pip install tensorflowИ за да инсталирате Pandas и Numpy,
pip install pandas numpyМоля, изтеглете примерния CSV файл от това хранилище: Github Repository - TensorFlow ML Model
Разбиране на данните
Правило №1 за анализ на данни и всичко, което е изградено върху данни: Първо разберете данните, които имате.
В този случай наборът от данни има две колони: Текст и Настроения. Докато колоната „текст“ съдържа различни твърдения, направени за филми, книги и т.н., колоната „чувство“ показва дали текстът е положителен, неутрален или отрицателен, като използва съответно числа 1, 2 и 0.
Подготовка на данни
Следващото основно правило е да изчистите дубликатите и да премахнете нулевите стойности във вашите примерни данни. Но в този случай, тъй като даденият набор от данни е сравнително малък и не съдържа дубликати или нулеви стойности, можем да пропуснем процеса на почистване на данни.


За да започнем изграждането на модела, трябва да съберем и подготвим набора от данни, за да обучим модела за анализ на настроението. Pandas, популярна библиотека за анализ и манипулиране на данни, може да се използва за тази задача.
import pandas as pd # Load data from CSV data = pd.read_csv('sentiment.csv') # Change the path of downloaded CSV File accordingly # Text data and labels texts = data['text'].tolist() labels = data['sentiment'].values Горният код преобразува CSV файла в рамка с данни, използвайки функция pandas.read_csv() . След това присвоява стойностите на колоната „сентимент“ към списък на Python с помощта на функцията tolist() и създава масив Numpy със стойностите.
Защо да използвате масив Numpy?
Както може би вече знаете, Numpy е основно създаден за манипулиране на данни. Масивите Numpy ефективно обработват цифрови етикети за задачи за машинно обучение, което предлага гъвкавост в организацията на данните. Ето защо в този случай използваме Numpy.
Обработка на текст
След като подготвим примерни данни, трябва да обработим повторно текста, което включва токенизация.
Токенизацията е процесът на разделяне на всяка текстова проба на отделни думи или токени, така че да можем да конвертираме необработените текстови данни във формат, който може да бъде обработен от модела , което му позволява да разбира и да се учи от отделните думи в текстовите проби .
Вижте изображението по-долу, за да научите как работи токенизацията.
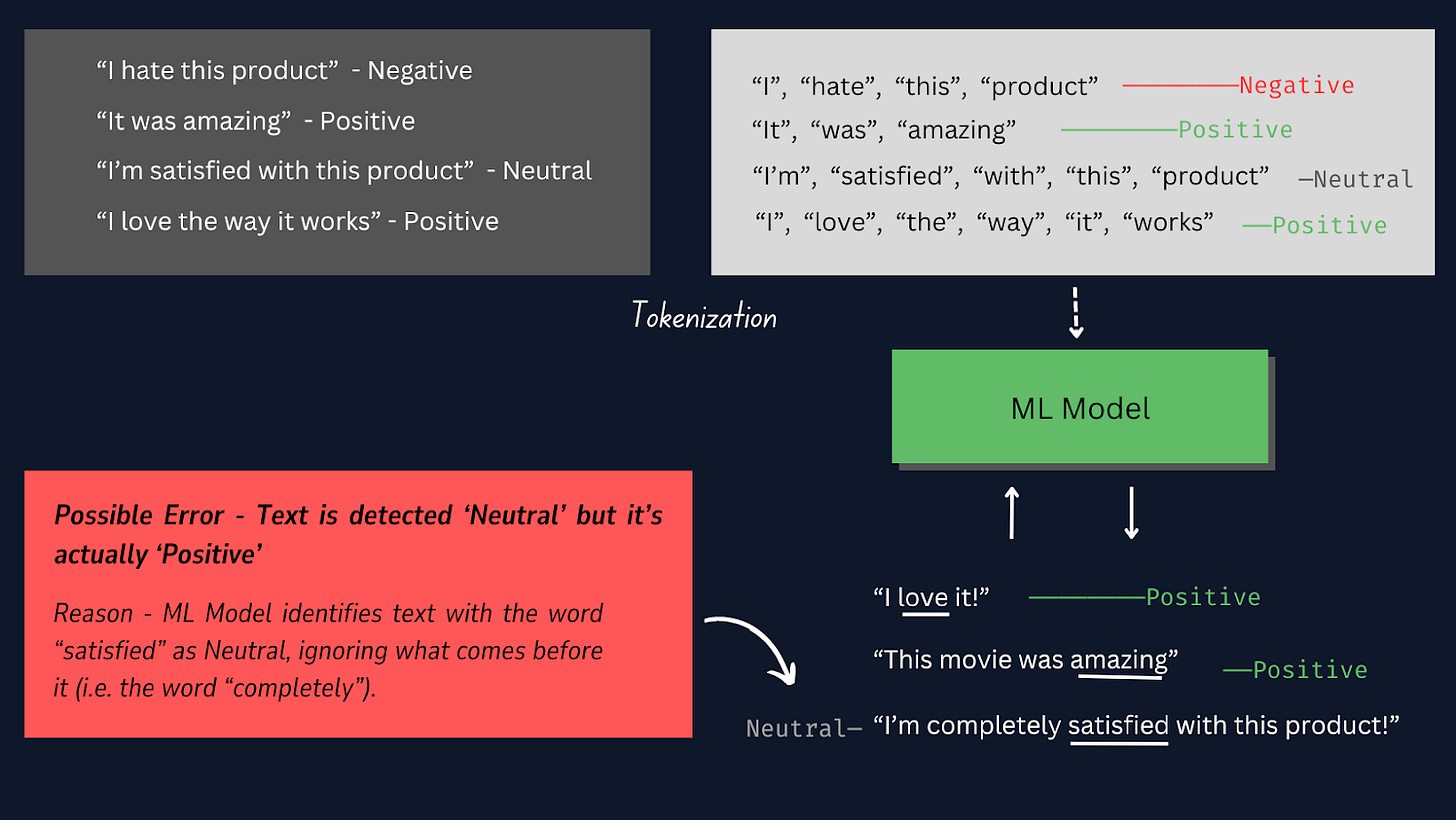
В този проект е най-добре да използваме ръчно токенизиране вместо други предварително изградени токенизатори, тъй като ни предоставя повече контрол върху процеса на токенизиране, гарантира съвместимост със специфични формати на данни и позволява персонализирани стъпки за предварителна обработка.
Забележка: При ръчното токенизиране ние пишем код за разделяне на текст на думи, което е много персонализирано според нуждите на проекта. Въпреки това, други методи, като например използването на TensorFlow Keras Tokenizer, идват с готови инструменти и функции за автоматично разделяне на текст, което е по-лесно за изпълнение, но по-малко персонализирано.
Следва кодовият фрагмент, който можем да използваме за токенизиране на примерни данни.
word_index = {} sequences = [] for text in texts: words = text.lower().split() sequence = [] for word in words: if word not in word_index: word_index[word] = len(word_index) + 1 sequence.append(word_index[word]) sequences.append(sequence)В горния код,
-
word_index: Празен речник, създаден за съхраняване на всяка уникална дума в набора от данни, заедно с нейната стойност. -
sequences: празен списък, който съхранява последователностите от цифрово представяне на думи за всяка текстова проба. -
for text in texts: преминава през всяка текстова проба в списъка „текстове“ (създаден по-рано). -
words = text.lower().split(): Преобразува всяка текстова проба в малки букви и я разделя на отделни думи въз основа на празно пространство. -
for word in words: Вложен цикъл, който итерира всяка дума в списъка „думи“, който съдържа токенизирани думи от текущите текстови проби. -
if word not in word_index: Ако думата не присъства в момента в речника word_index, тя се добавя към него заедно с уникален индекс, който се получава чрез добавяне на 1 към текущата дължина на речника. -
sequence. append (word_index[word]): След определяне на индекса на текущата дума, тя се добавя към списъка „последователност“. Това преобразува всяка дума в текстовата проба в съответния й индекс въз основа на речника „word_index“. -
sequence.append(sequence): След като всички думи в текстовата проба се преобразуват в числови индекси и се съхранят в списъка „последователност“, този списък се добавя към списъка „последователности“.
В обобщение, горният код токенизира текстовите данни, като преобразува всяка дума в нейното числено представяне въз основа на речника word_index , който преобразува думите в уникални индекси. Той създава поредици от числени представяния за всяка текстова проба, които могат да се използват като входни данни за модела.
Моделна архитектура
Архитектурата на определен модел е подреждането на слоеве, компоненти и връзки, които определят как данните протичат през него . Архитектурата на модела има значително влияние върху скоростта на обучение, производителността и способността за обобщение на модела.
След обработка на входните данни, можем да дефинираме архитектурата на модела, както в примера по-долу:
model = tf.keras.Sequential([ tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length), tf.keras.layers.LSTM(64), tf.keras.layers.Dense(3, activation='softmax') ])
В горния код използваме TensorFlow Keras, който е API за невронни мрежи от високо ниво, създаден за бързо експериментиране и създаване на прототипи на модели за дълбоко обучение, като опростява процеса на конструиране и компилиране на модели за машинно обучение.
-
tf. keras.Sequential(): Дефиниране на последователен модел, който е линеен стек от слоеве. Данните преминават от първия слой към последния, по ред. -
tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length): Този слой се използва за вграждане на думи, което преобразува думите в плътни вектори с фиксиран размер. Len(word_index) + 1 определя размера на речника, 16 е размерността на вграждането, а input_length=max_length задава входната дължина за всяка последователност. -
tf.keras.layers.LSTM(64): Този слой е слой с дълга краткосрочна памет (LSTM), който е вид повтаряща се невронна мрежа (RNN). Той обработва последователността от вграждане на думи и може да „запомни“ важни модели или зависимости в данните. Има 64 единици, които определят размерността на изходното пространство. -
tf.keras.layers.Dense(3, activation='softmax'): Това е плътно свързан слой с 3 единици и функция за активиране на softmax. Това е изходният слой на модела, създаващ разпределение на вероятността за трите възможни класа (приемайки проблем с класификация на няколко класа).


Компилация
В машинното обучение с TensorFlow компилацията се отнася до процеса на конфигуриране на модела за обучение чрез указване на три ключови компонента — функция за загуба, оптимизатор и показатели.
Функция за загуба : Измерва грешката между прогнозите на модела и действителните цели, като помага за насочване на корекциите на модела.
Оптимизатор : Настройва параметрите на модела, за да минимизира функцията за загуба, което позволява ефективно обучение.
Метрики : Осигурява оценка на ефективността извън загубата, като точност или прецизност, подпомагайки оценката на модела.

Кодът по-долу може да се използва за компилиране на модела за анализ на настроението:
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])тук,
loss='sparse_categorical_crossentropy': Функция за загуба обикновено се използва за задачи за класификация, независимо дали целевите етикети са цели числа и изходът на модела е вероятностно разпределение за множество класове. Той измерва разликата между истинските етикети и прогнозите , като се стреми да я минимизира по време на обучение.optimizer='adam': Adam е алгоритъм за оптимизация, който динамично адаптира скоростта на обучение по време на обучение. Той се използва широко на практика поради своята ефективност, устойчивост и ефективност в широк набор от задачи в сравнение с други оптимизатори.metrics = ['accuracy']: Точността е обща метрика, често използвана за оценка на класификационни модели. Той осигурява пряка мярка за цялостното представяне на модела по задачата, като процент проби, за които прогнозите на модела съвпадат с истинските етикети.

Обучение на модела
Сега, когато входните данни са обработени и готови и архитектурата на модела също е дефинирана, можем да обучим модела с помощта на метода model.fit() .
model.fit(padded_sequences, labels, epochs=15, verbose=1)padded_sequences: Входните данни за обучение на модела, който се състои от последователности с еднакви размери (запълването ще бъде обсъдено по-късно в урока).labels: целеви етикети, съответстващи на входните данни (т.е. категории настроения, присвоени на всяка текстова проба)epochs=15: Една епоха е едно пълно преминаване през целия набор от данни за обучение по време на процеса на обучение. Съответно в тази програма моделът итерира целия набор от данни 15 пъти по време на обучението.
Когато броят на епохите се увеличи, това потенциално ще подобри производителността, тъй като научава по-сложни модели чрез извадките от данни. Въпреки това, ако се използват твърде много епохи, моделът може да запомни тренировъчни данни, водещи (което се нарича „пренастройване“) до лошо обобщаване на нови данни. Времето, изразходвано за обучение, също ще се увеличи с увеличаването на броя на епохите и обратно.


verbose=1: Това е параметър за контролиране на изхода, който методът за прилягане на модела произвежда по време на обучение. Стойност 1 означава, че лентите за напредъка ще се показват в конзолата, докато моделът се обучава, 0 означава, че няма изход, а 2 означава един ред на епоха. Тъй като би било добре да видим стойностите на точността и загубата и времето, необходимо за всяка епоха, ще го зададем на 1.
Правене на прогнози
След компилиране и обучение на модела, той най-накрая може да прави прогнози въз основа на нашите примерни данни, просто като използва функцията predict(). Трябва обаче да въведем входни данни, за да тестваме модела и да получим изход. За да направим това, трябва да въведем някои текстови изрази и след това да помолим модела да предвиди настроението на входните данни.
test_texts = ["The price was too high for the quality", "The interface is user-friendly", "I'm satisfied"] test_sequences = [] for text in test_texts: words = text.lower().split() sequence = [] for word in words: if word in word_index: sequence.append(word_index[word]) test_sequences.append(sequence) Тук test_texts съхранява някои входни данни, докато списъкът test_sequences се използва за съхраняване на токенизирани тестови данни, които са думи, разделени с интервали след превръщането им в малки букви. Но все пак test_sequences няма да може да действа като входни данни за модела.
Причината е, че много рамки за дълбоко обучение, включително Tensorflow, обикновено изискват входните данни да имат еднакво измерение (което означава, че дължината на всяка последователност трябва да е еднаква), за да обработват партиди от данни ефективно. За да постигнете това, можете да използвате техники като запълване, където последователностите се разширяват, за да съответстват на дължината на най-дългите последователности в набора от данни, като използвате специален маркер като # или 0 (0, в този пример).
import numpy as np padded_test_sequences = [] for sequence in test_sequences: padded_sequence = sequence[:max_length] + [0] * (max_length - len(sequence)) padded_test_sequences.append(padded_sequence) # Convert to numpy array padded_test_sequences = np.array(padded_test_sequences)В дадения код,
-
padded_test_sequences: Празен списък за съхраняване на подплатените последователности, които ще се използват за тестване на модела. -
for sequence in sequences: Преминава през всяка последователност в списъка „последователности“. -
padded_sequence: Създава нова подплатена последователност за всяка последователност, съкращавайки оригиналната последователност до първите елементи max_length, за да осигури последователност. След това допълваме последователността с нули, за да съответства на max_length, ако е по-къса, което на практика прави всички последователности еднаква дължина. -
padded_test_sequences.append(): Добавете подплатена последователност към списъка, който ще се използва за тестване. -
padded_sequences = np.array(): Преобразуване на списъка с подплатени последователности в масив Numpy.


Сега, тъй като входните данни са готови за използване, моделът най-накрая може да предвиди настроението на входните текстове.
predictions = model.predict(padded_test_sequences) # Print predicted sentiments for i, text in enumerate(test_texts): print(f"Text: {text}, Predicted Sentiment: {np.argmax(predictions[i])}") В горния код методът model.predict() генерира прогнози за всяка тестова последователност, създавайки масив от прогнозирани вероятности за всяка категория настроения. След това преминава през всеки елемент test_texts и np.argmax(predictions[i]) връща индекса на най-високата вероятност в масива с прогнозирани вероятности за i-тата тестова проба. Този индекс съответства на прогнозираната категория на настроението с най-високата прогнозирана вероятност за всяка тестова проба, което означава, че най-добрата направена прогноза се извлича и показва като основен резултат.
Специални бележки *:* np.argmax() е функция NumPy, която намира индекса на максималната стойност в масив. В този контекст np.argmax(predictions[i]) помага да се определи категорията на настроението с най-високата прогнозирана вероятност за всяка тестова проба.
Програмата вече е готова за изпълнение. След компилиране и обучение на модела, моделът за машинно обучение ще отпечата своите прогнози за входните данни.


В изхода на модела можем да видим стойностите като „Точност“ и „Загуба“ за всяка епоха. Както бе споменато по-горе, точността е процентът на правилните прогнози от общия брой прогнози. По-високата точност е по-добра. Ако точността е 1,0, което означава 100%, това означава, че моделът е направил правилни прогнози във всички случаи. По същия начин 0,5 означава, че моделът е правил правилни прогнози през половината от времето, 0,25 означава правилно прогнозиране през четвърт от времето и т.н.
Загубата , от друга страна, показва колко зле прогнозите на модела съвпадат с истинските стойности. По-малката стойност на загубата означава по-добър модел с по-малък брой грешки, като стойността 0 е перфектната стойност на загубата, тъй като това означава, че няма грешки.
Не можем обаче да определим общата точност и загуба на модела с горните данни, показани за всяка епоха. За да направим това, можем да оценим модела с помощта на метода evaluate() и да отпечатаме неговата точност и загуба.
evaluation = model.evaluate(padded_sequences, labels, verbose=0) # Extract loss and accuracy loss = evaluation[0] accuracy = evaluation[1] # Print loss and accuracy print("Loss:", loss) print("Accuracy:", accuracy)Изход:
Loss: 0.6483516097068787 Accuracy: 0.7058823704719543Съответно в този модел стойността на загубата е 0,6483, което означава, че моделът е направил някои грешки. Точността на модела е около 70%, което означава, че прогнозите, направени от модела, са правилни повече от половината от времето. Като цяло този модел може да се счита за „малко добър“ модел; все пак, имайте предвид, че „добрите“ стойности на загуба и точност силно зависят от типа на модела, размера на набора от данни и целта на определен модел на машинно обучение.
И да, можем и трябва да подобрим горните показатели на модела чрез процеси на фина настройка и по-добри набори от примерни данни. Въпреки това, в името на този урок, нека спрем от тук. Ако искате втора част от този урок, моля, уведомете ме!
Резюме
В този урок изградихме модел за машинно обучение TensorFlow с възможност за предсказване на настроението на определен текст след анализ на примерния набор от данни.
Пълният код и примерният CSV файл могат да бъдат изтеглени и видени в GitHub Repository - GitHub - Buzzpy/Tensorflow-ML-Model




