




















Quay trở lại năm 2020, rất nhiều người đã chọn những sở thích đại dịch — những thứ mà họ có thể dốc toàn lực thực hiện trong khi bị hạn chế bởi lệnh phong tỏa. Tôi đã chọn cây trồng trong nhà.
Trước khi xảy ra đại dịch, tôi đã có một vườn ươm nhỏ trong nhà. Thành thật mà nói, ngay cả khi đó, việc chăm sóc từng cây mỗi ngày là rất nhiều công việc. Xem những cây nào trong số chúng cần được tưới nước, đảm bảo rằng tất cả chúng đều nhận được lượng ánh sáng mặt trời phù hợp, nói chuyện với chúng… #justHouseplantThings.
Có nhiều thời gian hơn ở nhà đồng nghĩa với việc tôi có thể đầu tư nhiều hơn vào cây trồng của mình. Và tôi đã làm được—thời gian, công sức và tiền bạc của tôi. Có vài chục cây trồng trong nhà của tôi; tất cả họ đều có tên, tính cách (ít nhất là tôi nghĩ vậy), và một số thậm chí còn có đôi mắt lờ mờ. Tất nhiên, điều này vẫn ổn khi tôi ở nhà cả ngày, nhưng khi cuộc sống dần trở lại bình thường, tôi thấy mình rơi vào một tình thế khó khăn: tôi không còn đủ thời gian để theo dõi các cây của mình nữa. Tôi cần một giải pháp. Cần phải có một cách tốt hơn để theo dõi cây trồng của tôi hơn là kiểm tra chúng theo cách thủ công mỗi ngày.


Nhập Apache Kafka®. Chà, thực sự, hãy nhập mong muốn của tôi để chọn một sở thích khác: các dự án phần cứng.
Tôi luôn muốn có lý do để xây dựng một dự án bằng Raspberry Pi và tôi biết rằng đây là cơ hội của mình. Tôi sẽ xây dựng một hệ thống có thể giám sát các nhà máy của mình để chỉ cảnh báo cho tôi khi chúng cần được chú ý ngay lập tức. Và tôi sẽ sử dụng Kafka làm xương sống.
Điều này thực sự hóa ra là một dự án rất hữu ích. Nó đã giải quyết một vấn đề rất thực tế mà tôi gặp phải và cho tôi cơ hội kết hợp nỗi ám ảnh về cây trồng trong nhà với mong muốn ngứa ngáy cuối cùng là được sử dụng Kafka ở nhà. Tất cả những điều này được gói gọn trong một dự án phần cứng dễ sử dụng và dễ tiếp cận mà bất kỳ ai cũng có thể tự thực hiện.
Nếu bạn giống tôi và bạn gặp vấn đề về cây trồng trong nhà mà chỉ có thể giải quyết bằng cách tự động hóa ngôi nhà của bạn hoặc ngay cả khi bạn hoàn toàn không giống tôi nhưng bạn vẫn muốn tìm hiểu kỹ một dự án thú vị, thì bài đăng trên blog này là dành cho bạn .
Hãy xắn tay áo lên và làm bẩn tay nào!
Gieo hạt
Đầu tiên, tôi ngồi xuống để tìm ra những gì tôi muốn đạt được từ dự án này. Đối với giai đoạn đầu tiên của hệ thống, việc có thể theo dõi độ ẩm của cây và nhận thông báo về chúng sẽ rất hữu ích—xét cho cùng, phần tốn thời gian nhất trong việc chăm sóc cây của tôi là quyết định loại cây nào cần được chăm sóc. Nếu hệ thống này có thể xử lý quá trình ra quyết định đó, tôi sẽ tiết kiệm được rất nhiều thời gian!
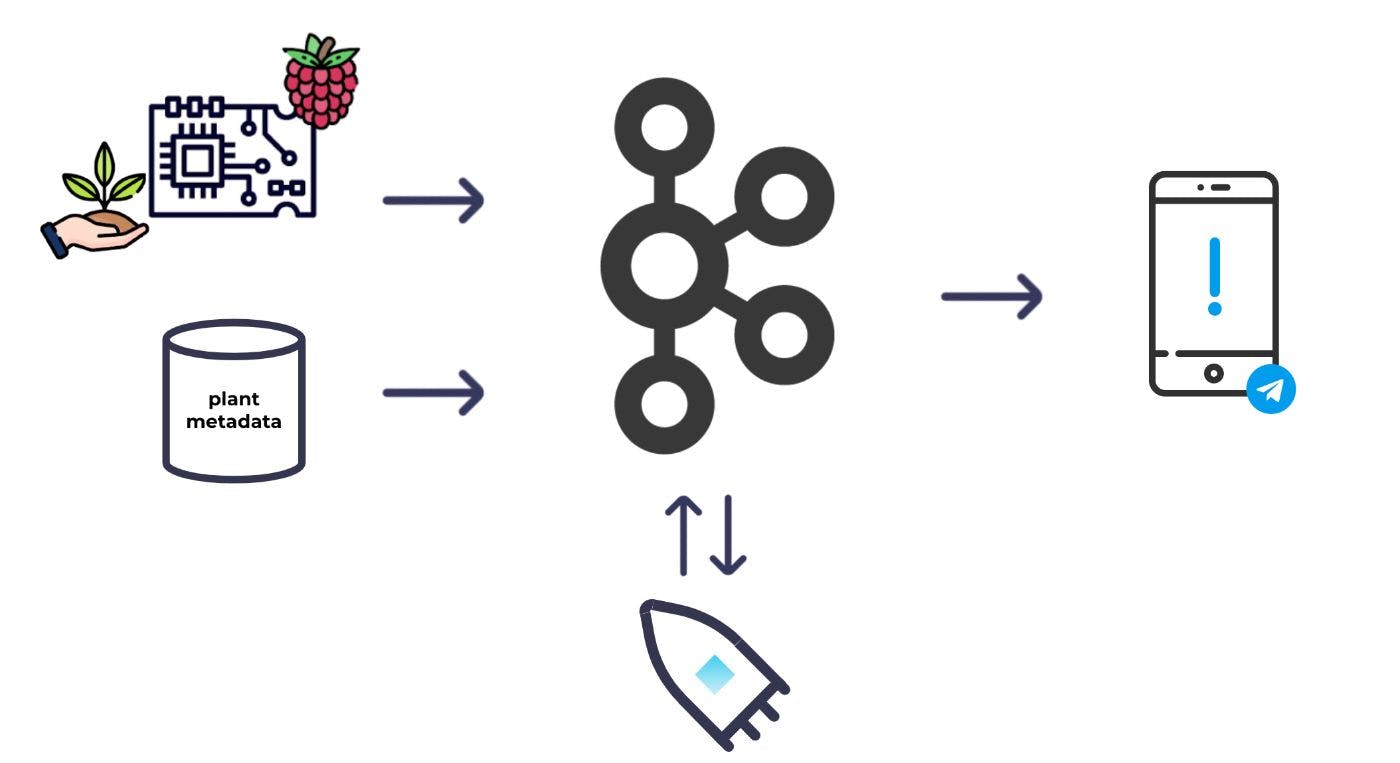
Ở cấp độ cao, đây là hệ thống cơ bản mà tôi đã hình dung:


Tôi sẽ đặt một số cảm biến độ ẩm trong đất và nối chúng với Raspberry Pi; Sau đó, tôi có thể thường xuyên đọc các bài đọc về độ ẩm và ném chúng vào Kafka. Ngoài việc đọc độ ẩm, tôi cũng cần một số siêu dữ liệu cho từng loại cây để quyết định loại cây nào cần được tưới nước. Tôi cũng sẽ tạo siêu dữ liệu thành Kafka. Với cả hai bộ dữ liệu trong Kafka, sau đó tôi có thể sử dụng xử lý luồng để kết hợp và làm phong phú các bộ dữ liệu với nhau và tính toán những cây nào cần được tưới nước. Từ đó, tôi có thể kích hoạt một cảnh báo.
Với một loạt các yêu cầu cơ bản đã được thiết lập, tôi bắt tay vào giai đoạn lắp ráp và phần cứng.
Lấy cuống của mọi thứ
Giống như nhiều kỹ sư tự trọng khác, tôi đã bắt đầu giai đoạn phần cứng với rất nhiều công cụ tìm kiếm trên Google. Tôi biết rằng tất cả các phần đều tồn tại để tạo nên thành công cho dự án này, nhưng vì đây là lần đầu tiên tôi làm việc với các thành phần vật lý nên tôi muốn đảm bảo rằng tôi biết chính xác mình đang làm gì.
Mục tiêu chính của hệ thống giám sát là cho tôi biết khi nào cần tưới cây, vì vậy rõ ràng là tôi cần một số loại cảm biến độ ẩm. Tôi được biết rằng cảm biến độ ẩm của đất có nhiều hình dạng và kích cỡ khác nhau, có sẵn dưới dạng các thành phần kỹ thuật số hoặc tương tự, và khác nhau ở cách chúng đo độ ẩm. Cuối cùng, tôi quyết định sử dụng các cảm biến điện dung I2C này. Chúng dường như là một lựa chọn tuyệt vời cho những người mới bắt đầu sử dụng phần cứng: là cảm biến điện dung, chúng sẽ tồn tại lâu hơn so với cảm biến dựa trên điện trở, chúng không yêu cầu chuyển đổi tương tự sang kỹ thuật số và chúng ít nhiều là plug-and- chơi. Thêm vào đó, họ cung cấp các phép đo nhiệt độ miễn phí.
Ngoài ra: Đối với những người tò mò, I2C có nghĩa là Mạch tích hợp liên kết. Mỗi cảm biến này giao tiếp qua một địa chỉ duy nhất; vì vậy, để lấy dữ liệu từ mỗi cảm biến, tôi cần đặt và theo dõi địa chỉ duy nhất cho mọi cảm biến mà tôi sử dụng—một điều cần lưu ý sau này.
Quyết định về cảm biến là phần quan trọng nhất trong thiết lập vật lý của tôi. Tất cả những gì còn lại phải làm theo cách của phần cứng là nắm giữ Raspberry Pi và một vài thiết bị. Sau đó, tôi được tự do để bắt đầu xây dựng hệ thống.
Tôi đã sử dụng các thành phần sau:
- Raspberry Pi 4 Mẫu B
- PCB Breadboard cỡ nửa
- Cảm biến độ ẩm đất điện dung
- Bộ kết nối cao độ JST
- dây ruy băng 4 sợi
- Máy uốn, máy tuốt dây điện, máy hàn, mỏ hàn (tất cả những thứ này tôi đều có thể dễ dàng tìm thấy trong nhà để xe của mình)


Từ đất lên…
Mặc dù tôi muốn dự án này trở nên dễ dàng và thân thiện với người mới bắt đầu, nhưng tôi cũng muốn thử thách bản thân thực hiện càng nhiều thao tác nối dây và hàn càng tốt. Để tôn vinh những người đi trước tôi , tôi đã bắt đầu cuộc hành trình lắp ráp này với một số sợi dây, máy uốn tóc và một giấc mơ. Bước đầu tiên là chuẩn bị đủ dây ruy băng để kết nối bốn cảm biến với breadboard và cũng để kết nối breadboard với Raspberry Pi của tôi. Để tạo khoảng cách giữa các thành phần trong quá trình thiết lập, tôi đã chuẩn bị trước độ dài 24 inch. Mỗi dây phải được tước, uốn và cắm vào đầu nối JST (dành cho dây kết nối cảm biến với bảng mạch) hoặc ổ cắm cái (để kết nối với chính Raspberry Pi). Tuy nhiên, tất nhiên, nếu bạn đang muốn tiết kiệm thời gian, công sức và nước mắt, tôi khuyên bạn không nên tự uốn dây của mình mà thay vào đó hãy mua dây đã chuẩn bị trước.
Ngoài ra: Với số lượng cây trồng trong nhà mà tôi sở hữu, bốn cây có vẻ là số lượng cảm biến thấp tùy ý để sử dụng trong thiết lập giám sát của tôi. Như đã nêu trước đó, vì các cảm biến này là thiết bị I2C nên mọi thông tin chúng liên lạc sẽ được gửi bằng một địa chỉ duy nhất. Điều đó nói rằng, tất cả các cảm biến độ ẩm đất mà tôi đã mua đều được vận chuyển với cùng một địa chỉ mặc định, đây là vấn đề đối với các thiết lập như thế này khi bạn muốn sử dụng nhiều thiết bị giống nhau. Có hai cách chính để giải quyết vấn đề này. Tùy chọn đầu tiên phụ thuộc vào chính thiết bị. Cảm biến cụ thể của tôi có hai nút nhảy địa chỉ I2C ở phía sau và hàn bất kỳ sự kết hợp nào trong số này có nghĩa là tôi có thể thay đổi địa chỉ I2C thành phạm vi từ 0x36 và 0x39. Tổng cộng, tôi có thể có bốn địa chỉ duy nhất, do đó có bốn cảm biến tôi sử dụng trong thiết lập cuối cùng. Nếu thiết bị thiếu phương tiện vật lý để thay đổi địa chỉ, tùy chọn thứ hai là định tuyến lại thông tin và thiết lập địa chỉ proxy bằng cách sử dụng ghép kênh. Cho rằng tôi chưa quen với phần cứng, tôi cảm thấy điều đó nằm ngoài phạm vi của dự án cụ thể này.
Sau khi chuẩn bị sẵn dây để kết nối các cảm biến với Raspberry Pi, tôi xác nhận rằng mọi thứ đã được thiết lập chính xác bằng cách sử dụng tập lệnh Python thử nghiệm để thu thập số đọc từ một cảm biến. Để yên tâm hơn, tôi đã kiểm tra ba cảm biến còn lại theo cách tương tự. Và chính trong giai đoạn này, tôi đã trực tiếp học được cách dây chéo ảnh hưởng đến các linh kiện điện tử… và mức độ khó khắc phục của những vấn đề này.
Cuối cùng thì hệ thống dây điện cũng hoạt động bình thường, tôi có thể kết nối tất cả các cảm biến với Raspberry Pi. Tất cả các cảm biến cần được kết nối với cùng một chân (GND, 3V3, SDA và SCL) trên Raspberry Pi. Tuy nhiên, mỗi cảm biến có một địa chỉ I2C duy nhất, vì vậy, mặc dù tất cả chúng đều giao tiếp qua cùng một dây, nhưng tôi vẫn có thể lấy dữ liệu từ các cảm biến cụ thể bằng địa chỉ của chúng. Tất cả những gì tôi phải làm là nối từng cảm biến với breadboard và sau đó kết nối breadboard với Raspberry Pi. Để đạt được điều này, tôi đã sử dụng một ít dây còn sót lại và kết nối các cột của bảng mạch bằng hàn. Sau đó, tôi hàn trực tiếp các đầu nối JST vào bảng mạch khung để có thể dễ dàng cắm các cảm biến.
Sau khi kết nối breadboard với Raspberry Pi, lắp các cảm biến vào bốn cây và xác nhận thông qua tập lệnh kiểm tra rằng tôi có thể đọc dữ liệu từ tất cả các cảm biến, tôi có thể bắt đầu sản xuất dữ liệu vào Kafka.
Dữ liệu cỏ xạ hương thực
Với thiết lập Raspberry Pi và tất cả các cảm biến độ ẩm hoạt động như mong đợi, đã đến lúc đưa Kafka vào hỗn hợp để bắt đầu truyền một số dữ liệu.
Như bạn có thể mong đợi, tôi cần một cụm Kafka trước khi có thể ghi bất kỳ dữ liệu nào vào Kafka. Vì muốn làm cho thành phần phần mềm của dự án này nhẹ và dễ cài đặt nhất có thể, tôi đã chọn sử dụng Confluent Cloud làm nhà cung cấp Kafka của mình. Làm như vậy có nghĩa là tôi không cần thiết lập hoặc quản lý bất kỳ cơ sở hạ tầng nào và cụm Kafka của tôi đã sẵn sàng trong vòng vài phút sau khi thiết lập.
Cũng cần lưu ý lý do tại sao tôi chọn sử dụng Kafka cho dự án này, đặc biệt khi xem xét rằng MQTT ít nhiều là tiêu chuẩn thực tế để truyền dữ liệu IoT từ các cảm biến. Cả Kafka và MQTT đều được xây dựng cho tin nhắn kiểu quán rượu/phụ, vì vậy chúng giống nhau về mặt đó. Nhưng nếu bạn có kế hoạch xây dựng một dự án truyền dữ liệu như dự án này, thì MQTT sẽ không thành công. Bạn cần một công nghệ khác như Kafka để xử lý quá trình xử lý luồng, tính ổn định của dữ liệu và bất kỳ tích hợp xuôi dòng nào. Điểm mấu chốt là MQTT và Kafka hoạt động rất tốt với nhau . Ngoài Kafka, tôi chắc chắn có thể đã sử dụng MQTT cho thành phần IoT trong dự án của mình. Thay vào đó, tôi quyết định làm việc trực tiếp với nhà sản xuất Python trên Raspberry Pi. Điều đó nói rằng, nếu bạn muốn sử dụng MQTT và Kafka cho bất kỳ dự án lấy cảm hứng từ IoT nào, hãy yên tâm rằng bạn vẫn có thể đưa dữ liệu MQTT của mình vào Kafka bằng Trình kết nối nguồn MQTT Kafka .
Làm cỏ thông qua dữ liệu
Trước khi đưa bất kỳ dữ liệu nào vào hoạt động, tôi đã lùi lại một bước để quyết định cách tôi muốn cấu trúc các thông điệp về chủ đề Kafka của mình. Đặc biệt đối với các dự án hack như thế này, thật dễ dàng để bắt đầu đưa dữ liệu vào một chủ đề Kafka mà không phải lo lắng về thế giới—nhưng điều quan trọng là phải biết cách bạn sẽ cấu trúc dữ liệu của mình theo các chủ đề, khóa nào bạn sẽ sử dụng và dữ liệu loại trong các lĩnh vực.
Vì vậy, hãy bắt đầu với các chủ đề. Những cái đó sẽ trông như thế nào? Các cảm biến có khả năng nắm bắt độ ẩm và nhiệt độ—những bài đọc này nên được viết cho một chủ đề hay nhiều chủ đề? Vì cả kết quả đo độ ẩm và nhiệt độ đều được ghi lại từ cảm biến của cây cùng một lúc, nên tôi đã lưu trữ chúng cùng nhau trong cùng một thông báo Kafka. Cùng với nhau, hai mẩu thông tin đó bao gồm một bài đọc thực vật cho các mục đích của dự án này. Tất cả sẽ diễn ra trong cùng một chủ đề đọc.
Ngoài dữ liệu cảm biến, tôi cần một chủ đề để lưu trữ siêu dữ liệu cây trồng trong nhà bao gồm loại cây mà cảm biến đang theo dõi cũng như ranh giới nhiệt độ và độ ẩm của nó. Thông tin này sẽ được sử dụng trong giai đoạn xử lý dữ liệu để xác định thời điểm đọc nên kích hoạt cảnh báo.
Tôi đã tạo hai chủ đề: houseplants-readings và houseplants-metadata . Tôi nên sử dụng bao nhiêu phân vùng? Đối với cả hai chủ đề, tôi quyết định sử dụng số lượng phân vùng mặc định trong Confluent Cloud, tại thời điểm viết bài này là sáu. Đó có phải là con số đúng không? Vâng, có và không. Trong trường hợp này, do khối lượng dữ liệu mà tôi đang xử lý thấp, sáu phân vùng cho mỗi chủ đề có thể là quá mức cần thiết, nhưng trong trường hợp sau này tôi mở rộng dự án này cho nhiều nhà máy hơn, thì sẽ tốt hơn nếu có sáu phân vùng .
Bên cạnh các phân vùng, một tham số cấu hình quan trọng khác cần lưu ý là tính năng nén nhật ký mà tôi đã bật trong chủ đề cây trồng trong nhà. Không giống như luồng sự kiện `đọc`, chủ đề `siêu dữ liệu` chứa dữ liệu tham chiếu—hoặc siêu dữ liệu. Bằng cách giữ nó trong một chủ đề nén, bạn đảm bảo rằng dữ liệu sẽ không bao giờ cũ và bạn sẽ luôn có quyền truy cập vào giá trị đã biết cuối cùng cho một khóa nhất định (khóa, nếu bạn nhớ, là mã định danh duy nhất cho mỗi cây trồng trong nhà).
Dựa trên những điều trên, tôi đã viết hai lược đồ Avro cho cả bài đọc và siêu dữ liệu cây trồng trong nhà (được rút ngắn ở đây để dễ đọc).
lược đồ bài đọc
{ "doc": "Houseplant reading taken from sensors.", "fields": [ {"name": "plant_id", "type": "int"}, {"name": "timestamp", "logicalType": "timestamp-millis", "type": "long"}, {"name": "moisture", "type": "float"}, {"name": "temperature", "type": "float"} ], "name": "reading", "namespace": "com.houseplants", "type": "record" }Giản đồ siêu dữ liệu cây trồng trong nhà
{ "doc": "Houseplant metadata.", "fields": [ {"name": "plant_id", "type": "int"}, {"name": "scientific_name", "type": "string"}, {"name": "common_name", "type": "string"}, {"name": "given_name", "type": "string"}, {"name": "temperature_threshold_low", "type": "float"}, {"name": "temperature_threshold_high", "type": "float"}, {"name": "moisture_threshold_low", "type": "float"}, {"name": "moisture_threshold_high", "type": "float"} ], "name": "houseplant", "namespace": "com.houseplants", "type": "record" }
Nếu bạn đã sử dụng Kafka trước đây, bạn sẽ biết rằng việc có chủ đề và biết giá trị thông điệp của bạn trông như thế nào chỉ là bước đầu tiên. Điều quan trọng không kém là biết khóa sẽ là gì cho mỗi thư. Đối với cả bài đọc và siêu dữ liệu, tôi đã tự hỏi bản thân mình một thể hiện của mỗi bộ dữ liệu này sẽ là gì, vì đó là thể hiện thực thể sẽ tạo thành cơ sở của một khóa trong Kafka. Vì số lần đọc được thực hiện trên mỗi cây và siêu dữ liệu được chỉ định cho mỗi cây nên một thực thể của cả hai bộ dữ liệu là một cây riêng lẻ. Tôi quyết định rằng chìa khóa logic của cả hai chủ đề sẽ dựa trên nhà máy. Tôi sẽ chỉ định một ID số cho mỗi nhà máy và lấy số đó làm chìa khóa cho cả thông báo đọc và thông báo siêu dữ liệu.
Vì vậy, với cảm giác hài lòng hơi tự mãn khi biết rằng mình đang đi đúng hướng, tôi có thể chuyển sự chú ý của mình sang việc truyền dữ liệu từ các cảm biến của mình vào các chủ đề Kafka.
tin nhắn tu luyện
Tôi muốn bắt đầu gửi dữ liệu từ các cảm biến của mình tới Kafka. Bước một là cài đặt thư viện confluent-kafka Python trên Raspberry Pi. Từ đó, tôi đã viết một tập lệnh Python để ghi lại các số đọc từ các cảm biến của mình và tạo dữ liệu trong Kafka.
Bạn có tin không nếu tôi nói với bạn rằng nó dễ dàng như vậy? Chỉ với một vài dòng mã, dữ liệu cảm biến của tôi đã được ghi vào và duy trì trong một chủ đề Kafka để sử dụng trong phân tích hạ nguồn. Tôi vẫn có một chút ham chơi khi nghĩ về nó.


Với các lần đọc cảm biến ở Kafka, giờ đây tôi cần siêu dữ liệu cây trồng trong nhà để tiến hành bất kỳ loại phân tích xuôi dòng nào. Trong các đường dẫn dữ liệu điển hình, loại dữ liệu này sẽ nằm trong cơ sở dữ liệu quan hệ hoặc một số kho lưu trữ dữ liệu khác và sẽ được nhập bằng Kafka Connect và nhiều trình kết nối có sẵn cho nó.
Thay vì tạo cơ sở dữ liệu bên ngoài của riêng mình, tôi quyết định sử dụng Kafka làm lớp lưu trữ liên tục cho siêu dữ liệu của mình. Với siêu dữ liệu chỉ dành cho một số ít thực vật, tôi đã viết dữ liệu trực tiếp tới Kafka theo cách thủ công bằng cách sử dụng một tập lệnh Python khác.
Gốc rễ của vấn đề
Dữ liệu của tôi ở Kafka; bây giờ là lúc để thực sự làm bẩn tay tôi. Nhưng trước tiên, hãy xem lại những gì tôi muốn đạt được với dự án này. Mục tiêu tổng thể là gửi cảnh báo khi cây của tôi có chỉ số độ ẩm thấp cho thấy chúng cần được tưới nước. Tôi có thể sử dụng xử lý luồng để làm phong phú thêm dữ liệu đọc bằng siêu dữ liệu và sau đó tính toán luồng dữ liệu mới để đưa ra các cảnh báo của mình.
Tôi đã chọn sử dụng ksqlDB cho giai đoạn xử lý dữ liệu của quy trình này để tôi có thể xử lý dữ liệu với mã hóa tối thiểu. Cùng với Confluent Cloud, ksqlDB rất dễ cài đặt và sử dụng—bạn chỉ cần cung cấp ngữ cảnh ứng dụng và viết một số SQL đơn giản để bắt đầu tải và xử lý dữ liệu của mình.
Xác định dữ liệu đầu vào
Trước khi tôi có thể bắt đầu xử lý dữ liệu, tôi cần khai báo các bộ dữ liệu của mình trong ứng dụng ksqlDB để nó có thể hoạt động được. Để làm như vậy, trước tiên tôi cần quyết định xem dữ liệu của tôi sẽ được biểu diễn dưới dạng đối tượng ksqlDB hạng nhất nào trong số hai đối tượng ksqlDB hạng nhất là— TABLE hoặc STREAM —và sau đó sử dụng câu lệnh CREATE để trỏ đến các chủ đề Kafka hiện có.
Dữ liệu đọc cây trồng trong nhà được biểu diễn trong ksqlDB dưới dạng STREAM —về cơ bản giống hệt như chủ đề Kafka (một chuỗi các sự kiện bất biến chỉ nối thêm) mà còn với một lược đồ. Khá thuận tiện là tôi đã thiết kế và khai báo lược đồ trước đó và ksqlDB có thể tìm nạp trực tiếp từ Sổ đăng ký lược đồ:
CREATE STREAM houseplant_readings ( id STRING KEY ) WITH ( kafka_topic='houseplant-readings', format='AVRO', partitions=4 );
Với luồng được tạo qua chủ đề Kafka, chúng ta có thể sử dụng SQL tiêu chuẩn để truy vấn và lọc nó để khám phá dữ liệu bằng một câu lệnh đơn giản như sau:
SELECT plant_id, moisture FROM HOUSEPLANT_READINGS EMIT CHANGES;


Siêu dữ liệu cây trồng trong nhà chỉ cần xem xét thêm một chút. Mặc dù nó được lưu trữ dưới dạng một chủ đề Kafka (giống như dữ liệu đọc), về mặt logic, nó là một loại dữ liệu khác—trạng thái của nó. Đối với mỗi nhà máy, nó có một cái tên, nó có một vị trí, v.v. Chúng tôi lưu trữ nó trong một chủ đề Kafka được nén và biểu thị nó trong ksqlDB dưới dạng TABLE . Một bảng—giống như trong RDBMS thông thường—cho chúng tôi biết trạng thái hiện tại của một khóa đã cho. Lưu ý rằng trong khi ksqlDB chọn chính lược đồ ở đây từ Sổ đăng ký lược đồ, chúng tôi cần khai báo rõ ràng trường nào đại diện cho khóa chính của bảng.
CREATE TABLE houseplant_metadata ( id INTEGER PRIMARY KEY ) WITH ( kafka_topic='houseplant-metadata', format='AVRO', partitions=4 );Làm giàu dữ liệu
Với cả hai bộ dữ liệu đã đăng ký với ứng dụng ksqlDB của tôi, bước tiếp theo là làm phong phú thêm houseplant_readings với siêu dữ liệu có trong bảng houseplants . Điều này tạo ra một luồng mới (được củng cố bởi chủ đề Kafka) với cả cách đọc và siêu dữ liệu cho nhà máy được liên kết:
Truy vấn làm giàu sẽ giống như sau:
CREATE STREAM houseplant_readings_enriched WITH ( kafka_topic='houseplant-readings-enriched', format='AVRO', partitions=4 ) AS SELECT r.id AS plant_id, r.timestamp AS ts, r.moisture AS moisture, r.temperature AS temperature, h.scientific_name AS scientific_name, h.common_name AS common_name, h.given_name AS given_name, h.temperature_low AS temperature_low, h.temperature_high AS temperature_high, h.moisture_low AS moisture_low, h.moisture_high AS moisture_high FROM houseplant_readings AS r LEFT OUTER JOIN houseplants AS h ON houseplant_readings.id = houseplants.id PARTITION BY r.id EMIT CHANGES;
Và đầu ra của truy vấn đó sẽ giống như thế này:


Tạo cảnh báo trên luồng sự kiện
Nghĩ lại phần đầu của bài viết này, bạn sẽ nhớ rằng mục đích chính của tất cả những điều này là để cho tôi biết khi nào một cái cây có thể cần được tưới nước. Chúng tôi có một dòng dữ liệu về độ ẩm (và nhiệt độ) và chúng tôi có một bảng cho chúng tôi biết ngưỡng mà tại đó mức độ ẩm của mỗi loại cây có thể cho thấy nó cần được tưới nước. Nhưng làm cách nào để xác định thời điểm gửi cảnh báo độ ẩm thấp? Và tôi gửi chúng bao lâu một lần?
Khi cố gắng trả lời những câu hỏi đó, tôi nhận thấy một vài điều về cảm biến của mình và dữ liệu mà chúng tạo ra. Trước hết, tôi đang thu thập dữ liệu trong khoảng thời gian năm giây. Nếu tôi gửi cảnh báo cho mỗi lần đọc độ ẩm thấp, tôi sẽ làm điện thoại của mình tràn ngập cảnh báo — điều đó không tốt. Tôi muốn nhận thông báo nhiều nhất mỗi giờ một lần. Điều thứ hai tôi nhận ra khi xem xét dữ liệu của mình là các cảm biến không hoàn hảo—tôi thường xuyên thấy số đọc sai thấp hoặc sai cao, mặc dù xu hướng chung theo thời gian là độ ẩm của cây sẽ giảm.
Kết hợp hai quan sát đó, tôi quyết định rằng trong khoảng thời gian 1 giờ nhất định, có lẽ sẽ đủ tốt để gửi cảnh báo nếu tôi thấy chỉ số độ ẩm thấp trong 20 phút. Cứ 5 giây lại có một lần đọc, tức là 720 lần đọc một giờ và… làm một phép toán nhỏ ở đây, điều đó có nghĩa là tôi cần xem 240 lần đọc thấp trong khoảng thời gian 1 giờ trước khi gửi cảnh báo.
Vì vậy, những gì chúng ta sẽ làm bây giờ là tạo một luồng mới sẽ chứa tối đa một sự kiện trên mỗi cây trong khoảng thời gian 1 giờ. Tôi đã đạt được điều này bằng cách viết truy vấn sau:
CREATE TABLE houseplant_low_readings WITH ( kafka_topic='houseplant-low-readings', format='AVRO', partitions=4 ) AS SELECT plant_id, given_name, common_name, scientific_name, CONCAT(given_name, ' the ', common_name, ' (', scientific_name, ') is looking pretty dry...') AS message, COUNT(*) AS low_reading_count FROM houseplant_readings_enriched WINDOW TUMBLING (SIZE 1 HOURS, GRACE PERIOD 30 MINUTES) WHERE moisture < moisture_low GROUP BY plant_id, given_name, common_name, scientific_name HAVING COUNT(*) > 240 EMIT FINAL;
Trước tiên, bạn sẽ nhận thấy tập hợp có cửa sổ . Truy vấn này hoạt động trong khoảng thời gian 1 giờ không chồng chéo, cho phép tôi tổng hợp dữ liệu trên mỗi ID thực vật trong một khoảng thời gian nhất định. Khá đơn giản.
Tôi đang lọc và đếm cụ thể các hàng trong luồng kết quả đọc được bổ sung trong đó giá trị đọc độ ẩm nhỏ hơn ngưỡng độ ẩm thấp cho cây đó. Nếu con số đó ít nhất là 240, tôi sẽ đưa ra một kết quả làm cơ sở cho một cảnh báo.
Nhưng bạn có thể thắc mắc tại sao kết quả của truy vấn này lại nằm trong một bảng. Chà, như chúng ta biết, các luồng đại diện cho lịch sử ít nhiều hoàn chỉnh của một thực thể dữ liệu, trong khi các bảng phản ánh giá trị cập nhật nhất cho một khóa nhất định. Điều quan trọng cần nhớ là truy vấn này thực sự là một ứng dụng phát trực tuyến có trạng thái dưới vỏ bọc. Khi các thông báo truyền qua luồng dữ liệu được làm giàu cơ bản, nếu thông báo cụ thể đó đáp ứng yêu cầu của bộ lọc, chúng tôi sẽ tăng số lần đọc thấp cho ID nhà máy đó trong khoảng thời gian 1 giờ và theo dõi thông báo đó trong một trạng thái. Tuy nhiên, điều tôi thực sự quan tâm trong truy vấn này là kết quả cuối cùng của phép tổng hợp—liệu số lần đọc thấp có trên 240 đối với một khóa nhất định hay không. Tôi muốn một cái bàn.
Ngoài ra: Bạn sẽ nhận thấy rằng dòng cuối cùng của câu lệnh đó là `EMIT CUỐI CÙNG`. Cụm từ này có nghĩa là, thay vì có khả năng đưa ra kết quả mỗi khi một hàng mới chạy qua ứng dụng phát trực tuyến, tôi sẽ đợi cho đến khi cửa sổ đóng lại trước khi đưa ra kết quả.
Kết quả của truy vấn này là, đối với một ID nhà máy nhất định trong khoảng thời gian một giờ cụ thể, tôi sẽ xuất nhiều nhất một thông báo cảnh báo, giống như tôi muốn.
phân nhánh ra
Tại thời điểm này, tôi đã có một chủ đề Kafka do ksqlDB đưa ra có chứa một thông báo khi cây có độ ẩm thấp phù hợp và ổn định. Nhưng làm cách nào để tôi thực sự lấy dữ liệu này ra khỏi Kafka? Điều thuận tiện nhất đối với tôi là nhận thông tin này trực tiếp trên điện thoại của tôi.
Tôi không định phát minh lại bánh xe ở đây, vì vậy tôi đã tận dụng bài đăng trên blog này mô tả việc sử dụng bot Telegram để đọc tin nhắn từ chủ đề Kafka và gửi thông báo đến điện thoại. Theo quy trình được phác thảo bởi blog, tôi đã tạo bot Telegram và bắt đầu cuộc trò chuyện với bot đó trên điện thoại của mình, ghi lại ID duy nhất của cuộc trò chuyện đó cùng với khóa API cho bot của tôi. Với thông tin đó, tôi có thể sử dụng API trò chuyện Telegram để gửi tin nhắn từ bot đến điện thoại của mình.
Điều đó tốt và tốt, nhưng làm cách nào để nhận thông báo từ Kafka đến bot Telegram của tôi? Tôi có thể gọi tính năng gửi tin nhắn bằng cách viết một ứng dụng tiêu dùng riêng sẽ sử dụng các cảnh báo từ chủ đề Kafka và gửi từng tin nhắn theo cách thủ công qua API trò chuyện Telegram. Nhưng điều đó nghe giống như công việc làm thêm. Thay vào đó, tôi quyết định sử dụng Trình kết nối chìm HTTP được quản lý hoàn toàn để thực hiện điều tương tự nhưng không viết bất kỳ mã bổ sung nào của riêng tôi.
Trong vòng vài phút, Bot Telegram của tôi đã sẵn sàng hoạt động và tôi đã mở một cuộc trò chuyện riêng giữa tôi và bot. Bằng cách sử dụng ID trò chuyện, giờ đây tôi có thể sử dụng Trình kết nối HTTP chìm được quản lý hoàn toàn trên Confluent Cloud để gửi tin nhắn thẳng đến điện thoại của mình.
Cấu hình đầy đủ trông như thế này:
{ "name": "HttpSinkConnector_Houseplants_Telegram_Bot", "config": { "topics": "houseplant-low-readings", "input.data.format": "AVRO", "connector.class": "HttpSink", "name": "HttpSinkConnector_Houseplants_Telegram_Bot", "kafka.auth.mode": "KAFKA_API_KEY", "http.api.url": "https://api.telegram.org/**********/sendMessage", "request.method": "POST", "headers": "Content-Type: application/json", "request.body.format": "string", "batch.max.size": "1", "batch.prefix": "{\"chat_id\":\"********\",", "batch.suffix": "}", "regex.patterns": ".*MESSAGE=(.*),LOW_READING_COUNT=(.*)}.*", "regex.replacements": "\"text\":\"$1\"", "regex.separator": "~", "tasks.max": "1" } }


Vài ngày sau khi khởi chạy trình kết nối, tôi nhận được một thông báo rất hữu ích cho tôi biết rằng cây của tôi cần được tưới nước. Thành công!


Chuyển qua một chiếc lá mới
Đã khoảng một năm kể từ khi tôi hoàn thành giai đoạn đầu của dự án này. Trong thời gian đó, tôi vui mừng báo cáo rằng tất cả các cây mà tôi đang theo dõi đều vui vẻ và khỏe mạnh! Tôi không còn phải mất thêm thời gian để kiểm tra chúng nữa và tôi hoàn toàn có thể tin tưởng vào các cảnh báo được tạo bởi kênh truyền dữ liệu trực tuyến của mình. Làm thế nào là mát mẻ đó?


Nếu quá trình xây dựng dự án này khiến bạn tò mò, thì tôi khuyến khích bạn bắt đầu với đường dẫn dữ liệu phát trực tuyến của riêng mình. Cho dù bạn là người dùng Kafka dày dạn kinh nghiệm muốn thử thách bản thân trong việc xây dựng và kết hợp các quy trình thời gian thực vào cuộc sống của chính mình hay là người hoàn toàn mới biết về Kafka, thì tôi ở đây để nói với bạn rằng những loại dự án này là dành cho bạn .
Cũng được xuất bản ở đây.








