
























こんにちは、皆さん!今のところ私にとってはバグだらけですが、2025 年が皆さんにとって良い年でありますように。
Doodles and Programming ブログへようこそ。今日は、TensorFlow + Python を使用して感情分析モデルを構築します。


このチュートリアルでは、Python を使用した機械学習の基礎についても学習します。また、前述のように、Python ライブラリである Tensorflow を使用して独自の機械学習モデルを構築できるようになります。このモデルは、提供されているサンプル データセットを学習して、入力テキストのトーンや感情を検出できるようになります。
前提条件
必要なのは、Python に関する知識 (もちろん最も基本的な知識) だけです。また、システムに Python がインストールされていることを確認してください (Python 3.9 以上が推奨されます)。
ただし、このチュートリアルを実行するのが難しいと感じても、心配しないでください。メールまたはメッセージを送ってください。できるだけ早く返信します。
ご存知ない方のために、機械学習とは何でしょうか?
簡単に言えば、機械学習 (ML) とは、データと統計を研究することで、コンピューターに学習と予測を行わせることです。提供されたデータを研究することで、コンピューターはパターンを識別して抽出し、それに基づいて予測を行うことができます。スパムメールの識別、音声認識、トラフィックの予測などは、機械学習の実際の使用例の一部です。
もっと良い例として、写真に写っている猫をコンピューターに認識させるとします。コンピューターにたくさんの猫の写真を見せて、「ねえ、コンピューター、これは猫だよ!」と言います。コンピューターは写真を見て、尖った耳、ひげ、毛皮などのパターンに気づき始めます。十分な例を見ると、コンピューターはこれまで見たことのない新しい写真に写っている猫を認識できるようになります。


私たちが毎日利用しているシステムの 1 つが、電子メールのスパム フィルターです。次の図は、その仕組みを示しています。


Python を使用する理由は何ですか?
Python プログラミング言語は ML やデータ サイエンス専用に構築されたものではありません。しかし、その適応性により、ML に最適なプログラミング言語と考えられています。何百ものライブラリが無料でダウンロードできるため、完全な手順を最初からプログラムする必要なく、事前に構築されたライブラリを使用して誰でも簡単に ML モデルを構築できます。
TensorFlow は、Google が機械学習と人工知能向けに構築したライブラリの 1 つです。TensorFlow はさまざまな機械学習および AI アルゴリズムで構成されているため、データ サイエンティスト、データ エンジニア、その他の開発者が機械学習モデルを簡単に構築するためによく使用されます。
インストール
Tensorflow をインストールするには、ターミナルで次のコマンドを実行します。
pip install tensorflowPandasとNumpyをインストールするには、
pip install pandas numpyサンプル CSV ファイルをこのリポジトリからダウンロードしてください: Github リポジトリ - TensorFlow ML モデル
データの理解
データ分析とデータに基づいて構築されるものすべてにおける第一のルール: まず、持っているデータを理解すること。
この場合、データセットにはテキストと感情の 2 つの列があります。「テキスト」列には映画や本などに関するさまざまな発言が含まれますが、「感情」列にはテキストが肯定的、中立的、否定的のいずれであるかが、それぞれ 1、2、0 の数字で示されます。
データ準備
次の経験則は、サンプル データ内の重複を消去し、null 値を削除することです。ただし、この場合、指定されたデータセットはかなり小さく、重複や null 値が含まれていないため、データ消去プロセスをスキップできます。


モデルの構築を開始するには、感情分析モデルをトレーニングするためのデータセットを収集して準備する必要があります。このタスクには、データ分析と操作のための一般的なライブラリである Pandas を使用できます。
import pandas as pd # Load data from CSV data = pd.read_csv('sentiment.csv') # Change the path of downloaded CSV File accordingly # Text data and labels texts = data['text'].tolist() labels = data['sentiment'].values上記のコードは、関数pandas.read_csv()を使用して CSV ファイルをデータ フレームに変換します。次に、 tolist()関数を使用して「sentiment」列の値を Python リストに割り当て、値を含む Numpy 配列を作成します。
Numpy 配列を使用する理由は何ですか?
すでにご存知かもしれませんが、Numpy は基本的にデータ操作用に構築されています。Numpy 配列は機械学習タスクの数値ラベルを効率的に処理し、データ編成に柔軟性をもたらします。そのため、この場合は Numpy を使用しています。
テキスト処理
サンプルデータを準備した後、トークン化を伴うテキストを再処理する必要があります。
トークン化とは、各テキスト サンプルを個別の単語またはトークンに分割するプロセスです。これにより、生のテキスト データをモデルが処理できる形式に変換し、テキスト サンプル内の個別の単語を理解して学習できるようになります。
トークン化の仕組みについては、下の画像を参照してください。
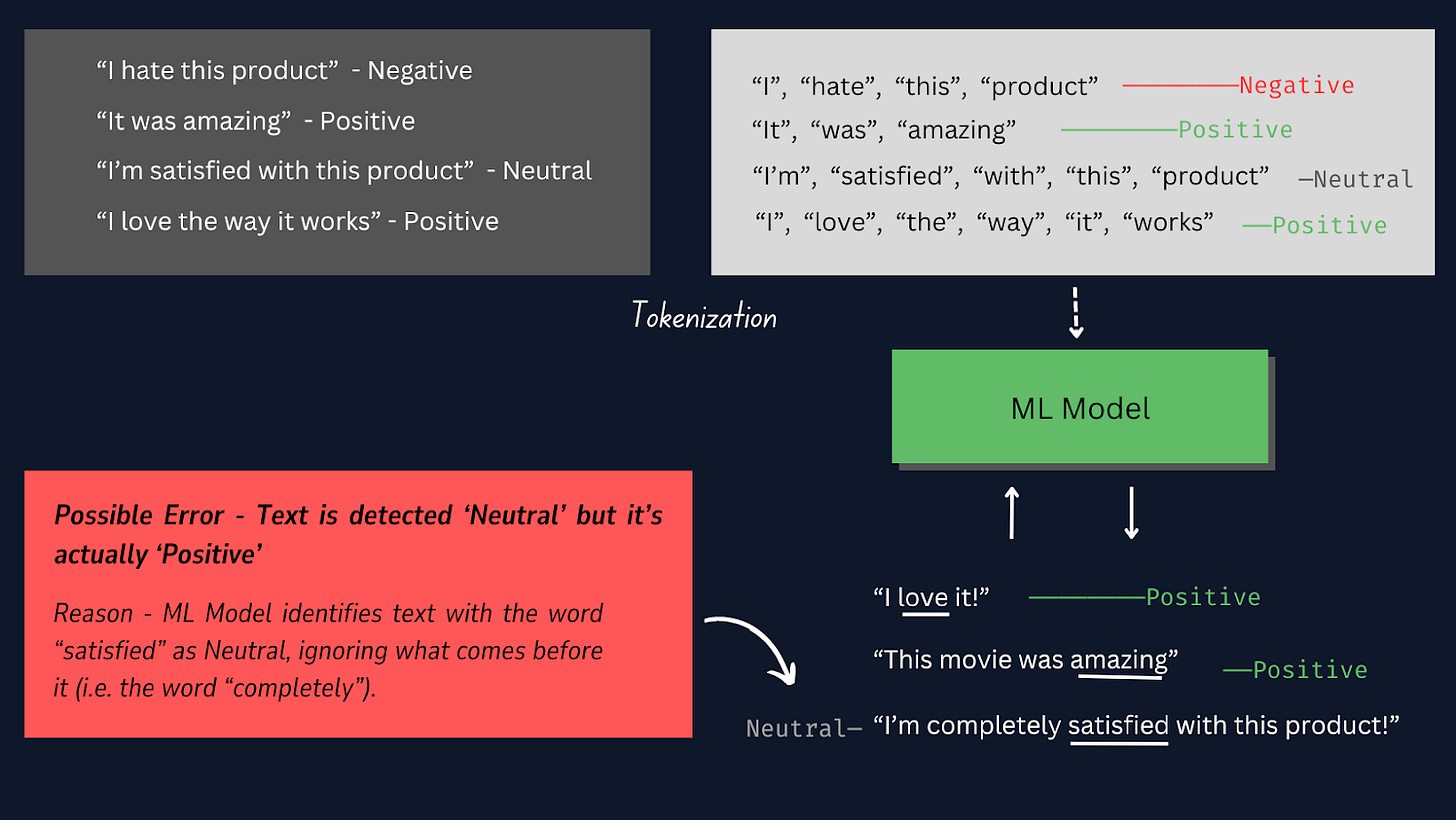
このプロジェクトでは、他の事前に構築されたトークナイザーの代わりに手動のトークン化を使用するのが最適です。これにより、トークン化プロセスをより細かく制御でき、特定のデータ形式との互換性が確保され、カスタマイズされた前処理手順が可能になります。
注: 手動トークン化では、テキストを単語に分割するコードを記述します。これは、プロジェクトのニーズに応じて高度にカスタマイズできます。ただし、TensorFlow Keras Tokenizer を使用するなどの他の方法では、テキストを自動的に分割するための既製のツールと関数が付属しており、実装は簡単ですが、カスタマイズ性は低くなります。
以下は、サンプル データのトークン化に使用できるコード スニペットです。
word_index = {} sequences = [] for text in texts: words = text.lower().split() sequence = [] for word in words: if word not in word_index: word_index[word] = len(word_index) + 1 sequence.append(word_index[word]) sequences.append(sequence)上記のコードでは、
-
word_index: データセット内の各一意の単語とその値を格納するために作成された空の辞書。 -
sequences: 各テキスト サンプルの単語の数値表現のシーケンスを格納する空のリスト。 -
for text in texts: 「texts」リスト(以前に作成)内の各テキスト サンプルをループします。 -
words = text.lower().split(): 各テキストサンプルを小文字に変換し、空白に基づいて個々の単語に分割します。 -
for word in words: 現在のテキスト サンプルからトークン化された単語を含む「words」リスト内の各単語を反復処理するネストされたループ。 -
if word not in word_index: 単語が現在 word_index 辞書に存在しない場合は、辞書の現在の長さに 1 を加えて得られる一意のインデックスとともに単語が追加されます。 -
sequence. append (word_index[word]): 現在の単語のインデックスを決定した後、それを「シーケンス」リストに追加します。これにより、テキストサンプル内の各単語が「word_index」辞書に基づいて対応するインデックスに変換されます。 -
sequence.append(sequence): テキストサンプル内のすべての単語が数値インデックスに変換され、「sequence」リストに格納された後、このリストが「sequences」リストに追加されます。
要約すると、上記のコードは、単語を一意のインデックスにマッピングする辞書word_indexに基づいて各単語を数値表現に変換することにより、テキスト データをトークン化します。各テキスト サンプルの数値表現のシーケンスを作成し、これをモデルの入力データとして使用できます。
モデルアーキテクチャ
特定のモデルのアーキテクチャとは、データがどのように流れるかを決定するレイヤー、コンポーネント、接続の配置です。モデルのアーキテクチャは、モデルのトレーニング速度、パフォーマンス、一般化能力に大きな影響を与えます。
入力データを処理した後、次の例のようにモデルのアーキテクチャを定義できます。
model = tf.keras.Sequential([ tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length), tf.keras.layers.LSTM(64), tf.keras.layers.Dense(3, activation='softmax') ])
上記のコードでは、機械学習モデルの構築とコンパイルのプロセスを簡素化することで、ディープラーニング モデルの迅速な実験とプロトタイピングのために構築された高レベルのニューラル ネットワーク API である TensorFlow Keras を使用しています。
-
tf. keras.Sequential(): レイヤーの線形スタックであるシーケンシャル モデルを定義します。データは最初のレイヤーから最後のレイヤーまで順番に流れます。 -
tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length): このレイヤーは単語埋め込みに使用され、単語を固定サイズの密なベクトルに変換します。len(word_index) + 1 は語彙のサイズを指定し、16 は埋め込みの次元であり、input_length=max_length は各シーケンスの入力長を設定します。 -
tf.keras.layers.LSTM(64): このレイヤーは Long Short-Term Memory (LSTM) レイヤーで、リカレント ニューラル ネットワーク (RNN) の一種です。単語埋め込みのシーケンスを処理し、データ内の重要なパターンや依存関係を「記憶」できます。出力空間の次元を決定する 64 個のユニットがあります。 -
tf.keras.layers.Dense(3, activation='softmax'): これは、3 つのユニットとソフトマックス活性化関数を持つ密に接続されたレイヤーです。これはモデルの出力レイヤーであり、3 つの可能なクラス (多クラス分類問題を想定) にわたる確率分布を生成します。


コンパイル
TensorFlow を使用した機械学習では、コンパイルとは、損失関数、オプティマイザー、メトリックという 3 つの主要コンポーネントを指定して、トレーニング用にモデルを構成するプロセスを指します。
損失関数: モデルの予測と実際のターゲット間の誤差を測定し、モデルの調整に役立ちます。
オプティマイザー: モデルのパラメータを調整して損失関数を最小限に抑え、効率的な学習を可能にします。
メトリクス: 精度や精密度など、損失を超えたパフォーマンス評価を提供し、モデル評価に役立ちます。

以下のコードを使用して、感情分析モデルをコンパイルできます。
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])ここ、
loss='sparse_categorical_crossentropy': 損失関数は、ターゲット ラベルが整数で、モデルの出力が複数のクラスにわたる確率分布であるかどうかに関係なく、分類タスクに一般的に使用されます。これは、トレーニング中に最小化することを目的として、実際のラベルと予測の差を測定します。optimizer='adam': Adam は、トレーニング中に学習率を動的に調整する最適化アルゴリズムです。他のオプティマイザーと比較して、幅広いタスクにわたって効率性、堅牢性、有効性が高いため、実際に広く使用されています。metrics = ['accuracy']: 精度は、分類モデルを評価するためによく使用される一般的なメトリックです。モデルの予測が実際のラベルと一致するサンプルの割合として、タスクにおけるモデルの全体的なパフォーマンスの直接的な測定値を提供します。

モデルのトレーニング
入力データが処理されて準備が整い、モデルのアーキテクチャも定義されたので、 model.fit()メソッドを使用してモデルをトレーニングできます。
model.fit(padded_sequences, labels, epochs=15, verbose=1)padded_sequences: モデルをトレーニングするための入力データ。同じ次元のシーケンスで構成されます (パディングについてはチュートリアルの後半で説明します)。labels: 入力データに対応するターゲットラベル(つまり、各テキストサンプルに割り当てられた感情カテゴリ)epochs=15: エポックとは、トレーニング プロセス中にトレーニング データセット全体を 1 回完全に通過することです。したがって、このプログラムでは、モデルはトレーニング中にデータセット全体を 15 回繰り返します。
エポック数を増やすと、データ サンプルを通じてより複雑なパターンを学習するため、パフォーマンスが向上する可能性があります。ただし、エポック数が多すぎると、モデルがトレーニング データを記憶してしまい、新しいデータの一般化が不十分になる可能性があります (「オーバーフィッティング」と呼ばれます)。エポック数が増えると、トレーニングにかかる時間も長くなりますが、その逆も同様です。


verbose=1: これは、モデルの適合メソッドがトレーニング中に生成する出力の量を制御するためのパラメーターです。値が 1 の場合、モデルのトレーニング中にコンソールに進行状況バーが表示されます。0 の場合、出力はありません。2 の場合、エポックごとに 1 行が表示されます。精度と損失の値、および各エポックにかかる時間を確認できると便利なので、1 に設定します。
予測を立てる
モデルのコンパイルとトレーニングが終わると、predict() 関数を使用するだけで、サンプル データに基づいて予測を行うことができます。ただし、モデルをテストして出力を受け取るには、入力データを入力する必要があります。そのためには、テキスト ステートメントをいくつか入力し、モデルに入力データの感情を予測するように依頼する必要があります。
test_texts = ["The price was too high for the quality", "The interface is user-friendly", "I'm satisfied"] test_sequences = [] for text in test_texts: words = text.lower().split() sequence = [] for word in words: if word in word_index: sequence.append(word_index[word]) test_sequences.append(sequence)ここで、 test_texts入力データを格納し、 test_sequencesリストはトークン化されたテスト データ (小文字に変換された後に空白で区切られた単語) を格納するために使用されます。ただし、それでもtest_sequencesモデルの入力データとして機能することはできません。
その理由は、Tensorflow を含む多くのディープラーニング フレームワークでは、通常、データのバッチを効率的に処理するために、入力データの次元が均一であること (つまり、すべてのシーケンスの長さが等しいこと) が求められるためです。これを実現するには、パディングなどの手法を使用できます。パディングでは、# や 0 (この例では 0) などの特別なトークンを使用して、データセット内の最長シーケンスの長さに合わせてシーケンスを拡張します。
import numpy as np padded_test_sequences = [] for sequence in test_sequences: padded_sequence = sequence[:max_length] + [0] * (max_length - len(sequence)) padded_test_sequences.append(padded_sequence) # Convert to numpy array padded_test_sequences = np.array(padded_test_sequences)与えられたコードでは、
-
padded_test_sequences: モデルのテストに使用されるパディングされたシーケンスを格納するための空のリスト。 -
for sequence in sequences: 「sequences」リスト内の各シーケンスをループします。 -
padded_sequence: 各シーケンスに対して新しいパディングされたシーケンスを作成し、一貫性を確保するために元のシーケンスを最初の max_length 要素に切り捨てます。次に、max_length が短い場合はそれに一致するようにシーケンスにゼロをパディングして、すべてのシーケンスを実質的に同じ長さにします。 -
padded_test_sequences.append(): テストに使用するリストにパディングされたシーケンスを追加します。 -
padded_sequences = np.array(): パディングされたシーケンスのリストを Numpy 配列に変換します。


これで、入力データが使用できる状態になったので、モデルは最終的に入力テキストの感情を予測できるようになりました。
predictions = model.predict(padded_test_sequences) # Print predicted sentiments for i, text in enumerate(test_texts): print(f"Text: {text}, Predicted Sentiment: {np.argmax(predictions[i])}")上記のコードでは、 model.predict()メソッドが各テスト シーケンスの予測を生成し、各感情カテゴリの予測確率の配列を生成します。次に、各test_texts要素を反復処理し、 np.argmax(predictions[i]) i 番目のテスト サンプルの予測確率配列の最高確率のインデックスを返します。このインデックスは、各テスト サンプルの予測確率が最も高い予測感情カテゴリに対応しており、最も優れた予測が抽出され、メイン出力として表示されます。
特記事項*:* np.argmax()配列内の最大値のインデックスを見つける NumPy 関数です。このコンテキストでは、 np.argmax(predictions[i])各テスト サンプルの予測確率が最も高い感情カテゴリを決定するのに役立ちます。
これでプログラムを実行する準備が整いました。モデルをコンパイルしてトレーニングした後、機械学習モデルは入力データに対する予測を出力します。


モデルの出力では、各エポックの「精度」と「損失」の値を確認できます。前述のように、精度は、予測全体のうちの正しい予測の割合です。精度が高いほど優れています。精度が 1.0 (100%) の場合、モデルはすべてのインスタンスで正しい予測を行ったことを意味します。同様に、0.5 はモデルが半分の時間で正しい予測を行ったことを意味し、0.25 は 4 分の 1 の時間で正しい予測を行ったことを意味します。
一方、損失は、モデルの予測が実際の値とどの程度一致していないかを示します。損失値が小さいほど、エラー数が少ない優れたモデルであることを意味し、値 0 はエラーが発生していないことを意味する完璧な損失値です。
ただし、各エポックに表示された上記のデータでは、モデルの全体的な精度と損失を判断することはできません。これを行うには、evaluate() メソッドを使用してモデルを評価し、その精度と損失を出力します。
evaluation = model.evaluate(padded_sequences, labels, verbose=0) # Extract loss and accuracy loss = evaluation[0] accuracy = evaluation[1] # Print loss and accuracy print("Loss:", loss) print("Accuracy:", accuracy)出力:
Loss: 0.6483516097068787 Accuracy: 0.7058823704719543したがって、このモデルでは、損失値は 0.6483 であり、モデルが何らかのエラーを犯したことを意味します。モデルの精度は約 70% であり、モデルによる予測が半分以上の確率で正しいことを意味します。全体的に、このモデルは「やや良い」モデルと見なすことができます。ただし、「良い」損失と精度の値は、モデルの種類、データセットのサイズ、および特定の機械学習モデルの目的によって大きく異なることに注意してください。
はい、プロセスを微調整し、サンプル データセットを改善することで、モデルの上記のメトリックを改善できますし、改善する必要があります。ただし、このチュートリアルでは、ここで止めておきましょう。このチュートリアルのパート 2 をご希望の場合は、ぜひお知らせください。
まとめ
このチュートリアルでは、サンプル データセットを分析した後、特定のテキストの感情を予測する機能を備えた TensorFlow 機械学習モデルを構築しました。
完全なコードとサンプル CSV ファイルは、GitHub リポジトリ - GitHub - Buzzpy/Tensorflow-ML-Modelからダウンロードして確認できます。








