
























Salam gözəl insanlar! Ümid edirəm ki, 2025-ci il sizinlə yaxşı rəftar edir, baxmayaraq ki, bu günə qədər mənim üçün çətin idi.
Doodles və Proqramlaşdırma bloquna xoş gəlmisiniz və bu gün biz quracağıq: TensorFlow + Python istifadə edərək hiss analizi modeli.


Bu dərslikdə biz Python ilə Maşın Öyrənmənin əsasları haqqında da öyrənəcəyik və əvvəllər qeyd edildiyi kimi, Python kitabxanası olan Tensorflow ilə öz Maşın Öyrənmə Modelimizi qura biləcəyik. Bu model təqdim edilmiş nümunə verilənlər toplusunu öyrənmək və öyrənməklə daxil edilən mətnin tonunu/emosiyasını aşkar edə biləcək.
İlkin şərtlər
Bizə lazım olan tək şey Python haqqında bir az bilikdir (əlbəttə ki, ən əsas şeylər) və həmçinin sisteminizdə Python quraşdırıldığından əmin olun (Python 3.9+ tövsiyə olunur).
Bununla belə, bu dərsliyi keçmək sizə çətin gəlirsə, narahat olmayın! Mənə e-poçt və ya mesaj göndərin; Mən sizə ən qısa zamanda qayıdacağam.
Əgər bilmirsinizsə, Machine Learning nədir?
Sadə dillə desək, Machine Learning (ML) məlumatları və statistikanı öyrənməklə kompüteri öyrənməyə və proqnozlar verməyə məcbur edir. Təqdim olunan məlumatları öyrənməklə, kompüter nümunələri müəyyən edə və çıxara bilər və sonra onların əsasında proqnozlar verə bilər. Spam E-poçtların müəyyən edilməsi, nitqin tanınması və trafikin proqnozlaşdırılması Maşın Öyrənməsinin bəzi real həyatda istifadə hallarıdır.
Daha yaxşı bir nümunə üçün, kompüterə fotoşəkillərdə pişikləri tanımağı öyrətmək istədiyimizi təsəvvür edin. Siz ona çoxlu pişik şəkillərini göstərib: "Hey, kompüter, bunlar pişikdir!" Kompüter şəkillərə baxır və sivri qulaqlar, bığlar və xəz kimi naxışları görməyə başlayır. Kifayət qədər nümunə gördükdən sonra, daha əvvəl görmədiyi yeni bir fotoşəkildə bir pişiyi tanıya bilər.


Hər gün istifadə etdiyimiz sistemlərdən biri də e-poçt spam filtrləridir. Aşağıdakı şəkil bunun necə edildiyini göstərir.


Niyə Python istifadə edirsiniz?
Python Proqramlaşdırma Dili xüsusi olaraq ML və ya Data Science üçün qurulmasa da, uyğunlaşma qabiliyyətinə görə ML üçün əla proqramlaşdırma dili hesab olunur. Pulsuz yükləmək üçün mövcud olan yüzlərlə kitabxana ilə hər kəs tam proseduru sıfırdan proqramlaşdırmağa ehtiyac olmadan əvvəlcədən qurulmuş kitabxanadan istifadə edərək asanlıqla ML modelləri qura bilər.
TensorFlow, Maşın Öyrənməsi və Süni İntellekt üçün Google tərəfindən qurulmuş belə bir kitabxanadır. TensorFlow tez-tez məlumat alimləri, məlumat mühəndisləri və digər tərtibatçılar tərəfindən maşın öyrənmə modellərini asanlıqla qurmaq üçün istifadə olunur, çünki o, müxtəlif maşın öyrənməsi və AI alqoritmlərindən ibarətdir.
Rəsmi TensorFlow Veb saytına daxil olun
Quraşdırma
Tensorflow quraşdırmaq üçün terminalınızda aşağıdakı əmri işlədin:
pip install tensorflowPandas və Numpy quraşdırmaq üçün,
pip install pandas numpyLütfən, nümunə CSV faylını bu depodan endirin: Github Repository - TensorFlow ML Model
Məlumatların başa düşülməsi
Məlumatların təhlili və verilənlər üzərində qurulan hər şeyin №1 qaydası: Əvvəlcə əldə etdiyiniz məlumatları anlayın.
Bu halda verilənlər dəstinin iki sütunu var: Mətn və Hiss. “Mətn” sütununda filmlər, kitablar və s. haqqında edilən müxtəlif ifadələr olsa da, “sentiment” sütunu müvafiq olaraq 1, 2 və 0 rəqəmlərindən istifadə edərək mətnin müsbət, neytral və ya mənfi olduğunu göstərir.
Məlumatların hazırlanması
Növbəti əsas qayda dublikatları təmizləmək və nümunə məlumatlarınızdakı null dəyərləri silməkdir. Lakin bu halda, verilmiş verilənlər toplusu kifayət qədər kiçik olduğundan və dublikatları və ya sıfır dəyərləri ehtiva etmədiyi üçün biz məlumatların təmizlənməsi prosesini keçə bilərik.


Modeli qurmağa başlamaq üçün hiss analizi modelini öyrətmək üçün məlumat dəstini toplamalı və hazırlamalıyıq. Məlumatların təhlili və manipulyasiyası üçün məşhur kitabxana olan Pandas bu iş üçün istifadə edilə bilər.
import pandas as pd # Load data from CSV data = pd.read_csv('sentiment.csv') # Change the path of downloaded CSV File accordingly # Text data and labels texts = data['text'].tolist() labels = data['sentiment'].values Yuxarıdakı kod pandas.read_csv() funksiyasından istifadə edərək CSV faylını verilənlər çərçivəsinə çevirir. Sonra, o, tolist() funksiyasından istifadə edərək, “sentiment” sütununun dəyərlərini Python siyahısına təyin edir və dəyərlərlə Numpy massivi yaradır.
Niyə Numpy massivindən istifadə etməlisiniz?
Artıq bildiyiniz kimi, Numpy əsasən məlumatların manipulyasiyası üçün qurulmuşdur . Numpy massivləri məlumatların təşkilində çeviklik təklif edən maşın öyrənmə tapşırıqları üçün ədədi etiketləri səmərəli şəkildə idarə edir . Buna görə də bu vəziyyətdə Numpy-dən istifadə edirik.
Mətn emalı
Nümunə məlumatları hazırladıqdan sonra Tokenizasiyanı əhatə edən Mətni yenidən emal etməliyik.
Tokenləşdirmə hər bir mətn nümunəsinin fərdi sözlərə və ya işarələrə bölünməsi prosesidir ki, biz xam mətn məlumatlarını model tərəfindən emal oluna bilən formata çevirə bilək, mətn nümunələrindəki ayrı-ayrı sözləri başa düşməyə və öyrənməyə imkan verək. .
Tokenizasiyanın necə işlədiyini öyrənmək üçün aşağıdakı şəkilə baxın.
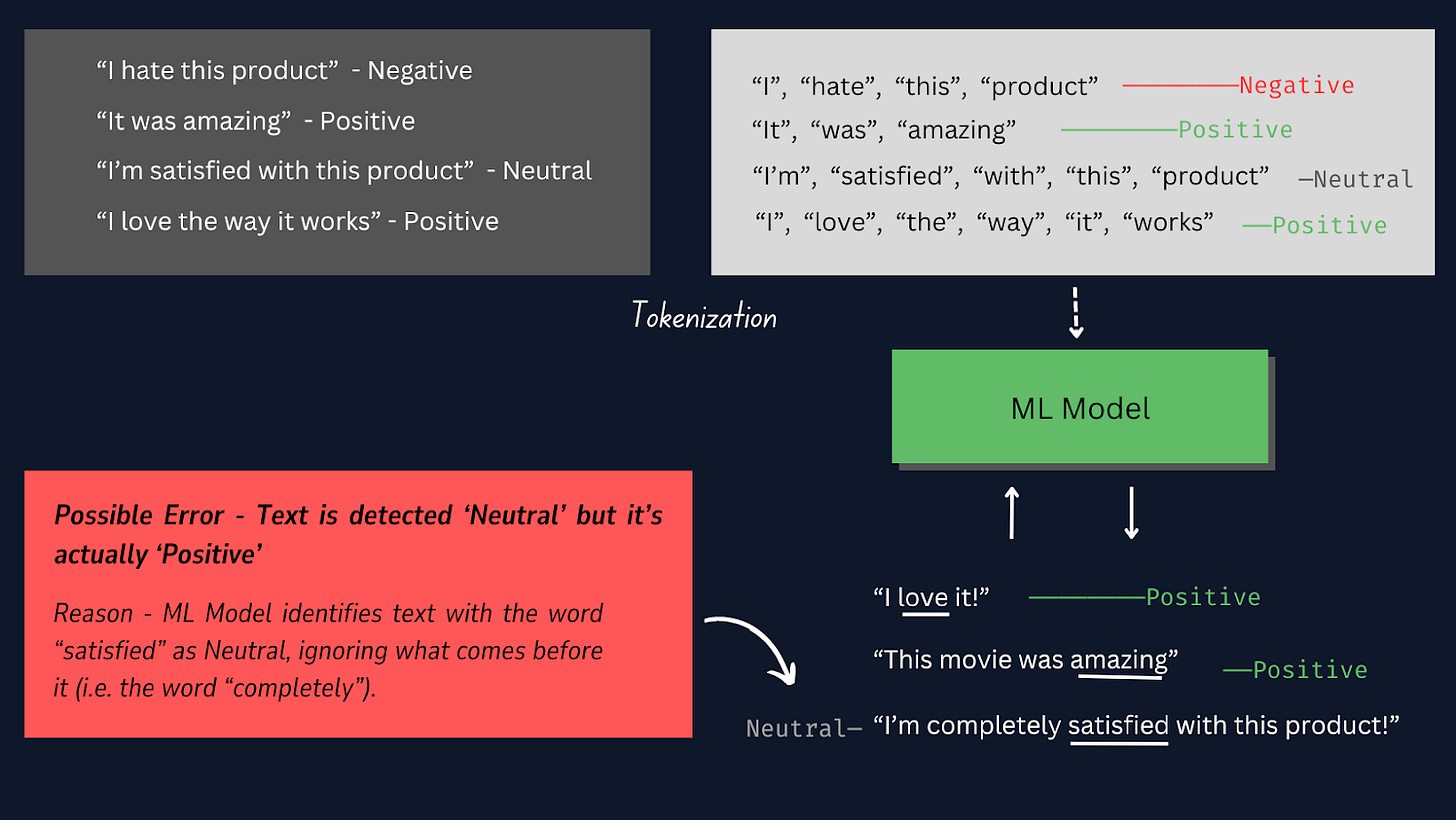
Bu layihədə, əvvəlcədən qurulmuş digər tokenizatorlar əvəzinə əl ilə tokenizasiyadan istifadə etmək daha yaxşıdır, çünki o, bizə tokenləşdirmə prosesi üzərində daha çox nəzarəti təmin edir, xüsusi məlumat formatları ilə uyğunluğu təmin edir və uyğunlaşdırılmış qabaqcadan emal addımlarına imkan verir.
Qeyd: Manual Tokenization-da biz mətni sözlərə bölmək üçün kod yazırıq ki, bu da layihənin ehtiyaclarına uyğun olaraq yüksək səviyyədə fərdiləşdirilə bilər. Bununla belə, TensorFlow Keras Tokenizer-dən istifadə kimi digər üsullar mətni avtomatik bölmək üçün hazır alətlər və funksiyalarla gəlir ki, bu da həyata keçirilməsi daha asan, lakin daha az fərdiləşdirilə bilər.
Aşağıda nümunə məlumatların tokenləşdirilməsi üçün istifadə edə biləcəyimiz kod parçası verilmişdir.
word_index = {} sequences = [] for text in texts: words = text.lower().split() sequence = [] for word in words: if word not in word_index: word_index[word] = len(word_index) + 1 sequence.append(word_index[word]) sequences.append(sequence)Yuxarıdakı kodda,
-
word_index: Datasetdə hər bir unikal sözü dəyəri ilə birlikdə saxlamaq üçün yaradılmış boş lüğət. -
sequences: Hər mətn nümunəsi üçün sözlərin ədədi təmsil ardıcıllığını saxlayan boş siyahı. -
for text in texts: “mətnlər” siyahısında (əvvəllər yaradılmış) hər bir mətn nümunəsi arasında dövr edir. -
words = text.lower().split(): Hər mətn nümunəsini kiçik hərflərə çevirir və boşluğa əsaslanaraq onu fərdi sözlərə bölür. -
for word in words: Cari mətn nümunələrindən işarələnmiş sözləri ehtiva edən “sözlər” siyahısındakı hər bir sözün üzərində təkrarlanan daxili dövrə. -
if word not in word_index: Əgər söz hazırda word_index lüğətində mövcud deyilsə, lüğətin cari uzunluğuna 1 əlavə etməklə əldə edilən unikal indekslə birlikdə ona əlavə edilir. -
sequence. append (word_index[word]): Cari sözün indeksini təyin etdikdən sonra o, “ardıcıllıq” siyahısına əlavə olunur. Bu, mətn nümunəsindəki hər bir sözü “word_index” lüğətinə əsaslanan müvafiq indeksinə çevirir. -
sequence.append(sequence): Mətn nümunəsindəki bütün sözlər ədədi indekslərə çevrildikdən və “ardıcıllıq” siyahısında saxlandıqdan sonra bu siyahı “ardıcıllıqlar” siyahısına əlavə olunur.
Xülasə olaraq, yuxarıdakı kod sözləri unikal indekslərə uyğunlaşdıran word_index lüğəti əsasında hər bir sözü öz ədədi təsvirinə çevirərək mətn məlumatlarını tokenləşdirir. O, hər bir mətn nümunəsi üçün ədədi təsvirlərin ardıcıllığını yaradır, bunlardan model üçün giriş məlumatları kimi istifadə edilə bilər.
Model Memarlıq
Müəyyən bir modelin arxitekturası məlumatların ondan necə axdığını müəyyən edən təbəqələrin, komponentlərin və əlaqələrin təşkilidir . Modelin arxitekturası modelin təlim sürətinə, performansına və ümumiləşdirmə qabiliyyətinə əhəmiyyətli dərəcədə təsir göstərir.
Giriş məlumatlarını emal etdikdən sonra modelin arxitekturasını aşağıdakı nümunədə olduğu kimi təyin edə bilərik:
model = tf.keras.Sequential([ tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length), tf.keras.layers.LSTM(64), tf.keras.layers.Dense(3, activation='softmax') ])
Yuxarıdakı kodda biz maşın öyrənmə modellərinin qurulması və tərtibi prosesini sadələşdirməklə Dərin Öyrənmə modellərinin sürətli eksperimenti və prototiplənməsi üçün qurulmuş yüksək səviyyəli neyron şəbəkələri API olan TensorFlow Keras-dan istifadə edirik.
-
tf. keras.Sequential(): Qatların xətti yığını olan ardıcıl modelin müəyyən edilməsi. Məlumat ardıcıl olaraq birinci təbəqədən sonuncuya axır. -
tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length): Bu təbəqə sözləri sabit ölçülü sıx vektorlara çevirən sözün daxil edilməsi üçün istifadə olunur. len(word_index) + 1 lüğət ölçüsünü təyin edir, 16 yerləşdirmənin ölçülüyüdür və input_length=max_length hər ardıcıllıq üçün giriş uzunluğunu təyin edir. -
tf.keras.layers.LSTM(64): Bu təbəqə təkrarlanan neyron şəbəkəsinin (RNN) bir növü olan Uzun Qısamüddətli Yaddaş (LSTM) qatıdır. O, sözlərin yerləşdirilməsi ardıcıllığını emal edir və verilənlərdəki mühüm nümunələri və ya asılılıqları "xatırlaya" bilir. Çıxış sahəsinin ölçüsünü təyin edən 64 ədəd var. -
tf.keras.layers.Dense(3, activation='softmax'): Bu, 3 vahid və softmax aktivləşdirmə funksiyası olan sıx əlaqəli qatdır. Bu, üç mümkün sinif üzrə (çox sinifli təsnifat problemini nəzərə alaraq) ehtimal paylanması istehsal edən modelin çıxış təbəqəsidir.


Kompilyasiya
TensorFlow ilə Maşın Öyrənməsində kompilyasiya üç əsas komponenti - Loss Function, Optimizer və Metrics - göstərərək təlim üçün modeli konfiqurasiya etmək prosesinə aiddir.
Zərər funksiyası : Modelin proqnozları ilə faktiki hədəflər arasındakı xətanı ölçür, model tənzimləmələrinə rəhbərlik etməyə kömək edir.
Optimizator : İtki funksiyasını minimuma endirmək üçün modelin parametrlərini tənzimləyir, səmərəli öyrənməyə imkan verir.
Metriklər : Modelin qiymətləndirilməsinə kömək edən dəqiqlik və ya dəqiqlik kimi itkidən kənar performans qiymətləndirməsini təmin edir.

Aşağıdakı kod Sentiment Analizi Modelini tərtib etmək üçün istifadə edilə bilər:
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])Burada,
loss='sparse_categorical_crossentropy': Hədəf etiketlərinin tam ədədlər olub-olmamasından və modelin çıxışının çoxsaylı siniflər üzrə ehtimal paylanması olub-olmamasından asılı olmayaraq Təsnifat tapşırıqları üçün ümumiyyətlə itki funksiyası istifadə olunur. Təlim zamanı onu minimuma endirmək məqsədi ilə həqiqi etiketlər və proqnozlar arasındakı fərqi ölçür .optimizer='adam': Adam təlim zamanı dinamik olaraq öyrənmə sürətini uyğunlaşdıran optimallaşdırma alqoritmidir. Digər optimallaşdırıcılarla müqayisədə səmərəliliyi, möhkəmliyi və müxtəlif tapşırıqlar üzrə effektivliyi səbəbindən praktikada geniş istifadə olunur.metrics = ['accuracy']: Dəqiqlik təsnifat modellərini qiymətləndirmək üçün tez-tez istifadə olunan ümumi metrikdir. O, modelin proqnozlarının həqiqi etiketlərə uyğun gəldiyi nümunələrin faizi kimi modelin tapşırıq üzrə ümumi performansının sadə ölçülməsini təmin edir.

Modelin hazırlanması
İndi daxil edilmiş məlumatlar işlənib hazır olduqdan və modelin arxitekturası da müəyyən edildikdən sonra model.fit() metodundan istifadə edərək modeli öyrədə bilərik.
model.fit(padded_sequences, labels, epochs=15, verbose=1)padded_sequences: Eyni ölçülü ardıcıllıqlardan ibarət modeli öyrətmək üçün giriş məlumatları (doldurma dərslikdə daha sonra müzakirə olunacaq).labels: Daxil edilmiş məlumatlara uyğun hədəf etiketləri (yəni hər mətn nümunəsinə təyin edilmiş hiss kateqoriyaları)epochs=15: Dövr təlim prosesi zamanı tam təlim verilənlər bazasından bir tam keçiddir. Müvafiq olaraq, bu proqramda model təlim zamanı tam verilənlər toplusunu 15 dəfə təkrarlayır.
Dövrlərin sayı artırıldıqda, məlumat nümunələri vasitəsilə daha mürəkkəb nümunələri öyrəndiyi üçün performansı potensial olaraq yaxşılaşdıracaqdır. Bununla belə, çoxlu dövrlərdən istifadə edilərsə, model yeni məlumatların zəif ümumiləşdirilməsinə gətirib çıxaran (“həddindən artıq uyğunlaşma” adlanır) təlim məlumatlarını yadda saxlaya bilər. Təlim üçün sərf olunan vaxt da dövrlərin sayının artması ilə artacaq və əksinə.


verbose=1: Bu, təlim zamanı modelin uyğunluq metodunun nə qədər məhsul istehsal etdiyinə nəzarət etmək üçün parametrdir. 1 dəyəri o deməkdir ki, model inkişaf etdikcə tərəqqi çubuqları konsolda göstəriləcək, 0 çıxışın olmaması, 2 isə hər dövr üçün bir sətir deməkdir. Dəqiqlik və itki dəyərlərini və hər bir dövr üçün çəkilən vaxtı görmək yaxşı olardı, biz onu 1-ə təyin edəcəyik.
Proqnozlar etmək
Modeli tərtib etdikdən və öyrətdikdən sonra o, nəhayət, sadəcə proqnozlaşdıran() funksiyasından istifadə etməklə nümunə məlumatlarımız əsasında proqnozlar verə bilər. Bununla belə, modeli sınaqdan keçirmək və çıxışı almaq üçün giriş məlumatlarını daxil etməliyik. Bunu etmək üçün bəzi mətn ifadələrini daxil etməliyik və sonra modeldən giriş məlumatlarının əhval-ruhiyyəsini proqnozlaşdırmasını xahiş etməliyik.
test_texts = ["The price was too high for the quality", "The interface is user-friendly", "I'm satisfied"] test_sequences = [] for text in test_texts: words = text.lower().split() sequence = [] for word in words: if word in word_index: sequence.append(word_index[word]) test_sequences.append(sequence) Burada test_texts bəzi giriş məlumatlarını saxlayır, test_sequences siyahısı isə kiçik hərflərə çevrildikdən sonra boşluqlara bölünən sözlər olan tokenləşdirilmiş test məlumatlarını saxlamaq üçün istifadə olunur. Ancaq yenə də test_sequences model üçün giriş məlumatları kimi çıxış edə bilməyəcək.
Səbəb odur ki, Tensorflow da daxil olmaqla bir çox dərin öyrənmə çərçivələri verilənlər toplularını səmərəli şəkildə emal etmək üçün adətən giriş məlumatlarının vahid ölçüyə malik olmasını (bu o deməkdir ki, hər bir ardıcıllığın uzunluğu bərabər olmalıdır) tələb edir. Buna nail olmaq üçün # və ya 0 (bu nümunədə 0) kimi xüsusi işarədən istifadə etməklə ardıcıllığın verilənlər bazasındakı ən uzun ardıcıllıqların uzunluğuna uyğunlaşdırıldığı padding kimi üsullardan istifadə edə bilərsiniz.
import numpy as np padded_test_sequences = [] for sequence in test_sequences: padded_sequence = sequence[:max_length] + [0] * (max_length - len(sequence)) padded_test_sequences.append(padded_sequence) # Convert to numpy array padded_test_sequences = np.array(padded_test_sequences)Verilmiş kodda,
-
padded_test_sequences: Modeli sınaqdan keçirmək üçün istifadə olunacaq dolğun ardıcıllıqları saxlamaq üçün boş siyahı. -
for sequence in sequences: “ardıcıllıqlar” siyahısındakı hər bir ardıcıllıqla dövr edir. -
padded_sequence: Ardıcıllığı təmin etmək üçün orijinal ardıcıllığı ilk max_length elementlərinə kəsərək hər ardıcıllıq üçün yeni dolğun ardıcıllıq yaradır. Sonra, biz ardıcıllığı sıfırlarla doldururuq ki, əgər daha qısadırsa max_length-ə uyğun olsun və effektiv şəkildə bütün ardıcıllıqları eyni uzunluqda edək. -
padded_test_sequences.append(): Sınaq üçün istifadə olunacaq siyahıya doldurulmuş ardıcıllıq əlavə edin. -
padded_sequences = np.array(): Doldurulmuş ardıcıllıqların siyahısını Numpy massivinə çevirmək.


İndi, giriş məlumatları istifadəyə hazır olduğundan, model nəhayət daxil olan mətnlərin əhval-ruhiyyəsini proqnozlaşdıra bilər.
predictions = model.predict(padded_test_sequences) # Print predicted sentiments for i, text in enumerate(test_texts): print(f"Text: {text}, Predicted Sentiment: {np.argmax(predictions[i])}") Yuxarıdakı kodda model.predict() metodu hər bir hiss kateqoriyası üçün proqnozlaşdırılan ehtimallar massivi istehsal edərək hər bir test ardıcıllığı üçün proqnozlar yaradır. Sonra o, hər bir test_texts elementi vasitəsilə təkrarlanır və np.argmax(predictions[i]) i-ci test nümunəsi üçün proqnozlaşdırılan ehtimallar massivində ən yüksək ehtimal indeksini qaytarır. Bu indeks hər bir test nümunəsi üçün ən yüksək proqnozlaşdırılan ehtimala malik proqnozlaşdırılan əhval-ruhiyyə kateqoriyasına uyğundur, yəni edilən ən yaxşı proqnoz çıxarılır və əsas çıxış kimi göstərilir.
Xüsusi qeydlər *:* np.argmax() massivdə maksimum dəyərin indeksini tapan NumPy funksiyasıdır. Bu kontekstdə np.argmax(predictions[i]) hər bir test nümunəsi üçün ən yüksək proqnozlaşdırılan ehtimala malik əhval-ruhiyyə kateqoriyasını müəyyən etməyə kömək edir.
Proqram artıq işə hazırdır. Modeli tərtib etdikdən və öyrətdikdən sonra Maşın Öyrənmə Modeli giriş məlumatları üçün öz proqnozlarını çap edəcək.


Modelin çıxışında biz dəyərləri hər Dövr üçün “Dəqiqlik” və “İtki” kimi görə bilərik. Daha əvvəl qeyd edildiyi kimi, Dəqiqlik ümumi proqnozlardan düzgün proqnozların faizidir. Nə qədər yüksək dəqiqlik daha yaxşıdır. Dəqiqlik 1.0, yəni 100% olarsa, bu, modelin bütün instansiyalarda düzgün proqnozlar verdiyi anlamına gəlir. Eynilə, 0,5 modelin vaxtın yarısında düzgün proqnozlar verdiyini, 0,25 isə vaxtın dörddəbirində düzgün proqnoz verdiyini bildirir və s.
Zərər , əksinə, modelin proqnozlarının həqiqi dəyərlərə nə qədər uyğun olduğunu göstərir. Daha az itki dəyəri daha az səhv sayı ilə daha yaxşı model deməkdir, 0 dəyəri mükəmməl itki dəyəridir, çünki heç bir səhv edilməmişdir.
Bununla belə, hər Epoch üçün göstərilən yuxarıda göstərilən məlumatlarla modelin ümumi dəqiqliyini və itkisini müəyyən edə bilmirik. Bunun üçün evaluate() metodundan istifadə edərək modeli qiymətləndirə və onun Dəqiqliyi və Zərərini çap edə bilərik.
evaluation = model.evaluate(padded_sequences, labels, verbose=0) # Extract loss and accuracy loss = evaluation[0] accuracy = evaluation[1] # Print loss and accuracy print("Loss:", loss) print("Accuracy:", accuracy)Çıxış:
Loss: 0.6483516097068787 Accuracy: 0.7058823704719543Müvafiq olaraq, bu modeldə Zərər dəyəri 0,6483-dür, bu da Modelin bəzi səhvlər etdiyini bildirir. Modelin dəqiqliyi təxminən 70% təşkil edir, yəni model tərəfindən verilən proqnozlar vaxtın yarısından çoxunda doğrudur. Ümumiyyətlə, bu modeli “bir az yaxşı” model hesab etmək olar; lakin nəzərə alın ki, “yaxşı” itki və dəqiqlik dəyərləri modelin növündən, verilənlər toplusunun ölçüsündən və müəyyən Maşın Öyrənmə Modelinin məqsədindən çox asılıdır.
Bəli, biz incə tənzimləmə prosesləri və daha yaxşı nümunə verilənlər bazası ilə modelin yuxarıdakı göstəricilərini təkmilləşdirə bilərik və etməliyik. Ancaq bu dərslik xatirinə buradan dayanaq. Bu dərsliyin ikinci hissəsini istəyirsinizsə, mənə bildirin!
Xülasə
Bu dərslikdə biz nümunə verilənlər dəstini təhlil etdikdən sonra müəyyən mətnin əhval-ruhiyyəsini təxmin etmək imkanı olan TensorFlow Maşın Öyrənmə Modeli yaratdıq.
Tam Kod və Nümunə CSV Faylı GitHub Anbarında endirilə və görünə bilər - GitHub - Buzzpy/Tensorflow-ML-Model







