




















早在 2020 年,许多人就开始了大流行的爱好——他们可以在受到封锁限制的情况下全力投入其中。我选择了室内植物。
在大流行之前,我家里已经有一个小托儿所了。老实说,即使那样,每天照料每一株植物也很辛苦。查看它们中的哪些需要浇水,确保它们都得到适量的阳光,与它们交谈……#justHouseplantThings。
有更多时间在家意味着我可以在我的植物上投入更多。我做到了——我的时间、努力和金钱。我家有几十株盆栽植物;他们都有名字、个性(至少我是这么认为的),有些甚至有一双圆圆的眼睛。当我整天呆在家里时,这当然很好,但是,随着生活慢慢恢复正常,我发现自己陷入了困境:我再也没有时间跟踪我的植物了。我需要一个解决方案。必须有一种比每天手动检查植物更好的方法来监控我的植物。


输入 Apache Kafka®。好吧,真的,输入我想要培养另一个爱好的愿望:硬件项目。
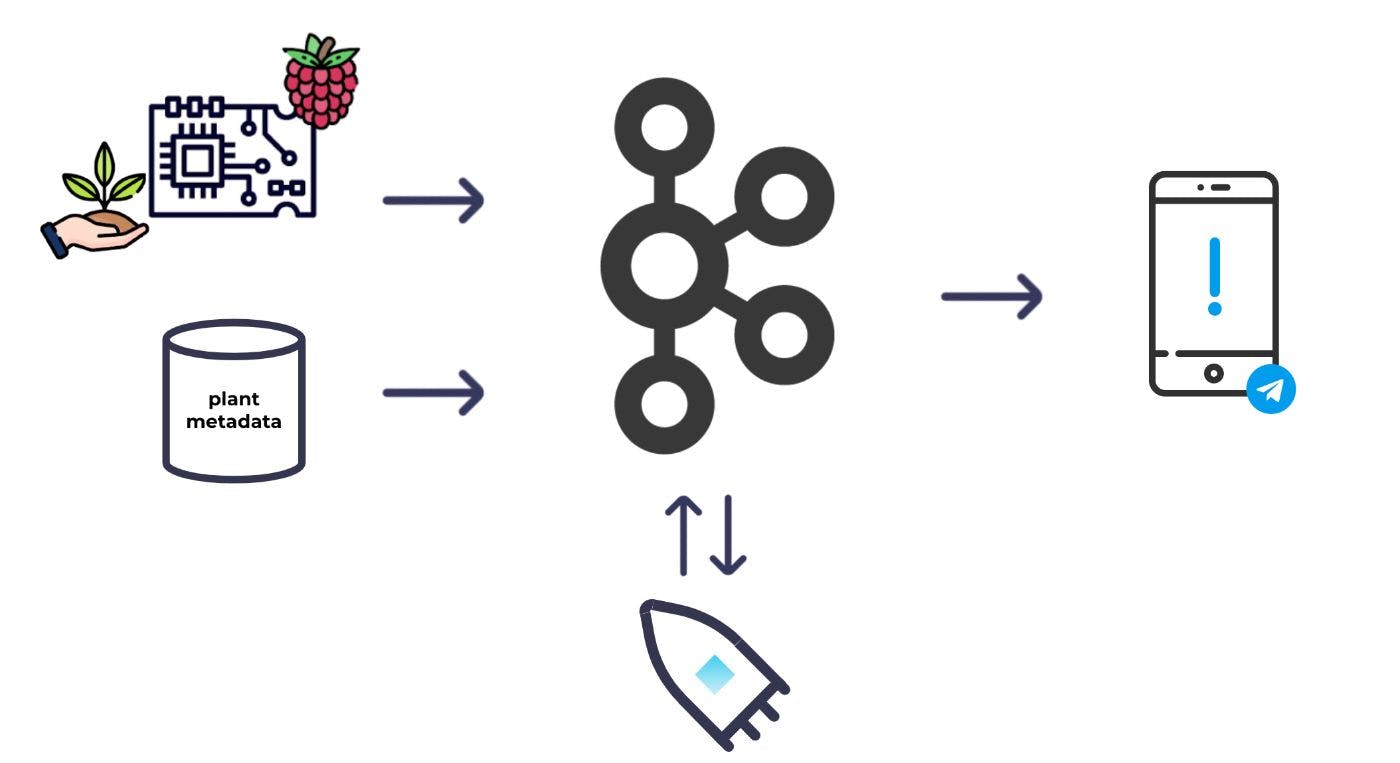
我一直想找个借口使用 Raspberry Pi 构建一个项目,我知道这是我的机会。我会建立一个系统来监控我的植物,只在它们需要注意时提醒我,而不是片刻之后。我会使用 Kafka 作为主干。
这实际上是一个非常有用的项目。它解决了我遇到的一个非常现实的问题,并让我有机会将我对室内植物的痴迷与我最终在家里使用 Kafka 的渴望结合起来。所有这些都巧妙地包含在一个简单易用的硬件项目中,任何人都可以自己实施。
如果您和我一样,并且遇到了只能通过家庭自动化来解决的室内植物问题,或者即使您与我完全不同,但仍然想要深入研究一个很酷的项目,那么这篇博文适合您.
让我们撸起袖子动手吧!
种下种子
首先,我坐下来弄清楚我想从这个项目中实现什么。对于系统的第一阶段,能够监测我的植物的水分含量并接收有关它们的警报将非常有帮助——毕竟,照顾我的植物最耗时的部分是决定哪些需要照顾。如果这个系统可以处理那个决策过程,我会节省很多时间!
在高层次上,这是我设想的基本系统:


我会在土壤中放置一些湿度传感器并将它们连接到 Raspberry Pi;然后我可以定期获取湿度读数并将其放入 Kafka 中。除了水分读数外,我还需要每种植物的一些元数据,以便决定哪些植物需要浇水。我也会将元数据生成到 Kafka 中。有了 Kafka 中的两个数据集,我就可以使用流处理来组合和丰富数据集,并计算哪些植物需要浇水。从那里,我可以触发警报。
确定了一组基本要求后,我进入了硬件和组装阶段。
抓东西的梗
像许多有自尊心的工程师一样,我通过大量谷歌搜索拉开了硬件阶段的序幕。我知道所有的部分都是为了让这个项目取得成功,但是,由于这是我第一次使用物理组件,所以我想确保我确切地知道我要做什么。
监控系统的主要目标是告诉我什么时候植物需要浇水,所以很明显,我需要某种湿度传感器。我了解到土壤湿度传感器有多种形状和尺寸,可作为模拟或数字组件使用,并且在测量湿度的方式上有所不同。最后,我选择了这些 I2C 电容式传感器。对于刚开始使用硬件的人来说,它们似乎是一个不错的选择:作为电容式传感器,它们比电阻式传感器的使用寿命更长,它们不需要模数转换,而且它们或多或少是即插即用的——玩。此外,他们还免费提供温度测量。
旁白:对于那些好奇的人,I2C 意味着内部集成电路。这些传感器中的每一个都通过一个唯一的地址进行通信;因此,为了从每个传感器获取数据,我需要设置并跟踪我使用的每个传感器的唯一地址——稍后要记住这一点。
决定传感器是我物理设置中最重要的部分。在硬件方面,剩下要做的就是弄到一个 Raspberry Pi 和一些设备。然后我就可以自由地开始构建系统了。
我使用了以下组件:
- 树莓派 4 B 型
- 半尺寸面包板 PCB
- 电容式土壤湿度传感器
- JST 螺距连接器套件
- 4股带状线
- 压接钳、剥线钳、焊锡、电烙铁(所有这些都是我在车库里随手找到的)


从土壤上...
虽然我希望这个项目简单易行且对初学者友好,但我也想挑战自己尽可能多地进行布线和焊接。为了向先辈致敬,我带着一些电线、一个压接器和一个梦想踏上了这次组装之旅。第一步是准备足够的带状线以将四个传感器连接到面包板,并将面包板连接到我的 Raspberry Pi。为了允许设置中组件之间的间距,我准备了 24 英寸的长度。每根电线都必须剥皮、压接并插入 JST 连接器(用于将传感器连接到面包板的电线)或母插座(用于连接到 Raspberry Pi 本身)。但是,当然,如果您想节省时间、精力和眼泪,我建议您不要压接自己的电线,而是提前购买准备好的电线。
旁白:鉴于我拥有的室内植物数量,在我的监控设置中使用四个传感器似乎是任意少的数量。如前所述,由于这些传感器是 I2C 设备,因此它们通信的任何信息都将使用唯一地址发送。也就是说,我购买的土壤湿度传感器都带有相同的默认地址,这对于您想要使用多个相同设备的设置来说是有问题的。有两种主要方法可以解决这个问题。第一个选项取决于设备本身。我的特定传感器背面有两个 I2C 地址跳线,焊接这些跳线的任意组合意味着我可以将 I2C 地址更改为 0x36 和 0x39 之间的范围。总的来说,我可以有四个唯一的地址,因此我在最终设置中使用了四个传感器。如果设备缺少更改地址的物理方法,则第二种选择是重新路由信息并使用多路复用设置代理地址。鉴于我是硬件新手,我觉得这超出了这个特定项目的范围。
准备好将传感器连接到 Raspberry Pi 的电线后,我通过使用测试 Python 脚本从单个传感器收集读数来确认一切设置正确。为了更加放心,我以相同的方式测试了其余三个传感器。正是在这个阶段,我亲身了解了交叉线如何影响电子元件……以及这些问题的调试难度。
接线终于可以正常工作后,我可以将所有传感器连接到 Raspberry Pi。所有传感器都需要连接到 Raspberry Pi 上的相同引脚(GND、3V3、SDA 和 SCL)。但是,每个传感器都有一个唯一的 I2C 地址,因此,尽管它们都通过相同的线路进行通信,但我仍然可以使用它们的地址从特定传感器获取数据。我所要做的就是将每个传感器连接到面包板,然后将面包板连接到 Raspberry Pi。为此,我使用了一些剩余的电线并使用焊料连接了面包板的柱子。然后我将 JST 连接器直接焊接到面包板上,这样我就可以轻松插入传感器。
将面包板连接到 Raspberry Pi、将传感器插入四个植物并通过测试脚本确认我可以从所有传感器读取数据后,我可以开始将数据生成到 Kafka 中。
百里香数据
在Raspberry Pi 设置和所有湿度传感器按预期工作的情况下,是时候将 Kafka 引入组合以开始流式传输一些数据了。
如您所料,在将任何数据写入 Kafka 之前,我需要一个 Kafka 集群。为了使该项目的软件组件尽可能轻量且易于设置,我选择使用Confluent Cloud作为我的 Kafka 提供商。这样做意味着我不需要设置或管理任何基础设施,而且我的 Kafka 集群在设置后几分钟内就可以准备就绪。
同样值得注意的是,为什么我选择在这个项目中使用 Kafka,特别是考虑到 MQTT 或多或少是从传感器流式传输 IoT 数据的事实标准。 Kafka 和 MQTT 都是为发布/订阅式消息传递而构建的,因此它们在这方面是相似的。但是,如果您打算构建一个像这个这样的数据流项目,MQTT 将无法胜任。您需要另一种技术(如 Kafka)来处理流处理、数据持久性和任何下游集成。底线是MQTT 和 Kafka 一起工作得很好。除了 Kafka,我绝对可以将 MQTT 用于我项目的 IoT 组件。相反,我决定直接与 Raspberry Pi 上的 Python 制作人合作。也就是说,如果您想将 MQTT 和 Kafka 用于任何受 IoT 启发的项目,请放心,您仍然可以使用MQTT Kafka Source Connector将 MQTT 数据导入 Kafka。
通过数据除草
在我将任何数据付诸行动之前,我退后一步来决定我想如何构建关于我的 Kafka 主题的消息。特别是对于像这样的 hack 项目,很容易开始将数据发射到 Kafka 主题中而无需担心 - 但重要的是要知道如何跨主题构建数据、将使用什么键以及数据字段中的类型。
那么让我们从主题开始吧。那些看起来怎么样?传感器具有捕捉湿度和温度的能力——这些读数应该写入单个主题还是多个主题?由于湿度和温度读数是同时从植物传感器捕获的,因此我将它们一起存储在同一条 Kafka 消息中。这两条信息一起构成了用于该项目目的的植物阅读。它们都属于同一个阅读主题。
除了传感器数据之外,我还需要一个主题来存储室内植物元数据,包括传感器正在监测的植物类型及其温度和湿度边界。该信息将在数据处理阶段用于确定读数何时应触发警报。
我创建了两个主题: houseplants-readings和houseplants-metadata 。我应该使用多少个分区?对于这两个主题,我决定使用 Confluent Cloud 中的默认分区数,在撰写本文时,默认分区数为 6。那是正确的数字吗?好吧,是的,不是。在这种情况下,由于我要处理的数据量很小,每个主题六个分区可能有点过头了,但如果以后我将这个项目扩展到更多工厂,最好有六个分区.
除了分区之外,另一个需要注意的重要配置参数是我在室内植物主题上启用的日志压缩。与“阅读”事件流不同,“元数据”主题包含参考数据或元数据。通过将它保存在一个紧凑的主题中,您可以确保数据永远不会过时,并且您将始终可以访问给定键的最后一个已知值(如果您还记得,该键是每个室内植物的唯一标识符)。
基于以上内容,我为读数和室内植物元数据编写了两个 Avro 模式(为了便于阅读,此处缩短)。
读数模式
{ "doc": "Houseplant reading taken from sensors.", "fields": [ {"name": "plant_id", "type": "int"}, {"name": "timestamp", "logicalType": "timestamp-millis", "type": "long"}, {"name": "moisture", "type": "float"}, {"name": "temperature", "type": "float"} ], "name": "reading", "namespace": "com.houseplants", "type": "record" }室内植物元数据模式
{ "doc": "Houseplant metadata.", "fields": [ {"name": "plant_id", "type": "int"}, {"name": "scientific_name", "type": "string"}, {"name": "common_name", "type": "string"}, {"name": "given_name", "type": "string"}, {"name": "temperature_threshold_low", "type": "float"}, {"name": "temperature_threshold_high", "type": "float"}, {"name": "moisture_threshold_low", "type": "float"}, {"name": "moisture_threshold_high", "type": "float"} ], "name": "houseplant", "namespace": "com.houseplants", "type": "record" }
如果您以前使用过 Kafka,您就会知道拥有主题并了解您的消息值是什么样的只是第一步。知道每条消息的密钥是什么同样重要。对于读数和元数据,我问自己每个数据集的实例是什么,因为实体实例应该构成 Kafka 中密钥的基础。由于读数是按植物进行的,元数据是按植物分配的,因此两个数据集的实体实例都是单个植物。我决定这两个主题的逻辑关键都基于植物。我会为每株植物分配一个数字 ID,并将该数字作为读数消息和元数据消息的关键。
因此,由于知道我正在以正确的方式进行此操作而产生的轻微自鸣得意的满足感,我可以将注意力转移到将数据从我的传感器流式传输到 Kafka 主题中。
培养讯息
我想开始将数据从我的传感器发送到 Kafka。第一步是在 Raspberry Pi 上安装confluent-kafka Python 库。从那里,我编写了一个Python 脚本来捕获传感器的读数并在 Kafka 中生成数据。
如果我告诉你这很容易,你会相信吗?只需几行代码,我的传感器数据就被写入并保存在 Kafka 主题中,以供下游分析使用。只是想想我还是有点头晕。


通过 Kafka 中的传感器读数,我现在需要室内植物元数据才能进行任何类型的下游分析。在典型的数据管道中,此类数据将驻留在关系数据库或其他一些数据存储中,并使用 Kafka Connect 和许多可用的连接器进行摄取。
我决定使用 Kafka 作为我的元数据的持久存储层,而不是启动我自己的外部数据库。对于少数植物的元数据,我使用另一个Python 脚本手动将数据直接写入 Kafka。
问题的根源
我的数据在卡夫卡;现在是时候真正动手了。但首先,让我们回顾一下我想通过这个项目实现的目标。总体目标是当我的植物水分含量低表明需要浇水时发出警报。我可以使用流处理来使用元数据丰富读数数据,然后计算新的数据流来驱动我的警报。
我选择将 ksqlDB 用于该管道的数据处理阶段,这样我就可以用最少的代码处理数据。结合 Confluent Cloud,ksqlDB 易于设置和使用——您只需提供一个应用程序上下文并编写一些简单的 SQL 即可开始加载和处理您的数据。
定义输入数据
在开始处理数据之前,我需要在 ksqlDB 应用程序中声明我的数据集,以便可以使用它。为此,我首先需要决定我的数据应该表示为两个一级 ksqlDB 对象中的哪一个TABLE或STREAM然后使用CREATE语句指向现有的 Kafka 主题。
室内植物读数数据在 ksqlDB 中表示为STREAM基本上与 Kafka 主题(一系列仅附加的不可变事件)完全相同,但也有一个模式。更方便的是,我之前已经设计并声明了模式,ksqlDB 可以直接从模式注册表中获取它:
CREATE STREAM houseplant_readings ( id STRING KEY ) WITH ( kafka_topic='houseplant-readings', format='AVRO', partitions=4 );
通过在 Kafka 主题上创建的流,我们可以使用标准 SQL 来查询和过滤它,以使用如下简单的语句来探索数据:
SELECT plant_id, moisture FROM HOUSEPLANT_READINGS EMIT CHANGES;


室内植物元数据需要多加考虑。虽然它存储为 Kafka 主题(就像读数数据一样),但它在逻辑上是一种不同类型的数据——它的状态。对于每一种植物,它都有一个名称、一个位置等等。我们将其存储在压缩的 Kafka 主题中,并在 ksqlDB 中将其表示为TABLE 。一张表——就像在常规 RDBMS 中一样——告诉我们给定键的当前状态。请注意,虽然 ksqlDB 从模式注册表中获取模式本身,但我们确实需要明确声明哪个字段代表表的主键。
CREATE TABLE houseplant_metadata ( id INTEGER PRIMARY KEY ) WITH ( kafka_topic='houseplant-metadata', format='AVRO', partitions=4 );丰富数据
在我的 ksqlDB 应用程序中注册了两个数据集后,下一步是使用houseplants表中包含的元数据来丰富houseplant_readings 。这将创建一个新流(由 Kafka 主题支持),其中包含相关工厂的阅读和元数据:
扩充查询类似于以下内容:
CREATE STREAM houseplant_readings_enriched WITH ( kafka_topic='houseplant-readings-enriched', format='AVRO', partitions=4 ) AS SELECT r.id AS plant_id, r.timestamp AS ts, r.moisture AS moisture, r.temperature AS temperature, h.scientific_name AS scientific_name, h.common_name AS common_name, h.given_name AS given_name, h.temperature_low AS temperature_low, h.temperature_high AS temperature_high, h.moisture_low AS moisture_low, h.moisture_high AS moisture_high FROM houseplant_readings AS r LEFT OUTER JOIN houseplants AS h ON houseplant_readings.id = houseplants.id PARTITION BY r.id EMIT CHANGES;
该查询的输出将是这样的:


在事件流上创建警报
回想本文的开头,您会记得所有这一切的全部意义在于告诉我植物何时需要浇水。我们有一系列水分(和温度)读数,我们有一张表格告诉我们每株植物的水分水平可能表明它需要浇水的阈值。但是我如何确定何时发送低湿度警报?我多久发送一次?
在试图回答这些问题时,我注意到一些关于我的传感器和它们生成的数据的事情。首先,我以五秒的间隔捕获数据。如果我要为每个低水分读数发送警报,我就会用警报淹没我的手机——那可不好。我宁愿每小时最多收到一次警报。在查看我的数据时我意识到的第二件事是传感器并不完美——我经常看到错误的低或错误的高读数,尽管随着时间的推移总的趋势是植物的水分含量会降低。
结合这两个观察结果,我决定在给定的 1 小时内,如果我看到 20 分钟的低水分读数,就可能足以发送警报。每 5 秒一个读数,即每小时 720 个读数,并且……在这里做一些数学运算,这意味着我需要在 1 小时内看到 240 个低读数才能发送警报。
所以我们现在要做的是创建一个新流,每 1 小时内每个植物最多包含一个事件。我通过编写以下查询实现了这一点:
CREATE TABLE houseplant_low_readings WITH ( kafka_topic='houseplant-low-readings', format='AVRO', partitions=4 ) AS SELECT plant_id, given_name, common_name, scientific_name, CONCAT(given_name, ' the ', common_name, ' (', scientific_name, ') is looking pretty dry...') AS message, COUNT(*) AS low_reading_count FROM houseplant_readings_enriched WINDOW TUMBLING (SIZE 1 HOURS, GRACE PERIOD 30 MINUTES) WHERE moisture < moisture_low GROUP BY plant_id, given_name, common_name, scientific_name HAVING COUNT(*) > 240 EMIT FINAL;
首先,您会注意到窗口聚合。此查询在非重叠的 1 小时窗口上运行,允许我在给定窗口内聚合每个植物 ID 的数据。非常简单。
我专门过滤并计算了丰富读数流中水分读数小于该植物低水分阈值的行。如果该计数至少为 240,我将输出一个结果,该结果将构成警报的基础。
但是您可能想知道为什么这个查询的结果在一个表中。好吧,正如我们所知,流代表了数据实体或多或少的完整历史,而表则反映了给定键的最新值。重要的是要记住,这个查询实际上是一个有状态的流应用程序。当消息在底层丰富的数据流上流动时,如果该特定消息满足过滤要求,我们会在 1 小时窗口内增加该植物 ID 的低读数计数,并在状态内跟踪它。然而,在这个查询中我真正关心的是聚合的最终结果——对于给定的键,低读数的计数是否超过 240。我想要一张桌子。
旁白:您会注意到该语句的最后一行是“EMIT FINAL”。这句话的意思是,我不会在每次新行流经流式应用程序时潜在地输出结果,而是等到窗口关闭后再发出结果。
此查询的结果是,对于特定一小时窗口内的给定植物 ID,我将根据需要最多输出一条警报消息。
分支出
在这一点上,我有一个由 ksqlDB 填充的 Kafka 主题,其中包含一条消息,当植物具有适当且持续的低水分水平时。但是我实际上如何从 Kafka 中获取这些数据呢?对我来说最方便的是直接在我的手机上接收这些信息。
我不打算在这里重新发明轮子,所以我利用了这篇描述使用 Telegram 机器人从 Kafka 主题读取消息并将警报发送到手机的博客文章。按照博客概述的流程,我创建了一个 Telegram 机器人并在我的手机上开始与该机器人对话,记下该对话的唯一 ID 以及我的机器人的 API 密钥。有了这些信息,我就可以使用 Telegram 聊天 API 将消息从我的机器人发送到我的手机。
这很好,但是我如何将警报从 Kafka 发送到我的 Telegram 机器人?我可以通过编写一个定制的消费者来调用消息发送,该消费者将使用来自 Kafka 主题的警报并通过 Telegram 聊天 API 手动发送每条消息。但这听起来像是额外的工作。相反,我决定使用完全托管的 HTTP 接收器连接器来做同样的事情,但我自己没有编写任何额外的代码。
几分钟后,我的 Telegram 机器人就可以开始行动了,我和机器人之间开始了私人聊天。使用聊天 ID,我现在可以使用 Confluent Cloud 上完全托管的 HTTP Sink 连接器将消息直接发送到我的手机。
完整配置如下所示:
{ "name": "HttpSinkConnector_Houseplants_Telegram_Bot", "config": { "topics": "houseplant-low-readings", "input.data.format": "AVRO", "connector.class": "HttpSink", "name": "HttpSinkConnector_Houseplants_Telegram_Bot", "kafka.auth.mode": "KAFKA_API_KEY", "http.api.url": "https://api.telegram.org/**********/sendMessage", "request.method": "POST", "headers": "Content-Type: application/json", "request.body.format": "string", "batch.max.size": "1", "batch.prefix": "{\"chat_id\":\"********\",", "batch.suffix": "}", "regex.patterns": ".*MESSAGE=(.*),LOW_READING_COUNT=(.*)}.*", "regex.replacements": "\"text\":\"$1\"", "regex.separator": "~", "tasks.max": "1" } }


启动连接器几天后,我收到了一条非常有用的消息,告诉我我的植物需要浇水。成功!


改过自新
自从我完成该项目的初始阶段以来,已经过去了大约一年。那时,我很高兴地报告我监测的所有植物都快乐健康!我不再需要花费任何额外的时间来检查它们,我可以完全依赖流数据管道生成的警报。多么酷啊?


如果构建此项目的过程引起您的兴趣,我鼓励您开始使用自己的流数据管道。无论您是想要挑战自己在自己的生活中构建和整合实时管道的经验丰富的 Kafka 用户,还是完全不熟悉 Kafka 的人,我都在这里告诉您,这些类型的项目适合您。
也发布在这里。








