





















2020 সালে, অনেক লোক মহামারী শখগুলি বেছে নিয়েছিল - যে জিনিসগুলি তারা লকডাউন দ্বারা সীমাবদ্ধ থাকাকালীন নিজেকে সম্পূর্ণ শক্তিতে নিক্ষেপ করতে পারে। আমি বাড়ির গাছপালা বেছে নিয়েছি।
মহামারীর আগে, আমার বাড়িতে একটি ছোট নার্সারির পরিমাণ ছিল। সত্যি বলতে, তারপরেও, প্রতিদিন প্রতিটি গাছের যত্ন নেওয়া অনেক কাজ ছিল। তাদের মধ্যে কাকে জল দেওয়া দরকার তা দেখে, তারা সবাই সঠিক পরিমাণে সূর্যালোক পেয়েছে তা নিশ্চিত করে, তাদের সাথে কথা বলে… #justHouseplantThings.
বাড়িতে আরও সময় থাকার মানে হল যে আমি আমার গাছগুলিতে আরও বিনিয়োগ করতে পারি। এবং আমি করেছি—আমার সময়, প্রচেষ্টা এবং অর্থ। আমার বাড়িতে কয়েক ডজন হাউসপ্ল্যান্ট আছে; তাদের সবার নাম, ব্যক্তিত্ব আছে (অন্তত আমি তাই মনে করি), এবং কারো কারো চোখও আছে। আমি সারাদিন বাড়িতে থাকার সময় অবশ্যই এটি ঠিক ছিল, কিন্তু, জীবন ধীরে ধীরে স্বাভাবিক হয়ে যাওয়ার সাথে সাথে আমি নিজেকে একটি কঠিন অবস্থানে পেয়েছি: আমার গাছপালাগুলির ট্র্যাক রাখার জন্য পৃথিবীতে আমার আর সময় ছিল না। আমি একটি সমাধান প্রয়োজন. প্রতিদিন ম্যানুয়ালি পরীক্ষা করার চেয়ে আমার গাছপালা নিরীক্ষণ করার আরও ভাল উপায় থাকতে হবে।


Apache Kafka® লিখুন। ঠিক আছে, সত্যিই, আমার আরেকটি শখ বাছাই করার ইচ্ছা লিখুন: হার্ডওয়্যার প্রকল্প।
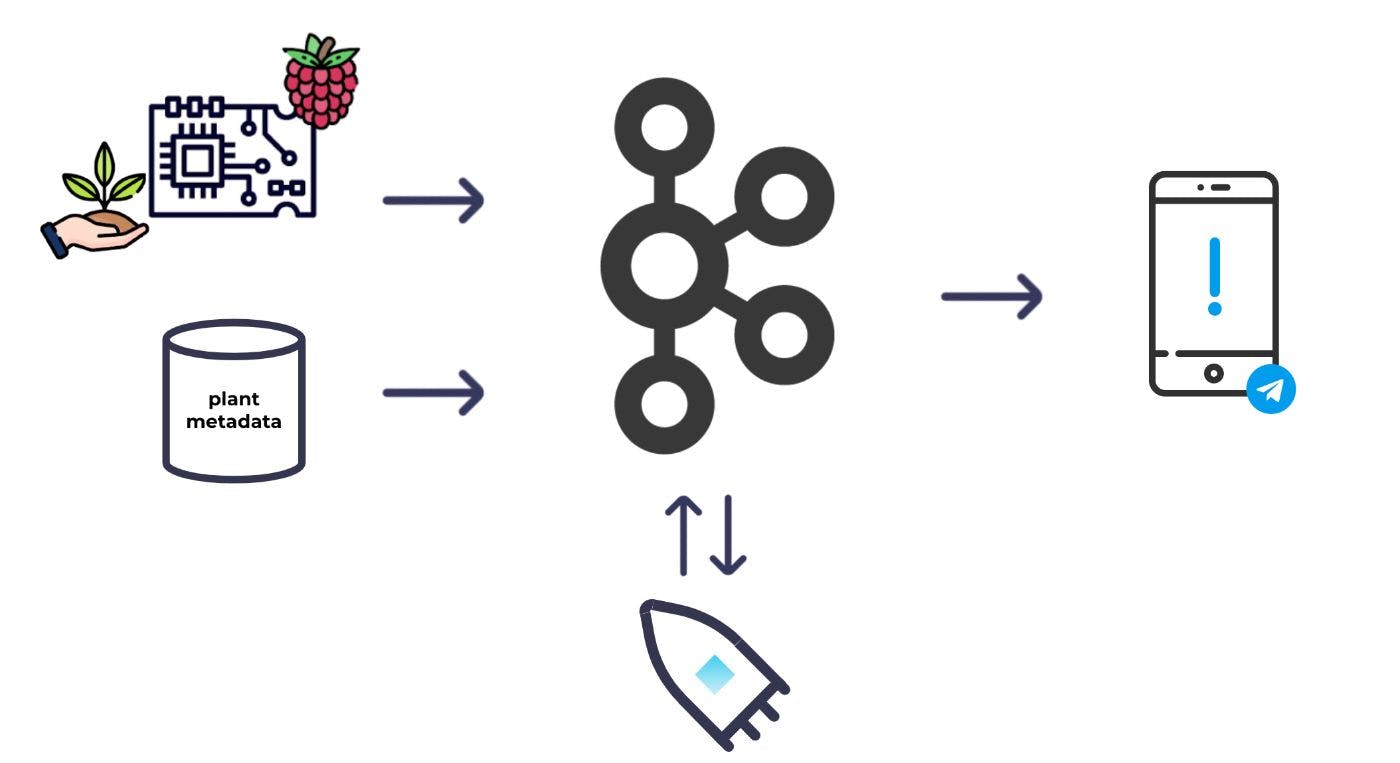
আমি সবসময় একটি রাস্পবেরি পাই ব্যবহার করে একটি প্রকল্প তৈরি করার জন্য একটি অজুহাত চেয়েছি এবং আমি জানতাম যে এটি আমার সুযোগ। আমি এমন একটি সিস্টেম তৈরি করব যা আমার গাছপালা পর্যবেক্ষণ করতে পারে শুধুমাত্র তখনই আমাকে সতর্ক করতে যখন তাদের মনোযোগের প্রয়োজন হয় এবং এক মুহূর্ত পরে নয়। আর আমি কাফকাকে মেরুদণ্ড হিসেবে ব্যবহার করব।
এটি আসলে একটি খুব দরকারী প্রকল্প হতে পরিণত. এটি আমার একটি খুব বাস্তব সমস্যার সমাধান করেছে এবং অবশেষে কাফকাকে বাড়িতে ব্যবহার করার জন্য আমার চুলকানির আকাঙ্ক্ষার সাথে আমার বাড়ির গাছের আবেশকে একত্রিত করার সুযোগ দিয়েছে। এই সমস্ত একটি সহজ এবং অ্যাক্সেসযোগ্য হার্ডওয়্যার প্রকল্পে সুন্দরভাবে আবৃত করা হয়েছিল যা যে কেউ নিজেরাই বাস্তবায়ন করতে পারে।
আপনি যদি আমার মতো হন এবং আপনার একটি হাউসপ্ল্যান্টের সমস্যা থাকে যা শুধুমাত্র আপনার বাড়ির স্বয়ংক্রিয়তার মাধ্যমে সমাধান করা যেতে পারে, অথবা আপনি যদি আমার মতো নাও হন তবে আপনি এখনও একটি দুর্দান্ত প্রকল্পের সন্ধান করতে চান, এই ব্লগ পোস্টটি আপনার জন্য .
আসুন আমাদের হাতা গুটানো এবং আমাদের হাত নোংরা করি!
বীজ রোপণ
প্রথমে, আমি এই প্রকল্প থেকে কী অর্জন করতে চাই তা বের করতে বসেছিলাম। সিস্টেমের প্রথম ধাপের জন্য, আমার উদ্ভিদের আর্দ্রতার মাত্রা নিরীক্ষণ করতে এবং সেগুলি সম্পর্কে সতর্কতা গ্রহণ করতে সক্ষম হওয়া খুবই সহায়ক হবে- সর্বোপরি, আমার উদ্ভিদের যত্ন নেওয়ার সবচেয়ে সময়সাপেক্ষ অংশটি ছিল কোনটির যত্ন নেওয়া দরকার তা নির্ধারণ করা। যদি এই সিস্টেমটি সিদ্ধান্ত নেওয়ার প্রক্রিয়াটি পরিচালনা করতে পারে তবে আমি এক টন সময় বাঁচাতে পারব!
একটি উচ্চ স্তরে, এই মৌলিক সিস্টেম যা আমি কল্পনা করেছি:


আমি মাটিতে কিছু আর্দ্রতা সেন্সর রাখব এবং এগুলিকে একটি রাস্পবেরি পাইতে লাগিয়ে দেব; আমি তখন নিয়মিত আর্দ্রতা রিডিং নিতে পারতাম এবং সেগুলো কাফকার মধ্যে ফেলে দিতে পারতাম। আর্দ্রতা রিডিং ছাড়াও, কোন গাছে জল দেওয়া দরকার তা নির্ধারণ করার জন্য প্রতিটি গাছের জন্য আমার কিছু মেটাডেটাও প্রয়োজন। আমি কাফকাতেও মেটাডেটা তৈরি করব। কাফকার উভয় ডেটাসেটের সাথে, আমি তখন স্ট্রিম প্রসেসিং ব্যবহার করে ডেটাসেটগুলিকে একে অপরের সাথে একত্রিত করতে এবং সমৃদ্ধ করতে পারি এবং কোন গাছগুলিতে জল দেওয়া দরকার তা গণনা করতে পারি। সেখান থেকে, আমি একটি সতর্কতা ট্রিগার করতে পারি।
মৌলিক প্রয়োজনীয়তার সেটের সাথে, আমি হার্ডওয়্যার এবং সমাবেশ পর্বে প্রবেশ করেছি।
জিনিসের ডালপালা নেওয়া
অনেক স্ব-সম্মানিত প্রকৌশলীর মতো, আমি এক টন গুগলিং দিয়ে হার্ডওয়্যার স্টেজ শুরু করেছি। আমি জানতাম যে এই প্রকল্পটিকে সফল করার জন্য সমস্ত অংশই বিদ্যমান ছিল, কিন্তু, যেহেতু এটি আমার প্রথমবারের মতো শারীরিক উপাদানগুলির সাথে কাজ করা ছিল, আমি নিশ্চিত করতে চেয়েছিলাম যে আমি ঠিক কী জানি তা আমি জানি৷
মনিটরিং সিস্টেমের মূল লক্ষ্য ছিল আমাকে বলা যে কখন গাছপালাকে জল দিতে হবে, তাই স্পষ্টতই, আমার কিছু ধরণের আর্দ্রতা সেন্সর দরকার ছিল। আমি শিখেছি যে মাটির আর্দ্রতা সেন্সরগুলি বিভিন্ন আকার এবং আকারে আসে, এনালগ বা ডিজিটাল উপাদান হিসাবে পাওয়া যায় এবং তারা যে পদ্ধতিতে আর্দ্রতা পরিমাপ করে তার মধ্যে পার্থক্য রয়েছে। শেষ পর্যন্ত, আমি এই I2C ক্যাপাসিটিভ সেন্সরগুলিতে স্থির হয়েছি। হার্ডওয়্যার দিয়ে শুরু করা কারো জন্য এগুলি একটি দুর্দান্ত বিকল্প বলে মনে হয়েছিল: ক্যাপাসিটিভ সেন্সর হিসাবে, তারা প্রতিরোধী-ভিত্তিকগুলির চেয়ে বেশি সময় ধরে থাকবে, তাদের কোনও অ্যানালগ-টু-ডিজিটাল রূপান্তরের প্রয়োজন নেই এবং তারা কমবেশি প্লাগ-এবং- খেলা এছাড়াও, তারা বিনামূল্যে তাপমাত্রা পরিমাপের প্রস্তাব দেয়।
একটি পাশে: যারা কৌতূহলী তাদের জন্য, I2C মানে ইন্টার-ইন্টিগ্রেটেড সার্কিট। এই সেন্সরগুলির প্রতিটি একটি অনন্য ঠিকানার মাধ্যমে যোগাযোগ করে; তাই প্রতিটি সেন্সর থেকে ডেটা সংগ্রহ করার জন্য, আমি ব্যবহার করি এমন প্রতিটি সেন্সরের জন্য আমাকে অনন্য ঠিকানা সেট করতে হবে এবং ট্র্যাক করতে হবে—কিছুটা পরে মনে রাখতে হবে।
সেন্সর সম্পর্কে সিদ্ধান্ত নেওয়া আমার শারীরিক সেটআপের সবচেয়ে বড় অংশ ছিল। হার্ডওয়্যারের পথে যা করা বাকি ছিল তা হল একটি রাস্পবেরি পাই এবং কয়েক টুকরো সরঞ্জাম রাখা। তারপর আমি সিস্টেম বিল্ডিং শুরু বিনামূল্যে ছিল.
আমি নিম্নলিখিত উপাদান ব্যবহার করেছি:
- রাস্পবেরি পাই 4 মডেল বি
- অর্ধ-আকারের ব্রেডবোর্ড পিসিবি
- ক্যাপাসিটিভ মাটির আর্দ্রতা সেন্সর
- JST পিচ সংযোগকারী কিট
- 4 স্ট্র্যান্ড ফিতা তারের
- ক্রিম্পার, তারের স্ট্রিপার, সোল্ডার, সোল্ডারিং আয়রন (যা সবই আমি সুবিধামত আমার গ্যারেজে পেয়েছি)


মাটি থেকে উপরে…
যদিও আমি এই প্রকল্পটি সহজ এবং শিক্ষানবিস-বান্ধব হতে চেয়েছিলাম, আমি যতটা সম্ভব তারের এবং সোল্ডারিং করার জন্য নিজেকে চ্যালেঞ্জ করতে চেয়েছিলাম। আমার আগে যারা এসেছিল তাদের সম্মান জানাতে, আমি কিছু তার, একটি ক্রিম্পার এবং একটি স্বপ্ন নিয়ে এই সমাবেশ যাত্রা শুরু করেছি। প্রথম ধাপটি ছিল ব্রেডবোর্ডের সাথে চারটি সেন্সর সংযুক্ত করার জন্য পর্যাপ্ত ফিতা তার প্রস্তুত করা এবং আমার রাস্পবেরি পাইয়ের সাথে ব্রেডবোর্ড সংযোগ করা। সেটআপে উপাদানগুলির মধ্যে ব্যবধানের অনুমতি দেওয়ার জন্য, আমি 24" দৈর্ঘ্য প্রস্তুত করেছি। প্রতিটি তারকে একটি JST সংযোগকারী (সেন্সরগুলিকে ব্রেডবোর্ডের সাথে সংযোগকারী তারের জন্য) অথবা একটি মহিলা সকেট (রাস্পবেরি পাইয়ের সাথে সংযোগ করার জন্য) হয় ছিনতাই, ক্রিম করা এবং প্লাগ করতে হয়েছিল। তবে, অবশ্যই, আপনি যদি সময়, প্রচেষ্টা এবং অশ্রু বাঁচাতে চান তবে আমি সুপারিশ করব যে আপনি আপনার নিজের তারগুলিকে ক্রাম্প করবেন না এবং পরিবর্তে সময়ের আগে প্রস্তুত তারগুলি কিনুন৷
একদিকে: আমার মালিকানাধীন হাউসপ্ল্যান্টের সংখ্যা বিবেচনা করে, চারটি আমার মনিটরিং সেটআপে ব্যবহার করার জন্য যথেচ্ছভাবে কম সংখ্যক সেন্সর বলে মনে হতে পারে। আগেই বলা হয়েছে, যেহেতু এই সেন্সরগুলি হল I2C ডিভাইস, তাই তারা যোগাযোগ করে এমন যেকোন তথ্য একটি অনন্য ঠিকানা ব্যবহার করে পাঠানো হবে। এটি বলেছে, আমি যে মাটির আর্দ্রতা সেন্সরগুলি কিনেছি সেগুলি একই ডিফল্ট ঠিকানা দিয়ে পাঠানো হয়েছে, যা এই ধরনের সেটআপগুলির জন্য সমস্যাযুক্ত যেখানে আপনি একই ডিভাইসের একাধিক ব্যবহার করতে চান৷ এই চারপাশে পেতে দুটি প্রধান উপায় আছে. প্রথম বিকল্পটি ডিভাইসের উপর নির্ভর করে। আমার নির্দিষ্ট সেন্সরের পিছনে দুটি I2C অ্যাড্রেস জাম্পার ছিল, এবং এইগুলির যে কোনও সংমিশ্রণ সোল্ডার করার অর্থ হল যে আমি I2C ঠিকানাটি 0x36 এবং 0x39 থেকে পরিসরে পরিবর্তন করতে পারি। মোট, আমার চারটি অনন্য ঠিকানা থাকতে পারে, তাই আমি চূড়ান্ত সেটআপে চারটি সেন্সর ব্যবহার করি। যদি ডিভাইসগুলিতে ঠিকানা পরিবর্তন করার জন্য কোনও শারীরিক উপায়ের অভাব থাকে, তবে দ্বিতীয় বিকল্পটি হল তথ্য পুনঃরুট করা এবং মাল্টিপ্লেক্স ব্যবহার করে প্রক্সি ঠিকানা সেট আপ করা। প্রদত্ত যে আমি হার্ডওয়্যারে নতুন, আমি অনুভব করেছি যে এটি এই বিশেষ প্রকল্পের সুযোগের বাইরে ছিল।
সেন্সরগুলিকে রাস্পবেরি পাইয়ের সাথে সংযুক্ত করার জন্য তারগুলি প্রস্তুত করার পরে, আমি নিশ্চিত করেছি যে একটি একক সেন্সর থেকে রিডিং সংগ্রহ করার জন্য একটি পরীক্ষা পাইথন স্ক্রিপ্ট ব্যবহার করে সবকিছু সঠিকভাবে সেট আপ করা হয়েছে৷ অতিরিক্ত আশ্বাসের জন্য, আমি একইভাবে বাকি তিনটি সেন্সর পরীক্ষা করেছি। এবং এই পর্যায়ে আমি নিজেই শিখেছি কিভাবে ক্রস করা তারগুলি ইলেকট্রনিক উপাদানগুলিকে প্রভাবিত করে... এবং এই সমস্যাগুলি ডিবাগ করা কতটা কঠিন।
ওয়্যারিং শেষ পর্যন্ত কাজের ক্রমে, আমি রাস্পবেরি পাই-তে সমস্ত সেন্সর সংযোগ করতে পারি। রাস্পবেরি পাইতে সমস্ত সেন্সরকে একই পিনের (GND, 3V3, SDA, এবং SCL) সাথে সংযুক্ত করতে হবে। প্রতিটি সেন্সরের একটি অনন্য I2C ঠিকানা রয়েছে, যদিও, তাই, যদিও তারা সবাই একই তারের মাধ্যমে যোগাযোগ করছে, তবুও আমি তাদের ঠিকানা ব্যবহার করে নির্দিষ্ট সেন্সর থেকে ডেটা পেতে পারি। আমাকে যা করতে হয়েছিল তা হল প্রতিটি সেন্সরকে ব্রেডবোর্ডে তারের এবং তারপরে ব্রেডবোর্ডটিকে রাস্পবেরি পাইয়ের সাথে সংযুক্ত করতে হবে। এটি অর্জন করতে, আমি কিছুটা অবশিষ্ট তারের ব্যবহার করেছি এবং সোল্ডার ব্যবহার করে ব্রেডবোর্ডের কলামগুলি সংযুক্ত করেছি। আমি তখন JST কানেক্টরগুলিকে সরাসরি ব্রেডবোর্ডে সোল্ডার করেছি যাতে আমি সহজেই সেন্সর প্লাগ করতে পারি।
রাস্পবেরি পাই-এর সাথে ব্রেডবোর্ড সংযোগ করার পরে, চারটি প্ল্যান্টে সেন্সর ঢোকানো এবং পরীক্ষার স্ক্রিপ্টের মাধ্যমে নিশ্চিত করা যে আমি সমস্ত সেন্সর থেকে ডেটা পড়তে পারি, আমি কাফকাতে ডেটা তৈরি করার কাজ শুরু করতে পারি।
বাস্তব-থাইম ডেটা
রাস্পবেরি পাই সেটআপ এবং সমস্ত আর্দ্রতা সেন্সর প্রত্যাশিতভাবে কাজ করার সাথে সাথে, কিছু ডেটা স্ট্রিমিং শুরু করার জন্য কাফকাকে মিশ্রণে আনার সময় এসেছে৷
আপনি যেমন আশা করতে পারেন, আমি কাফকাতে কোনো ডেটা লিখতে পারার আগে আমার একটি কাফকা ক্লাস্টার দরকার ছিল। এই প্রকল্পের সফ্টওয়্যার উপাদানটিকে যতটা সম্ভব লাইটওয়েট এবং সেট আপ করা সহজ করতে চাই, আমি আমার কাফকা প্রদানকারী হিসাবে কনফ্লুয়েন্ট ক্লাউড ব্যবহার করা বেছে নিয়েছি। এটি করার অর্থ হল যে আমাকে কোন অবকাঠামো সেট আপ বা পরিচালনা করার প্রয়োজন নেই এবং আমার কাফকা ক্লাস্টার এটি সেট আপ করার কয়েক মিনিটের মধ্যেই প্রস্তুত ছিল।
আমি কেন এই প্রকল্পের জন্য কাফকা ব্যবহার করতে বেছে নিয়েছি তাও লক্ষ করার মতো, বিশেষ করে সেন্সর থেকে আইওটি ডেটা স্ট্রিম করার জন্য এমকিউটিটি কমবেশি ডি ফ্যাক্টো স্ট্যান্ডার্ড। কাফকা এবং এমকিউটিটি উভয়ই পাব/সাব-স্টাইল মেসেজিংয়ের জন্য তৈরি করা হয়েছে, তাই তারা সেই ক্ষেত্রে একই রকম। কিন্তু আপনি যদি এটির মতো একটি ডেটা স্ট্রিমিং প্রকল্প তৈরি করার পরিকল্পনা করেন তবে MQTT কম পড়বে। স্ট্রীম প্রসেসিং, ডেটা স্থিরতা এবং যেকোনো ডাউনস্ট্রিম ইন্টিগ্রেশন পরিচালনা করতে আপনার কাফকার মতো আরেকটি প্রযুক্তির প্রয়োজন। নীচের লাইন হল যে MQTT এবং কাফকা সত্যিই একসাথে কাজ করে । কাফকা ছাড়াও, আমি অবশ্যই আমার প্রকল্পের IoT উপাদানের জন্য MQTT ব্যবহার করতে পারতাম। পরিবর্তে, আমি রাস্পবেরি পাইতে পাইথন প্রযোজকের সাথে সরাসরি কাজ করার সিদ্ধান্ত নিয়েছি। এতে বলা হয়েছে, আপনি যদি কোনো IoT-অনুপ্রাণিত প্রকল্পের জন্য MQTT এবং Kafka ব্যবহার করতে চান, তবে নিশ্চিত থাকুন যে আপনি এখনও MQTT Kafka উৎস সংযোগকারী ব্যবহার করে আপনার MQTT ডেটা কাফকাতে পেতে পারেন।
তথ্য মাধ্যমে আগাছা
আমি যেকোন ডেটাকে গতিশীল করার আগে, আমি আমার কাফকা বিষয়ের বার্তাগুলিকে কীভাবে গঠন করতে চাই তা সিদ্ধান্ত নিতে আমি এক ধাপ পিছিয়ে নিয়েছিলাম। বিশেষ করে এই ধরনের হ্যাক প্রজেক্টের জন্য, বিশ্বের কোনো চিন্তা ছাড়াই কাফকা বিষয়ের মধ্যে ডেটা ফায়ার করা শুরু করা সহজ—কিন্তু বিষয়গুলি জুড়ে আপনি কীভাবে আপনার ডেটা গঠন করবেন, আপনি কোন কী ব্যবহার করবেন এবং ডেটা কী হবে তা জানা গুরুত্বপূর্ণ। ক্ষেত্রের ধরন।
তো চলুন শুরু করা যাক বিষয়গুলো দিয়ে। সেগুলি দেখতে কেমন হবে? সেন্সরগুলির আর্দ্রতা এবং তাপমাত্রা ক্যাপচার করার ক্ষমতা ছিল - এই রিডিংগুলি কি একটি একক বিষয়ে বা একাধিক লেখা উচিত? যেহেতু একই সময়ে একটি উদ্ভিদের সেন্সর থেকে আর্দ্রতা এবং তাপমাত্রার রিডিং উভয়ই ক্যাপচার করা হচ্ছিল, তাই আমি একই কাফকা বার্তায় সেগুলি একসাথে সংরক্ষণ করেছি। একত্রে, তথ্যের সেই দুটি অংশে এই প্রকল্পের উদ্দেশ্যে একটি উদ্ভিদ পাঠ করা ছিল। এটা সব একই পড়ার বিষয় যেতে হবে.
সেন্সর ডেটা ছাড়াও, সেন্সর যে ধরনের উদ্ভিদ পর্যবেক্ষণ করছে এবং এর তাপমাত্রা এবং আর্দ্রতার সীমানা সহ হাউসপ্ল্যান্ট মেটাডেটা সংরক্ষণ করার জন্য আমার একটি বিষয়ের প্রয়োজন ছিল। এই তথ্যটি ডেটা প্রসেসিং পর্যায়ে ব্যবহার করা হবে তা নির্ধারণ করতে কখন একটি রিডিং একটি সতর্কতা ট্রিগার করবে।
আমি দুটি বিষয় তৈরি করেছি: houseplants-readings এবং houseplants-metadata । আমি কয়টি পার্টিশন ব্যবহার করব? উভয় বিষয়ের জন্য, আমি কনফ্লুয়েন্ট ক্লাউডে পার্টিশনের ডিফল্ট সংখ্যা ব্যবহার করার সিদ্ধান্ত নিয়েছি যা লেখার সময় ছয়টি। যে সঠিক সংখ্যা ছিল? ভাল, হ্যাঁ এবং না. এই ক্ষেত্রে, আমি যে ডেটা নিয়ে কাজ করছি তার কম ভলিউমের কারণে, প্রতি বিষয়ের জন্য ছয়টি পার্টিশন ওভারকিল হতে পারে, কিন্তু যদি আমি এই প্রকল্পটি পরবর্তীতে আরও প্ল্যান্টে প্রসারিত করি, তাহলে ছয়টি পার্টিশন থাকা ভালো হবে। .
পার্টিশন ছাড়াও, আরেকটি গুরুত্বপূর্ণ কনফিগারেশন প্যারামিটার যা নোট করতে হবে তা হল লগ কমপ্যাকশন যা আমি হাউসপ্ল্যান্ট বিষয়ে সক্রিয় করেছি। ইভেন্টের `রিডিং` স্ট্রীমের বিপরীতে, `মেটাডেটা` বিষয় রেফারেন্স ডেটা—বা মেটাডেটা ধারণ করে। এটিকে একটি সংক্ষিপ্ত বিষয়ের মধ্যে ধরে রেখে আপনি নিশ্চিত করেন যে ডেটা কখনই বৃদ্ধ হবে না এবং আপনার কাছে সর্বদা একটি প্রদত্ত কী (কী, যদি আপনি মনে রাখেন, প্রতিটি হাউসপ্ল্যান্টের জন্য একটি অনন্য শনাক্তকারী) এর সর্বশেষ পরিচিত মানটি অ্যাক্সেস করতে পারবেন।
উপরের উপর ভিত্তি করে, আমি রিডিং এবং হাউসপ্ল্যান্ট মেটাডেটা উভয়ের জন্য দুটি অভ্র স্কিমা লিখেছি (পঠনযোগ্যতার জন্য এখানে সংক্ষিপ্ত করা হয়েছে)।
রিডিং স্কিমা
{ "doc": "Houseplant reading taken from sensors.", "fields": [ {"name": "plant_id", "type": "int"}, {"name": "timestamp", "logicalType": "timestamp-millis", "type": "long"}, {"name": "moisture", "type": "float"}, {"name": "temperature", "type": "float"} ], "name": "reading", "namespace": "com.houseplants", "type": "record" }হাউসপ্ল্যান্ট মেটাডেটা স্কিমা
{ "doc": "Houseplant metadata.", "fields": [ {"name": "plant_id", "type": "int"}, {"name": "scientific_name", "type": "string"}, {"name": "common_name", "type": "string"}, {"name": "given_name", "type": "string"}, {"name": "temperature_threshold_low", "type": "float"}, {"name": "temperature_threshold_high", "type": "float"}, {"name": "moisture_threshold_low", "type": "float"}, {"name": "moisture_threshold_high", "type": "float"} ], "name": "houseplant", "namespace": "com.houseplants", "type": "record" }
আপনি যদি আগে কাফকা ব্যবহার করে থাকেন, আপনি জানেন যে বিষয়গুলি থাকা এবং আপনার বার্তার মানগুলি কেমন তা জানা হল প্রথম পদক্ষেপ। প্রতিটি বার্তার জন্য কী কী হবে তা জানা ঠিক ততটাই গুরুত্বপূর্ণ৷ রিডিং এবং মেটাডেটা উভয়ের জন্য, আমি নিজেকে জিজ্ঞাসা করেছি যে এই প্রতিটি ডেটাসেটের একটি উদাহরণ কী হবে, কারণ এটি এমন একটি সত্তা উদাহরণ যা কাফকার একটি কী-এর ভিত্তি তৈরি করা উচিত। যেহেতু প্রতি উদ্ভিদের রিডিং নেওয়া হচ্ছে এবং প্রতি উদ্ভিদের জন্য মেটাডেটা বরাদ্দ করা হয়েছে, উভয় ডেটাসেটের একটি সত্তা উদাহরণ ছিল একটি পৃথক উদ্ভিদ। আমি সিদ্ধান্ত নিয়েছি যে উভয় বিষয়ের যৌক্তিক কী উদ্ভিদের উপর ভিত্তি করে হবে। আমি প্রতিটি প্ল্যান্টে একটি সংখ্যাসূচক আইডি বরাদ্দ করব এবং সেই নম্বরটি রিডিং বার্তা এবং মেটাডেটা বার্তা উভয়েরই চাবিকাঠি হবে।
তাই আমি এই সম্পর্কে সঠিক পথে যাচ্ছি জেনে যে কিছুটা সন্তুষ্টির অনুভূতি আসে, আমি আমার সেন্সর থেকে ডেটা কাফকা বিষয়গুলিতে স্ট্রিম করার দিকে মনোযোগ দিতে পারি।
বার্তা চাষ
আমি আমার সেন্সর থেকে ডাটা কাফকার কাছে পাঠানো শুরু করতে চেয়েছিলাম। প্রথম ধাপটি ছিল রাস্পবেরি পাইতে confluent-kafka পাইথন লাইব্রেরি ইনস্টল করা। সেখান থেকে, আমি আমার সেন্সর থেকে রিডিং ক্যাপচার করতে এবং কাফকাতে ডেটা তৈরি করতে একটি পাইথন স্ক্রিপ্ট লিখেছিলাম।
আমি যদি আপনাকে বলি যে এটি এত সহজ ছিল আপনি কি এটি বিশ্বাস করবেন? কোডের মাত্র কয়েক লাইনের সাথে, আমার সেন্সর ডেটা ডাউনস্ট্রিম অ্যানালিটিক্সে ব্যবহারের জন্য একটি কাফকা টপিক-এ লেখা হয়েছিল এবং স্থির ছিল। আমি এখনও এটি সম্পর্কে চিন্তা করে একটু ঘাবড়ে যাই।


কাফকাতে সেন্সর রিডিংয়ের সাথে, আমার এখন প্রয়োজন ছিল হাউসপ্ল্যান্ট মেটাডেটা যাতে যেকোনো ধরণের ডাউনস্ট্রিম বিশ্লেষণ পরিচালনা করতে হয়। সাধারণ ডেটা পাইপলাইনগুলিতে, এই ধরণের ডেটা একটি রিলেশনাল ডাটাবেস বা অন্য কোনও ডেটা স্টোরে থাকবে এবং কাফকা কানেক্ট এবং এর জন্য উপলব্ধ অনেকগুলি সংযোগকারী ব্যবহার করে গৃহীত হবে।
আমার নিজের একটি বাহ্যিক ডাটাবেস স্পিন আপ করার পরিবর্তে, আমি আমার মেটাডেটার জন্য স্থায়ী স্টোরেজ স্তর হিসাবে কাফকা ব্যবহার করার সিদ্ধান্ত নিয়েছি। মাত্র কয়েকটি গাছের মেটাডেটা সহ, আমি অন্য পাইথন স্ক্রিপ্ট ব্যবহার করে সরাসরি কাফকার কাছে ডাটা লিখেছিলাম।
সমস্যার মূল
আমার ডেটা কাফকাতে আছে; এখন সত্যিই আমার হাত নোংরা করার সময়। কিন্তু প্রথমে, আসুন এই প্রকল্পের সাথে আমি কী অর্জন করতে চেয়েছিলাম তা আবার দেখা যাক। সামগ্রিক লক্ষ্য হল একটি সতর্কতা পাঠানো যখন আমার গাছগুলিতে আর্দ্রতা কম থাকে যা নির্দেশ করে যে তাদের জল দেওয়া দরকার। আমি মেটাডেটা দিয়ে রিডিং ডেটা সমৃদ্ধ করতে স্ট্রিম প্রসেসিং ব্যবহার করতে পারি এবং তারপর আমার সতর্কতা চালানোর জন্য ডেটার একটি নতুন স্ট্রিম গণনা করতে পারি।
আমি এই পাইপলাইনের ডেটা প্রক্রিয়াকরণ পর্যায়ে ksqlDB ব্যবহার করতে বেছে নিয়েছি যাতে আমি ন্যূনতম কোডিং সহ ডেটা প্রক্রিয়া করতে পারি। কনফ্লুয়েন্ট ক্লাউডের সাথে একত্রে, ksqlDB সেট আপ করা এবং ব্যবহার করা সহজ—আপনি কেবল একটি অ্যাপ্লিকেশন প্রসঙ্গ সরবরাহ করুন এবং আপনার ডেটা লোড এবং প্রক্রিয়াকরণ শুরু করতে কিছু সাধারণ SQL লিখুন।
ইনপুট ডেটা সংজ্ঞায়িত করা
আমি ডেটা প্রক্রিয়াকরণ শুরু করার আগে, আমাকে ksqlDB অ্যাপ্লিকেশনের মধ্যে আমার ডেটাসেটগুলি ঘোষণা করতে হবে যাতে এটি কাজ করার জন্য উপলব্ধ হয়। এটি করার জন্য, আমাকে প্রথমে সিদ্ধান্ত নিতে হবে যে দুটি প্রথম-শ্রেণির ksqlDB অবজেক্টের মধ্যে কোনটি আমার ডেটাকে উপস্থাপন করা উচিত— TABLE বা STREAM —এবং তারপরে বিদ্যমান কাফকা বিষয়গুলি নির্দেশ করার জন্য একটি CREATE বিবৃতি ব্যবহার করুন৷
হাউসপ্ল্যান্ট রিডিং ডেটা ksqlDB-তে একটি STREAM হিসাবে উপস্থাপন করা হয় — মূলত কাফকা বিষয়ের মতো (অপরিবর্তনীয় ইভেন্টগুলির একটি সংযোজন-শুধু সিরিজ) কিন্তু একটি স্কিমার সাথেও। বরং সুবিধাজনকভাবে আমি ইতিমধ্যে স্কিমা ডিজাইন এবং ঘোষণা করেছি, এবং ksqlDB এটি সরাসরি স্কিমা রেজিস্ট্রি থেকে আনতে পারে:
CREATE STREAM houseplant_readings ( id STRING KEY ) WITH ( kafka_topic='houseplant-readings', format='AVRO', partitions=4 );
কাফকা বিষয়ের উপর তৈরি স্ট্রীম দিয়ে, আমরা এইরকম একটি সাধারণ বিবৃতি ব্যবহার করে ডেটা অন্বেষণ করতে অনুসন্ধান করতে এবং ফিল্টার করার জন্য স্ট্যান্ডার্ড SQL ব্যবহার করতে পারি:
SELECT plant_id, moisture FROM HOUSEPLANT_READINGS EMIT CHANGES;


হাউসপ্ল্যান্ট মেটাডেটা একটু বেশি বিবেচনা করা প্রয়োজন। যদিও এটি একটি কাফকা বিষয় হিসাবে সংরক্ষণ করা হয় (ঠিক রিডিং ডেটার মতো), এটি যৌক্তিকভাবে একটি ভিন্ন ধরনের ডেটা-এর অবস্থা। প্রতিটি উদ্ভিদের জন্য, এটির একটি নাম রয়েছে, এটির একটি অবস্থান রয়েছে ইত্যাদি। আমরা এটিকে একটি সংক্ষিপ্ত কাফকা বিষয়ে সংরক্ষণ করি এবং এটিকে একটি TABLE হিসাবে ksqlDB-এ উপস্থাপন করি। একটি টেবিল - ঠিক যেমন একটি নিয়মিত RDBMS - আমাদের একটি প্রদত্ত কীটির বর্তমান অবস্থা বলে। মনে রাখবেন যে যখন ksqlDB স্কিমা রেজিস্ট্রি থেকে স্কিমাটি এখানে তুলে নেয় তখন আমাদের স্পষ্টভাবে ঘোষণা করতে হবে যে কোন ক্ষেত্রটি টেবিলের প্রাথমিক কী উপস্থাপন করে।
CREATE TABLE houseplant_metadata ( id INTEGER PRIMARY KEY ) WITH ( kafka_topic='houseplant-metadata', format='AVRO', partitions=4 );ডেটা সমৃদ্ধ করুন
আমার ksqlDB অ্যাপ্লিকেশনের সাথে নিবন্ধিত উভয় ডেটাসেটের সাথে, পরবর্তী ধাপ হল houseplants টেবিলে থাকা মেটাডেটা সহ houseplant_readings সমৃদ্ধ করা। এটি একটি নতুন স্ট্রীম তৈরি করে (একটি কাফকা বিষয় দ্বারা আন্ডারপিনড) সংশ্লিষ্ট উদ্ভিদের পড়া এবং মেটাডেটা উভয়ের সাথে:
সমৃদ্ধকরণ ক্যোয়ারী নিম্নলিখিত মত কিছু দেখতে হবে:
CREATE STREAM houseplant_readings_enriched WITH ( kafka_topic='houseplant-readings-enriched', format='AVRO', partitions=4 ) AS SELECT r.id AS plant_id, r.timestamp AS ts, r.moisture AS moisture, r.temperature AS temperature, h.scientific_name AS scientific_name, h.common_name AS common_name, h.given_name AS given_name, h.temperature_low AS temperature_low, h.temperature_high AS temperature_high, h.moisture_low AS moisture_low, h.moisture_high AS moisture_high FROM houseplant_readings AS r LEFT OUTER JOIN houseplants AS h ON houseplant_readings.id = houseplants.id PARTITION BY r.id EMIT CHANGES;
এবং সেই প্রশ্নের আউটপুট এরকম কিছু হবে:


ইভেন্টের একটি প্রবাহে সতর্কতা তৈরি করা
এই নিবন্ধের শুরুতে ফিরে চিন্তা করে, আপনি মনে রাখবেন যে এই সমস্ত কিছুর পুরো বিষয়টি আমাকে বলা ছিল যে কখন একটি গাছকে জল দেওয়া প্রয়োজন হতে পারে। আমরা আর্দ্রতা (এবং তাপমাত্রা) রিডিংয়ের একটি প্রবাহ পেয়েছি, এবং আমরা একটি টেবিল পেয়েছি যা আমাদেরকে বলে যে প্রান্তিকে প্রতিটি গাছের আর্দ্রতার স্তর নির্দেশ করতে পারে যে এটিতে জল দেওয়া প্রয়োজন। কিন্তু কম আর্দ্রতার সতর্কতা কখন পাঠাতে হবে তা আমি কীভাবে নির্ধারণ করব? এবং কত ঘন ঘন আমি তাদের পাঠাব?
এই প্রশ্নের উত্তর দেওয়ার চেষ্টা করার সময়, আমি আমার সেন্সর এবং তারা যে ডেটা তৈরি করছিল সে সম্পর্কে কয়েকটি জিনিস লক্ষ্য করেছি। প্রথমত, আমি পাঁচ সেকেন্ডের ব্যবধানে ডেটা ক্যাপচার করছি। আমি যদি প্রতিটি কম আর্দ্রতার জন্য একটি সতর্কতা পাঠাই, আমি সতর্কতার সাথে আমার ফোনকে প্লাবিত করব - এটি ভাল নয়। আমি প্রতি ঘন্টায় সর্বোচ্চ একবার একটি সতর্কতা পেতে পছন্দ করি। আমার ডেটা দেখে দ্বিতীয় যে জিনিসটি আমি বুঝতে পেরেছিলাম তা হল সেন্সরগুলি নিখুঁত ছিল না—আমি নিয়মিত মিথ্যা কম বা মিথ্যা উচ্চ রিডিং দেখছিলাম, যদিও সময়ের সাথে সাথে সাধারণ প্রবণতা ছিল যে একটি গাছের আর্দ্রতা স্তর হ্রাস পাবে।
এই দুটি পর্যবেক্ষণ একত্রিত করে, আমি সিদ্ধান্ত নিয়েছি যে একটি নির্দিষ্ট 1-ঘণ্টার মধ্যে, যদি আমি 20 মিনিটের কম আর্দ্রতার রিডিং দেখি তবে একটি সতর্কতা পাঠানোর জন্য এটি সম্ভবত যথেষ্ট হবে। প্রতি 5 সেকেন্ডে একটি রিডিং এ, এটি প্রতি ঘন্টায় 720 রিডিং, এবং… এখানে কিছুটা গণিত করা, এর মানে একটি সতর্কতা পাঠানোর আগে আমাকে 1-ঘন্টা সময়ের মধ্যে 240টি কম রিডিং দেখতে হবে।
তাই আমরা এখন যা করব তা হল একটি নতুন স্ট্রীম তৈরি করা যাতে 1-ঘন্টা পিরিয়ড প্রতি উদ্ভিদ প্রতি সর্বাধিক একটি ইভেন্ট থাকবে। আমি নিম্নলিখিত ক্যোয়ারী লিখে এটি অর্জন করেছি:
CREATE TABLE houseplant_low_readings WITH ( kafka_topic='houseplant-low-readings', format='AVRO', partitions=4 ) AS SELECT plant_id, given_name, common_name, scientific_name, CONCAT(given_name, ' the ', common_name, ' (', scientific_name, ') is looking pretty dry...') AS message, COUNT(*) AS low_reading_count FROM houseplant_readings_enriched WINDOW TUMBLING (SIZE 1 HOURS, GRACE PERIOD 30 MINUTES) WHERE moisture < moisture_low GROUP BY plant_id, given_name, common_name, scientific_name HAVING COUNT(*) > 240 EMIT FINAL;
প্রথম জিনিসগুলি প্রথমে, আপনি উইন্ডোড অ্যাগ্রিগেশন লক্ষ্য করবেন। এই ক্যোয়ারীটি অ-ওভারল্যাপিং 1-ঘন্টা উইন্ডোতে কাজ করে, আমাকে একটি প্রদত্ত উইন্ডোর মধ্যে প্ল্যান্ট আইডি প্রতি একত্রিত করার অনুমতি দেয়। অনেকটাই অকপট.
আমি বিশেষভাবে সমৃদ্ধ রিডিং স্ট্রীমের জন্য ফিল্টার করছি এবং সারিগুলি গণনা করছি যেখানে আর্দ্রতা পড়ার মান সেই উদ্ভিদের জন্য কম আর্দ্রতার থ্রেশহোল্ডের চেয়ে কম। যদি সেই সংখ্যাটি কমপক্ষে 240 হয়, আমি এমন একটি ফলাফল আউটপুট করব যা একটি সতর্কতার ভিত্তি তৈরি করবে।
কিন্তু আপনি ভাবছেন কেন এই প্রশ্নের ফলাফল একটি টেবিলে আছে। ঠিক আছে, যেমনটি আমরা জানি, স্ট্রীমগুলি একটি ডেটা সত্তার কম-বেশি সম্পূর্ণ ইতিহাস উপস্থাপন করে, যেখানে টেবিলগুলি একটি প্রদত্ত কী-এর জন্য সর্বাধিক আপ-টু-ডেট মান প্রতিফলিত করে। এটা মনে রাখা গুরুত্বপূর্ণ যে এই প্রশ্নটি আসলে কভারের অধীনে একটি রাষ্ট্রীয় স্ট্রিমিং অ্যাপ্লিকেশন। অন্তর্নিহিত সমৃদ্ধ ডেটা স্ট্রীমের মাধ্যমে বার্তাগুলি প্রবাহিত হলে, যদি সেই নির্দিষ্ট বার্তাটি ফিল্টারের প্রয়োজনীয়তা পূরণ করে, আমরা 1-ঘন্টার উইন্ডোর মধ্যে সেই প্ল্যান্ট আইডির জন্য কম রিডিংয়ের সংখ্যা বৃদ্ধি করি এবং একটি রাজ্যের মধ্যে এটির ট্র্যাক রাখি। এই ক্যোয়ারীতে আমি সত্যিই যা যত্নশীল, যাইহোক, একত্রিতকরণের চূড়ান্ত ফলাফল—প্রদত্ত কী-এর জন্য কম রিডিংয়ের সংখ্যা 240-এর উপরে কিনা। আমি একটি টেবিল চাই.
একটি পাশে: আপনি লক্ষ্য করবেন যে উক্তিটির শেষ লাইনটি হল `EMIT FINAL`। এই শব্দগুচ্ছের অর্থ হল, প্রতিবার স্ট্রিমিং অ্যাপ্লিকেশনের মধ্য দিয়ে একটি নতুন সারি প্রবাহিত হলে সম্ভাব্য ফলাফল আউটপুট করার পরিবর্তে, ফলাফল নির্গত হওয়ার আগে উইন্ডোটি বন্ধ না হওয়া পর্যন্ত আমি অপেক্ষা করব।
এই প্রশ্নের ফলাফল হল যে, একটি নির্দিষ্ট এক ঘন্টার উইন্ডোতে একটি প্রদত্ত প্ল্যান্ট আইডির জন্য, আমি সর্বাধিক একটি সতর্কতা বার্তা আউটপুট করব, ঠিক যেমনটি আমি চেয়েছিলাম।
শাখাবিন্যাস আউট
এই মুহুর্তে, আমার কাছে ksqlDB দ্বারা একটি কাফকা বিষয় রয়েছে যেখানে একটি বার্তা রয়েছে যখন একটি গাছের আর্দ্রতা যথাযথভাবে এবং ধারাবাহিকভাবে কম থাকে। কিন্তু আমি আসলে কাফকা থেকে এই তথ্য কিভাবে পেতে পারি? আমার জন্য সবচেয়ে সুবিধাজনক জিনিস সরাসরি আমার ফোনে এই তথ্য গ্রহণ করা হবে.
আমি এখানে চাকাটি পুনরায় উদ্ভাবন করতে যাচ্ছিলাম না, তাই আমি এই ব্লগ পোস্টের সুবিধা নিয়েছি যা একটি টেলিগ্রাম বট ব্যবহার করে কাফকা বিষয় থেকে বার্তা পড়তে এবং একটি ফোনে সতর্কতা পাঠাতে বর্ণনা করে। ব্লগ দ্বারা বর্ণিত প্রক্রিয়া অনুসরণ করে, আমি একটি টেলিগ্রাম বট তৈরি করেছি এবং আমার বটের জন্য API কী সহ সেই কথোপকথনের অনন্য আইডি নোট করে আমার ফোনে সেই বটের সাথে একটি কথোপকথন শুরু করেছি। সেই তথ্য দিয়ে, আমি আমার বট থেকে আমার ফোনে বার্তা পাঠাতে টেলিগ্রাম চ্যাট API ব্যবহার করতে পারি।
এটা ভাল এবং ভাল, কিন্তু আমি কিভাবে কাফকা থেকে আমার টেলিগ্রাম বট থেকে আমার সতর্কতা পেতে পারি? আমি একটি বেসপোক ভোক্তা লিখে বার্তা পাঠানোর আহ্বান জানাতে পারি যা কাফকা বিষয় থেকে সতর্কতা গ্রহণ করবে এবং টেলিগ্রাম চ্যাট API এর মাধ্যমে প্রতিটি বার্তা ম্যানুয়ালি পাঠাবে। কিন্তু এটা অতিরিক্ত কাজের মত শোনাচ্ছে। পরিবর্তে, আমি এই একই জিনিসটি করার জন্য সম্পূর্ণরূপে পরিচালিত HTTP সিঙ্ক সংযোগকারী ব্যবহার করার সিদ্ধান্ত নিয়েছি, কিন্তু আমার নিজের কোনো অতিরিক্ত কোড না লিখেই।
কয়েক মিনিটের মধ্যে, আমার টেলিগ্রাম বট কাজ করার জন্য প্রস্তুত ছিল, এবং আমি আমার এবং বটের মধ্যে একটি ব্যক্তিগত চ্যাট খুলেছিলাম। চ্যাট আইডি ব্যবহার করে, আমি এখন সরাসরি আমার ফোনে বার্তা পাঠাতে কনফ্লুয়েন্ট ক্লাউডে সম্পূর্ণরূপে পরিচালিত HTTP সিঙ্ক সংযোগকারী ব্যবহার করতে পারি।
সম্পূর্ণ কনফিগারেশন এই মত লাগছিল:
{ "name": "HttpSinkConnector_Houseplants_Telegram_Bot", "config": { "topics": "houseplant-low-readings", "input.data.format": "AVRO", "connector.class": "HttpSink", "name": "HttpSinkConnector_Houseplants_Telegram_Bot", "kafka.auth.mode": "KAFKA_API_KEY", "http.api.url": "https://api.telegram.org/**********/sendMessage", "request.method": "POST", "headers": "Content-Type: application/json", "request.body.format": "string", "batch.max.size": "1", "batch.prefix": "{\"chat_id\":\"********\",", "batch.suffix": "}", "regex.patterns": ".*MESSAGE=(.*),LOW_READING_COUNT=(.*)}.*", "regex.replacements": "\"text\":\"$1\"", "regex.separator": "~", "tasks.max": "1" } }


সংযোগকারী চালু করার কয়েকদিন পরে, আমি একটি খুব দরকারী বার্তা পেয়েছি যে আমাকে জানায় যে আমার উদ্ভিদে জল দেওয়া দরকার। সফলতার !


একটি নতুন পাতা উল্টানো
এই প্রকল্পের প্রাথমিক পর্যায়টি সম্পন্ন করার পর প্রায় এক বছর হয়ে গেছে। সেই সময়ে, আমি রিপোর্ট করতে পেরে খুশি যে আমি যে সমস্ত গাছপালা পর্যবেক্ষণ করছি সেগুলি সুখী এবং স্বাস্থ্যকর! সেগুলি পরীক্ষা করার জন্য আমাকে আর কোনও অতিরিক্ত সময় ব্যয় করতে হবে না এবং আমি আমার স্ট্রিমিং ডেটা পাইপলাইন দ্বারা উত্পন্ন সতর্কতার উপর একচেটিয়াভাবে নির্ভর করতে পারি। কিভাবে শীতল হয়?


যদি এই প্রকল্পটি তৈরি করার প্রক্রিয়াটি আপনাকে আগ্রহী করে, আমি আপনাকে আপনার নিজস্ব স্ট্রিমিং ডেটা পাইপলাইনে শুরু করতে উত্সাহিত করি৷ আপনি একজন পাকা কাফকা ব্যবহারকারী যিনি আপনার নিজের জীবনে রিয়েল-টাইম পাইপলাইন তৈরি এবং অন্তর্ভুক্ত করার জন্য নিজেকে চ্যালেঞ্জ করতে চান, বা কাফকাতে সম্পূর্ণ নতুন কেউ, আমি আপনাকে বলতে এখানে এসেছি যে এই ধরণের প্রকল্পগুলি আপনার জন্য ।
এছাড়াও এখানে প্রকাশিত.









