
























Olá, pessoas lindas! Espero que 2025 esteja tratando vocês bem, mesmo que tenha sido um ano cheio de bugs para mim, até agora.
Bem-vindo ao blog Doodles and Programming. Hoje vamos construir: Um modelo de análise de sentimentos usando TensorFlow + Python.


Neste tutorial, também aprenderemos sobre os fundamentos do Machine Learning com Python e, como mencionado antes, seremos capazes de construir nosso próprio Machine Learning Model com Tensorflow, uma biblioteca Python. Este modelo será capaz de detectar o tom/emoção do texto de entrada , estudando e aprendendo com o conjunto de dados de amostra fornecido.
Pré-requisitos
Tudo o que precisamos é de algum conhecimento de Python (as coisas mais básicas, é claro) e também garantir que você tenha o Python instalado no seu sistema (Python 3.9+ é recomendado).
No entanto, se você achar difícil passar por este tutorial, não se preocupe! Envie-me um e-mail ou uma mensagem; entrarei em contato com você o mais rápido possível.
Caso você não saiba, o que é aprendizado de máquina?
Em termos simples, Machine Learning (ML) está fazendo o computador aprender e fazer previsões, estudando dados e estatísticas. Ao estudar os dados fornecidos, o computador pode identificar e extrair padrões e então fazer previsões com base neles. Identificação de e-mails de spam, reconhecimento de fala e previsão de tráfego são alguns casos de uso da vida real de Machine Learning.
Para um exemplo melhor, imagine que queremos ensinar um computador a reconhecer gatos em fotos. Você mostraria a ele muitas fotos de gatos e diria: "Ei, computador, estes são gatos!" O computador olha para as fotos e começa a notar padrões – como orelhas pontudas, bigodes e pelos. Depois de ver exemplos suficientes, ele pode reconhecer um gato em uma nova foto que ele não viu antes.


Um desses sistemas que aproveitamos todos os dias são os filtros de spam de e-mail. A imagem a seguir mostra como isso é feito.


Por que usar Python?
Embora a Linguagem de Programação Python não seja construída especificamente para ML ou Ciência de Dados, ela é considerada uma ótima linguagem de programação para ML devido à sua adaptabilidade. Com centenas de bibliotecas disponíveis para download gratuito, qualquer um pode facilmente construir modelos de ML usando uma biblioteca pré-construída sem a necessidade de programar o procedimento completo do zero.
TensorFlow é uma dessas bibliotecas construídas pelo Google para Machine Learning e Inteligência Artificial. TensorFlow é frequentemente usado por cientistas de dados, engenheiros de dados e outros desenvolvedores para construir modelos de machine learning facilmente, pois consiste em uma variedade de algoritmos de machine learning e IA.
Visite o site oficial do TensorFlow
Instalação
Para instalar o Tensorflow, execute o seguinte comando no seu terminal:
pip install tensorflowE para instalar o Pandas e o Numpy,
pip install pandas numpyBaixe o arquivo CSV de exemplo deste repositório: Repositório Github - Modelo TensorFlow ML
Compreendendo os dados
Regra nº 1 da análise de dados e de qualquer coisa que seja construída com base em dados: entenda primeiro os dados que você tem.
Neste caso, o conjunto de dados tem duas colunas: Texto e Sentimento. Enquanto a coluna "texto" tem uma variedade de declarações feitas sobre filmes, livros, etc., a coluna "sentimento" mostra se o texto é positivo, neutro ou negativo, usando os números 1, 2 e 0, respectivamente.
Preparação de dados
A próxima regra prática é limpar as duplicatas e remover valores nulos em seus dados de amostra. Mas, neste caso, como o conjunto de dados fornecido é bem pequeno e não contém duplicatas ou valores nulos, podemos pular o processo de limpeza de dados.


Para começar a construir o modelo, devemos reunir e preparar o conjunto de dados para treinar o modelo de análise de sentimento. Pandas, uma biblioteca popular para análise e manipulação de dados, pode ser usada para essa tarefa.
import pandas as pd # Load data from CSV data = pd.read_csv('sentiment.csv') # Change the path of downloaded CSV File accordingly # Text data and labels texts = data['text'].tolist() labels = data['sentiment'].values O código acima converte o arquivo CSV em um data frame, usando a função pandas.read_csv() . Em seguida, ele atribui os valores da coluna “sentiment” a uma lista Python usando a função tolist() e cria um array Numpy com os valores.
Por que usar um array Numpy?
Como você já deve saber, o Numpy é basicamente construído para manipulação de dados. Os arrays Numpy manipulam eficientemente rótulos numéricos para tarefas de aprendizado de máquina, o que oferece flexibilidade na organização de dados. É por isso que estamos usando o Numpy neste caso.
Processando Texto
Depois de preparar os dados de amostra, precisamos reprocessar o Texto, o que envolve Tokenização.
Tokenização é o processo de dividir cada amostra de texto em palavras ou tokens individuais, para que possamos converter os dados de texto brutos em um formato que pode ser processado pelo modelo , permitindo que ele entenda e aprenda com as palavras individuais nas amostras de texto.
Consulte a imagem abaixo para saber como funciona a tokenização.
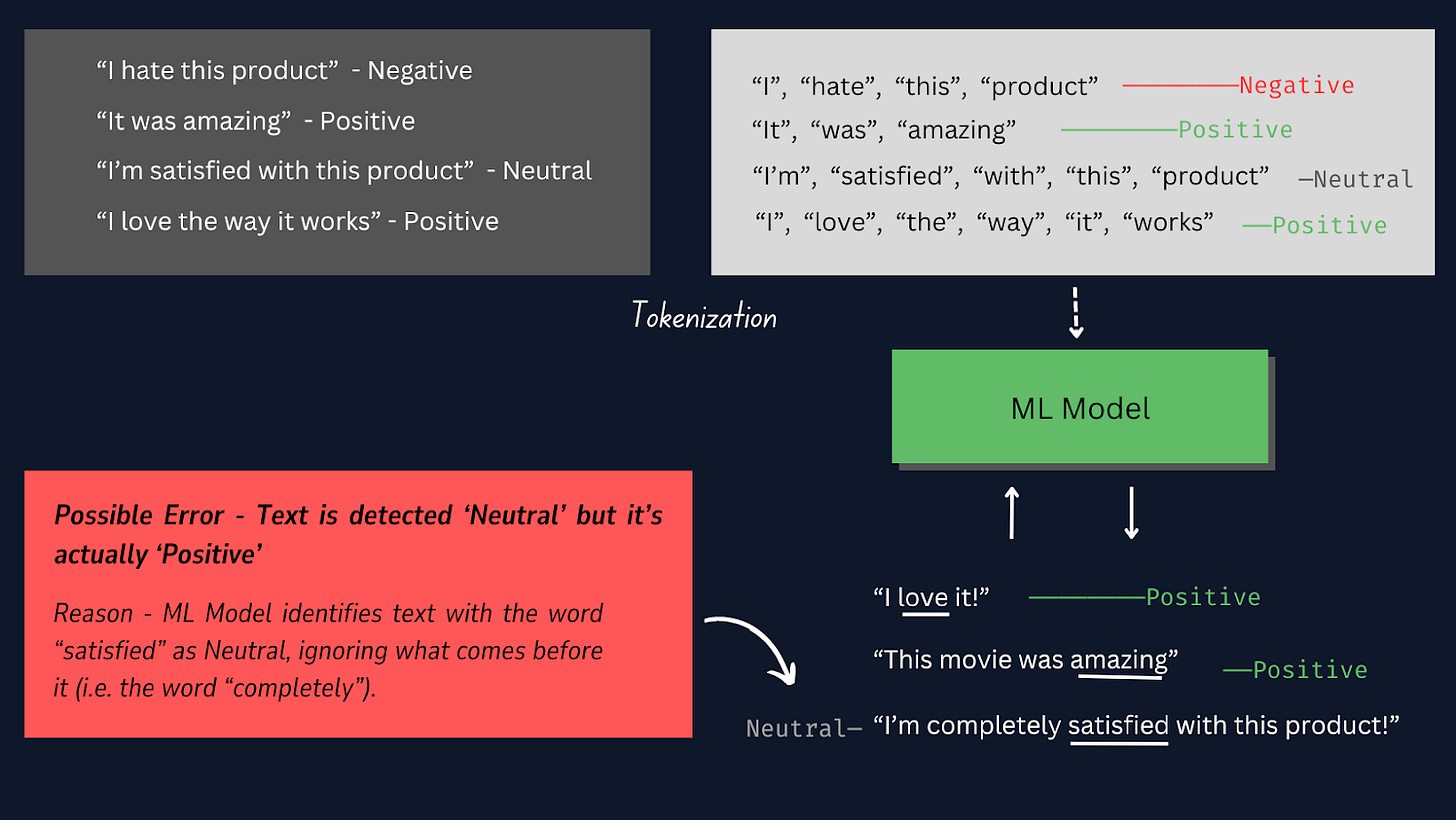
Neste projeto, é melhor usar a tokenização manual em vez de outros tokenizadores pré-criados, pois isso nos fornece mais controle sobre o processo de tokenização, garante compatibilidade com formatos de dados específicos e permite etapas de pré-processamento personalizadas.
Nota: Na Tokenização Manual, escrevemos código para dividir texto em palavras, o que é altamente personalizável de acordo com as necessidades do projeto. No entanto, outros métodos, como usar o TensorFlow Keras Tokenizer, vêm com ferramentas e funções prontas para dividir texto automaticamente, o que é mais fácil de implementar, mas menos personalizável.
A seguir está o trecho de código que podemos usar para tokenização de dados de amostra.
word_index = {} sequences = [] for text in texts: words = text.lower().split() sequence = [] for word in words: if word not in word_index: word_index[word] = len(word_index) + 1 sequence.append(word_index[word]) sequences.append(sequence)No código acima,
-
word_index: Um dicionário vazio criado para armazenar cada palavra única no conjunto de dados, juntamente com seu valor. -
sequences: Uma lista vazia que armazena as sequências de representação numérica de palavras para cada amostra de texto. -
for text in texts: percorre cada amostra de texto na lista “textos” (criada anteriormente). -
words = text.lower().split(): Converte cada amostra de texto em minúsculas e a divide em palavras individuais, com base nos espaços em branco. -
for word in words: Um loop aninhado que itera sobre cada palavra na lista “palavras”, que contém palavras tokenizadas dos exemplos de texto atuais. -
if word not in word_index: se a palavra não estiver presente no dicionário word_index, ela será adicionada a ele junto com um índice exclusivo, obtido adicionando 1 ao comprimento atual do dicionário. -
sequence. append (word_index[word]): Após determinar o índice da palavra atual, ela é anexada à lista “sequence”. Isso converte cada palavra na amostra de texto para seu índice correspondente com base no dicionário “word_index”. -
sequence.append(sequence): Depois que todas as palavras no exemplo de texto são convertidas em índices numéricos e armazenadas na lista “sequence”, esta lista é anexada à lista “sequences”.
Em resumo, o código acima tokeniza os dados de texto convertendo cada palavra em sua representação numérica com base no dicionário word_index , que mapeia palavras para índices exclusivos. Ele cria sequências de representações numéricas para cada amostra de texto, que podem ser usadas como dados de entrada para o modelo.
Arquitetura do modelo
A arquitetura de um determinado modelo é o arranjo de camadas, componentes e conexões que determinam como os dados fluem por ele . A arquitetura do modelo tem um impacto significativo na velocidade de treinamento, desempenho e capacidade de generalização do modelo.
Após processar os dados de entrada, podemos definir a arquitetura do modelo como no exemplo abaixo:
model = tf.keras.Sequential([ tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length), tf.keras.layers.LSTM(64), tf.keras.layers.Dense(3, activation='softmax') ])
No código acima, usamos o TensorFlow Keras, que é uma API de redes neurais de alto nível criada para experimentação e prototipagem rápidas de modelos de aprendizado profundo, simplificando o processo de construção e compilação de modelos de aprendizado de máquina.
-
tf. keras.Sequential(): Definindo um modelo sequencial, que é uma pilha linear de camadas. Os dados fluem da primeira camada para a última, em ordem. -
tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length): Esta camada é usada para incorporação de palavras, que converte palavras em vetores densos de tamanho fixo. O len(word_index) + 1 especifica o tamanho do vocabulário, 16 é a dimensionalidade da incorporação e input_length=max_length define o comprimento de entrada para cada sequência. -
tf.keras.layers.LSTM(64): Esta camada é uma camada Long Short-Term Memory (LSTM), que é um tipo de rede neural recorrente (RNN). Ela processa a sequência de embeddings de palavras e pode "lembrar" padrões ou dependências importantes nos dados. Ela tem 64 unidades, que determinam a dimensionalidade do espaço de saída. -
tf.keras.layers.Dense(3, activation='softmax'): Esta é uma camada densamente conectada com 3 unidades e uma função de ativação softmax. É a camada de saída do modelo, produzindo uma distribuição de probabilidade sobre as três classes possíveis (assumindo um problema de classificação multiclasse).


Compilação
No Machine Learning com TensorFlow, compilação se refere ao processo de configuração do modelo para treinamento especificando três componentes principais : Função de Perda, Otimizador e Métricas.
Função de perda : mede o erro entre as previsões do modelo e as metas reais, ajudando a orientar os ajustes do modelo.
Otimizador : ajusta os parâmetros do modelo para minimizar a função de perda, permitindo um aprendizado eficiente.
Métricas : Fornece avaliação de desempenho além da perda, como precisão ou exatidão, auxiliando na avaliação do modelo.

O código abaixo pode ser usado para compilar o Modelo de Análise de Sentimento:
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])Aqui,
loss='sparse_categorical_crossentropy': Uma função de perda é geralmente usada para tarefas de classificação, quer os rótulos de destino sejam inteiros e a saída do modelo seja uma distribuição de probabilidade sobre várias classes. Ela mede a diferença entre rótulos verdadeiros e previsões , visando minimizá-la durante o treinamento.optimizer='adam': Adam é um algoritmo de otimização que adapta a taxa de aprendizado dinamicamente durante o treinamento. É amplamente usado na prática por causa de sua eficiência, robustez e eficácia em uma ampla gama de tarefas quando comparado a outros otimizadores.metrics = ['accuracy']: A precisão é uma métrica comum frequentemente usada para avaliar modelos de classificação. Ela fornece uma medida direta do desempenho geral do modelo na tarefa, como a porcentagem de amostras para as quais as previsões do modelo correspondem aos rótulos verdadeiros.

Treinando o modelo
Agora que os dados de entrada estão processados e prontos e a arquitetura do modelo também está definida, podemos treinar o modelo usando o método model.fit() .
model.fit(padded_sequences, labels, epochs=15, verbose=1)padded_sequences: Os dados de entrada para treinar o modelo, que consiste em sequências das mesmas dimensões (o preenchimento será discutido mais adiante no tutorial).labels: rótulos de destino correspondentes aos dados de entrada (ou seja, categorias de sentimento atribuídas a cada amostra de texto)epochs=15: Uma época é uma passagem completa pelo conjunto de dados de treinamento completo durante o processo de treinamento. Consequentemente, neste programa, o modelo itera sobre o conjunto de dados completo 15 vezes durante o treinamento.
Quando o número de épocas é aumentado, ele potencialmente melhora o desempenho, pois aprende padrões mais complexos por meio das amostras de dados. No entanto, se muitas épocas forem usadas, o modelo pode memorizar dados de treinamento, levando (o que é chamado de “overfitting”) à generalização ruim de novos dados. O tempo consumido para treinamento também aumentará com o aumento do número de épocas e vice-versa.


verbose=1: Este é um parâmetro para controlar quanta saída o método de ajuste do modelo produz durante o treinamento. Um valor de 1 significa que as barras de progresso serão exibidas no console enquanto o modelo treina, 0 significa nenhuma saída e 2 significa uma linha por época. Como seria bom ver os valores de precisão e perda e o tempo gasto para cada época, definiremos como 1.
Fazendo previsões
Após a compilação e o treinamento do modelo, ele pode finalmente fazer previsões com base em nossos dados de amostra, simplesmente usando a função predict(). No entanto, precisamos inserir dados de entrada para testar o modelo e receber a saída. Para fazer isso, devemos inserir algumas declarações de texto e, em seguida, pedir ao modelo para prever o sentimento dos dados de entrada.
test_texts = ["The price was too high for the quality", "The interface is user-friendly", "I'm satisfied"] test_sequences = [] for text in test_texts: words = text.lower().split() sequence = [] for word in words: if word in word_index: sequence.append(word_index[word]) test_sequences.append(sequence) Aqui, test_texts armazena alguns dados de entrada enquanto a lista test_sequences é usada para armazenar dados de teste tokenizados, que são palavras divididas por espaços em branco após se transformarem em minúsculas. Mas ainda assim, test_sequences não será capaz de atuar como dados de entrada para o modelo.
O motivo é que muitas estruturas de aprendizado profundo, incluindo o Tensorflow, geralmente exigem que os dados de entrada tenham uma dimensão uniforme (o que significa que o comprimento de cada sequência deve ser igual), para processar lotes de dados de forma eficiente. Para conseguir isso, você pode usar técnicas como padding, onde as sequências são estendidas para corresponder ao comprimento das sequências mais longas no conjunto de dados, usando um token especial como # ou 0 (0, neste exemplo).
import numpy as np padded_test_sequences = [] for sequence in test_sequences: padded_sequence = sequence[:max_length] + [0] * (max_length - len(sequence)) padded_test_sequences.append(padded_sequence) # Convert to numpy array padded_test_sequences = np.array(padded_test_sequences)No código fornecido,
-
padded_test_sequences: Uma lista vazia para armazenar as sequências preenchidas que serão usadas para testar o modelo. -
for sequence in sequences: Percorre cada sequência na lista “sequências”. -
padded_sequence: Cria uma nova sequência preenchida para cada sequência, truncando a sequência original para os primeiros elementos max_length para garantir consistência. Então, estamos preenchendo a sequência com zeros para corresponder ao max_length se for mais curto, efetivamente tornando todas as sequências do mesmo comprimento. -
padded_test_sequences.append(): Adicione uma sequência preenchida à lista que será usada para testes. -
padded_sequences = np.array(): Convertendo a lista de sequências preenchidas em uma matriz Numpy.


Agora, como os dados de entrada estão prontos para uso, o modelo pode finalmente prever o sentimento dos textos de entrada.
predictions = model.predict(padded_test_sequences) # Print predicted sentiments for i, text in enumerate(test_texts): print(f"Text: {text}, Predicted Sentiment: {np.argmax(predictions[i])}") No código acima, o método model.predict() gera previsões para cada sequência de teste, produzindo uma matriz de probabilidades previstas para cada categoria de sentimento. Em seguida, ele itera por cada elemento test_texts e np.argmax(predictions[i]) retorna o índice da maior probabilidade na matriz de probabilidades previstas para a i-ésima amostra de teste. Esse índice corresponde à categoria de sentimento prevista com a maior probabilidade prevista para cada amostra de teste, o que significa que a melhor previsão feita é extraída e mostrada como a saída principal.
Notas Especiais *:* np.argmax() é uma função NumPy que encontra o índice do valor máximo em uma matriz. Neste contexto, np.argmax(predictions[i]) ajuda a determinar a categoria de sentimento com a maior probabilidade prevista para cada amostra de teste.
O programa agora está pronto para ser executado. Após compilar e treinar o modelo, o Machine Learning Model imprimirá suas previsões para os dados de entrada.


Na saída do modelo, podemos ver os valores como “Precisão” e “Perda” para cada Época. Como mencionado antes, Precisão é a porcentagem de previsões corretas do total de previsões. Quanto maior a precisão, melhor. Se a precisão for 1,0, o que significa 100%, significa que o modelo fez previsões corretas em todas as instâncias. Da mesma forma, 0,5 significa que o modelo fez previsões corretas metade do tempo, 0,25 significa previsão correta um quarto do tempo e assim por diante.
Perda , por outro lado, mostra o quão mal as previsões do modelo correspondem aos valores verdadeiros. O menor valor de perda significa um modelo melhor com menos número de erros, com o valor 0 sendo o valor de perda perfeito, pois isso significa que nenhum erro é cometido.
No entanto, não podemos determinar a precisão geral e a perda do modelo com os dados acima mostrados para cada Época. Para fazer isso, podemos avaliar o modelo usando o método assess() e imprimir sua Precisão e Perda.
evaluation = model.evaluate(padded_sequences, labels, verbose=0) # Extract loss and accuracy loss = evaluation[0] accuracy = evaluation[1] # Print loss and accuracy print("Loss:", loss) print("Accuracy:", accuracy)Saída:
Loss: 0.6483516097068787 Accuracy: 0.7058823704719543Assim, neste modelo, o valor de Perda é 0,6483, o que significa que o Modelo cometeu alguns erros. A precisão do modelo é de cerca de 70%, o que significa que as previsões feitas pelo modelo estão corretas mais da metade das vezes. No geral, este modelo pode ser considerado um modelo “ligeiramente bom”; no entanto, observe que os valores “bons” de perda e precisão dependem muito do tipo de modelo, do tamanho do conjunto de dados e do propósito de um determinado Modelo de Aprendizado de Máquina.
E sim, podemos e devemos melhorar as métricas acima do modelo por meio de processos de ajuste fino e melhores conjuntos de dados de amostra. No entanto, para o propósito deste tutorial, vamos parar por aqui. Se você quiser uma segunda parte deste tutorial, por favor, me avise!
Resumo
Neste tutorial, construímos um modelo de aprendizado de máquina do TensorFlow com a capacidade de prever o sentimento de um determinado texto, após analisar o conjunto de dados de amostra.
O código completo e o arquivo CSV de amostra podem ser baixados e visualizados no repositório GitHub - GitHub - Buzzpy/Tensorflow-ML-Model








