




















Em 2020, muitas pessoas adquiriram hobbies pandêmicos - coisas nas quais poderiam se dedicar com força total enquanto estavam restritas por bloqueios. Eu escolhi plantas de casa.
Antes da pandemia, eu já tinha uma pequena creche em minha casa. Honestamente, mesmo assim, dava muito trabalho cuidar de cada planta todos os dias. Vendo qual delas precisava ser regada, garantindo que todas recebessem a quantidade certa de luz solar, conversando com elas... #sócoisasdeplantasemcasa.
Ter mais tempo em casa significava que eu poderia investir mais em minhas plantas. E eu fiz - meu tempo, esforço e dinheiro. Existem algumas dezenas de plantas domésticas em minha casa; todos eles têm nomes, personalidades (pelo menos eu acho) e alguns até têm olhos arregalados. Isso, é claro, era bom enquanto eu ficava em casa o dia todo, mas, à medida que a vida voltava ao normal, me vi em uma situação difícil: não tinha mais todo o tempo do mundo para acompanhar minhas plantas. Eu precisava de uma solução. Deve haver uma maneira melhor de monitorar minhas plantas do que verificá-las manualmente todos os dias.


Digite Apache Kafka®. Bem, realmente, entra meu desejo de pegar mais um hobby: projetos de hardware.
Sempre quis uma desculpa para criar um projeto usando um Raspberry Pi e sabia que essa era minha chance. Eu construiria um sistema que pudesse monitorar minhas plantas para me alertar apenas quando elas precisassem de atenção e nem um momento depois. E eu usaria Kafka como espinha dorsal.
Isso realmente acabou sendo um projeto muito útil. Resolveu um problema muito real que eu tinha e me deu a chance de combinar minha obsessão por plantas domésticas com meu desejo ardente de finalmente usar Kafka em casa. Tudo isso foi agrupado em um projeto de hardware fácil e acessível que qualquer um poderia implementar por conta própria.
Se você é como eu e tem um problema de planta de casa que só pode ser resolvido automatizando sua casa, ou mesmo se você não é como eu, mas ainda quer um projeto legal para se aprofundar, este post de blog é para você .
Vamos arregaçar as mangas e botar a mão na massa!
Plantando as sementes
Primeiro, sentei-me para descobrir o que queria alcançar com este projeto. Para a primeira fase do sistema, poder monitorar os níveis de umidade de minhas plantas e receber alertas sobre elas seria muito útil - afinal, a parte mais demorada de cuidar de minhas plantas era decidir quais precisavam ser cuidadas. Se esse sistema pudesse lidar com esse processo de tomada de decisão, eu economizaria muito tempo!
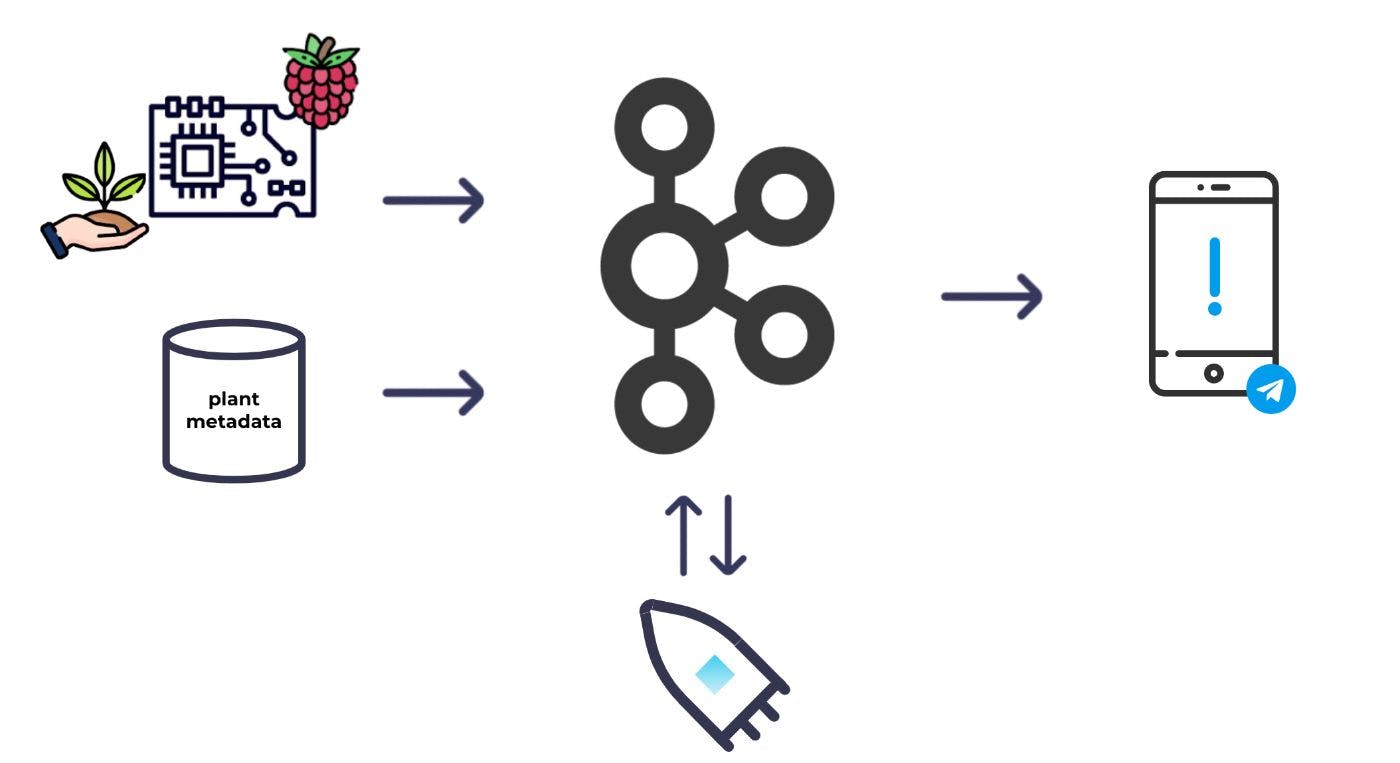
Em alto nível, este é o sistema básico que imaginei:


Eu colocaria alguns sensores de umidade no solo e os conectaria a um Raspberry Pi; Eu poderia fazer leituras de umidade regularmente e jogá-las no Kafka. Além das leituras de umidade, também precisei de alguns metadados para cada planta para decidir quais plantas precisam ser regadas. Eu também produziria os metadados no Kafka. Com ambos os conjuntos de dados em Kafka, eu poderia usar o processamento de fluxo para combinar e enriquecer os conjuntos de dados uns com os outros e calcular quais plantas precisam ser regadas. A partir daí, eu poderia disparar um alerta.
Com um conjunto de requisitos básicos estabelecidos, mergulhei na fase de hardware e montagem.
Tomando talo de coisas
Como muitos engenheiros que se prezam, iniciei o estágio de hardware com uma tonelada de pesquisas no Google. Eu sabia que todas as peças existiam para tornar este projeto um sucesso, mas, como era a primeira vez que trabalhava com componentes físicos, queria ter certeza de que sabia exatamente no que estava me metendo.
O principal objetivo do sistema de monitoramento era me dizer quando as plantas precisavam ser regadas, então, obviamente, eu precisava de algum tipo de sensor de umidade. Aprendi que os sensores de umidade do solo vêm em uma variedade de formas e tamanhos, estão disponíveis como componentes analógicos ou digitais e diferem na maneira como medem a umidade. No final, optei por esses sensores capacitivos I2C. Eles pareciam ser uma ótima opção para quem estava começando com hardware: como sensores capacitivos, duravam mais que os resistivos, não exigiam conversão analógica para digital e eram mais ou menos plug-and- jogar. Além disso, eles ofereciam medições de temperatura gratuitamente.
Um aparte: Para quem tem curiosidade, I2C significa Circuito Inter-Integrado. Cada um desses sensores se comunica por meio de um endereço exclusivo; portanto, para obter dados de cada sensor, preciso definir e acompanhar o endereço exclusivo de cada sensor que uso - algo a ser lembrado mais tarde.
Decidir sobre os sensores foi a maior parte da minha configuração física. Tudo o que faltava fazer em termos de hardware era conseguir um Raspberry Pi e alguns equipamentos. Então eu estava livre para começar a construir o sistema.
Usei os seguintes componentes:
- Raspberry Pi 4 Modelo B
- Placa de ensaio PCB de tamanho médio
- Sensores Capacitivos de Umidade do Solo
- Kit de Conector de Passo JST
- fio de fita de 4 fios
- Crimpadores, descascadores de fios, solda, ferro de solda (todos os quais encontrei convenientemente na minha garagem)


Do solo para cima…
Embora eu quisesse que este projeto fosse fácil e amigável para iniciantes, também queria me desafiar a fazer o máximo possível de fiação e solda. Para homenagear aqueles que vieram antes de mim , embarquei nesta jornada de montagem com alguns fios, um crimpador e um sonho. O primeiro passo foi preparar fio de fita suficiente para conectar quatro sensores à placa de ensaio e também para conectar a placa de ensaio ao meu Raspberry Pi. Para permitir o espaçamento entre os componentes na configuração, preparei comprimentos de 24”. Cada fio teve que ser descascado, crimpado e conectado a um conector JST (para os fios que conectam os sensores à placa de ensaio) ou a um soquete fêmea (para conectar ao próprio Raspberry Pi). Mas, é claro, se você deseja economizar tempo, esforço e lágrimas, recomendo que não prenda seus próprios fios e, em vez disso, compre fios preparados com antecedência.
Um aparte: dado o número de plantas domésticas que possuo, quatro podem parecer um número arbitrariamente baixo de sensores para usar em minha configuração de monitoramento. Conforme declarado anteriormente, como esses sensores são dispositivos I2C, qualquer informação que eles comuniquem será enviada usando um endereço exclusivo. Dito isso, os sensores de umidade do solo que comprei são todos enviados com o mesmo endereço padrão, o que é problemático para configurações como esta em que você deseja usar vários do mesmo dispositivo. Existem duas maneiras principais de contornar isso. A primeira opção depende do próprio dispositivo. Meu sensor particular tinha dois jumpers de endereço I2C na parte traseira, e soldar qualquer combinação deles significava que eu poderia alterar o endereço I2C para variar de 0x36 e 0x39. No total, eu poderia ter quatro endereços únicos, daí os quatro sensores que uso na configuração final. Se os dispositivos não tiverem um meio físico para alterar endereços, a segunda opção é redirecionar as informações e configurar endereços de proxy usando um multiplex. Visto que sou novo em hardware, senti que isso estava fora do escopo deste projeto em particular.
Depois de preparar os fios para conectar os sensores ao Raspberry Pi, confirmei que tudo estava configurado corretamente usando um script Python de teste para coletar leituras de um único sensor. Para maior segurança, testei os três sensores restantes da mesma maneira. E foi durante esse estágio que aprendi em primeira mão como os fios cruzados afetam os componentes eletrônicos… e como esses problemas são difíceis de depurar.
Com a fiação finalmente funcionando, pude conectar todos os sensores ao Raspberry Pi. Todos os sensores precisavam ser conectados aos mesmos pinos (GND, 3V3, SDA e SCL) no Raspberry Pi. Cada sensor tem um endereço I2C exclusivo, portanto, embora todos estejam se comunicando pelos mesmos fios, ainda posso obter dados de sensores específicos usando seus endereços. Tudo o que eu precisava fazer era conectar cada sensor à placa de ensaio e, em seguida, conectar a placa de ensaio ao Raspberry Pi. Para conseguir isso, usei um pouco de sobra de fio e conectei as colunas da protoboard usando solda. Em seguida, soldei os conectores JST diretamente na placa de ensaio para poder conectar os sensores facilmente.
Depois de conectar a breadboard ao Raspberry Pi, inserir os sensores em quatro plantas e confirmar por meio do script de teste que eu poderia ler os dados de todos os sensores, pude começar a trabalhar na produção dos dados no Kafka.
Dados de tomilho real
Com a configuração do Raspberry Pi e todos os sensores de umidade funcionando conforme o esperado, era hora de trazer o Kafka para o mix para começar a transmitir alguns dados.
Como você pode esperar, eu precisava de um cluster Kafka antes de poder gravar qualquer dado no Kafka. Querendo tornar o componente de software deste projeto o mais leve e fácil de configurar possível, optei por usar o Confluent Cloud como meu provedor Kafka. Isso significava que eu não precisava configurar ou gerenciar nenhuma infraestrutura e que meu cluster Kafka estava pronto minutos após a configuração.
Também vale a pena observar por que escolhi usar Kafka para este projeto, especialmente considerando que MQTT é mais ou menos o padrão de fato para streaming de dados de IoT de sensores. Kafka e MQTT são criados para mensagens de estilo pub/sub, portanto, são semelhantes nesse aspecto. Mas se você planeja criar um projeto de streaming de dados como este, o MQTT ficará aquém. Você precisa de outra tecnologia como Kafka para lidar com processamento de fluxo, persistência de dados e qualquer integração downstream. O ponto principal é que MQTT e Kafka funcionam muito bem juntos . Além do Kafka, eu definitivamente poderia ter usado o MQTT para o componente IoT do meu projeto. Em vez disso, decidi trabalhar diretamente com o produtor Python no Raspberry Pi. Dito isso, se você quiser usar MQTT e Kafka para qualquer projeto inspirado em IoT, tenha certeza de que ainda pode colocar seus dados MQTT no Kafka usando o MQTT Kafka Source Connector .
Eliminando dados
Antes de colocar qualquer dado em movimento, dei um passo para trás para decidir como queria estruturar as mensagens no meu tópico Kafka. Especialmente para projetos de hack como este, é fácil começar a disparar dados em um tópico Kafka sem nenhuma preocupação no mundo - mas é importante saber como você estruturará seus dados em tópicos, qual chave usará e os dados tipos em campos.
Então vamos começar com os tópicos. Como vão ficar? Os sensores tinham a capacidade de capturar umidade e temperatura - essas leituras deveriam ser gravadas em um único tópico ou em vários? Como as leituras de umidade e temperatura estavam sendo capturadas do sensor de uma planta ao mesmo tempo, eu as armazenei juntas na mesma mensagem Kafka. Juntas, essas duas informações compuseram uma leitura da planta para os propósitos deste projeto. Tudo iria no mesmo tópico de leitura.
Além dos dados do sensor, eu precisava de um tópico para armazenar os metadados das plantas domésticas, incluindo o tipo de planta que o sensor está monitorando e seus limites de temperatura e umidade. Essas informações seriam usadas durante o estágio de processamento de dados para determinar quando uma leitura deveria disparar um alerta.
Eu criei dois tópicos: houseplants-readings e houseplants-metadata . Quantas partições devo usar? Para ambos os tópicos, decidi usar o número padrão de partições no Confluent Cloud que, no momento da redação deste artigo, é seis. Esse era o número certo? Bem, sim e não. Nesse caso, devido ao baixo volume de dados com que estou lidando, seis partições por tópico pode ser um exagero, mas caso eu expanda esse projeto para mais plantas posteriormente, seria bom ter seis partições .
Além das partições, outro parâmetro de configuração importante a ser observado é a compactação de toras que habilitei no tópico de plantas domésticas. Ao contrário do fluxo de eventos `readings`, o tópico `metadata` contém dados de referência - ou metadados. Mantendo-o em um tópico compactado, você garante que os dados nunca envelhecerão e sempre terá acesso ao último valor conhecido para uma determinada chave (a chave, se você se lembra, sendo um identificador exclusivo para cada planta de casa).
Com base no exposto, escrevi dois esquemas Avro para as leituras e os metadados da planta doméstica (abreviados aqui para facilitar a leitura).
Esquema de leituras
{ "doc": "Houseplant reading taken from sensors.", "fields": [ {"name": "plant_id", "type": "int"}, {"name": "timestamp", "logicalType": "timestamp-millis", "type": "long"}, {"name": "moisture", "type": "float"}, {"name": "temperature", "type": "float"} ], "name": "reading", "namespace": "com.houseplants", "type": "record" }Esquema de metadados de plantas domésticas
{ "doc": "Houseplant metadata.", "fields": [ {"name": "plant_id", "type": "int"}, {"name": "scientific_name", "type": "string"}, {"name": "common_name", "type": "string"}, {"name": "given_name", "type": "string"}, {"name": "temperature_threshold_low", "type": "float"}, {"name": "temperature_threshold_high", "type": "float"}, {"name": "moisture_threshold_low", "type": "float"}, {"name": "moisture_threshold_high", "type": "float"} ], "name": "houseplant", "namespace": "com.houseplants", "type": "record" }
Se você já usou Kafka antes, sabe que ter tópicos e saber como são os valores de sua mensagem é apenas o primeiro passo. É igualmente importante saber qual será a chave para cada mensagem. Tanto para as leituras quanto para os metadados, me perguntei o que seria uma instância de cada um desses conjuntos de dados, pois é a instância da entidade que deve formar a base de uma chave em Kafka. Como as leituras estão sendo feitas por planta e os metadados são atribuídos por planta , uma instância de entidade de ambos os conjuntos de dados era uma planta individual. Decidi que a chave lógica de ambos os tópicos seria baseada na planta. Eu atribuiria um ID numérico a cada planta e faria com que esse número fosse a chave para as mensagens de leitura e as mensagens de metadados.
Então, com a sensação ligeiramente presunçosa de saber que estava fazendo isso da maneira certa, pude voltar minha atenção para transmitir os dados de meus sensores para os tópicos Kafka.
Cultivando mensagens
Eu queria começar a enviar os dados dos meus sensores para o Kafka. O primeiro passo foi instalar a biblioteca confluent-kafka Python no Raspberry Pi. A partir daí, escrevi um script Python para capturar as leituras de meus sensores e produzir os dados em Kafka.
Você acreditaria se eu dissesse que é tão fácil assim? Com apenas algumas linhas de código, meus dados de sensor estavam sendo gravados e persistidos em um tópico Kafka para uso em análises downstream. Ainda fico um pouco tonta só de pensar nisso.


Com as leituras do sensor em Kafka, agora eu precisava dos metadados da planta doméstica para conduzir qualquer tipo de análise posterior. Em pipelines de dados típicos, esse tipo de dados residiria em um banco de dados relacional ou algum outro armazenamento de dados e seria ingerido usando o Kafka Connect e os vários conectores disponíveis para ele.
Em vez de criar um banco de dados externo próprio, decidi usar o Kafka como a camada de armazenamento persistente para meus metadados. Com metadados para apenas um punhado de plantas, escrevi manualmente os dados direto para Kafka usando outro script Python .
A raiz do problema
Meus dados estão em Kafka; agora é hora de realmente sujar as mãos. Mas primeiro, vamos revisitar o que eu queria alcançar com este projeto. O objetivo geral é enviar um alerta quando minhas plantas apresentarem leituras de baixa umidade que indiquem que precisam ser regadas. Posso usar o processamento de fluxo para enriquecer os dados de leitura com os metadados e, em seguida, calcular um novo fluxo de dados para direcionar meus alertas.
Optei por usar o ksqlDB para o estágio de processamento de dados desse pipeline para poder processar os dados com o mínimo de codificação. Em conjunto com o Confluent Cloud, o ksqlDB é fácil de configurar e usar - você simplesmente fornece um contexto de aplicativo e escreve um SQL simples para começar a carregar e processar seus dados.
Definindo os dados de entrada
Antes que eu pudesse começar a processar os dados, eu precisava declarar meus conjuntos de dados dentro do aplicativo ksqlDB para que eles estivessem disponíveis para trabalhar. Para fazer isso, primeiro eu precisava decidir qual dos dois objetos ksqlDB de primeira classe meus dados deveriam ser representados como - TABLE ou STREAM - e então usar uma instrução CREATE para apontar para os tópicos Kafka existentes.
Os dados de leitura da planta doméstica são representados no ksqlDB como um STREAM — basicamente exatamente o mesmo que um tópico Kafka (uma série de eventos imutáveis apenas anexados), mas também com um esquema. De forma bastante conveniente, eu já havia projetado e declarado o esquema anteriormente, e o ksqlDB pode buscá-lo diretamente no Registro de Esquemas:
CREATE STREAM houseplant_readings ( id STRING KEY ) WITH ( kafka_topic='houseplant-readings', format='AVRO', partitions=4 );
Com o fluxo criado sobre o tópico Kafka, podemos usar SQL padrão para consultar e filtrá-lo para explorar os dados usando uma instrução simples como esta:
SELECT plant_id, moisture FROM HOUSEPLANT_READINGS EMIT CHANGES;


Os metadados das plantas domésticas precisam de um pouco mais de consideração. Embora seja armazenado como um tópico Kafka (assim como os dados de leitura), é logicamente um tipo diferente de dado - seu estado. Para cada planta, ela tem um nome, uma localização e assim por diante. Nós o armazenamos em um tópico Kafka compactado e o representamos no ksqlDB como uma TABLE . Uma tabela - assim como em um RDBMS normal - nos informa o estado atual de uma determinada chave. Observe que enquanto o ksqlDB coleta o próprio esquema aqui do Registro de Esquema, precisamos declarar explicitamente qual campo representa a chave primária da tabela.
CREATE TABLE houseplant_metadata ( id INTEGER PRIMARY KEY ) WITH ( kafka_topic='houseplant-metadata', format='AVRO', partitions=4 );Enriqueça os dados
Com ambos os conjuntos de dados registrados com meu aplicativo ksqlDB, a próxima etapa é enriquecer houseplant_readings com os metadados contidos na tabela houseplants . Isso cria um novo fluxo (apoiado por um tópico Kafka) com a leitura e os metadados para a planta associada:
A consulta de enriquecimento seria algo como o seguinte:
CREATE STREAM houseplant_readings_enriched WITH ( kafka_topic='houseplant-readings-enriched', format='AVRO', partitions=4 ) AS SELECT r.id AS plant_id, r.timestamp AS ts, r.moisture AS moisture, r.temperature AS temperature, h.scientific_name AS scientific_name, h.common_name AS common_name, h.given_name AS given_name, h.temperature_low AS temperature_low, h.temperature_high AS temperature_high, h.moisture_low AS moisture_low, h.moisture_high AS moisture_high FROM houseplant_readings AS r LEFT OUTER JOIN houseplants AS h ON houseplant_readings.id = houseplants.id PARTITION BY r.id EMIT CHANGES;
E a saída dessa consulta seria algo como isto:


Criando alertas em um fluxo de eventos
Pensando no início deste artigo, você deve se lembrar que o objetivo de tudo isso era me dizer quando uma planta precisaria ser regada. Temos um fluxo de leituras de umidade (e temperatura) e uma tabela que nos informa o limite no qual o nível de umidade de cada planta pode indicar que ela precisa ser regada. Mas como determino quando enviar um alerta de baixa umidade? E com que frequência os envio?
Ao tentar responder a essas perguntas, notei algumas coisas sobre meus sensores e os dados que eles estavam gerando. Em primeiro lugar, estou capturando dados em intervalos de cinco segundos. Se eu enviasse um alerta para cada leitura de umidade baixa, inundaria meu telefone com alertas - isso não é bom. Prefiro receber um alerta no máximo uma vez a cada hora. A segunda coisa que percebi ao olhar para meus dados foi que os sensores não eram perfeitos - eu via regularmente falsas leituras baixas ou falsas altas, embora a tendência geral ao longo do tempo fosse que o nível de umidade de uma planta diminuísse.
Combinando essas duas observações, decidi que dentro de um determinado período de 1 hora, provavelmente seria bom enviar um alerta se eu visse 20 minutos de leituras de baixa umidade. Em uma leitura a cada 5 segundos, são 720 leituras por hora, e… fazendo um pouco de matemática aqui, isso significa que eu precisaria ver 240 leituras baixas em um período de 1 hora antes de enviar um alerta.
Então, o que faremos agora é criar um novo fluxo que conterá no máximo um evento por planta por período de 1 hora. Eu consegui isso escrevendo a seguinte consulta:
CREATE TABLE houseplant_low_readings WITH ( kafka_topic='houseplant-low-readings', format='AVRO', partitions=4 ) AS SELECT plant_id, given_name, common_name, scientific_name, CONCAT(given_name, ' the ', common_name, ' (', scientific_name, ') is looking pretty dry...') AS message, COUNT(*) AS low_reading_count FROM houseplant_readings_enriched WINDOW TUMBLING (SIZE 1 HOURS, GRACE PERIOD 30 MINUTES) WHERE moisture < moisture_low GROUP BY plant_id, given_name, common_name, scientific_name HAVING COUNT(*) > 240 EMIT FINAL;
Em primeiro lugar, você notará a agregação janelada . Essa consulta opera em janelas de 1 hora sem sobreposição, permitindo agregar dados por ID da planta em uma determinada janela. Bem direto.
Estou especificamente filtrando e contando as linhas no fluxo de leituras enriquecidas em que o valor da leitura de umidade é menor que o limite de baixa umidade para aquela planta. Se essa contagem for de pelo menos 240, gerarei um resultado que formará a base de um alerta.
Mas você deve estar se perguntando porque o resultado dessa consulta está em uma tabela. Bem, como sabemos, os fluxos representam um histórico mais ou menos completo de uma entidade de dados, enquanto as tabelas refletem o valor mais atualizado de uma determinada chave. É importante lembrar que essa consulta é, na verdade, um aplicativo de streaming de estado nos bastidores. À medida que as mensagens fluem no fluxo de dados enriquecido subjacente, se essa mensagem específica atender ao requisito de filtro, incrementamos a contagem de leituras baixas para esse ID da planta dentro da janela de 1 hora e a acompanhamos dentro de um estado. O que realmente me interessa nessa consulta, no entanto, é o resultado final da agregação - se a contagem de leituras baixas está acima de 240 para uma determinada chave. Eu quero uma mesa.
Um aparte: você notará que a última linha dessa instrução é `EMIT FINAL`. Essa frase significa que, em vez de potencialmente produzir um resultado toda vez que uma nova linha flui pelo aplicativo de streaming, esperarei até que a janela seja fechada antes que um resultado seja emitido.
O resultado dessa consulta é que, para um determinado ID de planta em uma janela específica de uma hora, eu emitirei no máximo uma mensagem de alerta, exatamente como eu queria.
Ramificando-se
Neste ponto, eu tinha um tópico Kafka preenchido por ksqlDB contendo uma mensagem quando uma planta tem um nível de umidade baixa de forma adequada e consistente. Mas como eu realmente obtenho esses dados do Kafka? O mais conveniente para mim seria receber essas informações diretamente no meu telefone.
Eu não estava prestes a reinventar a roda aqui, então aproveitei esta postagem no blog que descreve o uso de um bot do Telegram para ler mensagens de um tópico Kafka e enviar alertas para um telefone. Seguindo o processo descrito pelo blog, criei um bot do Telegram e iniciei uma conversa com esse bot no meu telefone, anotando o ID exclusivo dessa conversa junto com a chave API do meu bot. Com essas informações, eu poderia usar a API de chat do Telegram para enviar mensagens do meu bot para o meu telefone.
Isso é muito bom, mas como faço para obter meus alertas de Kafka para meu bot do Telegram? Eu poderia invocar o envio de mensagens escrevendo um consumidor sob medida que consumiria os alertas do tópico Kafka e enviaria manualmente cada mensagem por meio da API de bate-papo do Telegram. Mas isso soa como trabalho extra. Em vez disso, decidi usar o HTTP Sink Connector totalmente gerenciado para fazer a mesma coisa, mas sem escrever nenhum código adicional de minha autoria.
Em alguns minutos, meu Bot do Telegram estava pronto para ação e abri um chat privado entre mim e o bot. Usando o ID do chat, agora posso usar o HTTP Sink Connector totalmente gerenciado no Confluent Cloud para enviar mensagens diretamente para o meu telefone.
A configuração completa ficou assim:
{ "name": "HttpSinkConnector_Houseplants_Telegram_Bot", "config": { "topics": "houseplant-low-readings", "input.data.format": "AVRO", "connector.class": "HttpSink", "name": "HttpSinkConnector_Houseplants_Telegram_Bot", "kafka.auth.mode": "KAFKA_API_KEY", "http.api.url": "https://api.telegram.org/**********/sendMessage", "request.method": "POST", "headers": "Content-Type: application/json", "request.body.format": "string", "batch.max.size": "1", "batch.prefix": "{\"chat_id\":\"********\",", "batch.suffix": "}", "regex.patterns": ".*MESSAGE=(.*),LOW_READING_COUNT=(.*)}.*", "regex.replacements": "\"text\":\"$1\"", "regex.separator": "~", "tasks.max": "1" } }


Alguns dias depois de lançar o conector, recebi uma mensagem muito útil avisando que minha planta precisava ser regada. Sucesso!


Virando uma nova folha
Faz cerca de um ano que concluí a fase inicial deste projeto. Nesse período, fico feliz em informar que todas as plantas que estou monitorando estão felizes e saudáveis! Não preciso mais perder tempo verificando-os e posso contar exclusivamente com os alertas gerados pelo meu pipeline de dados de streaming. Quão legal é isso?


Se o processo de criação deste projeto o intrigou, encorajo-o a começar seu próprio pipeline de dados de streaming. Seja você um usuário experiente do Kafka que deseja se desafiar a construir e incorporar pipelines em tempo real em sua própria vida ou alguém que é totalmente novo no Kafka, estou aqui para dizer que esses tipos de projetos são para você .
Também publicado aqui.








