




















En 2020, muchas personas adoptaron pasatiempos pandémicos, cosas a las que podían lanzarse con toda su fuerza mientras estaban restringidos por los bloqueos. Elegí plantas de interior.
Antes de la pandemia, ya tenía lo que equivalía a una pequeña guardería en mi casa. Honestamente, incluso entonces, fue mucho trabajo cuidar cada planta todos los días. Ver cuáles de ellos necesitaban ser regados, asegurarse de que todos recibieran la cantidad correcta de luz solar, hablar con ellos... #justHouseplantThings.
Tener más tiempo en casa significaba que podía invertir más en mis plantas. Y lo hice: mi tiempo, esfuerzo y dinero. Hay algunas docenas de plantas de interior en mi casa; todos tienen nombres, personalidades (al menos eso creo), y algunos incluso tienen ojos saltones. Esto, por supuesto, estaba bien mientras estaba en casa todo el día, pero, a medida que la vida volvía lentamente a la normalidad, me encontré en una posición difícil: ya no tenía todo el tiempo del mundo para hacer un seguimiento de mis plantas. Necesitaba una solución. Tenía que haber una mejor manera de monitorear mis plantas que revisarlas manualmente todos los días.


Introduzca Apache Kafka®. Bueno, realmente, ingresa mi deseo de adquirir otro pasatiempo: proyectos de hardware.
Siempre quise una excusa para desarrollar un proyecto con una Raspberry Pi y sabía que esta era mi oportunidad. Construiría un sistema que pudiera monitorear mis plantas para alertarme solo cuando necesitaran atención y no un momento después. Y usaría a Kafka como columna vertebral.
Esto realmente resultó ser un proyecto muy útil. Resolvió un problema muy real que tenía y me dio la oportunidad de combinar mi obsesión por las plantas de interior con mi deseo de usar finalmente Kafka en casa. Todo esto se envolvió perfectamente en un proyecto de hardware fácil y accesible que cualquiera podría implementar por su cuenta.
Si eres como yo y tienes un problema con una planta de interior que solo puede resolverse automatizando tu hogar, o incluso si no eres como yo pero aún quieres un proyecto genial en el que profundizar, esta publicación de blog es para ti. .
¡Arremanguémonos y ensuciémonos las manos!
plantando las semillas
Primero, me senté para averiguar qué quería lograr con este proyecto. Para la primera fase del sistema, sería muy útil poder monitorear los niveles de humedad de mis plantas y recibir alertas sobre ellos; después de todo, la parte más lenta del cuidado de mis plantas fue decidir cuáles necesitaban cuidados. Si este sistema pudiera manejar ese proceso de toma de decisiones, ¡me ahorraría mucho tiempo!
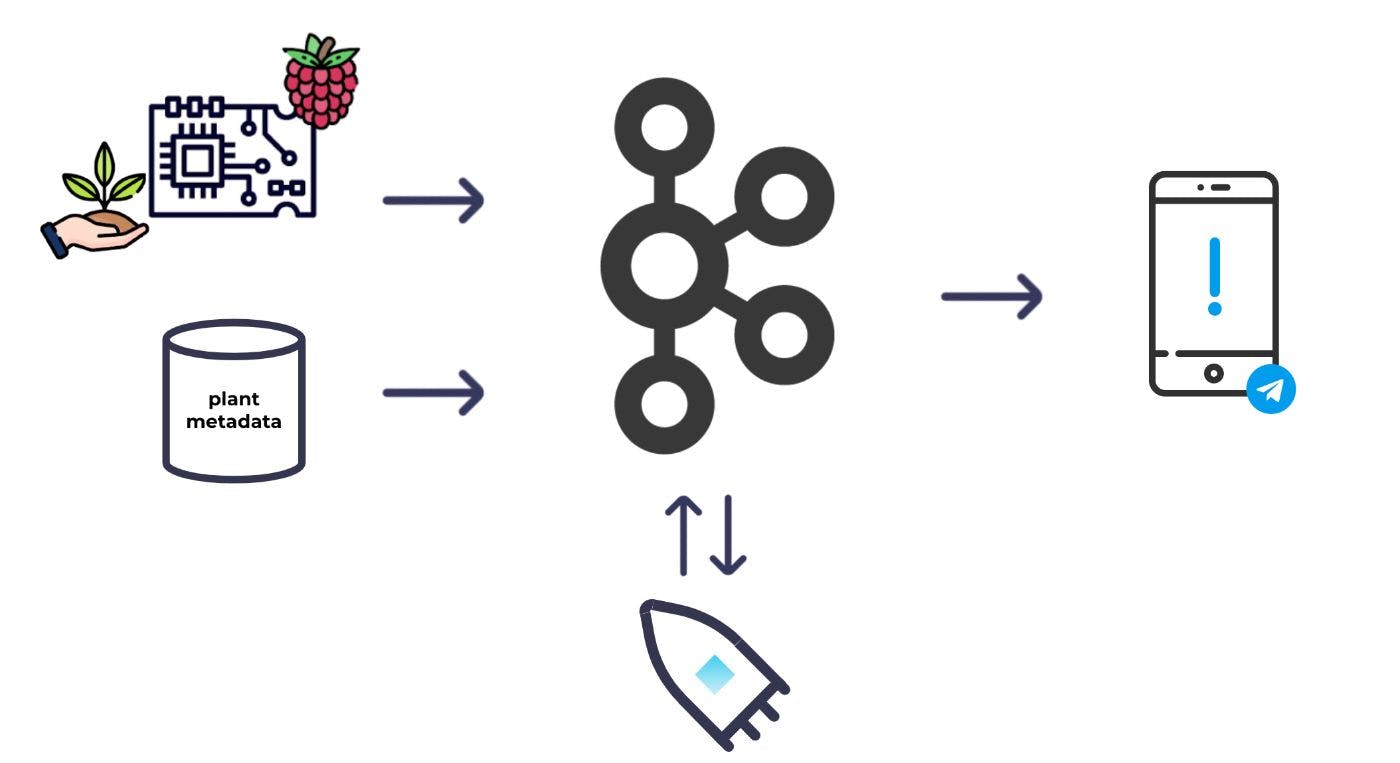
A un alto nivel, este es el sistema básico que imaginé:


Colocaría algunos sensores de humedad en el suelo y los conectaría a una Raspberry Pi; Luego podría tomar lecturas de humedad regularmente y arrojarlas a Kafka. Además de las lecturas de humedad, también necesitaba algunos metadatos para cada planta para decidir qué plantas necesitan ser regadas. También produciría los metadatos en Kafka. Con ambos conjuntos de datos en Kafka, podría usar el procesamiento de flujo para combinar y enriquecer los conjuntos de datos entre sí y calcular qué plantas necesitan ser regadas. A partir de ahí, podría activar una alerta.
Con un conjunto de requisitos básicos establecidos, me sumergí en la fase de hardware y montaje.
Tomando tallo de cosas
Como muchos ingenieros que se respetan a sí mismos, comencé la etapa de hardware con un montón de búsquedas en Google. Sabía que existían todas las piezas para que este proyecto fuera un éxito, pero como era la primera vez que trabajaba con componentes físicos, quería asegurarme de saber exactamente en qué me estaba metiendo.
El objetivo principal del sistema de monitoreo era decirme cuándo había que regar las plantas, así que obviamente necesitaba algún tipo de sensor de humedad. Aprendí que los sensores de humedad del suelo vienen en una variedad de formas y tamaños, están disponibles como componentes analógicos o digitales y difieren en la forma en que miden la humedad. Al final, me decidí por estos sensores capacitivos I2C. Parecían ser una gran opción para alguien que acababa de empezar con el hardware: como sensores capacitivos, duraban más que los basados en resistencia, no requerían conversión de analógico a digital y eran más o menos plug-and- jugar. Además, ofrecieron mediciones de temperatura de forma gratuita.
Un aparte: para aquellos que tienen curiosidad, I2C significa Circuito Interintegrado. Cada uno de estos sensores se comunica a través de una dirección única; por lo tanto, para obtener datos de cada sensor, debo configurar y realizar un seguimiento de la dirección única de cada sensor que uso, algo a tener en cuenta para más adelante.
Decidir sobre los sensores fue la parte más importante de mi configuración física. Todo lo que quedaba por hacer en cuanto al hardware era conseguir una Raspberry Pi y algunos equipos. Entonces fui libre de comenzar a construir el sistema.
Usé los siguientes componentes:
- Raspberry Pi 4 Modelo B
- Placa de circuito impreso de tamaño medio
- Sensores capacitivos de humedad del suelo
- Kit de conector de paso JST
- Alambre de cinta de 4 hilos
- Crimpers, pelacables, soldadura, soldador (todo lo cual encontré convenientemente en mi garaje)


Desde el suelo hacia arriba…
Aunque quería que este proyecto fuera fácil y apto para principiantes, también quería desafiarme a mí mismo para hacer la mayor cantidad posible de cableado y soldadura. Para honrar a los que me precedieron , me embarqué en este viaje de montaje con unos alambres, una crimpadora y un sueño. El primer paso fue preparar suficiente cable plano para conectar cuatro sensores a la placa y también para conectar la placa a mi Raspberry Pi. Para permitir el espacio entre los componentes en la configuración, preparé longitudes de 24". Cada cable tuvo que ser pelado, engarzado y enchufado en un conector JST (para los cables que conectan los sensores a la placa de pruebas) o en un enchufe hembra (para conectarse a la propia Raspberry Pi). Pero, por supuesto, si está buscando ahorrar tiempo, esfuerzo y lágrimas, le recomiendo que no engarce sus propios cables y, en su lugar, compre cables preparados con anticipación.
Un comentario aparte: Dada la cantidad de plantas de interior que tengo, cuatro pueden parecer una cantidad arbitrariamente baja de sensores para usar en mi configuración de monitoreo. Como se indicó anteriormente, dado que estos sensores son dispositivos I2C, cualquier información que comuniquen se enviará mediante una dirección única. Dicho esto, todos los sensores de humedad del suelo que compré se envían con la misma dirección predeterminada, lo cual es problemático para configuraciones como esta en las que desea usar varios del mismo dispositivo. Hay dos formas principales de evitar esto. La primera opción depende del propio dispositivo. Mi sensor particular tenía dos puentes de dirección I2C en la parte trasera, y soldar cualquier combinación de estos significaba que podía cambiar la dirección I2C para que oscilara entre 0x36 y 0x39. En total, podría tener cuatro direcciones únicas, de ahí los cuatro sensores que uso en la configuración final. Si los dispositivos carecen de un medio físico para cambiar las direcciones, la segunda opción es redirigir la información y configurar direcciones proxy mediante un multiplex. Dado que soy nuevo en el hardware, sentí que estaba fuera del alcance de este proyecto en particular.
Después de preparar los cables para conectar los sensores a la Raspberry Pi, confirmé que todo estaba configurado correctamente mediante un script de prueba de Python para recopilar lecturas de un solo sensor. Para mayor tranquilidad, probé los tres sensores restantes de la misma manera. Y fue durante esta etapa que aprendí de primera mano cómo los cables cruzados afectan los componentes electrónicos... y cuán difíciles son de depurar estos problemas.
Con el cableado finalmente funcionando, pude conectar todos los sensores a la Raspberry Pi. Todos los sensores debían conectarse a los mismos pines (GND, 3V3, SDA y SCL) en la Raspberry Pi. Sin embargo, cada sensor tiene una dirección I2C única, por lo que, aunque todos se comunican a través de los mismos cables, aún podría obtener datos de sensores específicos usando su dirección. Todo lo que tenía que hacer era conectar cada sensor a la placa de pruebas y luego conectar la placa de pruebas a la Raspberry Pi. Para lograr esto, usé un poco de alambre sobrante y conecté las columnas del protoboard usando soldadura. Luego soldé los conectores JST directamente a la placa de prueba para poder enchufar fácilmente los sensores.
Después de conectar la placa de prueba a la Raspberry Pi, insertar los sensores en cuatro plantas y confirmar a través de un script de prueba que podía leer los datos de todos los sensores, pude comenzar a trabajar en la producción de datos en Kafka.
Datos de tomillo real
Con la configuración de Raspberry Pi y todos los sensores de humedad funcionando como se esperaba, era hora de incluir a Kafka en la mezcla para comenzar a transmitir algunos datos.
Como era de esperar, necesitaba un clúster de Kafka antes de poder escribir datos en Kafka. Con el deseo de hacer que el componente de software de este proyecto fuera lo más liviano y fácil de configurar posible, opté por usar Confluent Cloud como mi proveedor de Kafka. Hacerlo significaba que no necesitaba configurar ni administrar ninguna infraestructura y que mi clúster de Kafka estaba listo a los pocos minutos de configurarlo.
También vale la pena señalar por qué elegí usar Kafka para este proyecto, especialmente considerando que MQTT es más o menos el estándar de facto para transmitir datos de IoT desde sensores. Tanto Kafka como MQTT están diseñados para mensajes de estilo pub/sub, por lo que son similares en ese sentido. Pero si planea desarrollar un proyecto de transmisión de datos como este, MQTT se quedará corto. Necesita otra tecnología como Kafka para manejar el procesamiento de secuencias, la persistencia de datos y cualquier integración posterior. La conclusión es que MQTT y Kafka funcionan muy bien juntos . Además de Kafka, definitivamente podría haber usado MQTT para el componente IoT de mi proyecto. En cambio, decidí trabajar directamente con el productor de Python en Raspberry Pi. Dicho esto, si desea usar MQTT y Kafka para cualquier proyecto inspirado en IoT, tenga la seguridad de que aún puede obtener sus datos de MQTT en Kafka utilizando el MQTT Kafka Source Connector .
Eliminación de datos
Antes de poner ningún dato en movimiento, di un paso atrás para decidir cómo quería estructurar los mensajes sobre mi tema de Kafka. Especialmente para proyectos de pirateo como este, es fácil comenzar a enviar datos a un tema de Kafka sin preocuparse por nada, pero es importante saber cómo estructurará sus datos en todos los temas, qué clave usará y los datos. tipos en los campos.
Así que vamos a empezar con los temas. ¿Cómo se verán esos? Los sensores tenían la capacidad de capturar la humedad y la temperatura. ¿Deberían escribirse estas lecturas en un solo tema o en varios? Dado que tanto las lecturas de humedad como las de temperatura se capturaban desde el sensor de una planta al mismo tiempo, las almacené juntas en el mismo mensaje de Kafka. Juntas, esas dos piezas de información componían una lectura de planta para los propósitos de este proyecto. Todo iría en el mismo tema de lectura.
Además de los datos del sensor, necesitaba un tema para almacenar los metadatos de la planta de interior, incluido el tipo de planta que el sensor está monitoreando y sus límites de temperatura y humedad. Esta información se usaría durante la etapa de procesamiento de datos para determinar cuándo una lectura debería activar una alerta.
Creé dos temas: houseplants-readings y houseplants-metadata . ¿Cuántas particiones debo usar? Para ambos temas, decidí usar el número predeterminado de particiones en Confluent Cloud que, en el momento de escribir este artículo, es seis. ¿Era ese el número correcto? Bueno, sí y no. En este caso, debido al bajo volumen de datos que estoy manejando, seis particiones por tema podrían ser excesivos, pero en el caso de que más adelante amplí este proyecto a más plantas, sería bueno tener seis particiones. .
Además de las particiones, otro parámetro de configuración importante a tener en cuenta es la compactación de troncos que habilité en el tema de las plantas de interior. A diferencia del flujo de eventos de `lecturas`, el tema `metadatos` contiene datos de referencia, o metadatos. Al mantenerlo en un tema compacto, se asegura de que los datos nunca caduquen y siempre tendrá acceso al último valor conocido para una clave determinada (la clave, si recuerda, es un identificador único para cada planta de interior).
En base a lo anterior, escribí dos esquemas de Avro para las lecturas y los metadatos de la planta de interior (abreviados aquí para facilitar la lectura).
esquema de lecturas
{ "doc": "Houseplant reading taken from sensors.", "fields": [ {"name": "plant_id", "type": "int"}, {"name": "timestamp", "logicalType": "timestamp-millis", "type": "long"}, {"name": "moisture", "type": "float"}, {"name": "temperature", "type": "float"} ], "name": "reading", "namespace": "com.houseplants", "type": "record" }Esquema de metadatos de plantas de interior
{ "doc": "Houseplant metadata.", "fields": [ {"name": "plant_id", "type": "int"}, {"name": "scientific_name", "type": "string"}, {"name": "common_name", "type": "string"}, {"name": "given_name", "type": "string"}, {"name": "temperature_threshold_low", "type": "float"}, {"name": "temperature_threshold_high", "type": "float"}, {"name": "moisture_threshold_low", "type": "float"}, {"name": "moisture_threshold_high", "type": "float"} ], "name": "houseplant", "namespace": "com.houseplants", "type": "record" }
Si ha usado Kafka antes, sabe que tener temas y saber cómo se ven los valores de su mensaje es solo el primer paso. Es igual de importante saber cuál será la clave para cada mensaje. Tanto para las lecturas como para los metadatos, me pregunté cuál sería una instancia de cada uno de estos conjuntos de datos, ya que es la instancia de la entidad la que debería formar la base de una clave en Kafka. Dado que las lecturas se toman por planta y los metadatos se asignan por planta , una instancia de entidad de ambos conjuntos de datos era una planta individual. Decidí que la clave lógica de ambos temas estaría basada en la planta. Asignaría una identificación numérica a cada planta y haría que ese número sea la clave tanto para los mensajes de lecturas como para los mensajes de metadatos.
Entonces, con la sensación de satisfacción un poco engreída que surge de saber que estaba haciendo esto de la manera correcta, pude centrar mi atención en transmitir los datos de mis sensores a los temas de Kafka.
Cultivando mensajes
Quería comenzar a enviar los datos de mis sensores a Kafka. El primer paso fue instalar la biblioteca Python confluent-kafka en la Raspberry Pi. A partir de ahí, escribí un script de Python para capturar las lecturas de mis sensores y generar los datos en Kafka.
¿Me creerías si te dijera que es así de fácil? Con solo un par de líneas de código, los datos de mi sensor se escribieron y persistieron en un tema de Kafka para su uso en análisis posteriores. Todavía me mareo un poco solo de pensarlo.


Con las lecturas de los sensores en Kafka, ahora necesitaba los metadatos de la planta de interior para realizar cualquier tipo de análisis posterior. En las canalizaciones de datos típicas, este tipo de datos residiría en una base de datos relacional o en algún otro almacén de datos y se incorporaría mediante Kafka Connect y los muchos conectores disponibles para ello.
En lugar de crear una base de datos externa propia, decidí usar Kafka como la capa de almacenamiento persistente para mis metadatos. Con metadatos para solo un puñado de plantas, escribí manualmente los datos directamente en Kafka usando otro script de Python .
La raíz del problema
Mis datos están en Kafka; ahora es el momento de realmente ensuciarme las manos. Pero primero, revisemos lo que quería lograr con este proyecto. El objetivo general es enviar una alerta cuando mis plantas tengan lecturas bajas de humedad que indiquen que necesitan riego. Puedo usar el procesamiento de secuencias para enriquecer los datos de las lecturas con los metadatos y luego calcular una nueva secuencia de datos para impulsar mis alertas.
Opté por usar ksqlDB para la etapa de procesamiento de datos de esta canalización para poder procesar los datos con una codificación mínima. Junto con Confluent Cloud, ksqlDB es fácil de configurar y usar: simplemente proporciona un contexto de aplicación y escribe un SQL simple para comenzar a cargar y procesar sus datos.
Definición de los datos de entrada
Antes de poder comenzar a procesar los datos, necesitaba declarar mis conjuntos de datos dentro de la aplicación ksqlDB para que estuviera disponible para trabajar con ellos. Para hacerlo, primero necesitaba decidir cuál de los dos objetos ksqlDB de primera clase deberían representar mis datos como TABLE o STREAM y luego usar una instrucción CREATE para señalar los temas de Kafka existentes.
Los datos de las lecturas de las plantas de interior se representan en ksqlDB como un STREAM , básicamente igual que un tema de Kafka (una serie de eventos inmutables solo para agregar), pero también con un esquema. Convenientemente, ya había diseñado y declarado el esquema anteriormente, y ksqlDB puede obtenerlo directamente del Registro de esquemas:
CREATE STREAM houseplant_readings ( id STRING KEY ) WITH ( kafka_topic='houseplant-readings', format='AVRO', partitions=4 );
Con el flujo creado sobre el tema de Kafka, podemos usar SQL estándar para consultarlo y filtrarlo para explorar los datos usando una declaración simple como esta:
SELECT plant_id, moisture FROM HOUSEPLANT_READINGS EMIT CHANGES;


Los metadatos de las plantas de interior necesitan un poco más de consideración. Si bien se almacena como un tema de Kafka (al igual que los datos de lectura), es lógicamente un tipo diferente de datos: su estado. Para cada planta, tiene un nombre, tiene una ubicación, etc. Lo almacenamos en un tema de Kafka compactado y lo representamos en ksqlDB como una TABLE . Una tabla, al igual que en un RDBMS normal, nos dice el estado actual de una clave dada. Tenga en cuenta que aunque ksqlDB recoge el esquema en sí mismo aquí desde el Registro de esquemas, necesitamos declarar explícitamente qué campo representa la clave principal de la tabla.
CREATE TABLE houseplant_metadata ( id INTEGER PRIMARY KEY ) WITH ( kafka_topic='houseplant-metadata', format='AVRO', partitions=4 );Enriquecer los datos
Con ambos conjuntos de datos registrados con mi aplicación ksqlDB, el siguiente paso es enriquecer houseplant_readings con los metadatos contenidos en la tabla houseplants . Esto crea una nueva secuencia (respaldada por un tema de Kafka) con la lectura y los metadatos de la planta asociada:
La consulta de enriquecimiento sería similar a la siguiente:
CREATE STREAM houseplant_readings_enriched WITH ( kafka_topic='houseplant-readings-enriched', format='AVRO', partitions=4 ) AS SELECT r.id AS plant_id, r.timestamp AS ts, r.moisture AS moisture, r.temperature AS temperature, h.scientific_name AS scientific_name, h.common_name AS common_name, h.given_name AS given_name, h.temperature_low AS temperature_low, h.temperature_high AS temperature_high, h.moisture_low AS moisture_low, h.moisture_high AS moisture_high FROM houseplant_readings AS r LEFT OUTER JOIN houseplants AS h ON houseplant_readings.id = houseplants.id PARTITION BY r.id EMIT CHANGES;
Y el resultado de esa consulta sería algo como esto:


Creación de alertas en un flujo de eventos
Pensando en el comienzo de este artículo, recordará que el objetivo de todo esto era decirme cuándo podría necesitar agua una planta. Tenemos un flujo de lecturas de humedad (y temperatura), y tenemos una tabla que nos dice el umbral en el que el nivel de humedad de cada planta puede indicar que necesita riego. Pero, ¿cómo determino cuándo enviar una alerta de humedad baja? y cada cuanto tiempo los envio?
Al tratar de responder a esas preguntas, noté algunas cosas sobre mis sensores y los datos que generaban. En primer lugar, estoy capturando datos a intervalos de cinco segundos. Si tuviera que enviar una alerta por cada lectura de humedad baja, inundaría mi teléfono con alertas, eso no es bueno. Preferiría recibir una alerta como máximo una vez cada hora. La segunda cosa de la que me di cuenta al mirar mis datos fue que los sensores no eran perfectos: regularmente veía lecturas falsas bajas o falsas altas, aunque la tendencia general con el tiempo era que el nivel de humedad de una planta disminuiría.
Combinando esas dos observaciones, decidí que dentro de un período determinado de 1 hora, probablemente sería lo suficientemente bueno como para enviar una alerta si obtuviera lecturas bajas de humedad durante 20 minutos. Con una lectura cada 5 segundos, eso es 720 lecturas por hora, y... haciendo un poco de matemáticas aquí, eso significa que necesitaría ver 240 lecturas bajas en un período de 1 hora antes de enviar una alerta.
Entonces, lo que haremos ahora es crear una nueva transmisión que contendrá como máximo un evento por planta por período de 1 hora. Logré esto escribiendo la siguiente consulta:
CREATE TABLE houseplant_low_readings WITH ( kafka_topic='houseplant-low-readings', format='AVRO', partitions=4 ) AS SELECT plant_id, given_name, common_name, scientific_name, CONCAT(given_name, ' the ', common_name, ' (', scientific_name, ') is looking pretty dry...') AS message, COUNT(*) AS low_reading_count FROM houseplant_readings_enriched WINDOW TUMBLING (SIZE 1 HOURS, GRACE PERIOD 30 MINUTES) WHERE moisture < moisture_low GROUP BY plant_id, given_name, common_name, scientific_name HAVING COUNT(*) > 240 EMIT FINAL;
Lo primero es lo primero, notará la agregación en ventana . Esta consulta opera en ventanas de 1 hora que no se superponen, lo que me permite agregar datos por ID de planta dentro de una ventana determinada. Muy claro.
Estoy filtrando específicamente y contando las filas en el flujo de lecturas enriquecidas donde el valor de lectura de humedad es menor que el umbral de humedad bajo para esa planta. Si ese recuento es de al menos 240, mostraré un resultado que formará la base de una alerta.
Pero quizás se pregunte por qué el resultado de esta consulta está en una tabla. Bueno, como sabemos, los flujos representan un historial más o menos completo de una entidad de datos, mientras que las tablas reflejan el valor más actualizado para una clave determinada. Es importante recordar que esta consulta es en realidad una aplicación de transmisión con estado oculta. A medida que los mensajes fluyen en el flujo de datos enriquecido subyacente, si ese mensaje en particular cumple con el requisito de filtro, incrementamos el conteo de lecturas bajas para esa ID de planta dentro de la ventana de 1 hora y realizamos un seguimiento dentro de un estado. Sin embargo, lo que realmente me importa en esta consulta es el resultado final de la agregación, si el recuento de lecturas bajas es superior a 240 para una clave determinada. quiero una mesa
Un comentario aparte: notará que la última línea de esa declaración es `EMIT FINAL`. Esta frase significa que, en lugar de generar potencialmente un resultado cada vez que una nueva fila fluye a través de la aplicación de transmisión, esperaré hasta que la ventana se haya cerrado antes de que se emita un resultado.
El resultado de esta consulta es que, para una identificación de planta dada en una ventana específica de una hora, mostraré como máximo un mensaje de alerta, tal como quería.
ramificándose
En este punto, tenía un tema de Kafka poblado por ksqlDB que contenía un mensaje cuando una planta tiene un nivel de humedad bajo de manera adecuada y constante. Pero, ¿cómo obtengo realmente estos datos de Kafka? Lo más conveniente para mí sería recibir esta información directamente en mi teléfono.
No estaba dispuesto a reinventar la rueda aquí, así que aproveché esta publicación de blog que describe el uso de un bot de Telegram para leer mensajes de un tema de Kafka y enviar alertas a un teléfono. Siguiendo el proceso descrito en el blog, creé un bot de Telegram y comencé una conversación con ese bot en mi teléfono, tomando nota de la ID única de esa conversación junto con la clave API de mi bot. Con esa información, podría usar la API de chat de Telegram para enviar mensajes desde mi bot a mi teléfono.
Eso está muy bien, pero ¿cómo envío mis alertas de Kafka a mi bot de Telegram? Podría invocar el envío de mensajes escribiendo un consumidor personalizado que consumiría las alertas del tema de Kafka y enviaría manualmente cada mensaje a través de la API de chat de Telegram. Pero eso suena como un trabajo extra. En su lugar, decidí usar el HTTP Sink Connector completamente administrado para hacer lo mismo, pero sin escribir ningún código adicional propio.
En unos minutos, mi Telegram Bot estaba listo para la acción y tenía un chat privado abierto entre el bot y yo. Usando la ID de chat, ahora podía usar el conector receptor HTTP totalmente administrado en Confluent Cloud para enviar mensajes directamente a mi teléfono.
La configuración completa se veía así:
{ "name": "HttpSinkConnector_Houseplants_Telegram_Bot", "config": { "topics": "houseplant-low-readings", "input.data.format": "AVRO", "connector.class": "HttpSink", "name": "HttpSinkConnector_Houseplants_Telegram_Bot", "kafka.auth.mode": "KAFKA_API_KEY", "http.api.url": "https://api.telegram.org/**********/sendMessage", "request.method": "POST", "headers": "Content-Type: application/json", "request.body.format": "string", "batch.max.size": "1", "batch.prefix": "{\"chat_id\":\"********\",", "batch.suffix": "}", "regex.patterns": ".*MESSAGE=(.*),LOW_READING_COUNT=(.*)}.*", "regex.replacements": "\"text\":\"$1\"", "regex.separator": "~", "tasks.max": "1" } }


Unos días después de lanzar el conector, recibí un mensaje muy útil que me informaba que mi planta necesitaba ser regada. ¡Éxito!


Volviendo una nueva hoja
Ha pasado aproximadamente un año desde que completé la fase inicial de este proyecto. En ese momento, me complace informar que todas las plantas que estoy monitoreando están felices y saludables. Ya no tengo que pasar más tiempo revisándolos y puedo confiar exclusivamente en las alertas generadas por mi flujo de transmisión de datos. ¿Cuan genial es eso?


Si el proceso de creación de este proyecto lo intrigó, lo animo a comenzar con su propia canalización de transmisión de datos. Ya sea que sea un usuario experimentado de Kafka que quiera desafiarse a sí mismo para crear e incorporar canalizaciones en tiempo real en su propia vida, o alguien que es completamente nuevo en Kafka, estoy aquí para decirle que este tipo de proyectos son para usted .
También publicado aquí.








