




















2020 年にさかのぼると、非常に多くの人々がパンデミックの趣味を始めました。観葉植物を選びました。
パンデミックの前に、私はすでに家に小さな保育園に相当するものを持っていました.正直なところ、毎日すべての植物の世話をするのは大変でした。どの植物に水をやる必要があるかを確認し、すべての植物に適切な量の日光が当たるようにし、話しかけたり… #justHouseplantThings.
家にいる時間が増えたことで、植物により多く投資できるようになりました。そして、私はそうしました—私の時間、労力、そしてお金。私の家には数十の観葉植物があります。全員に名前があり、性格があり (少なくとも私はそう思います)、中にはぎくしゃくした目をしている人もいます。もちろん、これは私が一日中家にいる間は問題ありませんでしたが、生活がゆっくりと通常に戻るにつれて、私は困難な立場にあることに気付きました。世界中で植物を追跡する時間がなくなったのです。解決策が必要でした。毎日手作業で植物をチェックするよりも、植物を監視するためのより良い方法が必要でした.


Apache Kafka® に入ります。ええと、本当に、もう 1 つの趣味であるハードウェア プロジェクトを始めたいという私の願望を入力してください。
私はいつも、Raspberry Pi を使ってプロジェクトを構築する言い訳が欲しかったのですが、これが私のチャンスだとわかっていました。植物を監視して、注意が必要なときにのみ警告を発するシステムを構築します。そして、Kafka をバックボーンとして使用します。
これは実際、非常に有用なプロジェクトであることが判明しました。それは私が抱えていた非常に現実的な問題を解決し、観葉植物への執着と、最終的に家でカフカを使用したいという私のかゆい欲求を組み合わせる機会を与えてくれました.これらすべてが、誰でも自分で実装できる簡単でアクセスしやすいハードウェア プロジェクトにきちんとまとめられました。
あなたが私のようで、家を自動化することによってのみ解決できる観葉植物の問題を抱えている場合、または私とはまったく違うが、それでも掘り下げてクールなプロジェクトが必要な場合でも、このブログ投稿はあなたのためのものです. .
袖まくりして手を汚しましょう!
種をまく
まず、このプロジェクトで何を達成したいかを考えました。システムの最初の段階では、植物の水分レベルを監視し、アラートを受け取ることができれば非常に役に立ちます。結局のところ、私の植物の世話で最も時間のかかる部分は、世話をする必要があるものを決定することでした.このシステムがその意思決定プロセスを処理できれば、時間を大幅に節約できるでしょう!
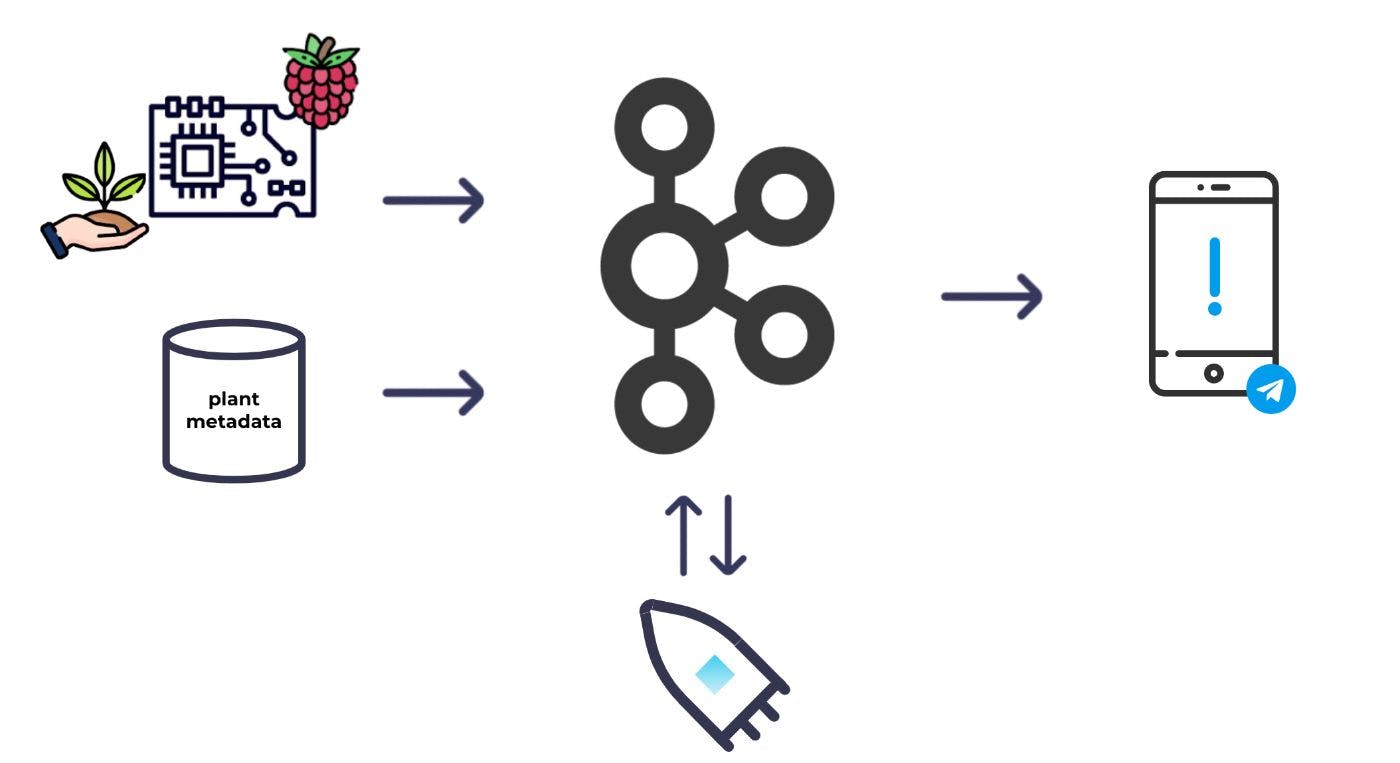
大まかに言うと、これが私が思い描いた基本的なシステムです。


土壌にいくつかの水分センサーを配置し、これらを Raspberry Pi に接続します。その後、定期的に水分の測定値を取得し、それらを Kafka に投げ込むことができました。水分の測定値に加えて、どの植物に水をやる必要があるかを判断するために、各植物のメタデータも必要でした。メタデータも Kafka に生成します。 Kafka の両方のデータセットを使用して、ストリーム処理を使用して、データセットを互いに組み合わせて強化し、どの植物に水をやる必要があるかを計算できます。そこから、アラートをトリガーできます。
一連の基本的な要件が確立されたので、ハードウェアと組み立てのフェーズに入りました。
物事の茎を取る
多くの自尊心のあるエンジニアと同様に、私はハードウェア ステージの開始時に大量の Google 検索を行いました。このプロジェクトを成功させるためにすべての要素が存在することは知っていましたが、物理的なコンポーネントを扱うのはこれが初めてだったので、自分が何に夢中になっているのかを正確に理解したいと思いました.
監視システムの主な目的は、植物にいつ水をやる必要があるかを知らせることだったので、明らかに何らかの水分センサーが必要でした。土壌水分センサーにはさまざまな形状とサイズがあり、アナログ コンポーネントまたはデジタル コンポーネントとして利用でき、水分を測定する方法が異なることを知りました。最終的に、これらの I2C 静電容量式センサーに落ち着きました。これらは、ハードウェアを使い始めたばかりの人にとっては素晴らしい選択肢のように思えました。静電容量センサーとして、抵抗ベースのものより長持ちし、アナログからデジタルへの変換を必要とせず、多かれ少なかれプラグアンド-遊ぶ。さらに、彼らは無料で温度測定を提供しました。
余談ですが、興味のある方のために、I2C は Inter-Integrated Circuit を意味します。これらの各センサーは、一意のアドレスを介して通信します。そのため、各センサーからデータを取得するには、使用するすべてのセンサーに一意のアドレスを設定して追跡する必要があります。これは後で覚えておく必要があります。
センサーの決定は、私の物理的なセットアップの最大の部分でした。ハードウェアに関しては、Raspberry Pi といくつかの機器を入手するだけで済みました。その後、私は自由にシステムの構築を開始しました。
次のコンポーネントを使用しました。
- ラズベリーパイ4モデルB
- ハーフサイズ ブレッドボード PCB
- 容量性土壌水分センサー
- JST ピッチ コネクタ キット
- 4 ストランド リボン ワイヤ
- クリンパー、ワイヤー ストリッパー、はんだ、はんだごて (ガレージで便利に見つけたすべて)


土から…
このプロジェクトは簡単で初心者にやさしくしたかったのですが、できるだけ多くの配線とはんだ付けに挑戦したかったのです。私の前に来た人々に敬意を表して、私はワイヤー、クリンパ、そして夢を持ってこの組み立ての旅に乗り出しました。最初のステップは、4 つのセンサーをブレッドボードに接続し、ブレッドボードを Raspberry Pi に接続するのに十分なリボン ワイヤを準備することでした。セットアップでコンポーネント間のスペースを確保するために、24 インチの長さを用意しました。各ワイヤは、剥がして圧着し、JST コネクタ (センサをブレッドボードに接続するワイヤ用) またはメス ソケット (Raspberry Pi 自体に接続するため) に差し込む必要がありました。しかし、もちろん、時間、労力、涙を節約したい場合は、自分でワイヤーを圧着するのではなく、あらかじめ準備されたワイヤーを購入することをお勧めします.
余談ですが、私が所有している観葉植物の数を考えると、監視設定で使用するセンサーの数が 4 つというのは非常に少ないように見えるかもしれません。前述のように、これらのセンサーは I2C デバイスであるため、通信する情報はすべて一意のアドレスを使用して送信されます。そうは言っても、私が購入した土壌水分センサーはすべて同じデフォルトアドレスで出荷されています。これは、同じデバイスを複数使用したいこのようなセットアップには問題があります.これを回避するには、主に 2 つの方法があります。最初のオプションは、デバイス自体によって異なります。私の特定のセンサーには、背面に 2 つの I2C アドレス ジャンパーがあり、これらの任意の組み合わせをはんだ付けすると、I2C アドレスを 0x36 から 0x39 の範囲に変更できました。合計で 4 つの一意のアドレスを持つことができたので、最終的なセットアップで使用する 4 つのセンサーです。デバイスにアドレスを変更するための物理的な手段がない場合、2 番目のオプションは、情報を再ルーティングし、マルチプレックスを使用してプロキシ アドレスを設定することです。私はハードウェアに慣れていないので、それはこの特定のプロジェクトの範囲外だと感じました。
センサーを Raspberry Pi に接続するためのワイヤを準備したら、 テスト Python スクリプトを使用して 1 つのセンサーから読み取り値を収集し、すべてが正しくセットアップされていることを確認しました。さらに安心させるために、残りの 3 つのセンサーを同じ方法でテストしました。この段階で、交差したワイヤが電子部品にどのように影響するか、そしてこれらの問題をデバッグするのがいかに難しいかを直接学びました。
ようやく配線が整い、すべてのセンサーを Raspberry Pi に接続できました。すべてのセンサーは、Raspberry Pi の同じピン (GND、3V3、SDA、および SCL) に接続する必要がありました。ただし、すべてのセンサーには固有の I2C アドレスがあるため、すべて同じワイヤで通信していても、アドレスを使用して特定のセンサーからデータを取得できました。各センサーをブレッドボードに配線し、ブレッドボードを Raspberry Pi に接続するだけでした。これを実現するために、少し残ったワイヤを使用して、ブレッドボードの列をはんだで接続しました。次に、センサーを簡単に接続できるように、JST コネクタをブレッドボードに直接はんだ付けしました。
ブレッドボードを Raspberry Pi に接続し、センサーを 4 つのプラントに挿入し、すべてのセンサーからデータを読み取れることをテスト スクリプトで確認した後、データを Kafka に生成する作業を開始できました。
リアルタイムデータ
Raspberry Pi のセットアップとすべての水分センサーが期待どおりに機能するようになったので、Kafka をミックスに取り入れてデータのストリーミングを開始するときが来ました。
ご想像のとおり、データを Kafka に書き込む前に Kafka クラスターが必要でした。このプロジェクトのソフトウェア コンポーネントをできるだけ軽量で簡単にセットアップできるようにしたいので、私はConfluent Cloud をKafka プロバイダーとして使用することにしました。そうすることで、インフラストラクチャをセットアップまたは管理する必要がなくなり、セットアップから数分で Kafka クラスターの準備が整いました。
MQTT が多かれ少なかれセンサーから IoT データをストリーミングするための事実上の標準であることを考えると、このプロジェクトで Kafka を使用することにした理由も注目に値します。 Kafka と MQTT はどちらも pub/sub スタイルのメッセージング用に構築されているため、その点では似ています。しかし、このようなデータ ストリーミング プロジェクトの構築を計画している場合、MQTT では不十分です。ストリーム処理、データの永続性、ダウンストリームの統合を処理するには、Kafka などの別のテクノロジが必要です。要するに、MQTT と Kafka は非常にうまく連携するということです。 Kafka に加えて、プロジェクトの IoT コンポーネントに MQTT を使用することもできたはずです。代わりに、Raspberry Pi で Python プロデューサーと直接連携することにしました。とはいえ、IoT に触発されたプロジェクトで MQTT と Kafka を使用したい場合は、 MQTT Kafka Source Connectorを使用して MQTT データを Kafka に取り込むことができますのでご安心ください。
データの除草
データを動作させる前に、一歩下がって、Kafka トピックに関するメッセージをどのように構造化するかを決定しました。特にこのようなハッキング プロジェクトの場合、心配することなく Kafka トピックにデータを送信し始めるのは簡単ですが、トピック間でデータをどのように構造化するか、どのキーを使用するか、およびデータを理解することが重要です。フィールドに入力します。
それでは、トピックから始めましょう。それらはどのように見えますか?センサーには、水分と温度をキャプチャする機能がありました。これらの読み取り値は、単一のトピックに書き込む必要がありますか?それとも複数のトピックに書き込む必要がありますか?水分と温度の両方の測定値が植物のセンサーから同時にキャプチャされていたので、同じ Kafka メッセージにまとめて保存しました。この 2 つの情報を合わせて、このプロジェクトの目的のためのプラント リーディングを構成しました。それはすべて同じ読書トピックに入るでしょう。
センサー データに加えて、センサーが監視している植物の種類とその温度と湿度の境界を含む観葉植物のメタデータを格納するためのトピックが必要でした。この情報は、データ処理段階で使用され、読み取り値がアラートをトリガーするタイミングを決定します。
houseplants-readingsとhouseplants-metadata 2 つのトピックを作成しました。いくつのパーティションを使用する必要がありますか?両方のトピックについて、Confluent Cloud のデフォルトのパーティション数 (執筆時点では 6) を使用することにしました。それは正しい数字でしたか?はい、いいえ。この場合、扱っているデータ量が少ないため、トピックごとに 6 つのパーティションはやり過ぎかもしれませんが、後でこのプロジェクトをより多くのプラントに拡張する場合は、6 つのパーティションがあればよいでしょう。 .
パーティションの他に、注目すべきもう 1 つの重要な構成パラメーターは、観葉植物のトピックで有効にしたログの圧縮です。イベントの `readings` ストリームとは異なり、`metadata` トピックには参照データ (メタデータ) が保持されます。圧縮されたトピックに保持することで、データが古くなることはなく、特定のキーの最後の既知の値に常にアクセスできます (覚えている場合、キーは各観葉植物の一意の識別子です)。
上記に基づいて、読み取り値と観葉植物のメタデータの両方に対して 2 つの Avro スキーマを作成しました (読みやすくするためにここでは短縮されています)。
読み値スキーマ
{ "doc": "Houseplant reading taken from sensors.", "fields": [ {"name": "plant_id", "type": "int"}, {"name": "timestamp", "logicalType": "timestamp-millis", "type": "long"}, {"name": "moisture", "type": "float"}, {"name": "temperature", "type": "float"} ], "name": "reading", "namespace": "com.houseplants", "type": "record" }観葉植物のメタデータ スキーマ
{ "doc": "Houseplant metadata.", "fields": [ {"name": "plant_id", "type": "int"}, {"name": "scientific_name", "type": "string"}, {"name": "common_name", "type": "string"}, {"name": "given_name", "type": "string"}, {"name": "temperature_threshold_low", "type": "float"}, {"name": "temperature_threshold_high", "type": "float"}, {"name": "moisture_threshold_low", "type": "float"}, {"name": "moisture_threshold_high", "type": "float"} ], "name": "houseplant", "namespace": "com.houseplants", "type": "record" }
以前に Kafka を使用したことがある場合は、トピックを持ち、メッセージの値がどのように見えるかを知ることが最初のステップにすぎないことを知っています。各メッセージのキーが何であるかを知ることも同様に重要です。読み取り値とメタデータの両方について、Kafka のキーの基礎を形成するエンティティ インスタンスであるため、これらの各データセットのインスタンスが何であるかを自問しました。測定値は植物ごとに取得され、メタデータは植物ごとに割り当てられるため、両方のデータセットのエンティティ インスタンスは個々の植物でした。私は、両方のトピックの論理的なキーは植物に基づいていると判断しました。各プラントに数値 ID を割り当て、その番号を読み取りメッセージとメタデータ メッセージの両方のキーにします。
したがって、これを正しい方法で行っていることを知っていることから得られるやや独善的な満足感で、センサーからのデータを Kafka トピックにストリーミングすることに注意を向けることができました。
メッセージの育成
センサーから Kafka へのデータの送信を開始したかったのです。ステップ 1 は、 confluent-kafka Python ライブラリを Raspberry Pi にインストールすることでした。そこから、センサーから読み取り値を取得し、Kafka でデータを生成するPython スクリプトを作成しました。
そんなに簡単だって言ったら信じてくれる?わずか数行のコードで、下流の分析で使用するためにセンサー データが Kafka トピックに書き込まれ、保持されていました。考えただけでまだ少しめまいがします。


Kafka でセンサーを読み取ったため、あらゆる種類のダウンストリーム分析を行うために、観葉植物のメタデータが必要になりました。典型的なデータ パイプラインでは、この種のデータはリレーショナル データベースまたはその他のデータ ストアに存在し、Kafka Connect とそれに使用できる多くのコネクタを使用して取り込まれます。
独自の外部データベースをスピンアップするのではなく、Kafka をメタデータの永続的なストレージ レイヤーとして使用することにしました。ほんの一握りの植物のメタデータを使用して、別のPython スクリプトを使用して手動で直接 Kafka にデータを書き込みました。
問題の根本
私のデータは Kafka にあります。今こそ、本当に手を汚す時です。しかし、最初に、このプロジェクトで達成したかったことをもう一度考えてみましょう。全体的な目標は、植物の水分測定値が低く、水やりが必要であることを示している場合にアラートを送信することです。ストリーム処理を使用して、読み取りデータをメタデータで強化し、新しいデータ ストリームを計算してアラートを生成できます。
最小限のコーディングでデータを処理できるように、このパイプラインのデータ処理段階で ksqlDB を使用することにしました。 Confluent Cloud と組み合わせると、ksqlDB は簡単にセットアップして使用できます。アプリケーション コンテキストをプロビジョニングし、単純な SQL を記述して、データのロードと処理を開始するだけです。
入力データの定義
データの処理を開始する前に、ksqlDB アプリケーション内でデータセットを宣言して、使用できるようにする必要がありました。そのためには、最初に 2 つの最上級の ksqlDB オブジェクト ( TABLEまたはSTREAMのどちらでデータを表すかを決定し、 CREATEステートメントを使用して既存の Kafka トピックを指す必要がありました。
観葉植物の測定値データは、ksqlDB ではSTREAMとして表されます。これは基本的に Kafka トピック (追加のみの一連の不変イベント) とまったく同じですが、スキーマも備えています。便利なことに、スキーマは以前に設計して宣言していたので、ksqlDB はスキーマ レジストリから直接取得できます。
CREATE STREAM houseplant_readings ( id STRING KEY ) WITH ( kafka_topic='houseplant-readings', format='AVRO', partitions=4 );
Kafka トピックに対して作成されたストリームを使用して、標準 SQL を使用してクエリを実行し、フィルター処理して、次のような単純なステートメントを使用してデータを探索できます。
SELECT plant_id, moisture FROM HOUSEPLANT_READINGS EMIT CHANGES;


観葉植物のメタデータについては、もう少し考慮する必要があります。これは Kafka トピックとして (読み取りデータと同様に) 保存されますが、論理的には異なるタイプのデータ、つまり状態です。各植物には、名前、場所などがあります。圧縮された Kafka トピックに格納し、 ksqlDB でTABLEとして表します。テーブルは、通常の RDBMS と同様に、特定のキーの現在の状態を示します。 ksqlDB はここでスキーマ レジストリからスキーマ自体を取得しますが、テーブルの主キーを表すフィールドを明示的に宣言する必要があることに注意してください。
CREATE TABLE houseplant_metadata ( id INTEGER PRIMARY KEY ) WITH ( kafka_topic='houseplant-metadata', format='AVRO', partitions=4 );データを充実させる
両方のデータセットを ksqlDB アプリケーションに登録したら、次のステップは、 houseplantsテーブルに含まれるメタデータでhouseplant_readings強化することです。これにより、関連付けられたプラントの読み取りとメタデータの両方を含む新しいストリーム (Kafka トピックによって支えられている) が作成されます。
強化クエリは次のようになります。
CREATE STREAM houseplant_readings_enriched WITH ( kafka_topic='houseplant-readings-enriched', format='AVRO', partitions=4 ) AS SELECT r.id AS plant_id, r.timestamp AS ts, r.moisture AS moisture, r.temperature AS temperature, h.scientific_name AS scientific_name, h.common_name AS common_name, h.given_name AS given_name, h.temperature_low AS temperature_low, h.temperature_high AS temperature_high, h.moisture_low AS moisture_low, h.moisture_high AS moisture_high FROM houseplant_readings AS r LEFT OUTER JOIN houseplants AS h ON houseplant_readings.id = houseplants.id PARTITION BY r.id EMIT CHANGES;
そして、そのクエリの出力は次のようになります。


イベント ストリームでのアラートの作成
この記事の冒頭を振り返ってみると、これらすべての要点は、植物にいつ水をやる必要があるかを教えてくれることだったことを覚えているでしょう.水分 (および温度) の読み取り値のストリームがあり、各植物の水分レベルが水やりの必要性を示す可能性があるしきい値を示す表があります。しかし、低湿度アラートを送信するタイミングをどのように判断すればよいでしょうか?どのくらいの頻度で送信しますか?
これらの質問に答えようとして、センサーとセンサーが生成するデータについていくつかのことに気付きました。まず、5 秒間隔でデータをキャプチャしています。湿度が低くなるたびにアラートを送信するとしたら、携帯電話にアラートが殺到することになります。これは良くありません。 1 時間に 1 回の頻度でアラートを受け取りたいと考えています。データを見て気づいた 2 番目のことは、センサーが完璧ではないということでした。植物の水分レベルが低下するという一般的な傾向は時間の経過とともに見られましたが、誤った最低または最高の測定値が定期的に表示されていました。
これらの 2 つの観察結果を組み合わせて、1 時間以内に 20 分間の低水分測定値を見れば、おそらくアラートを送信するのに十分であると判断しました. 5 秒ごとに 1 回の読み取りでは、1 時間に 720 回の読み取りが行われます。ここで少し計算すると、アラートを送信する前に、1 時間に 240 回の低い読み取り値を確認する必要があります。
ここで行うことは、プラントごとに 1 時間ごとに最大 1 つのイベントを含む新しいストリームを作成することです。次のクエリを書くことでこれを達成しました:
CREATE TABLE houseplant_low_readings WITH ( kafka_topic='houseplant-low-readings', format='AVRO', partitions=4 ) AS SELECT plant_id, given_name, common_name, scientific_name, CONCAT(given_name, ' the ', common_name, ' (', scientific_name, ') is looking pretty dry...') AS message, COUNT(*) AS low_reading_count FROM houseplant_readings_enriched WINDOW TUMBLING (SIZE 1 HOURS, GRACE PERIOD 30 MINUTES) WHERE moisture < moisture_low GROUP BY plant_id, given_name, common_name, scientific_name HAVING COUNT(*) > 240 EMIT FINAL;
まず最初に、 windowed Aggregationに気付くでしょう。このクエリは、重複しない 1 時間のウィンドウで動作するため、特定のウィンドウ内でプラント ID ごとにデータを集計できます。かなり簡単です。
具体的には、強化された測定値ストリームで、水分測定値がその植物の低水分しきい値未満の行をフィルタリングしてカウントしています。その数が少なくとも 240 であれば、アラートの基礎となる結果を出力します。
しかし、なぜこのクエリの結果がテーブルにあるのか疑問に思うかもしれません。ご存知のように、ストリームはデータ エンティティのほぼ完全な履歴を表しますが、テーブルは特定のキーの最新の値を反映します。このクエリは、実際には内部のステートフル ストリーミング アプリケーションであることを覚えておくことが重要です。メッセージが基盤となる強化されたデータ ストリームを通過するときに、その特定のメッセージがフィルター要件を満たしている場合、1 時間のウィンドウ内でそのプラント ID の低い読み取り値のカウントを増やし、状態内でそれを追跡します。ただし、このクエリで私が本当に気にかけているのは、集計の最終結果です。特定のキーについて、低い読み取り値の数が 240 を超えているかどうかです。テーブルが欲しい。
余談ですが、このステートメントの最後の行は「EMIT FINAL」です。このフレーズは、新しい行がストリーミング アプリケーションを通過するたびに潜在的に結果を出力するのではなく、結果が出力される前にウィンドウが閉じられるまで待機することを意味します。
このクエリの結果は、特定の 1 時間のウィンドウ内の特定のプラント ID に対して、希望どおり、最大で 1 つの警告メッセージを出力するということです。
分岐する
この時点で、植物の水分レベルが適切かつ一貫して低い場合のメッセージを含む ksqlDB によって入力された Kafka トピックがありました。しかし、実際にこのデータを Kafka から取得するにはどうすればよいでしょうか?私にとって最も便利なのは、この情報を電話で直接受け取ることです。
ここで車輪を再発明するつもりはなかったので、Telegram ボットを使用して Kafka トピックからメッセージを読み取り、電話にアラートを送信する方法について説明しているこのブログ投稿を利用しました。ブログで概説されているプロセスに従って、Telegram ボットを作成し、電話でそのボットとの会話を開始し、その会話の一意の ID とボットの API キーを書き留めました。その情報を使用して、Telegram チャット API を使用して、ボットから電話にメッセージを送信できます。
それはいいことですが、Kafka から Telegram ボットにアラートを送信するにはどうすればよいですか? Kafka トピックからのアラートを消費し、Telegram チャット API を介して各メッセージを手動で送信する特注のコンシューマーを作成することで、メッセージ送信を呼び出すことができます。しかし、それは余分な作業のように聞こえます。代わりに、フル マネージドの HTTP Sink Connector を使用してこれと同じことを行うことにしましたが、独自のコードを追加することはありませんでした。
数分以内に、Telegram ボットが動作する準備が整い、私とボットの間でプライベート チャットが開かれました。チャット ID を使用して、Confluent Cloud でフルマネージドの HTTP Sink Connector を使用して、自分の電話にメッセージを直接送信できるようになりました。
完全な構成は次のようになります。
{ "name": "HttpSinkConnector_Houseplants_Telegram_Bot", "config": { "topics": "houseplant-low-readings", "input.data.format": "AVRO", "connector.class": "HttpSink", "name": "HttpSinkConnector_Houseplants_Telegram_Bot", "kafka.auth.mode": "KAFKA_API_KEY", "http.api.url": "https://api.telegram.org/**********/sendMessage", "request.method": "POST", "headers": "Content-Type: application/json", "request.body.format": "string", "batch.max.size": "1", "batch.prefix": "{\"chat_id\":\"********\",", "batch.suffix": "}", "regex.patterns": ".*MESSAGE=(.*),LOW_READING_COUNT=(.*)}.*", "regex.replacements": "\"text\":\"$1\"", "regex.separator": "~", "tasks.max": "1" } }


コネクタを起動してから数日後、植物に水をやる必要があることを知らせる非常に役立つメッセージを受け取りました。成功!


新しい葉をひっくり返す
このプロジェクトの初期段階が完了してから約 1 年が経ちました。その間、私が監視しているすべての植物が幸せで健康であることを報告できてうれしいです!それらをチェックするために余分な時間を費やす必要がなくなり、ストリーミング データ パイプラインによって生成されたアラートだけに頼ることができます。それはどれほどクールですか?


このプロジェクトを構築するプロセスに興味を持った場合は、独自のストリーミング データ パイプラインを開始することをお勧めします。リアルタイム パイプラインを構築して自分の生活に組み込むことに挑戦したいベテランの Kafka ユーザーであろうと、Kafka をまったく初めて使用する人であろうと、これらの種類のプロジェクトがあなたに適していることをお伝えします。








