





















Im Jahr 2020 haben sich so viele Menschen pandemiebedingten Hobbys angenommen – Dingen, denen sie sich trotz der Einschränkungen durch den Lockdown mit voller Wucht widmen konnten. Ich habe mich für Zimmerpflanzen entschieden.
Vor der Pandemie hatte ich in meinem Haus bereits so etwas wie ein kleines Kinderzimmer. Ehrlich gesagt war es schon damals eine Menge Arbeit, sich jeden Tag um jede einzelne Pflanze zu kümmern. Sehen Sie, welche von ihnen gegossen werden müssen, stellen Sie sicher, dass sie alle die richtige Menge Sonnenlicht bekommen, sprechen Sie mit ihnen ... #justHouseplantThings.
Da ich mehr Zeit zu Hause hatte, konnte ich mehr in meine Pflanzen investieren. Und das habe ich getan – meine Zeit, meine Mühe und mein Geld. In meinem Haus gibt es ein paar Dutzend Zimmerpflanzen; Sie alle haben Namen, Persönlichkeiten (zumindest glaube ich das) und einige haben sogar Kulleraugen. Das war natürlich in Ordnung, solange ich den ganzen Tag zu Hause war, aber als sich das Leben langsam wieder normalisierte, befand ich mich in einer schwierigen Lage: Ich hatte nicht mehr die ganze Zeit der Welt, den Überblick über meine Pflanzen zu behalten. Ich brauchte eine Lösung. Es musste eine bessere Möglichkeit geben, meine Pflanzen zu überwachen, als sie jeden Tag manuell zu überprüfen.


Geben Sie Apache Kafka® ein. Nun ja, wirklich, ich möchte mich noch einem weiteren Hobby widmen: Hardware-Projekten.
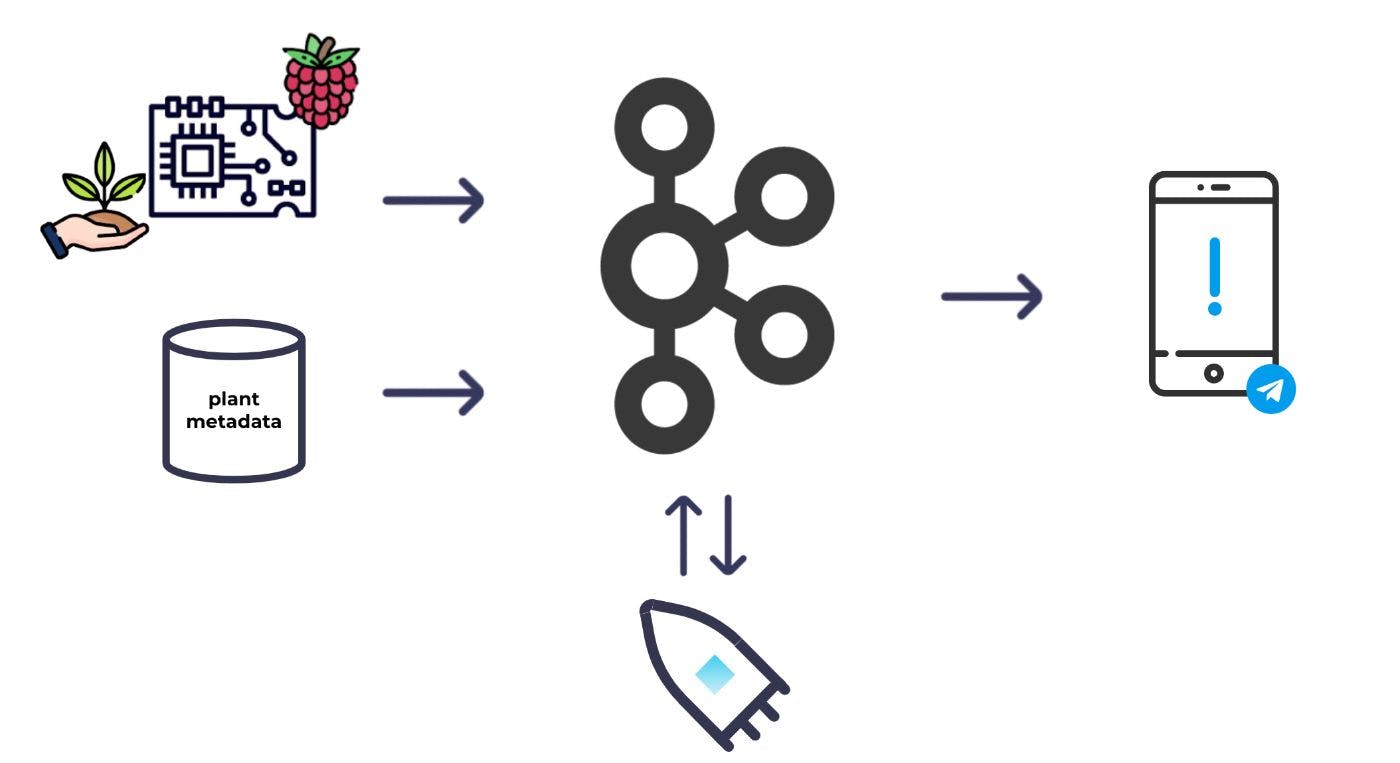
Ich wollte schon immer einen Vorwand haben, um ein Projekt mit einem Raspberry Pi zu entwickeln, und ich wusste, dass dies meine Chance war. Ich würde ein System aufbauen, das meine Pflanzen überwachen kann, um mich nur dann zu alarmieren, wenn sie Aufmerksamkeit benötigen, und nicht einen Moment später. Und ich würde Kafka als Rückgrat verwenden.
Es stellte sich heraus, dass es sich tatsächlich um ein sehr nützliches Projekt handelte. Es löste ein sehr reales Problem, das ich hatte, und gab mir die Möglichkeit, meine Zimmerpflanzenbesessenheit mit meinem brennenden Wunsch zu verbinden, endlich Kafka zu Hause zu verwenden. All dies wurde sauber in ein einfaches und zugängliches Hardwareprojekt verpackt, das jeder selbst implementieren konnte.
Wenn Sie wie ich sind und ein Zimmerpflanzenproblem haben, das nur durch die Automatisierung Ihres Zuhauses gelöst werden kann, oder wenn Sie ganz und gar nicht wie ich sind, aber dennoch ein cooles Projekt suchen, in das Sie sich vertiefen können, dann ist dieser Blogbeitrag genau das Richtige für Sie .
Krempeln wir die Ärmel hoch und machen uns die Hände schmutzig!
Die Samen pflanzen
Zuerst habe ich mich hingesetzt, um herauszufinden, was ich mit diesem Projekt erreichen wollte. Für die erste Phase des Systems wäre es sehr hilfreich, den Feuchtigkeitsgehalt meiner Pflanzen überwachen und Benachrichtigungen darüber erhalten zu können – schließlich war der zeitaufwändigste Teil der Pflege meiner Pflanzen die Entscheidung, welche Pflanzen gepflegt werden müssen. Wenn dieses System diesen Entscheidungsprozess bewältigen könnte, würde ich eine Menge Zeit sparen!
Auf hoher Ebene ist dies das grundlegende System, das ich mir vorgestellt habe:


Ich würde einige Feuchtigkeitssensoren im Boden platzieren und diese an einen Raspberry Pi anschließen; Ich könnte dann regelmäßig Feuchtigkeitsmessungen durchführen und diese in Kafka einfließen lassen. Zusätzlich zu den Feuchtigkeitswerten benötigte ich auch einige Metadaten für jede Pflanze, um zu entscheiden, welche Pflanzen bewässert werden müssen. Ich würde die Metadaten auch in Kafka produzieren. Mit beiden Datensätzen in Kafka könnte ich dann die Stream-Verarbeitung nutzen, um die Datensätze miteinander zu kombinieren und anzureichern und zu berechnen, welche Pflanzen bewässert werden müssen. Von dort aus konnte ich eine Warnung auslösen.
Nachdem eine Reihe grundlegender Anforderungen festgelegt waren, begann ich mit der Hardware- und Montagephase.
Sich um Dinge kümmern
Wie viele Ingenieure mit etwas Selbstachtung habe ich die Hardware-Phase mit einer Menge Googeln begonnen. Ich wusste, dass alle Teile vorhanden waren, um dieses Projekt zu einem Erfolg zu machen, aber da dies das erste Mal war, dass ich mit physischen Komponenten arbeitete, wollte ich sicherstellen, dass ich genau wusste, worauf ich mich einließ.
Der Hauptzweck des Überwachungssystems bestand darin, mir mitzuteilen, wann Pflanzen gegossen werden mussten. Daher brauchte ich natürlich eine Art Feuchtigkeitssensor. Ich habe gelernt, dass Bodenfeuchtigkeitssensoren in verschiedenen Formen und Größen erhältlich sind, als analoge oder digitale Komponenten erhältlich sind und sich in der Art und Weise unterscheiden, wie sie die Feuchtigkeit messen. Am Ende habe ich mich für diese kapazitiven I2C-Sensoren entschieden. Sie schienen eine großartige Option für jemanden zu sein, der gerade erst mit der Hardware anfing: Als kapazitive Sensoren hielten sie länger als auf Widerstandsbasis, sie erforderten keine Analog-Digital-Umwandlung und sie waren mehr oder weniger Plug-and-Play-fähig. spielen. Außerdem boten sie kostenlose Temperaturmessungen an.
Nebenbei: Für diejenigen, die neugierig sind: I2C bedeutet Inter-Integrated Circuit. Jeder dieser Sensoren kommuniziert über eine eindeutige Adresse; Um also Daten von jedem Sensor zu erfassen, muss ich die eindeutige Adresse für jeden von mir verwendeten Sensor festlegen und verfolgen – etwas, das ich mir für später merken sollte.
Die Entscheidung für Sensoren war der größte Teil meiner physischen Einrichtung. An Hardware fehlten nur noch ein Raspberry Pi und ein paar Geräte. Dann konnte ich mit dem Aufbau des Systems beginnen.
Ich habe folgende Komponenten verwendet:
- Raspberry Pi 4 Modell B
- Halbgroße Breadboard-Leiterplatte
- Kapazitive Bodenfeuchtesensoren
- JST Pitch Connector Kit
- 4-adriger Flachbanddraht
- Crimpzangen, Abisolierzangen, Lötzinn, Lötkolben (alles habe ich praktischerweise in meiner Garage gefunden)


Vom Boden aufwärts…
Obwohl ich wollte, dass dieses Projekt einfach und anfängerfreundlich ist, wollte ich mich auch der Herausforderung stellen, so viel wie möglich zu verkabeln und zu löten. Um diejenigen zu ehren, die vor mir kamen , begab ich mich mit einigen Drähten, einer Crimpzange und einem Traum auf diese Montagereise. Der erste Schritt bestand darin, genügend Flachbandkabel vorzubereiten, um vier Sensoren an das Steckbrett anzuschließen und das Steckbrett auch an meinen Raspberry Pi anzuschließen. Um den Abstand zwischen den Komponenten im Aufbau zu ermöglichen, habe ich 24-Zoll-Längen vorbereitet. Jeder Draht musste abisoliert, gecrimpt und entweder in einen JST-Stecker (für die Drähte, die die Sensoren mit dem Steckbrett verbinden) oder eine Buchse (für den Anschluss an den Raspberry Pi selbst) eingesteckt werden. Aber wenn Sie Zeit, Mühe und Geld sparen möchten, würde ich Ihnen natürlich empfehlen, Ihre Drähte nicht selbst zu quetschen und stattdessen vorgefertigte Drähte im Voraus zu kaufen.
Nebenbemerkung: Angesichts der Anzahl meiner Zimmerpflanzen scheinen vier eine willkürlich geringe Anzahl von Sensoren zu sein, die ich in meinem Überwachungsaufbau verwenden kann. Da es sich bei diesen Sensoren um I2C-Geräte handelt, werden, wie bereits erwähnt, alle von ihnen übermittelten Informationen über eine eindeutige Adresse gesendet. Allerdings werden die von mir gekauften Bodenfeuchtigkeitssensoren alle mit derselben Standardadresse geliefert, was bei solchen Konfigurationen, bei denen Sie mehrere gleiche Geräte verwenden möchten, problematisch ist. Es gibt zwei Möglichkeiten, dies zu umgehen. Die erste Option hängt vom Gerät selbst ab. Mein spezieller Sensor hatte zwei I2C-Adressbrücken auf der Rückseite, und durch das Einlöten einer beliebigen Kombination davon konnte ich die I2C-Adresse so ändern, dass sie zwischen 0x36 und 0x39 liegt. Insgesamt könnte ich vier eindeutige Adressen haben, daher die vier Sensoren, die ich im endgültigen Setup verwende. Fehlen den Geräten physische Möglichkeiten zur Adressänderung, besteht die zweite Möglichkeit darin, Informationen umzuleiten und Proxy-Adressen über einen Multiplex einzurichten. Da ich Hardware-Neuling bin, hatte ich das Gefühl, dass dies außerhalb des Rahmens dieses speziellen Projekts liegt.
Nachdem ich die Kabel für den Anschluss der Sensoren an den Raspberry Pi vorbereitet hatte, bestätigte ich, dass alles korrekt eingerichtet war, indem ich ein Test-Python-Skript verwendete, um Messwerte von einem einzelnen Sensor zu sammeln. Zur zusätzlichen Sicherheit habe ich die restlichen drei Sensoren auf die gleiche Weise getestet. Und in dieser Phase erfuhr ich aus erster Hand, wie sich gekreuzte Drähte auf elektronische Komponenten auswirken … und wie schwierig es ist, diese Probleme zu beheben.
Nachdem die Verkabelung endlich funktionierte, konnte ich alle Sensoren an den Raspberry Pi anschließen. Alle Sensoren mussten an die gleichen Pins (GND, 3V3, SDA und SCL) des Raspberry Pi angeschlossen werden. Jeder Sensor hat jedoch eine eindeutige I2C-Adresse. Obwohl alle über dieselben Leitungen kommunizieren, konnte ich anhand ihrer Adresse dennoch Daten von bestimmten Sensoren abrufen. Ich musste lediglich jeden Sensor mit dem Steckbrett verbinden und dann das Steckbrett mit dem Raspberry Pi verbinden. Um dies zu erreichen, habe ich ein Stück Drahtreste verwendet und die Säulen des Steckbretts mit Lötzinn verbunden. Anschließend habe ich JST-Anschlüsse direkt auf das Steckbrett gelötet, sodass ich die Sensoren problemlos anschließen konnte.
Nachdem ich das Steckbrett an den Raspberry Pi angeschlossen, die Sensoren in vier Pflanzen eingesetzt und per Testskript bestätigt hatte, dass ich Daten von allen Sensoren lesen konnte, konnte ich mit der Arbeit an der Produktion der Daten in Kafka beginnen.
Echte Thymiandaten
Nachdem das Raspberry Pi-Setup und alle Feuchtigkeitssensoren wie erwartet funktionierten, war es an der Zeit, Kafka in den Mix einzubeziehen, um mit dem Streamen einiger Daten zu beginnen.
Wie zu erwarten war, brauchte ich einen Kafka-Cluster, bevor ich Daten in Kafka schreiben konnte. Um die Softwarekomponente dieses Projekts so leichtgewichtig und einfach einzurichten wie möglich zu gestalten, habe ich mich für die Verwendung von Confluent Cloud als Kafka-Anbieter entschieden. Dadurch musste ich keine Infrastruktur einrichten oder verwalten und mein Kafka-Cluster war innerhalb weniger Minuten nach der Einrichtung bereit.
Erwähnenswert ist auch, warum ich mich für Kafka für dieses Projekt entschieden habe, insbesondere wenn man bedenkt, dass MQTT mehr oder weniger der De-facto-Standard für das Streamen von IoT-Daten von Sensoren ist. Sowohl Kafka als auch MQTT sind für Messaging im Pub/Sub-Stil konzipiert und ähneln sich daher in dieser Hinsicht. Wenn Sie jedoch planen, ein Daten-Streaming-Projekt wie dieses aufzubauen, wird MQTT zu kurz kommen. Sie benötigen eine andere Technologie wie Kafka, um die Stream-Verarbeitung, die Datenpersistenz und alle nachgelagerten Integrationen zu bewältigen. Unterm Strich funktionieren MQTT und Kafka wirklich gut zusammen . Zusätzlich zu Kafka hätte ich definitiv MQTT für die IoT-Komponente meines Projekts verwenden können. Stattdessen habe ich mich entschieden, direkt mit dem Python-Produzenten auf dem Raspberry Pi zusammenzuarbeiten. Wenn Sie jedoch MQTT und Kafka für ein IoT-inspiriertes Projekt verwenden möchten, können Sie sicher sein, dass Sie Ihre MQTT-Daten weiterhin über den MQTT Kafka Source Connector in Kafka übertragen können.
Durchsuchen von Daten
Bevor ich irgendwelche Daten in die Tat umsetzte, trat ich einen Schritt zurück und überlegte, wie ich die Botschaften zu meinem Kafka-Thema strukturieren wollte. Besonders bei Hack-Projekten wie diesem ist es einfach, ohne Sorgen damit zu beginnen, Daten in ein Kafka-Thema zu schicken – aber es ist wichtig zu wissen, wie Sie Ihre Daten themenübergreifend strukturieren, welchen Schlüssel Sie verwenden und welche Daten Sie verwenden Typen in Feldern.
Beginnen wir also mit den Themen. Wie werden diese aussehen? Die Sensoren hatten die Fähigkeit, Feuchtigkeit und Temperatur zu erfassen – sollten diese Messwerte zu einem einzelnen Thema oder zu mehreren geschrieben werden? Da sowohl die Feuchtigkeits- als auch die Temperaturwerte gleichzeitig vom Sensor einer Pflanze erfasst wurden, habe ich sie zusammen in derselben Kafka-Nachricht gespeichert. Zusammen bildeten diese beiden Informationen eine Pflanzenlesung für die Zwecke dieses Projekts. Es würde alles zum gleichen Lesethema gehören.
Zusätzlich zu den Sensordaten brauchte ich ein Thema zum Speichern der Zimmerpflanzen-Metadaten, einschließlich der Art der Pflanze, die der Sensor überwacht, sowie ihrer Temperatur- und Feuchtigkeitsgrenzen. Diese Informationen würden während der Datenverarbeitungsphase verwendet, um zu bestimmen, wann ein Messwert eine Warnung auslösen sollte.
Ich habe zwei Themen erstellt: houseplants-readings und houseplants-metadata . Wie viele Partitionen sollte ich verwenden? Für beide Themen habe ich mich entschieden, die Standardanzahl von Partitionen in Confluent Cloud zu verwenden, die zum Zeitpunkt des Schreibens sechs beträgt. War das die richtige Zahl? Nun, ja und nein. In diesem Fall könnten aufgrund des geringen Datenvolumens, mit dem ich es zu tun habe, sechs Partitionen pro Thema übertrieben sein, aber für den Fall, dass ich dieses Projekt später auf weitere Anlagen ausweite, wäre es gut, sechs Partitionen zu haben .
Neben den Partitionen ist ein weiterer wichtiger Konfigurationsparameter, den Sie beachten sollten, die Protokollkomprimierung, die ich beim Thema Zimmerpflanzen aktiviert habe. Im Gegensatz zum Ereignisstrom „Lesungen“ enthält das Thema „Metadaten“ Referenzdaten – oder Metadaten. Indem Sie es in einem komprimierten Thema aufbewahren, stellen Sie sicher, dass die Daten niemals veralten und Sie immer Zugriff auf den letzten bekannten Wert für einen bestimmten Schlüssel haben (wobei der Schlüssel, wenn Sie sich erinnern, eine eindeutige Kennung für jede Zimmerpflanze ist).
Basierend auf dem oben Gesagten habe ich zwei Avro-Schemata sowohl für die Messwerte als auch für die Zimmerpflanzen-Metadaten geschrieben (hier zur besseren Lesbarkeit gekürzt).
Leseschema
{ "doc": "Houseplant reading taken from sensors.", "fields": [ {"name": "plant_id", "type": "int"}, {"name": "timestamp", "logicalType": "timestamp-millis", "type": "long"}, {"name": "moisture", "type": "float"}, {"name": "temperature", "type": "float"} ], "name": "reading", "namespace": "com.houseplants", "type": "record" }Metadatenschema für Zimmerpflanzen
{ "doc": "Houseplant metadata.", "fields": [ {"name": "plant_id", "type": "int"}, {"name": "scientific_name", "type": "string"}, {"name": "common_name", "type": "string"}, {"name": "given_name", "type": "string"}, {"name": "temperature_threshold_low", "type": "float"}, {"name": "temperature_threshold_high", "type": "float"}, {"name": "moisture_threshold_low", "type": "float"}, {"name": "moisture_threshold_high", "type": "float"} ], "name": "houseplant", "namespace": "com.houseplants", "type": "record" }
Wenn Sie Kafka schon einmal verwendet haben, wissen Sie, dass es nur der erste Schritt ist, Themen zu haben und zu wissen, wie Ihre Nachrichtenwerte aussehen. Ebenso wichtig ist es zu wissen, was der Schlüssel für jede Nachricht sein wird. Sowohl für die Messwerte als auch für die Metadaten habe ich mich gefragt, was eine Instanz jedes dieser Datensätze wäre, da es die Entitätsinstanz ist, die die Grundlage eines Schlüssels in Kafka bilden sollte. Da die Messwerte pro Pflanze erfasst werden und die Metadaten jeder Pflanze zugewiesen werden, war eine Entitätsinstanz beider Datensätze eine einzelne Pflanze. Ich entschied, dass der logische Schlüssel beider Themen auf der Pflanze basieren würde. Ich würde jeder Pflanze eine numerische ID zuweisen und diese Nummer als Schlüssel sowohl für die Messwertmeldungen als auch für die Metadatenmeldungen festlegen.
Mit dem leicht selbstgefälligen Gefühl der Befriedigung, das sich aus dem Wissen ergibt, dass ich die Sache richtig gemacht habe, konnte ich meine Aufmerksamkeit darauf richten, die Daten meiner Sensoren in die Kafka-Themen zu streamen.
Botschaften kultivieren
Ich wollte damit beginnen, die Daten meiner Sensoren an Kafka zu senden. Schritt eins bestand darin, die Python-Bibliothek confluent-kafka auf dem Raspberry Pi zu installieren. Von dort aus habe ich ein Python-Skript geschrieben, um die Messwerte meiner Sensoren zu erfassen und die Daten in Kafka zu erzeugen.
Würden Sie es glauben, wenn ich Ihnen sagen würde, dass es so einfach ist? Mit nur wenigen Codezeilen wurden meine Sensordaten in ein Kafka-Thema geschrieben und dort gespeichert, um sie in nachgelagerten Analysen zu verwenden. Mir wird immer noch ein wenig schwindelig, wenn ich nur daran denke.


Mit Sensorablesungen in Kafka benötigte ich nun die Metadaten der Zimmerpflanze, um irgendeine Art von nachgelagerter Analyse durchführen zu können. In typischen Datenpipelines würden sich diese Art von Daten in einer relationalen Datenbank oder einem anderen Datenspeicher befinden und über Kafka Connect und die vielen dafür verfügbaren Konnektoren aufgenommen werden.
Anstatt eine eigene externe Datenbank aufzubauen, habe ich mich entschieden, Kafka als dauerhafte Speicherebene für meine Metadaten zu verwenden. Da ich nur Metadaten für eine Handvoll Pflanzen hatte, schrieb ich die Daten mithilfe eines anderen Python-Skripts manuell direkt in Kafka.
Die Wurzel des Problems
Meine Daten sind in Kafka; Jetzt ist es an der Zeit, mir richtig die Hände schmutzig zu machen. Aber lassen Sie uns zunächst noch einmal darüber nachdenken, was ich mit diesem Projekt erreichen wollte. Das übergeordnete Ziel besteht darin, eine Warnung zu senden, wenn meine Pflanzen niedrige Feuchtigkeitswerte aufweisen, die darauf hinweisen, dass sie bewässert werden müssen. Ich kann die Stream-Verarbeitung verwenden, um die Messwerte mit den Metadaten anzureichern und dann einen neuen Datenstrom zu berechnen, um meine Warnungen voranzutreiben.
Ich habe mich für die Verwendung von ksqlDB für die Datenverarbeitungsphase dieser Pipeline entschieden, damit ich die Daten mit minimalem Programmieraufwand verarbeiten kann. In Verbindung mit Confluent Cloud ist ksqlDB einfach einzurichten und zu verwenden – Sie stellen einfach einen Anwendungskontext bereit und schreiben ein paar einfache SQL-Anweisungen, um mit dem Laden und Verarbeiten Ihrer Daten zu beginnen.
Definieren der Eingabedaten
Bevor ich mit der Verarbeitung der Daten beginnen konnte, musste ich meine Datensätze in der ksqlDB-Anwendung deklarieren, damit sie für die Arbeit verfügbar waren. Dazu musste ich zunächst entscheiden, als welches der beiden erstklassigen ksqlDB-Objekte meine Daten dargestellt werden sollten – TABLE oder STREAM – und dann eine CREATE Anweisung verwenden, um auf die vorhandenen Kafka-Themen zu verweisen.
Die Zimmerpflanzen-Messdaten werden in ksqlDB als STREAM dargestellt – im Grunde genau das Gleiche wie ein Kafka-Topic (eine nur anfügbare Reihe unveränderlicher Ereignisse), aber auch mit einem Schema. Praktischerweise hatte ich das Schema bereits zuvor entworfen und deklariert, und ksqlDB kann es direkt aus der Schema-Registrierung abrufen:
CREATE STREAM houseplant_readings ( id STRING KEY ) WITH ( kafka_topic='houseplant-readings', format='AVRO', partitions=4 );
Mit dem über das Kafka-Thema erstellten Stream können wir ihn mithilfe von Standard-SQL abfragen und filtern, um die Daten mithilfe einer einfachen Anweisung wie dieser zu untersuchen:
SELECT plant_id, moisture FROM HOUSEPLANT_READINGS EMIT CHANGES;


Die Zimmerpflanzen-Metadaten müssen etwas genauer berücksichtigt werden. Obwohl es als Kafka-Topic gespeichert wird (genau wie die Lesedaten), handelt es sich logischerweise um einen anderen Datentyp – seinen Zustand. Für jede Pflanze gibt es einen Namen, einen Standort usw. Wir speichern es in einem komprimierten Kafka-Topic und stellen es in ksqlDB als TABLE dar. Eine Tabelle teilt uns – genau wie in einem normalen RDBMS – den aktuellen Status eines bestimmten Schlüssels mit. Beachten Sie, dass ksqlDB hier zwar das Schema selbst aus der Schema-Registrierung übernimmt, wir jedoch explizit deklarieren müssen, welches Feld den Primärschlüssel der Tabelle darstellt.
CREATE TABLE houseplant_metadata ( id INTEGER PRIMARY KEY ) WITH ( kafka_topic='houseplant-metadata', format='AVRO', partitions=4 );Bereichern Sie die Daten
Nachdem beide Datensätze bei meiner ksqlDB-Anwendung registriert sind, besteht der nächste Schritt darin, die houseplant_readings “ mit den in der Tabelle houseplants enthaltenen Metadaten anzureichern. Dadurch wird ein neuer Stream (untermauert durch ein Kafka-Thema) mit sowohl der Lektüre als auch den Metadaten für die zugehörige Pflanze erstellt:
Die Anreicherungsabfrage würde etwa wie folgt aussehen:
CREATE STREAM houseplant_readings_enriched WITH ( kafka_topic='houseplant-readings-enriched', format='AVRO', partitions=4 ) AS SELECT r.id AS plant_id, r.timestamp AS ts, r.moisture AS moisture, r.temperature AS temperature, h.scientific_name AS scientific_name, h.common_name AS common_name, h.given_name AS given_name, h.temperature_low AS temperature_low, h.temperature_high AS temperature_high, h.moisture_low AS moisture_low, h.moisture_high AS moisture_high FROM houseplant_readings AS r LEFT OUTER JOIN houseplants AS h ON houseplant_readings.id = houseplants.id PARTITION BY r.id EMIT CHANGES;
Und die Ausgabe dieser Abfrage würde etwa so aussehen:


Erstellen von Warnungen für einen Ereignisstrom
Wenn Sie an den Anfang dieses Artikels zurückdenken, werden Sie sich daran erinnern, dass der Sinn all dessen darin bestand, mir mitzuteilen, wann eine Pflanze möglicherweise gegossen werden muss. Wir haben eine Reihe von Feuchtigkeits- (und Temperatur-)Messwerten und eine Tabelle, die uns den Schwellenwert angibt, bei dem der Feuchtigkeitsgehalt jeder Pflanze darauf hindeutet, dass sie bewässert werden muss. Aber wie bestimme ich, wann eine Warnung zu niedriger Luftfeuchtigkeit gesendet werden soll? Und wie oft versende ich sie?
Bei dem Versuch, diese Fragen zu beantworten, sind mir einige Dinge an meinen Sensoren und den von ihnen generierten Daten aufgefallen. Zunächst erfasse ich Daten im Fünf-Sekunden-Intervall. Wenn ich bei jedem Feuchtigkeitsmangel eine Warnung senden würde, würde ich mein Telefon mit Warnungen überfluten – das nützt nichts. Ich würde es vorziehen, höchstens einmal pro Stunde eine Benachrichtigung zu erhalten. Das zweite, was mir beim Betrachten meiner Daten auffiel, war, dass die Sensoren nicht perfekt waren – ich sah regelmäßig falsch niedrige oder falsch hohe Messwerte, obwohl der allgemeine Trend im Laufe der Zeit darin bestand, dass der Feuchtigkeitsgehalt einer Pflanze abnahm.
Durch die Kombination dieser beiden Beobachtungen kam ich zu dem Schluss, dass es wahrscheinlich ausreichen würde, innerhalb eines bestimmten Zeitraums von einer Stunde eine Warnung zu senden, wenn ich 20 Minuten lang niedrige Feuchtigkeitswerte sehe. Bei einem Messwert alle 5 Sekunden sind das 720 Messwerte pro Stunde, und wenn ich hier ein wenig nachrechne, bedeutet das, dass ich in einem Zeitraum von einer Stunde 240 niedrige Messwerte sehen müsste, bevor ich eine Warnung senden kann.
Was wir jetzt tun, ist, einen neuen Stream zu erstellen, der höchstens ein Ereignis pro Pflanze und in einem Zeitraum von einer Stunde enthält. Dies habe ich erreicht, indem ich die folgende Abfrage geschrieben habe:
CREATE TABLE houseplant_low_readings WITH ( kafka_topic='houseplant-low-readings', format='AVRO', partitions=4 ) AS SELECT plant_id, given_name, common_name, scientific_name, CONCAT(given_name, ' the ', common_name, ' (', scientific_name, ') is looking pretty dry...') AS message, COUNT(*) AS low_reading_count FROM houseplant_readings_enriched WINDOW TUMBLING (SIZE 1 HOURS, GRACE PERIOD 30 MINUTES) WHERE moisture < moisture_low GROUP BY plant_id, given_name, common_name, scientific_name HAVING COUNT(*) > 240 EMIT FINAL;
Das Wichtigste zuerst: Sie werden die Fensteraggregation bemerken. Diese Abfrage erfolgt über nicht überlappende 1-Stunden-Fenster, sodass ich Daten pro Anlagen-ID innerhalb eines bestimmten Fensters aggregieren kann. Ziemlich einfach.
Ich filtere und zähle speziell die Zeilen im Stream mit angereicherten Messwerten, in denen der Feuchtigkeitsmesswert unter dem niedrigen Feuchtigkeitsschwellenwert für diese Pflanze liegt. Wenn dieser Wert mindestens 240 beträgt, gebe ich ein Ergebnis aus, das die Grundlage für eine Warnung bildet.
Aber Sie fragen sich vielleicht, warum das Ergebnis dieser Abfrage in einer Tabelle steht. Nun, wie wir wissen, stellen Streams einen mehr oder weniger vollständigen Verlauf einer Datenentität dar, während Tabellen den aktuellsten Wert für einen bestimmten Schlüssel widerspiegeln. Es ist wichtig, sich daran zu erinnern, dass es sich bei dieser Abfrage tatsächlich um eine Stateful-Streaming-Anwendung handelt. Während Nachrichten auf dem zugrunde liegenden angereicherten Datenstrom durchfließen und diese bestimmte Nachricht die Filteranforderung erfüllt, erhöhen wir die Anzahl der niedrigen Messwerte für diese Anlagen-ID innerhalb des 1-Stunden-Fensters und verfolgen sie innerhalb eines Status. Was mich bei dieser Abfrage jedoch wirklich interessiert, ist das Endergebnis der Aggregation – ob die Anzahl der niedrigen Messwerte für einen bestimmten Schlüssel über 240 liegt. Ich möchte einen Tisch.
Nebenbei: Sie werden feststellen, dass die letzte Zeile dieser Anweisung „EMIT FINAL“ lautet. Dieser Satz bedeutet, dass ich nicht jedes Mal, wenn eine neue Zeile durch die Streaming-Anwendung fließt, ein Ergebnis ausgibt, sondern warte, bis das Fenster geschlossen ist, bevor ein Ergebnis ausgegeben wird.
Das Ergebnis dieser Abfrage ist, dass ich für eine bestimmte Anlagen-ID in einem bestimmten einstündigen Fenster höchstens eine Warnmeldung ausgeben werde, genau wie ich es wollte.
Verzweigung
Zu diesem Zeitpunkt hatte ich ein Kafka-Thema, das von ksqlDB gefüllt wurde und eine Meldung enthielt, wenn eine Pflanze einen angemessen und konstant niedrigen Feuchtigkeitsgehalt aufweist. Aber wie bekomme ich diese Daten eigentlich aus Kafka heraus? Für mich wäre es am bequemsten, diese Informationen direkt auf mein Handy zu erhalten.
Ich hatte hier nicht vor, das Rad neu zu erfinden, also habe ich diesen Blog-Beitrag genutzt, der die Verwendung eines Telegram-Bots beschreibt, um Nachrichten aus einem Kafka-Thema zu lesen und Benachrichtigungen an ein Telefon zu senden. Ich folgte dem im Blog beschriebenen Prozess, erstellte einen Telegram-Bot und startete eine Konversation mit diesem Bot auf meinem Telefon, wobei ich mir die eindeutige ID dieser Konversation zusammen mit dem API-Schlüssel für meinen Bot notierte. Mit diesen Informationen könnte ich die Telegram-Chat-API verwenden, um Nachrichten von meinem Bot an mein Telefon zu senden.
Das ist schön und gut, aber wie bekomme ich meine Benachrichtigungen von Kafka an meinen Telegram-Bot? Ich könnte das Senden von Nachrichten aufrufen, indem ich einen maßgeschneiderten Verbraucher schreibe, der die Warnungen aus dem Kafka-Thema verarbeitet und jede Nachricht manuell über die Telegram-Chat-API sendet. Aber das klingt nach zusätzlicher Arbeit. Stattdessen habe ich mich entschieden, den vollständig verwalteten HTTP Sink Connector zu verwenden, um dasselbe zu tun, jedoch ohne zusätzlichen eigenen Code zu schreiben.
Innerhalb weniger Minuten war mein Telegram-Bot einsatzbereit und ich hatte einen privaten Chat zwischen mir und dem Bot geöffnet. Mithilfe der Chat-ID konnte ich jetzt den vollständig verwalteten HTTP Sink Connector in Confluent Cloud verwenden, um Nachrichten direkt an mein Telefon zu senden.
Die vollständige Konfiguration sah so aus:
{ "name": "HttpSinkConnector_Houseplants_Telegram_Bot", "config": { "topics": "houseplant-low-readings", "input.data.format": "AVRO", "connector.class": "HttpSink", "name": "HttpSinkConnector_Houseplants_Telegram_Bot", "kafka.auth.mode": "KAFKA_API_KEY", "http.api.url": "https://api.telegram.org/**********/sendMessage", "request.method": "POST", "headers": "Content-Type: application/json", "request.body.format": "string", "batch.max.size": "1", "batch.prefix": "{\"chat_id\":\"********\",", "batch.suffix": "}", "regex.patterns": ".*MESSAGE=(.*),LOW_READING_COUNT=(.*)}.*", "regex.replacements": "\"text\":\"$1\"", "regex.separator": "~", "tasks.max": "1" } }


Ein paar Tage nach der Einführung des Connectors erhielt ich eine sehr nützliche Nachricht, die mich darüber informierte, dass meine Pflanze bewässert werden musste. Erfolg!


Ein neues Kapitel aufschlagen
Es ist ungefähr ein Jahr her, seit ich die erste Phase dieses Projekts abgeschlossen habe. In dieser Zeit kann ich mit Freude berichten, dass alle Pflanzen, die ich beobachte, glücklich und gesund sind! Ich muss keine zusätzliche Zeit mehr damit verbringen, sie zu überprüfen, und kann mich ausschließlich auf die von meiner Streaming-Datenpipeline generierten Warnungen verlassen. Wie cool ist das?


Wenn Sie der Aufbau dieses Projekts fasziniert hat, empfehle ich Ihnen, mit der Entwicklung Ihrer eigenen Streaming-Datenpipeline zu beginnen. Egal, ob Sie ein erfahrener Kafka-Benutzer sind, der sich der Herausforderung stellen möchte, Echtzeit-Pipelines zu erstellen und in Ihr eigenes Leben zu integrieren, oder jemand, der Kafka noch nicht kennt, ich bin hier, um Ihnen zu sagen, dass diese Art von Projekten das Richtige für Sie ist.
Auch hier veröffentlicht.









