






20,902 показання
Базові знання Python можуть допомогти вам створити власну модель машинного навчання


















Надто довго; Читати
Давайте створимо власну модель машинного навчання за допомогою Tensorflow, бібліотеки Python.




Привіт красиві люди! Сподіваюся, що 2025 рік ставиться до вас добре, хоча я поки що мав проблеми.
Ласкаво просимо до блогу Doodles and Programming, і сьогодні ми створимо: модель аналізу настроїв за допомогою TensorFlow + Python.


У цьому підручнику ми також дізнаємося про основи машинного навчання за допомогою Python і, як згадувалося раніше, ми зможемо створити власну модель машинного навчання за допомогою Tensorflow, бібліотеки Python. Ця модель зможе визначити тон/емоцію введеного тексту , вивчаючи наданий зразок набору даних.
передумови
Все, що нам потрібно, це деякі знання Python (звичайно, найосновніші речі), а також переконайтеся, що у вашій системі встановлено Python (рекомендується Python 3.9+).
Однак, якщо вам важко пройти цей посібник, не хвилюйтеся! Надішліть мені електронний лист або повідомлення; Я зв’яжуся з вами якомога швидше.
Якщо ви не знаєте, що таке машинне навчання?
Простіше кажучи, машинне навчання (ML) змушує комп’ютер навчатися та робити прогнози, вивчаючи дані та статистику. Вивчаючи надані дані, комп’ютер може ідентифікувати та витягувати закономірності, а потім робити прогнози на їх основі. Ідентифікація спаму, розпізнавання мовлення та прогнозування трафіку – це деякі випадки використання машинного навчання в реальному житті.
Для кращого прикладу уявіть, що ми хочемо навчити комп’ютер розпізнавати котів на фотографіях. Ви б показали йому багато фотографій котів і сказали: «Гей, комп’ютер, це коти!» Комп’ютер дивиться на зображення і починає помічати візерунки – як-от гострі вуха, вуса та хутро. Переглянувши достатньо прикладів, він може впізнати кота на новому фото, якого раніше не бачив.


Однією з таких систем, якою ми користуємося щодня, є фільтри електронної пошти для спаму. На наступному зображенні показано, як це робиться.


Навіщо використовувати Python?
Незважаючи на те, що мова програмування Python не створена спеціально для ML або Data Science, вона вважається чудовою мовою програмування для ML завдяки своїй адаптивності. Завдяки сотням бібліотек, доступних для безкоштовного завантаження, будь-хто може легко створювати моделі ML за допомогою попередньо створеної бібліотеки без необхідності програмувати всю процедуру з нуля.
TensorFlow — одна з таких бібліотек, створена Google для машинного навчання та штучного інтелекту. TensorFlow часто використовується науковцями з даних, інженерами з обробки даних та іншими розробниками для легкої побудови моделей машинного навчання, оскільки він складається з різноманітних алгоритмів машинного навчання та ШІ.
Відвідайте офіційний веб-сайт TensorFlow
монтаж
Щоб установити Tensorflow, виконайте таку команду у своєму терміналі:
pip install tensorflowА щоб встановити Pandas і Numpy,
pip install pandas numpyБудь ласка, завантажте зразок файлу CSV із цього репозиторію: Github Repository - TensorFlow ML Model
Розуміння даних
Правило №1 щодо аналізу даних і всього, що базується на даних: спочатку зрозумійте дані, які у вас є.
У цьому випадку набір даних має два стовпці: текст і почуття. У той час як стовпець «текст» містить різноманітні твердження про фільми, книги тощо, стовпець «настрої» показує, чи є текст позитивним, нейтральним чи негативним, використовуючи числа 1, 2 і 0 відповідно.
Підготовка даних
Наступне емпіричне правило полягає в тому, щоб очистити дублікати та видалити нульові значення у ваших вибіркових даних. Але в цьому випадку, оскільки заданий набір даних досить малий і не містить дублікатів або нульових значень, ми можемо пропустити процес очищення даних.


Щоб розпочати створення моделі, ми повинні зібрати та підготувати набір даних для навчання моделі аналізу настроїв. Для цього завдання можна використовувати Pandas, популярну бібліотеку для аналізу та обробки даних.
import pandas as pd # Load data from CSV data = pd.read_csv('sentiment.csv') # Change the path of downloaded CSV File accordingly # Text data and labels texts = data['text'].tolist() labels = data['sentiment'].values Наведений вище код перетворює файл CSV на фрейм даних за допомогою функції pandas.read_csv() . Потім він призначає значення стовпця «сентимент» списку Python за допомогою функції tolist() і створює масив Numpy зі значеннями.
Навіщо використовувати масив Numpy?
Як ви вже могли знати, Numpy в основному створений для маніпулювання даними. Масиви Numpy ефективно обробляють числові мітки для завдань машинного навчання, що забезпечує гнучкість організації даних. Ось чому ми використовуємо Numpy в цьому випадку.
Обробка тексту
Після підготовки зразків даних нам потрібно повторно обробити текст, що включає токенізацію.
Токенізація — це процес поділу кожного зразка тексту на окремі слова або лексеми, щоб ми могли перетворити необроблені текстові дані у формат, який може бути оброблений моделлю , дозволяючи їй розуміти окремі слова в зразках тексту та навчатися на них. .
Перегляньте зображення нижче, щоб дізнатися, як працює токенізація.
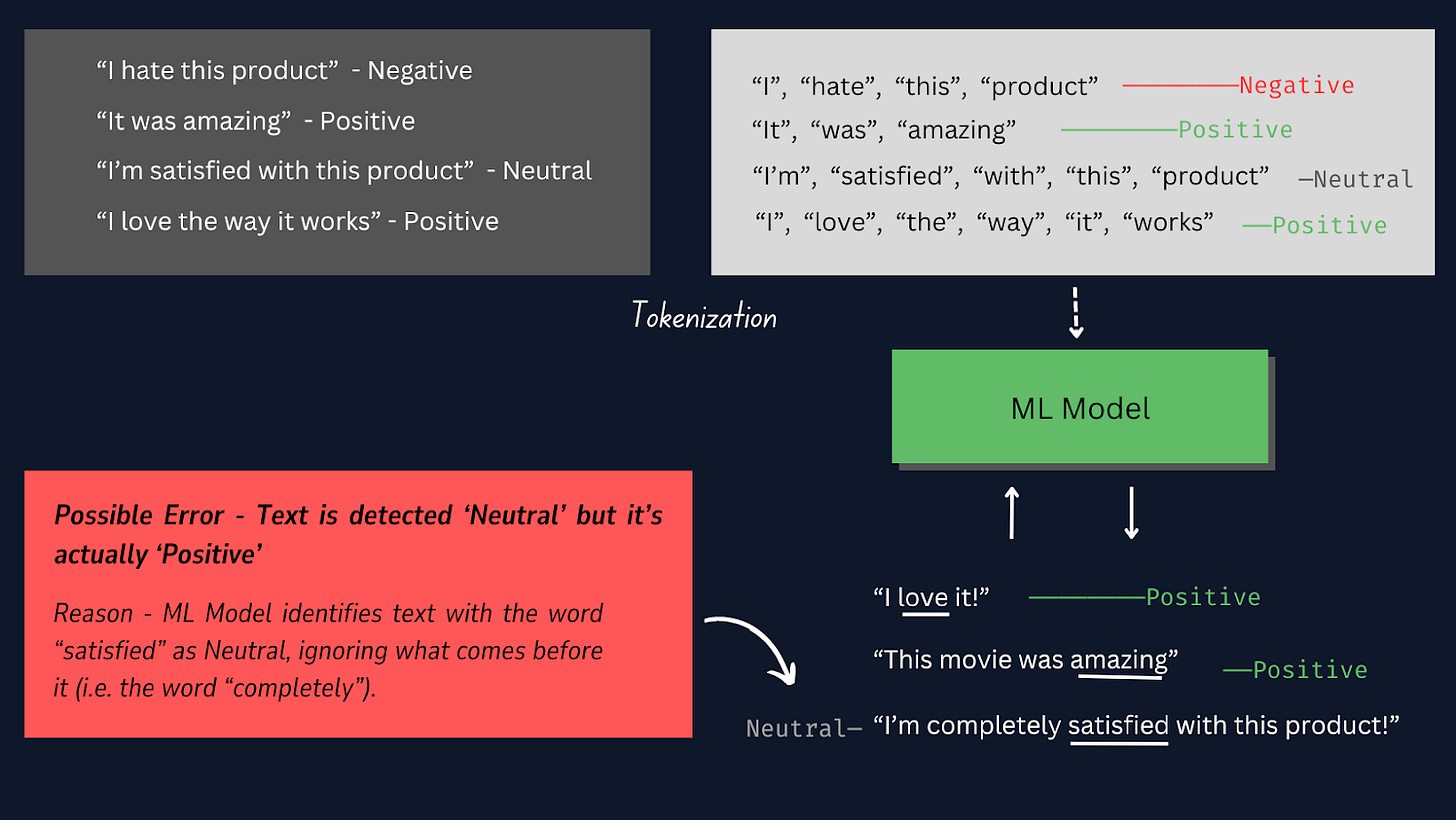
У цьому проекті найкраще використовувати ручну токенізацію замість інших попередньо створених токенізаторів, оскільки вона дає нам більше контролю над процесом токенізації, гарантує сумісність із певними форматами даних і дозволяє адаптувати етапи попередньої обробки.
Примітка. У ручній токенізації ми пишемо код для поділу тексту на слова, який можна налаштувати відповідно до потреб проекту. Однак інші методи, такі як використання TensorFlow Keras Tokenizer, постачаються з готовими інструментами та функціями для автоматичного поділу тексту, який легше реалізувати, але менш налаштовувати.
Нижче наведено фрагмент коду, який ми можемо використовувати для токенізації зразків даних.
word_index = {} sequences = [] for text in texts: words = text.lower().split() sequence = [] for word in words: if word not in word_index: word_index[word] = len(word_index) + 1 sequence.append(word_index[word]) sequences.append(sequence)У наведеному вище коді
-
word_index: порожній словник, створений для зберігання кожного унікального слова в наборі даних разом із його значенням. -
sequences: порожній список, який зберігає послідовності числового представлення слів для кожного зразка тексту. -
for text in texts: переглядає кожен зразок тексту у списку «тексти» (створеному раніше). -
words = text.lower().split(): перетворює кожен зразок тексту на нижній регістр і розділяє його на окремі слова на основі пробілів. -
for word in words: вкладений цикл, який повторює кожне слово у списку «слова», який містить слова з маркерами з поточних зразків тексту. -
if word not in word_index: якщо слова наразі немає у словнику word_index, воно додається до нього разом із унікальним індексом, який отримується шляхом додавання 1 до поточної довжини словника. -
sequence. append (word_index[word]): після визначення індексу поточного слова воно додається до списку «послідовності». Це перетворює кожне слово у зразку тексту на відповідний індекс на основі словника «word_index». -
sequence.append(sequence): після того, як усі слова у зразку тексту перетворено на числові індекси та збережено у списку «sequence», цей список додається до списку «sequences».
Підводячи підсумок, наведений вище код токенізує текстові дані, перетворюючи кожне слово на його числове представлення на основі словника word_index , який зіставляє слова з унікальними індексами. Він створює послідовності числових представлень для кожного зразка тексту, які можна використовувати як вхідні дані для моделі.
Архітектура моделі
Архітектура певної моделі – це розташування рівнів, компонентів і з’єднань, які визначають, як через неї проходять дані . Архітектура моделі має значний вплив на швидкість навчання, продуктивність і здатність до узагальнення моделі.
Після обробки вхідних даних ми можемо визначити архітектуру моделі, як у прикладі нижче:
model = tf.keras.Sequential([ tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length), tf.keras.layers.LSTM(64), tf.keras.layers.Dense(3, activation='softmax') ])
У наведеному вище коді ми використовуємо TensorFlow Keras, який є високорівневим API нейронних мереж, створеним для швидкого експериментування та створення прототипів моделей глибокого навчання шляхом спрощення процесу побудови та компіляції моделей машинного навчання.
-
tf. keras.Sequential(): Визначення послідовної моделі, яка є лінійним стеком шарів. Дані переходять у порядку від першого до останнього. -
tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length): цей шар використовується для вбудовування слів, яке перетворює слова на щільні вектори фіксованого розміру. len(word_index) + 1 вказує розмір словника, 16 — розмірність вбудовування, а input_length=max_length встановлює довжину введення для кожної послідовності. -
tf.keras.layers.LSTM(64): Цей рівень є рівнем довгострокової короткочасної пам’яті (LSTM), який є типом рекурентної нейронної мережі (RNN). Він обробляє послідовність вбудовування слів і може «запам’ятовувати» важливі моделі або залежності в даних. Має 64 одиниці, які визначають розмірність вихідного простору. -
tf.keras.layers.Dense(3, activation='softmax'): це щільно зв'язаний шар із 3 одиницями та функцією активації softmax. Це вихідний рівень моделі, що створює розподіл ймовірностей за трьома можливими класами (припускаючи проблему класифікації з кількома класами).


Компіляція
У машинному навчанні з TensorFlow компіляція стосується процесу налаштування моделі для навчання шляхом визначення трьох ключових компонентів — функції втрати, оптимізатора та метрики.
Функція втрати : вимірює похибку між прогнозами моделі та фактичними цілями, допомагаючи керувати коригуванням моделі.
Оптимізатор : налаштовує параметри моделі, щоб мінімізувати функцію втрат, забезпечуючи ефективне навчання.
Метрики : надає оцінку ефективності за винятком втрат, наприклад точність або точність, допомагаючи в оцінці моделі.

Наведений нижче код можна використати для компіляції моделі аналізу настрою:
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])тут,
loss='sparse_categorical_crossentropy': функція втрат зазвичай використовується для завдань класифікації, незалежно від того, чи цільові мітки є цілими числами, а результатом моделі є розподіл ймовірностей за кількома класами. Він вимірює різницю між справжніми мітками та прогнозами , щоб мінімізувати її під час навчання.optimizer='adam': Адам — це алгоритм оптимізації, який динамічно адаптує швидкість навчання під час навчання. Він широко використовується на практиці завдяки своїй ефективності, надійності й результативності в широкому діапазоні завдань порівняно з іншими оптимізаторами.metrics = ['accuracy']: Точність — це загальний показник, який часто використовують для оцінки моделей класифікації. Він забезпечує пряме вимірювання загальної продуктивності моделі у виконанні завдання, як відсоток зразків, для яких прогнози моделі відповідають справжнім міткам.

Навчання моделі
Тепер, коли вхідні дані оброблені та готові, а архітектура моделі також визначена, ми можемо навчити модель за допомогою методу model.fit() .
model.fit(padded_sequences, labels, epochs=15, verbose=1)padded_sequences: вхідні дані для навчання моделі, яка складається з послідовностей однакових розмірів (заповнення обговорюватиметься пізніше в посібнику).labels: цільові мітки, що відповідають вхідним даним (тобто категорії настрою, призначені кожному зразку тексту)epochs=15: Епоха — це один повний прохід повного навчального набору даних під час процесу навчання. Відповідно, у цій програмі модель повторює повний набір даних 15 разів під час навчання.
Коли кількість епох збільшується, він потенційно покращить продуктивність, оскільки вивчає складніші шаблони за допомогою зразків даних. Однак, якщо використовується занадто багато епох, модель може запам’ятовувати навчальні дані, що призводить (що називається «переобладнанням») до поганого узагальнення нових даних. Час, витрачений на навчання, також буде збільшуватися зі збільшенням кількості епох і навпаки.


verbose=1: це параметр для контролю того, скільки вихідних даних видає метод підгонки моделі під час навчання. Значення 1 означає, що індикатори прогресу відображатимуться на консолі під час навчання моделі, 0 означає відсутність виводу, а 2 означає один рядок на епоху. Оскільки було б добре бачити значення точності та втрат, а також час, витрачений на кожну епоху, ми встановимо значення 1.
Складання прогнозів
Після компіляції та навчання моделі вона нарешті може робити прогнози на основі наших вибіркових даних, просто використовуючи функцію predict(). Однак нам потрібно ввести вхідні дані, щоб перевірити модель і отримати вихідні дані. Для цього ми повинні ввести деякі текстові вирази, а потім попросити модель передбачити настрій вхідних даних.
test_texts = ["The price was too high for the quality", "The interface is user-friendly", "I'm satisfied"] test_sequences = [] for text in test_texts: words = text.lower().split() sequence = [] for word in words: if word in word_index: sequence.append(word_index[word]) test_sequences.append(sequence) Тут test_texts зберігає деякі вхідні дані, тоді як список test_sequences використовується для зберігання токенізованих тестових даних, які є словами, розділеними пробілами після перетворення на малі літери. Але все одно test_sequences не зможе виступати в якості вхідних даних для моделі.
Причина полягає в тому, що багато фреймворків глибокого навчання, включаючи Tensorflow, зазвичай вимагають, щоб вхідні дані мали однакову розмірність (що означає, що довжина кожної послідовності повинна бути однаковою), щоб ефективно обробляти пакети даних. Щоб досягти цього, ви можете використовувати такі методи, як доповнення, де послідовності розширюються, щоб відповідати довжині найдовших послідовностей у наборі даних, використовуючи спеціальний маркер, наприклад # або 0 (0, у цьому прикладі).
import numpy as np padded_test_sequences = [] for sequence in test_sequences: padded_sequence = sequence[:max_length] + [0] * (max_length - len(sequence)) padded_test_sequences.append(padded_sequence) # Convert to numpy array padded_test_sequences = np.array(padded_test_sequences)У наведеному коді
-
padded_test_sequences: порожній список для зберігання доповнених послідовностей, які використовуватимуться для тестування моделі. -
for sequence in sequences: перебирає кожну послідовність у списку «послідовностей». -
padded_sequence: створює нову доповнену послідовність для кожної послідовності, скорочуючи оригінальну послідовність до перших елементів max_length для забезпечення узгодженості. Потім ми доповнюємо послідовність нулями, щоб відповідати max_length, якщо вона коротша, фактично роблячи всі послідовності однаковими. -
padded_test_sequences.append(): додайте доповнену послідовність до списку, який використовуватиметься для тестування. -
padded_sequences = np.array(): Перетворення списку доповнених послідовностей у масив Numpy.


Тепер, оскільки вхідні дані готові до використання, модель нарешті може передбачити настрої вхідних текстів.
predictions = model.predict(padded_test_sequences) # Print predicted sentiments for i, text in enumerate(test_texts): print(f"Text: {text}, Predicted Sentiment: {np.argmax(predictions[i])}") У наведеному вище коді метод model.predict() створює прогнози для кожної тестової послідовності, створюючи масив прогнозованих ймовірностей для кожної категорії настрою. Потім виконується ітерація по кожному елементу test_texts і np.argmax(predictions[i]) повертає індекс найвищої ймовірності в масиві прогнозованих ймовірностей для i-го тестового зразка. Цей індекс відповідає категорії прогнозованого настрою з найвищою прогнозованою ймовірністю для кожної тестової вибірки, що означає, що найкращий зроблений прогноз витягується та відображається як основний результат.
Особливі примітки *:* np.argmax() — це функція NumPy, яка знаходить індекс максимального значення в масиві. У цьому контексті np.argmax(predictions[i]) допомагає визначити категорію настрою з найвищою прогнозованою ймовірністю для кожного тестового зразка.
Тепер програма готова до запуску. Після компіляції та навчання моделі модель машинного навчання роздрукує свої прогнози для вхідних даних.


У вихідних даних моделі ми можемо бачити значення «Точність» і «Втрата» для кожної епохи. Як згадувалося раніше, точність – це відсоток правильних прогнозів від загальної кількості прогнозів. Чим вища точність, тим краще. Якщо точність становить 1,0, що означає 100%, це означає, що модель зробила правильні прогнози в усіх випадках. Аналогічно, 0,5 означає, що модель робила правильні прогнози половину часу, 0,25 означає правильний прогноз чверть часу і так далі.
Втрата , з іншого боку, показує, наскільки погано прогнози моделі відповідають справжнім значенням. Менше значення втрат означає кращу модель із меншою кількістю помилок, причому значення 0 є ідеальним значенням втрат, оскільки це означає відсутність помилок.
Однак ми не можемо визначити загальну точність і втрату моделі з наведеними вище даними для кожної епохи. Для цього ми можемо оцінити модель за допомогою методу evaluate() і надрукувати її точність і втрату.
evaluation = model.evaluate(padded_sequences, labels, verbose=0) # Extract loss and accuracy loss = evaluation[0] accuracy = evaluation[1] # Print loss and accuracy print("Loss:", loss) print("Accuracy:", accuracy)Вихід:
Loss: 0.6483516097068787 Accuracy: 0.7058823704719543Відповідно, у цій моделі значення втрати становить 0,6483, що означає, що модель зробила деякі помилки. Точність моделі становить близько 70%, що означає, що прогнози, зроблені моделлю, правильні більш ніж у половині випадків. Загалом цю модель можна вважати «трохи хорошою» моделлю; однак зауважте, що «хороші» значення втрат і точності сильно залежать від типу моделі, розміру набору даних і мети певної моделі машинного навчання.
І так, ми можемо і повинні покращити наведені вище показники моделі шляхом точного налаштування процесів і кращих вибіркових наборів даних. Однак заради цього підручника зупинимося на цьому. Якщо вам потрібна друга частина цього підручника, будь ласка, дайте мені знати!
Резюме
У цьому посібнику ми створили модель машинного навчання TensorFlow із можливістю передбачити настрій певного тексту після аналізу зразка набору даних.
Повний код і зразок файлу CSV можна завантажити та переглянути в репозиторії GitHub - GitHub - Buzzpy/Tensorflow-ML-Model

L O A D I N G
. . . comments & more!
. . . comments & more!




