
























Ciao bella gente! Spero che il 2025 vi stia trattando bene, anche se per me è stato un periodo pieno di bug, finora.
Benvenuti al blog Doodles and Programming. Oggi realizzeremo un modello di analisi del sentiment utilizzando TensorFlow + Python.


In questo tutorial, impareremo anche le basi del Machine Learning con Python e, come detto prima, saremo in grado di costruire il nostro modello di Machine Learning con Tensorflow, una libreria Python. Questo modello sarà in grado di rilevare il tono/emozione del testo di input , studiando e imparando dal set di dati di esempio fornito.
Prerequisiti
Tutto ciò di cui abbiamo bisogno è una certa conoscenza di Python (le nozioni più basilari, ovviamente) e, inoltre, assicurarci di aver installato Python sul nostro sistema (si consiglia Python 3.9+).
Tuttavia, se trovi difficile seguire questo tutorial, non preoccuparti! Mandami un'e-mail o un messaggio; ti risponderò il prima possibile.
Nel caso non lo sapessi, cos'è il Machine Learning?
In parole povere, il Machine Learning (ML) fa sì che il computer impari e faccia previsioni, studiando dati e statistiche. Studiando i dati forniti, il computer può identificare ed estrarre schemi e quindi fare previsioni basate su di essi. L'identificazione di e-mail di spam, il riconoscimento vocale e la previsione del traffico sono alcuni casi di utilizzo reale del Machine Learning.
Per un esempio migliore, immaginiamo di voler insegnare a un computer a riconoscere i gatti nelle foto. Gli mostreresti un sacco di foto di gatti e diresti: "Ehi, computer, questi sono gatti!" Il computer guarda le foto e inizia a notare dei pattern, come orecchie a punta, baffi e pelliccia. Dopo aver visto abbastanza esempi, può riconoscere un gatto in una nuova foto che non ha mai visto prima.


Uno di questi sistemi di cui ci avvaliamo ogni giorno è il filtro antispam per le email. L'immagine seguente mostra come funziona.


Perché usare Python?
Anche se Python Programming Language non è stato creato specificamente per ML o Data Science, è considerato un ottimo linguaggio di programmazione per ML grazie alla sua adattabilità. Con centinaia di librerie disponibili per il download gratuito, chiunque può facilmente creare modelli ML utilizzando una libreria pre-costruita senza dover programmare l'intera procedura da zero.
TensorFlow è una di queste librerie creata da Google per Machine Learning e Artificial Intelligence. TensorFlow è spesso utilizzato da data scientist, data engineer e altri sviluppatori per creare facilmente modelli di machine learning, poiché è costituito da una varietà di algoritmi di machine learning e AI.
Visita il sito Web ufficiale di TensorFlow
Installazione
Per installare Tensorflow, esegui il seguente comando nel tuo terminale:
pip install tensorflowE per installare Pandas e Numpy,
pip install pandas numpyScarica il file CSV di esempio da questo repository: Github Repository - TensorFlow ML Model
Comprendere i dati
Regola n. 1 per l'analisi dei dati e per tutto ciò che si basa sui dati: comprendere prima i dati in tuo possesso.
In questo caso, il set di dati ha due colonne: Testo e Sentimento. Mentre la colonna "testo" contiene una serie di affermazioni su film, libri, ecc., la colonna "sentimento" mostra se il testo è positivo, neutro o negativo, utilizzando rispettivamente i numeri 1, 2 e 0.
Preparazione dei dati
La successiva regola empirica è quella di pulire i duplicati e rimuovere i valori nulli nei dati campione. Ma in questo caso, poiché il set di dati dato è piuttosto piccolo e non contiene duplicati o valori nulli, possiamo saltare il processo di pulizia dei dati.


Per iniziare a costruire il modello, dovremmo raccogliere e preparare il set di dati per addestrare il modello di analisi del sentiment. Pandas, una popolare libreria per l'analisi e la manipolazione dei dati, può essere utilizzata per questo compito.
import pandas as pd # Load data from CSV data = pd.read_csv('sentiment.csv') # Change the path of downloaded CSV File accordingly # Text data and labels texts = data['text'].tolist() labels = data['sentiment'].values Il codice soprastante converte il file CSV in un data frame, usando la funzione pandas.read_csv() . Quindi, assegna i valori della colonna "sentiment" a un elenco Python usando la funzione tolist() e crea un array Numpy con i valori.
Perché utilizzare un array Numpy?
Come forse già saprai, Numpy è fondamentalmente creato per la manipolazione dei dati. Gli array Numpy gestiscono in modo efficiente le etichette numeriche per le attività di apprendimento automatico, il che offre flessibilità nell'organizzazione dei dati. Ecco perché in questo caso stiamo usando Numpy.
Elaborazione del testo
Dopo aver preparato i dati campione, dobbiamo rielaborare il testo, operazione che comporta la tokenizzazione.
La tokenizzazione è il processo di suddivisione di ogni campione di testo in singole parole o token, in modo da poter convertire i dati di testo grezzi in un formato che può essere elaborato dal modello , consentendogli di comprendere e apprendere dalle singole parole nei campioni di testo.
Per scoprire come funziona la tokenizzazione, fare riferimento all'immagine sottostante.
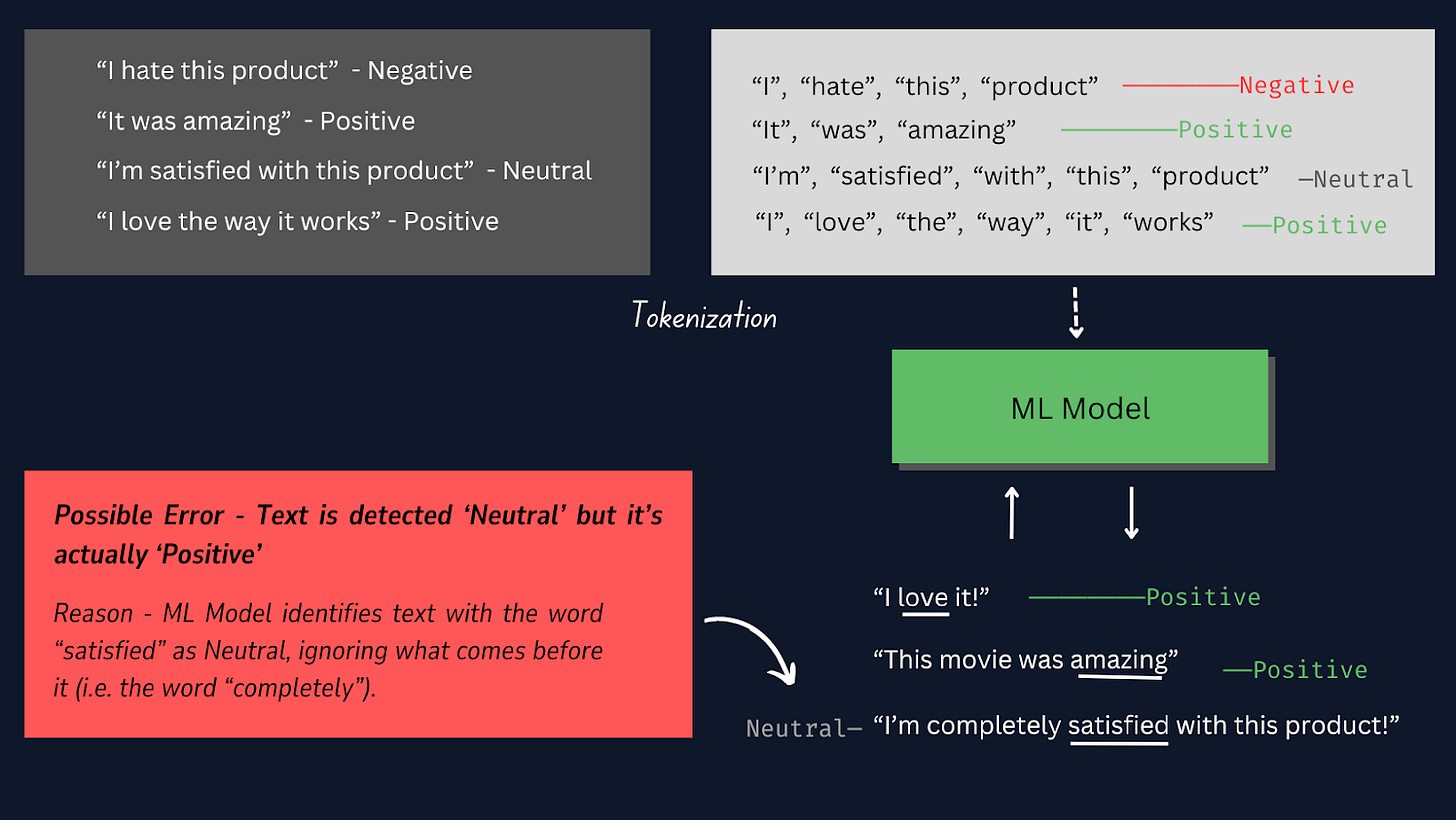
In questo progetto è meglio utilizzare la tokenizzazione manuale anziché altri tokenizzatori predefiniti, poiché ci fornisce un maggiore controllo sul processo di tokenizzazione, garantisce la compatibilità con formati di dati specifici e consente fasi di pre-elaborazione personalizzate.
Nota: nella tokenizzazione manuale, scriviamo codice per dividere il testo in parole, il che è altamente personalizzabile in base alle esigenze del progetto. Tuttavia, altri metodi, come l'utilizzo di TensorFlow Keras Tokenizer, sono dotati di strumenti e funzioni già pronti per dividere automaticamente il testo, il che è più facile da implementare ma meno personalizzabile.
Di seguito è riportato il frammento di codice che possiamo utilizzare per la tokenizzazione dei dati campione.
word_index = {} sequences = [] for text in texts: words = text.lower().split() sequence = [] for word in words: if word not in word_index: word_index[word] = len(word_index) + 1 sequence.append(word_index[word]) sequences.append(sequence)Nel codice sopra,
-
word_index: dizionario vuoto creato per memorizzare ogni parola univoca nel set di dati, insieme al suo valore. -
sequences: un elenco vuoto che memorizza le sequenze di rappresentazione numerica delle parole per ciascun campione di testo. -
for text in texts: scorre ogni campione di testo nell'elenco "testi" (creato in precedenza). -
words = text.lower().split(): converte ogni campione di testo in minuscolo e lo divide in singole parole, in base agli spazi vuoti. -
for word in words: un ciclo annidato che esegue un'iterazione su ogni parola nell'elenco "parole", che contiene parole tokenizzate dagli attuali campioni di testo. -
if word not in word_index: se la parola non è attualmente presente nel dizionario word_index, viene aggiunta ad esso insieme a un indice univoco, che si ottiene aggiungendo 1 alla lunghezza corrente del dizionario. -
sequence. append (word_index[word]): Dopo aver determinato l'indice della parola corrente, questa viene aggiunta all'elenco "sequence". Ciò converte ogni parola nel campione di testo nel suo indice corrispondente in base al dizionario "word_index". -
sequence.append(sequence): Dopo che tutte le parole nel campione di testo sono state convertite in indici numerici e memorizzate nell'elenco "sequence", questo elenco viene aggiunto all'elenco "sequences".
In sintesi, il codice sopra riportato tokenizza i dati di testo convertendo ogni parola nella sua rappresentazione numerica basata sul dizionario word_index , che mappa le parole in indici univoci. Crea sequenze di rappresentazioni numeriche per ogni campione di testo, che possono essere utilizzate come dati di input per il modello.
Architettura del modello
L'architettura di un certo modello è la disposizione di livelli, componenti e connessioni che determinano il modo in cui i dati fluiscono attraverso di esso . L'architettura del modello ha un impatto significativo sulla velocità di training, sulle prestazioni e sulla capacità di generalizzazione del modello.
Dopo aver elaborato i dati di input, possiamo definire l'architettura del modello come nell'esempio seguente:
model = tf.keras.Sequential([ tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length), tf.keras.layers.LSTM(64), tf.keras.layers.Dense(3, activation='softmax') ])
Nel codice soprastante utilizziamo TensorFlow Keras, un'API di reti neurali di alto livello creata per la sperimentazione e la prototipazione rapida di modelli di Deep Learning, semplificando il processo di costruzione e compilazione di modelli di apprendimento automatico.
-
tf. keras.Sequential(): Definizione di un modello sequenziale, che è una pila lineare di strati. I dati fluiscono dal primo strato all'ultimo, in ordine. -
tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length): questo layer è utilizzato per l'incorporamento di parole, che converte le parole in vettori densi di dimensione fissa. len(word_index) + 1 specifica la dimensione del vocabolario, 16 è la dimensionalità dell'incorporamento e input_length=max_length imposta la lunghezza di input per ogni sequenza. -
tf.keras.layers.LSTM(64): Questo strato è uno strato di memoria a lungo e breve termine (LSTM), che è un tipo di rete neurale ricorrente (RNN). Elabora la sequenza di word embedding e può "ricordare" importanti pattern o dipendenze nei dati. Ha 64 unità, che determinano la dimensionalità dello spazio di output. -
tf.keras.layers.Dense(3, activation='softmax'): Questo è uno strato densamente connesso con 3 unità e una funzione di attivazione softmax. È lo strato di output del modello, che produce una distribuzione di probabilità sulle tre classi possibili (ipotizzando un problema di classificazione multi-classe).


Compilazione
Nell'apprendimento automatico con TensorFlow, la compilazione si riferisce al processo di configurazione del modello per l'addestramento specificando tre componenti chiave : funzione di perdita, ottimizzatore e metriche.
Funzione di perdita : misura l'errore tra le previsioni del modello e gli obiettivi effettivi, aiutando a guidare gli aggiustamenti del modello.
Ottimizzatore : regola i parametri del modello per ridurre al minimo la funzione di perdita, consentendo un apprendimento efficiente.
Metriche : forniscono una valutazione delle prestazioni che va oltre la perdita, come accuratezza o precisione, facilitando la valutazione del modello.

Il codice seguente può essere utilizzato per compilare il modello di analisi del sentiment:
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])Qui,
loss='sparse_categorical_crossentropy': Una funzione di perdita è generalmente utilizzata per le attività di classificazione, indipendentemente dal fatto che le etichette di destinazione siano numeri interi e che l'output del modello sia una distribuzione di probabilità su più classi. Misura la differenza tra etichette vere e previsioni , mirando a ridurla al minimo durante l'addestramento.optimizer='adam': Adam è un algoritmo di ottimizzazione che adatta dinamicamente il tasso di apprendimento durante l'addestramento. È ampiamente utilizzato nella pratica per la sua efficienza, robustezza ed efficacia in un'ampia gamma di attività rispetto ad altri ottimizzatori.metrics = ['accuracy']: L'accuratezza è una metrica comune spesso utilizzata per valutare i modelli di classificazione. Fornisce una misura semplice delle prestazioni complessive del modello sul compito, come la percentuale di campioni per cui le previsioni del modello corrispondono alle etichette vere.

Formazione del modello
Ora che i dati di input sono stati elaborati e sono pronti e che è stata definita anche l'architettura del modello, possiamo addestrare il modello utilizzando il metodo model.fit() .
model.fit(padded_sequences, labels, epochs=15, verbose=1)padded_sequences: dati di input per l'addestramento del modello, costituiti da sequenze delle stesse dimensioni (il padding sarà trattato più avanti nel tutorial).labels: etichette di destinazione corrispondenti ai dati di input (ad esempio categorie di sentimento assegnate a ciascun campione di testo)epochs=15: Un'epoca è un passaggio completo attraverso il dataset di training completo durante il processo di training. Di conseguenza, in questo programma, il modello itera sul dataset completo 15 volte durante il training.
Quando il numero di epoche viene aumentato, potenzialmente migliorerà le prestazioni poiché apprende modelli più complessi attraverso i campioni di dati. Tuttavia, se vengono utilizzate troppe epoche, il modello potrebbe memorizzare i dati di training, portando (ciò è chiamato "overfitting") a una scarsa generalizzazione dei nuovi dati. Il tempo impiegato per il training aumenterà anche con l'aumento del numero di epoche e viceversa.


verbose=1: Questo è un parametro per controllare la quantità di output prodotta dal metodo di adattamento del modello durante l'addestramento. Un valore di 1 significa che le barre di avanzamento saranno visualizzate nella console mentre il modello si allena, 0 significa nessun output e 2 significa una riga per epoca. Poiché sarebbe utile vedere i valori di accuratezza e perdita e il tempo impiegato per ogni epoca, lo imposteremo su 1.
Fare previsioni
Dopo la compilazione e l'addestramento del modello, può finalmente fare previsioni basate sui nostri dati campione, semplicemente usando la funzione predict(). Tuttavia, dobbiamo immettere dati di input per testare il modello e ricevere output. Per farlo, dovremmo immettere alcune istruzioni di testo e poi chiedere al modello di prevedere il sentiment dei dati di input.
test_texts = ["The price was too high for the quality", "The interface is user-friendly", "I'm satisfied"] test_sequences = [] for text in test_texts: words = text.lower().split() sequence = [] for word in words: if word in word_index: sequence.append(word_index[word]) test_sequences.append(sequence) Qui, test_texts memorizza alcuni dati di input mentre l'elenco test_sequences viene utilizzato per memorizzare dati di test tokenizzati, che sono parole divise da spazi vuoti dopo essere state trasformate in minuscolo. Tuttavia, test_sequences non sarà in grado di fungere da dati di input per il modello.
Il motivo è che molti framework di deep learning, tra cui Tensorflow, solitamente richiedono che i dati di input abbiano una dimensione uniforme (il che significa che la lunghezza di ogni sequenza deve essere uguale), per elaborare batch di dati in modo efficiente. Per ottenere questo risultato, puoi usare tecniche come il padding, in cui le sequenze vengono estese per corrispondere alla lunghezza delle sequenze più lunghe nel dataset, usando un token speciale come # o 0 (0, in questo esempio).
import numpy as np padded_test_sequences = [] for sequence in test_sequences: padded_sequence = sequence[:max_length] + [0] * (max_length - len(sequence)) padded_test_sequences.append(padded_sequence) # Convert to numpy array padded_test_sequences = np.array(padded_test_sequences)Nel codice fornito,
-
padded_test_sequences: un elenco vuoto in cui memorizzare le sequenze imbottite che verranno utilizzate per testare il modello. -
for sequence in sequences: Esegue un ciclo attraverso ogni sequenza nell'elenco "sequenze". -
padded_sequence: Crea una nuova sequenza imbottita per ogni sequenza, troncando la sequenza originale ai primi elementi max_length per garantire coerenza. Quindi, stiamo aggiungendo degli zeri alla sequenza per farla corrispondere a max_length se è più corta, rendendo di fatto tutte le sequenze della stessa lunghezza. -
padded_test_sequences.append(): aggiunge una sequenza imbottita all'elenco che verrà utilizzato per i test. -
padded_sequences = np.array(): Conversione dell'elenco delle sequenze imbottite in un array Numpy.


Ora che i dati di input sono pronti per essere utilizzati, il modello può finalmente prevedere il sentiment dei testi di input.
predictions = model.predict(padded_test_sequences) # Print predicted sentiments for i, text in enumerate(test_texts): print(f"Text: {text}, Predicted Sentiment: {np.argmax(predictions[i])}") Nel codice sopra, il metodo model.predict() genera previsioni per ogni sequenza di test, producendo un array di probabilità previste per ogni categoria di sentiment. Quindi scorre ogni elemento test_texts e np.argmax(predictions[i]) restituisce l'indice della probabilità più alta nell'array di probabilità previste per l'i-esimo campione di test. Questo indice corrisponde alla categoria di sentiment prevista con la probabilità prevista più alta per ogni campione di test, il che significa che la migliore previsione effettuata viene estratta e mostrata come output principale.
Note speciali *:* np.argmax() è una funzione NumPy che trova l'indice del valore massimo in un array. In questo contesto, np.argmax(predictions[i]) aiuta a determinare la categoria di sentiment con la più alta probabilità prevista per ogni campione di test.
Il programma è ora pronto per essere eseguito. Dopo aver compilato e addestrato il modello, il modello di apprendimento automatico stamperà le sue previsioni per i dati di input.


Nell'output del modello, possiamo vedere i valori come "Accuracy" e "Loss" per ogni Epoch. Come accennato in precedenza, Accuracy è la percentuale di previsioni corrette sul totale delle previsioni. Maggiore è l'accuratezza, migliore è. Se l'accuratezza è 1,0, che significa 100%, significa che il modello ha fatto previsioni corrette in tutte le istanze. Allo stesso modo, 0,5 significa che il modello ha fatto previsioni corrette metà delle volte, 0,25 significa previsione corretta un quarto delle volte e così via.
La perdita , d'altro canto, mostra quanto male le previsioni del modello corrispondono ai valori reali. Il valore di perdita minore indica un modello migliore con un numero inferiore di errori, con il valore 0 che è il valore di perdita perfetto, in quanto significa che non vengono commessi errori.
Tuttavia, non possiamo determinare l'accuratezza e la perdita complessive del modello con i dati sopra indicati per ogni Epoch. Per farlo, possiamo valutare il modello usando il metodo estimate() e stampare la sua Accuracy e Loss.
evaluation = model.evaluate(padded_sequences, labels, verbose=0) # Extract loss and accuracy loss = evaluation[0] accuracy = evaluation[1] # Print loss and accuracy print("Loss:", loss) print("Accuracy:", accuracy)Produzione:
Loss: 0.6483516097068787 Accuracy: 0.7058823704719543Di conseguenza, in questo modello, il valore di perdita è 0,6483, il che significa che il modello ha commesso alcuni errori. L'accuratezza del modello è di circa il 70%, il che significa che le previsioni fatte dal modello sono corrette più della metà delle volte. Nel complesso, questo modello può essere considerato un modello "leggermente buono"; tuttavia, si noti che i valori di perdita e accuratezza "buoni" dipendono molto dal tipo di modello, dalla dimensione del set di dati e dallo scopo di un determinato modello di apprendimento automatico.
E sì, possiamo e dovremmo migliorare le metriche del modello di cui sopra, perfezionando i processi e migliorando i dataset campione. Tuttavia, per il bene di questo tutorial, fermiamoci qui. Se desideri una seconda parte di questo tutorial, per favore fammelo sapere!
Riepilogo
In questo tutorial abbiamo creato un modello di apprendimento automatico TensorFlow in grado di prevedere il sentimento di un determinato testo, dopo aver analizzato il set di dati campione.
Il codice completo e il file CSV di esempio possono essere scaricati e visualizzati nel repository GitHub - GitHub - Buzzpy/Tensorflow-ML-Model








