




















2020 में वापस, बहुत से लोगों ने महामारी के शौक को उठाया - वे चीजें जो वे खुद को पूरी ताकत से फेंक सकते थे, जबकि वे लॉकडाउन द्वारा प्रतिबंधित थे। मैंने हाउसप्लंट्स को चुना।
महामारी से पहले, मेरे पास पहले से ही मेरे घर में एक छोटी सी नर्सरी थी। ईमानदारी से, फिर भी, हर दिन हर पौधे की देखभाल करना बहुत काम का था। यह देखते हुए कि उनमें से किसे पानी पिलाने की जरूरत है, यह सुनिश्चित करते हुए कि उन सभी को सही मात्रा में धूप मिले, उनसे बात करें... #justHouseplantThings।
घर पर अधिक समय बिताने का मतलब था कि मैं अपने संयंत्रों में अधिक निवेश कर सकता था। और मैंने किया—मेरा समय, प्रयास और पैसा। मेरे घर में कुछ दर्जन हाउसप्लांट हैं; उन सभी के नाम, व्यक्तित्व हैं (कम से कम मुझे ऐसा लगता है), और कुछ की गुगली आँखें भी हैं। यह, निश्चित रूप से, जब मैं पूरे दिन घर पर था, ठीक था, लेकिन, जैसे-जैसे जीवन धीरे-धीरे सामान्य होने लगा, मैंने खुद को एक मुश्किल स्थिति में पाया: अब मेरे पास अपने पौधों पर नज़र रखने के लिए दुनिया में हर समय नहीं था। मुझे समाधान चाहिए था। मेरे पौधों की निगरानी करने के लिए उन्हें हर दिन मैन्युअल रूप से जांचने का एक बेहतर तरीका होना चाहिए था।


अपाचे काफ्का® दर्ज करें। ठीक है, वास्तव में, एक और शौक लेने की मेरी इच्छा दर्ज करें: हार्डवेयर प्रोजेक्ट।
मैं हमेशा रास्पबेरी पाई का उपयोग करके एक परियोजना बनाने का बहाना चाहता था, और मुझे पता था कि यह मेरा मौका था। मैं एक ऐसी प्रणाली का निर्माण करूंगा जो मेरे पौधों की निगरानी कर सके और मुझे केवल तभी सचेत कर सके जब उन्हें ध्यान देने की आवश्यकता थी और एक क्षण बाद नहीं। और मैं काफ्का को रीढ़ की तरह इस्तेमाल करूंगा।
यह वास्तव में एक बहुत ही उपयोगी परियोजना साबित हुई। इसने एक बहुत ही वास्तविक समस्या को हल किया जो मेरे पास थी और मुझे घर पर काफ्का का उपयोग करने की मेरी खुजली की इच्छा के साथ अपने हाउसप्लांट जुनून को संयोजित करने का मौका दिया। यह सब एक आसान और सुलभ हार्डवेयर प्रोजेक्ट में बड़े करीने से लपेटा गया था जिसे कोई भी अपने दम पर लागू कर सकता है।
यदि आप मेरे जैसे हैं और आपको हाउसप्लांट की समस्या है, जिसे केवल आपके घर को स्वचालित करके ही हल किया जा सकता है, या भले ही आप मेरी तरह बिल्कुल भी नहीं हैं, लेकिन फिर भी आप एक अच्छा प्रोजेक्ट चाहते हैं, तो यह ब्लॉग पोस्ट आपके लिए है .
चलो अपनी आस्तीनें चढ़ाएं और अपने हाथ गंदे करें!
बीज बोना
सबसे पहले, मैं यह पता लगाने के लिए बैठ गया कि मैं इस परियोजना से क्या हासिल करना चाहता हूं। सिस्टम के पहले चरण के लिए, मेरे पौधों की नमी के स्तर की निगरानी करने और उनके बारे में अलर्ट प्राप्त करने में सक्षम होना बहुत मददगार होगा - आखिरकार, मेरे पौधों की देखभाल करने का सबसे अधिक समय लेने वाला हिस्सा यह तय करना था कि किसकी देखभाल की जानी चाहिए। अगर यह सिस्टम निर्णय लेने की प्रक्रिया को संभाल सकता है, तो मैं बहुत समय बचा सकता हूँ!
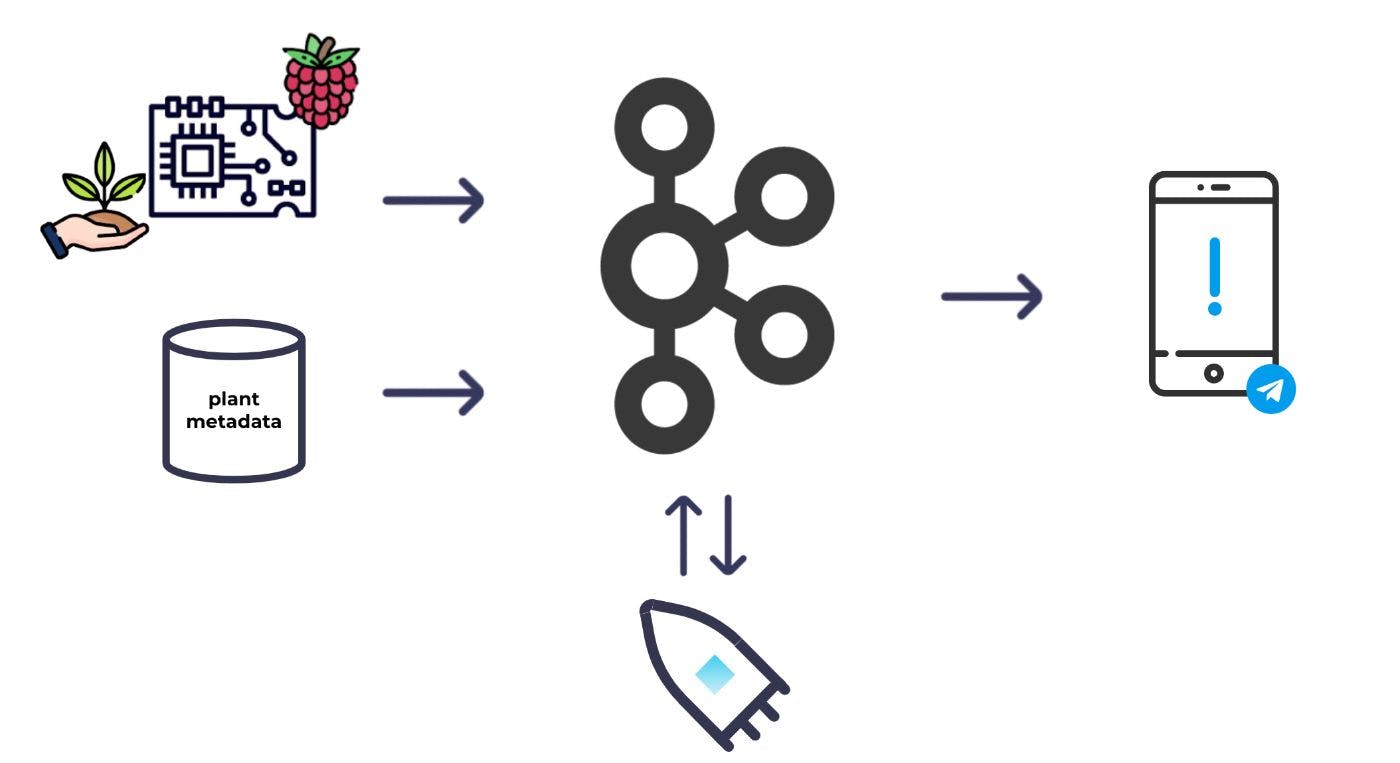
उच्च स्तर पर, यह वह मूल प्रणाली है जिसकी मैंने कल्पना की थी:


मैं मिट्टी में कुछ नमी सेंसर लगाऊंगा और इन्हें रास्पबेरी पाई तक लगा दूंगा; मैं तब नियमित रूप से नमी की रीडिंग ले सकता था और उन्हें काफ्का में डाल सकता था। नमी की रीडिंग के अलावा, मुझे यह तय करने के लिए प्रत्येक पौधे के लिए कुछ मेटाडेटा की भी आवश्यकता थी कि किन पौधों को पानी देने की आवश्यकता है। मैं मेटाडेटा को काफ्का में भी प्रस्तुत करूँगा। काफ्का में दोनों डेटासेट के साथ, मैं तब डेटासेट को एक दूसरे के साथ संयोजित और समृद्ध करने के लिए स्ट्रीम प्रोसेसिंग का उपयोग कर सकता था और गणना कर सकता था कि किन पौधों को पानी देने की आवश्यकता है। वहां से, मैं अलर्ट ट्रिगर कर सकता था।
स्थापित बुनियादी आवश्यकताओं के एक सेट के साथ, मैं हार्डवेयर और असेंबली चरण में प्रवेश करता हूं।
चीजों का डंठल लेना
कई स्वाभिमानी इंजीनियरों की तरह, मैंने ढेर सारी गूगलिंग के साथ हार्डवेयर चरण की शुरुआत की। मुझे पता था कि इस परियोजना को सफल बनाने के लिए सभी टुकड़े मौजूद थे, लेकिन, जैसा कि यह मेरा पहली बार भौतिक घटकों के साथ काम कर रहा था, मैं यह सुनिश्चित करना चाहता था कि मुझे ठीक-ठीक पता हो कि मैं अपने आप को क्या प्राप्त कर रहा हूं।
निगरानी प्रणाली का मुख्य लक्ष्य मुझे यह बताना था कि पौधों को कब पानी देना है, तो जाहिर है, मुझे किसी प्रकार के नमी संवेदक की आवश्यकता थी। मैंने सीखा है कि मिट्टी की नमी के सेंसर कई प्रकार के आकार और आकार में आते हैं, एनालॉग या डिजिटल घटकों के रूप में उपलब्ध होते हैं, और नमी को मापने के तरीके में भिन्न होते हैं। अंत में, मैं इन I2C कैपेसिटिव सेंसर पर बस गया। वे हार्डवेयर के साथ शुरुआत करने वाले किसी व्यक्ति के लिए एक बढ़िया विकल्प लग रहे थे: कैपेसिटिव सेंसर के रूप में, वे प्रतिरोधक-आधारित सेंसर की तुलना में अधिक समय तक चलेंगे, उन्हें एनालॉग-टू-डिजिटल रूपांतरण की आवश्यकता नहीं थी, और वे कमोबेश प्लग-एंड- थे खेलना। साथ ही, उन्होंने मुफ्त में तापमान माप की पेशकश की।
एक तरफ: जो लोग उत्सुक हैं, उनके लिए I2C का मतलब इंटर-इंटीग्रेटेड सर्किट है। इनमें से प्रत्येक सेंसर एक अद्वितीय पते पर संचार करता है; इसलिए प्रत्येक सेंसर से डेटा प्राप्त करने के लिए, मुझे अपने द्वारा उपयोग किए जाने वाले प्रत्येक सेंसर के लिए अद्वितीय पते को सेट करने और उसका ट्रैक रखने की आवश्यकता है - बाद में ध्यान में रखने के लिए कुछ।
सेंसर के बारे में फैसला करना मेरे फिजिकल सेटअप का सबसे बड़ा हिस्सा था। हार्डवेयर के रूप में जो कुछ किया जाना बाकी था, वह था रास्पबेरी पाई और कुछ उपकरणों को प्राप्त करना। तब मैं सिस्टम का निर्माण शुरू करने के लिए स्वतंत्र था।
मैंने निम्नलिखित घटकों का उपयोग किया:
- रास्पबेरी पाई 4 मॉडल बी
- आधा आकार का ब्रेडबोर्ड पीसीबी
- कैपेसिटिव मृदा नमी सेंसर
- जेएसटी पिच कनेक्टर किट
- 4 कतरा रिबन तार
- क्रिम्पर्स, वायर स्ट्रिपर्स, सोल्डर, सोल्डरिंग आयरन (ये सभी मुझे आसानी से अपने गैरेज में मिल गए)


ऊपर की मिट्टी से...
हालाँकि मैं चाहता था कि यह परियोजना आसान और शुरुआती-अनुकूल हो, मैं जितना संभव हो उतना वायरिंग और सोल्डरिंग करने के लिए खुद को चुनौती देना चाहता था। मेरे सामने आने वालों का सम्मान करने के लिए, मैं इस विधानसभा यात्रा पर कुछ तारों, एक क्रिम्पर और एक सपने के साथ निकल पड़ा। पहला कदम चार सेंसर को ब्रेडबोर्ड से जोड़ने के लिए पर्याप्त रिबन तार तैयार करना था और ब्रेडबोर्ड को मेरी रास्पबेरी पाई से जोड़ना था। सेटअप में घटकों के बीच रिक्ति की अनुमति देने के लिए, मैंने 24 ”लंबाई की तैयारी की। प्रत्येक तार को JST कनेक्टर (ब्रेडबोर्ड से सेंसर को जोड़ने वाले तारों के लिए) या एक महिला सॉकेट (स्वयं रास्पबेरी पाई से कनेक्ट करने के लिए) में छीनना, समेटना और प्लग करना पड़ता था। लेकिन, निश्चित रूप से, यदि आप समय, प्रयास और आँसू बचाने के लिए देख रहे हैं, तो मेरा सुझाव है कि आप अपने स्वयं के तारों को समेटें नहीं और इसके बजाय समय से पहले तैयार तारों को खरीद लें।
एक तरफ: मेरे पास जितने हाउसप्लंट्स हैं, उन्हें देखते हुए चार मेरे मॉनिटरिंग सेटअप में उपयोग करने के लिए मनमाने ढंग से कम संख्या में सेंसर लग सकते हैं। जैसा कि पहले कहा गया है, चूंकि ये सेंसर I2C डिवाइस हैं, कोई भी सूचना जो वे संचार करते हैं, एक अद्वितीय पते का उपयोग करके भेजी जाएगी। उस ने कहा, मेरे द्वारा खरीदे गए मिट्टी की नमी के सेंसर सभी एक ही डिफ़ॉल्ट पते के साथ भेजे जाते हैं, जो इस तरह के सेटअप के लिए समस्याग्रस्त है जहाँ आप एक ही डिवाइस के कई उपयोग करना चाहते हैं। इसके आसपास जाने के दो मुख्य तरीके हैं। पहला विकल्प डिवाइस पर ही निर्भर करता है। मेरे विशेष सेंसर के पीछे दो I2C एड्रेस जंपर्स थे, और इनमें से किसी भी संयोजन को टांका लगाने का मतलब था कि मैं I2C एड्रेस को 0x36 और 0x39 से बदल सकता हूं। कुल मिलाकर, मेरे पास चार अद्वितीय पते हो सकते हैं, इसलिए चार सेंसर मैं अंतिम सेटअप में उपयोग करता हूं। यदि उपकरणों में पतों को बदलने के लिए भौतिक साधनों की कमी है, तो दूसरा विकल्प सूचना को फिर से रूट करना और मल्टीप्लेक्स का उपयोग करके प्रॉक्सी पतों को सेट करना है। यह देखते हुए कि मैं हार्डवेयर में नया हूं, मुझे लगा कि यह इस विशेष परियोजना के दायरे से बाहर है।
सेंसर को रास्पबेरी पाई से जोड़ने के लिए तारों को तैयार करने के बाद, मैंने पुष्टि की कि एक सेंसर से रीडिंग एकत्र करने के लिए टेस्ट पायथन स्क्रिप्ट का उपयोग करके सब कुछ सही ढंग से सेट किया गया था। अतिरिक्त आश्वासन के लिए, मैंने शेष तीन सेंसरों का उसी तरह परीक्षण किया। और यह इस चरण के दौरान था कि मैंने पहली बार सीखा कि कैसे पार किए गए तार इलेक्ट्रॉनिक घटकों को प्रभावित करते हैं ... और इन मुद्दों को डिबग करना कितना मुश्किल है।
अंत में वायरिंग के काम करने के क्रम में, मैं सभी सेंसर को रास्पबेरी पाई से जोड़ सकता था। रास्पबेरी पाई पर सभी सेंसर को एक ही पिन (GND, 3V3, SDA और SCL) से कनेक्ट करने की आवश्यकता है। प्रत्येक सेंसर का एक अद्वितीय I2C पता होता है, हालाँकि, हालाँकि, वे सभी एक ही तार पर संचार कर रहे हैं, फिर भी मैं उनके पते का उपयोग करके विशिष्ट सेंसर से डेटा प्राप्त कर सकता हूँ। मुझे बस इतना करना था कि प्रत्येक सेंसर को ब्रेडबोर्ड से तार कर दिया जाए और फिर ब्रेडबोर्ड को रास्पबेरी पाई से जोड़ दिया जाए। इसे प्राप्त करने के लिए, मैंने कुछ बचे हुए तार का उपयोग किया और सोल्डर का उपयोग करके ब्रेडबोर्ड के स्तंभों को जोड़ा। मैंने तब JST कनेक्टर्स को सीधे ब्रेडबोर्ड पर टांका लगाया ताकि मैं सेंसर में आसानी से प्लग कर सकूं।
ब्रेडबोर्ड को रास्पबेरी पाई से जोड़ने के बाद, सेंसर को चार पौधों में डालने, और परीक्षण स्क्रिप्ट के माध्यम से पुष्टि करने के बाद कि मैं सभी सेंसर से डेटा पढ़ सकता हूं, मैं डेटा को काफ्का में बनाने पर काम शुरू कर सकता हूं।
रियल-थाइम डेटा
रास्पबेरी पाई सेटअप और उम्मीद के मुताबिक काम करने वाले सभी नमी सेंसर के साथ, कुछ डेटा स्ट्रीमिंग शुरू करने के लिए काफ्का को मिश्रण में लाने का समय था।
जैसा कि आप उम्मीद कर सकते हैं, काफ्का में कोई डेटा लिखने से पहले मुझे काफ्का क्लस्टर की आवश्यकता थी। इस परियोजना के सॉफ्टवेयर घटक को जितना संभव हो उतना हल्का और आसानी से स्थापित करना चाहते हैं, मैंने अपने काफ्का प्रदाता के रूप में कंफ्लुएंट क्लाउड का उपयोग करने का विकल्प चुना। ऐसा करने का मतलब था कि मुझे किसी बुनियादी ढांचे को स्थापित करने या प्रबंधित करने की आवश्यकता नहीं थी और मेरा काफ्का क्लस्टर इसे स्थापित करने के कुछ ही मिनटों में तैयार हो गया था।
यह भी ध्यान देने योग्य है कि मैंने इस परियोजना के लिए काफ्का का उपयोग करना क्यों चुना, विशेष रूप से यह देखते हुए कि एमक्यूटीटी कमोबेश सेंसर से आईओटी डेटा स्ट्रीमिंग के लिए वास्तविक मानक है। काफ्का और एमक्यूटीटी दोनों पब/सब-स्टाइल मैसेजिंग के लिए बनाए गए हैं, इसलिए वे इस संबंध में समान हैं। लेकिन अगर आप इस तरह की डेटा स्ट्रीमिंग परियोजना बनाने की योजना बना रहे हैं, तो MQTT कम पड़ जाएगा। स्ट्रीम प्रोसेसिंग, डेटा दृढ़ता और किसी भी डाउनस्ट्रीम इंटीग्रेशन को संभालने के लिए आपको काफ्का जैसी दूसरी तकनीक की जरूरत है। लब्बोलुआब यह है कि MQTT और काफ्का एक साथ वास्तव में अच्छी तरह से काम करते हैं । काफ्का के अलावा, मैं निश्चित रूप से अपने प्रोजेक्ट के IoT घटक के लिए MQTT का उपयोग कर सकता था। इसके बजाय, मैंने रास्पबेरी पाई पर सीधे पायथन निर्माता के साथ काम करने का फैसला किया। उस ने कहा, यदि आप किसी भी IoT- प्रेरित परियोजना के लिए MQTT और काफ्का का उपयोग करना चाहते हैं, तो निश्चिंत रहें कि आप अभी भी MQTT काफ्का स्रोत कनेक्टर का उपयोग करके अपने MQTT डेटा को काफ्का में प्राप्त कर सकते हैं।
डेटा के माध्यम से निराई
इससे पहले कि मैं कोई डेटा गति में लाऊं, मैंने यह तय करने के लिए एक कदम पीछे लिया कि मैं अपने काफ्का विषय पर संदेशों को कैसे संरचित करना चाहता हूं। विशेष रूप से इस तरह की हैक परियोजनाओं के लिए, दुनिया में बिना किसी चिंता के डेटा को काफ्का विषय में बंद करना शुरू करना आसान है - लेकिन यह जानना महत्वपूर्ण है कि आप अपने डेटा को विषयों में कैसे व्यवस्थित करेंगे, आप किस कुंजी का उपयोग करेंगे, और डेटा क्षेत्रों में प्रकार।
तो चलिए शुरू करते हैं विषयों से। वे कैसे दिखेंगे? सेंसर में नमी और तापमान को पकड़ने की क्षमता थी - क्या ये रीडिंग एक ही विषय या एकाधिक पर लिखी जानी चाहिए? चूँकि नमी और तापमान दोनों की रीडिंग एक ही समय में एक पौधे के सेंसर से ली जा रही थी, इसलिए मैंने उन्हें एक ही काफ्का संदेश में एक साथ संग्रहीत किया। साथ में, जानकारी के उन दो टुकड़ों में इस परियोजना के प्रयोजनों के लिए एक संयंत्र पढ़ना शामिल था। यह सब एक ही पठन विषय में जाएगा।
सेंसर डेटा के अलावा, मुझे हाउसप्लांट मेटाडेटा को स्टोर करने के लिए एक विषय की आवश्यकता थी जिसमें सेंसर निगरानी कर रहा है और इसका तापमान और नमी सीमाएं शामिल हैं। यह जानकारी डेटा प्रोसेसिंग चरण के दौरान यह निर्धारित करने के लिए उपयोग की जाएगी कि रीडिंग को अलर्ट ट्रिगर करना चाहिए या नहीं।
मैंने दो विषय बनाए: houseplants-readings और houseplants-metadata । मुझे कितने विभाजनों का उपयोग करना चाहिए? दोनों विषयों के लिए, मैंने कंफ्लुएंट क्लाउड में विभाजन की डिफ़ॉल्ट संख्या का उपयोग करने का निर्णय लिया, जो लेखन के समय छह है। क्या वह सही संख्या थी? अच्छा, हाँ और नहीं। इस मामले में, मैं जिस डेटा के साथ काम कर रहा हूं, उसके कम मात्रा के कारण, प्रति विषय छह विभाजन अधिक हो सकते हैं, लेकिन इस घटना में कि मैं इस परियोजना को बाद में और अधिक संयंत्रों में विस्तारित करता हूं, छह विभाजन होना अच्छा होगा .
विभाजन के अलावा, ध्यान देने के लिए एक और महत्वपूर्ण कॉन्फ़िगरेशन पैरामीटर लॉग कॉम्पैक्शन है जिसे मैंने हाउसप्लंट्स विषय पर सक्षम किया था। घटनाओं की `रीडिंग्स` स्ट्रीम के विपरीत, `मेटाडेटा` विषय संदर्भ डेटा—या मेटाडेटा रखता है। इसे एक संकुचित विषय में धारण करके आप सुनिश्चित करते हैं कि डेटा कभी भी पुराना नहीं होगा, और आपके पास हमेशा दी गई कुंजी के लिए अंतिम ज्ञात मूल्य तक पहुंच होगी (कुंजी, यदि आपको याद है, प्रत्येक हाउसप्लांट के लिए एक अद्वितीय पहचानकर्ता होने के नाते)।
उपरोक्त के आधार पर, मैंने रीडिंग और हाउसप्लांट मेटाडेटा (पठनीयता के लिए यहां संक्षिप्त) दोनों के लिए दो एवरो स्कीमा लिखे।
रीडिंग स्कीमा
{ "doc": "Houseplant reading taken from sensors.", "fields": [ {"name": "plant_id", "type": "int"}, {"name": "timestamp", "logicalType": "timestamp-millis", "type": "long"}, {"name": "moisture", "type": "float"}, {"name": "temperature", "type": "float"} ], "name": "reading", "namespace": "com.houseplants", "type": "record" }हाउसप्लांट मेटाडेटा स्कीमा
{ "doc": "Houseplant metadata.", "fields": [ {"name": "plant_id", "type": "int"}, {"name": "scientific_name", "type": "string"}, {"name": "common_name", "type": "string"}, {"name": "given_name", "type": "string"}, {"name": "temperature_threshold_low", "type": "float"}, {"name": "temperature_threshold_high", "type": "float"}, {"name": "moisture_threshold_low", "type": "float"}, {"name": "moisture_threshold_high", "type": "float"} ], "name": "houseplant", "namespace": "com.houseplants", "type": "record" }
यदि आपने पहले काफ्का का उपयोग किया है, तो आप जानते हैं कि विषय होना और यह जानना कि आपका संदेश मूल्य कैसा दिखता है, केवल पहला कदम है। यह जानना उतना ही महत्वपूर्ण है कि प्रत्येक संदेश की कुंजी क्या होगी। रीडिंग और मेटाडेटा दोनों के लिए, मैंने खुद से पूछा कि इनमें से प्रत्येक डेटासेट का एक उदाहरण क्या होगा, क्योंकि यह इकाई का उदाहरण है जिसे काफ्का में एक कुंजी का आधार बनाना चाहिए। चूँकि रीडिंग प्रति प्लांट ली जा रही है और मेटाडेटा प्रति प्लांट असाइन किया गया है, दोनों डेटासेट का एक इकाई उदाहरण एक व्यक्तिगत प्लांट था। मैंने तय किया कि दोनों विषयों की तार्किक कुंजी पौधे पर आधारित होगी। मैं प्रत्येक पौधे को एक संख्यात्मक आईडी प्रदान करूंगा और वह संख्या रीडिंग संदेशों और मेटाडेटा संदेशों दोनों की कुंजी होगी।
तो संतोष की थोड़ी सी आत्ममुग्धता के साथ जो यह जानने से आती है कि मैं इस बारे में सही तरीके से जा रहा था, मैं अपने सेंसर से डेटा को काफ्का विषयों में स्ट्रीम करने के लिए अपना ध्यान केंद्रित कर सकता था।
संदेशों की खेती
मैं अपने सेंसर से डेटा काफ्का को भेजना शुरू करना चाहता था। पहला कदम रास्पबेरी पाई पर confluent-kafka पायथन लाइब्रेरी स्थापित करना था। वहां से, मैंने अपने सेंसर से रीडिंग लेने और काफ्का में डेटा तैयार करने के लिए एक पायथन स्क्रिप्ट लिखी।
क्या आप विश्वास करेंगे अगर मैंने आपको बताया कि यह इतना आसान था? कोड की केवल कुछ पंक्तियों के साथ, मेरे सेंसर डेटा को डाउनस्ट्रीम एनालिटिक्स में उपयोग के लिए काफ्का विषय में लिखा और जारी रखा जा रहा था। मुझे अभी भी इसके बारे में सोचकर थोड़ा चक्कर आ रहा है।


काफ्का में सेंसर रीडिंग के साथ, मुझे अब किसी भी प्रकार के डाउनस्ट्रीम विश्लेषण के लिए हाउसप्लांट मेटाडेटा की आवश्यकता थी। विशिष्ट डेटा पाइपलाइनों में, इस प्रकार का डेटा एक रिलेशनल डेटाबेस या किसी अन्य डेटा स्टोर में रहता है और काफ्का कनेक्ट और इसके लिए उपलब्ध कई कनेक्टर्स का उपयोग करके अंतर्ग्रहित किया जाएगा।
अपने स्वयं के बाहरी डेटाबेस को स्पिन करने के बजाय, मैंने काफ्का को अपने मेटाडेटा के लिए लगातार भंडारण परत के रूप में उपयोग करने का निर्णय लिया। केवल कुछ मुट्ठी भर पौधों के लिए मेटाडेटा के साथ, मैंने मैन्युअल रूप से एक अन्य पायथन लिपि का उपयोग करके सीधे काफ्का को डेटा लिखा।
समस्या की जड़
मेरा डेटा काफ्का में है; अब वास्तव में मेरे हाथों को गंदा करने का समय आ गया है। लेकिन पहले, इस परियोजना के साथ मैं जो हासिल करना चाहता था, उस पर फिर से विचार करें। समग्र लक्ष्य एक अलर्ट भेजना है जब मेरे पौधों में नमी की रीडिंग कम होती है जो इंगित करती है कि उन्हें पानी पिलाने की आवश्यकता है। मैं मेटाडेटा के साथ रीडिंग डेटा को समृद्ध करने के लिए स्ट्रीम प्रोसेसिंग का उपयोग कर सकता हूं और फिर अपने अलर्ट चलाने के लिए डेटा की एक नई स्ट्रीम की गणना कर सकता हूं।
मैंने इस पाइपलाइन के डाटा प्रोसेसिंग चरण के लिए ksqlDB का उपयोग करने का विकल्प चुना ताकि मैं डेटा को न्यूनतम कोडिंग के साथ संसाधित कर सकूं। कंफ्लुएंट क्लाउड के संयोजन के साथ, ksqlDB को स्थापित करना और उपयोग करना आसान है - आप बस एक एप्लिकेशन संदर्भ का प्रावधान करते हैं और अपने डेटा को लोड करना और संसाधित करना शुरू करने के लिए कुछ सरल SQL लिखते हैं।
इनपुट डेटा को परिभाषित करना
इससे पहले कि मैं डेटा को संसाधित करना शुरू कर पाता, मुझे अपने डेटासेट को ksqlDB एप्लिकेशन के भीतर घोषित करने की आवश्यकता थी ताकि यह काम करने के लिए उपलब्ध हो सके। ऐसा करने के लिए, मुझे पहले यह तय करने की आवश्यकता थी कि दो प्रथम श्रेणी के ksqlDB ऑब्जेक्ट्स में से कौन सा मेरा डेटा - TABLE या STREAM के रूप में प्रदर्शित किया जाना चाहिए - और फिर मौजूदा काफ्का विषयों को इंगित करने के लिए एक CREATE स्टेटमेंट का उपयोग करें।
हाउसप्लांट रीडिंग डेटा को ksqlDB में एक STREAM के रूप में दर्शाया गया है - मूल रूप से एक काफ्का विषय (अपरिवर्तनीय घटनाओं की एक केवल-परिशिष्ट श्रृंखला) के समान है, लेकिन एक स्कीमा के साथ भी। बल्कि सुविधाजनक रूप से मैंने पहले ही स्कीमा को डिजाइन और घोषित कर दिया था, और ksqlDB इसे सीधे स्कीमा रजिस्ट्री से प्राप्त कर सकता है:
CREATE STREAM houseplant_readings ( id STRING KEY ) WITH ( kafka_topic='houseplant-readings', format='AVRO', partitions=4 );
काफ्का विषय पर बनाई गई धारा के साथ, हम इस तरह के एक साधारण कथन का उपयोग करके डेटा का पता लगाने के लिए क्वेरी और फ़िल्टर करने के लिए मानक SQL का उपयोग कर सकते हैं:
SELECT plant_id, moisture FROM HOUSEPLANT_READINGS EMIT CHANGES;


हाउसप्लांट मेटाडेटा को थोड़ा और अधिक विचार करने की आवश्यकता है। जबकि इसे काफ्का विषय के रूप में संग्रहीत किया जाता है (बिल्कुल रीडिंग डेटा की तरह), यह तार्किक रूप से एक अलग प्रकार का डेटा है - इसकी स्थिति। प्रत्येक पौधे के लिए, उसका एक नाम होता है, उसका एक स्थान होता है, इत्यादि। हम इसे एक संकुचित काफ्का विषय में संग्रहीत करते हैं और इसे ksqlDB में एक TABLE के रूप में प्रस्तुत करते हैं। एक तालिका - एक नियमित RDBMS की तरह - हमें दी गई कुंजी की वर्तमान स्थिति बताती है। ध्यान दें कि जबकि ksqlDB स्कीमा रजिस्ट्री से स्कीमा को चुनता है, हमें स्पष्ट रूप से यह घोषित करने की आवश्यकता है कि कौन सा फ़ील्ड तालिका की प्राथमिक कुंजी का प्रतिनिधित्व करता है।
CREATE TABLE houseplant_metadata ( id INTEGER PRIMARY KEY ) WITH ( kafka_topic='houseplant-metadata', format='AVRO', partitions=4 );डेटा समृद्ध करें
मेरे ksqlDB एप्लिकेशन के साथ पंजीकृत दोनों डेटासेट के साथ, अगला कदम houseplant_readings houseplants तालिका में निहित मेटाडेटा के साथ समृद्ध करना है। यह संबंधित संयंत्र के लिए पढ़ने और मेटाडेटा दोनों के साथ एक नई धारा (काफ्का विषय द्वारा रेखांकित) बनाता है:
संवर्धन क्वेरी कुछ इस तरह दिखेगी:
CREATE STREAM houseplant_readings_enriched WITH ( kafka_topic='houseplant-readings-enriched', format='AVRO', partitions=4 ) AS SELECT r.id AS plant_id, r.timestamp AS ts, r.moisture AS moisture, r.temperature AS temperature, h.scientific_name AS scientific_name, h.common_name AS common_name, h.given_name AS given_name, h.temperature_low AS temperature_low, h.temperature_high AS temperature_high, h.moisture_low AS moisture_low, h.moisture_high AS moisture_high FROM houseplant_readings AS r LEFT OUTER JOIN houseplants AS h ON houseplant_readings.id = houseplants.id PARTITION BY r.id EMIT CHANGES;
और उस क्वेरी का आउटपुट कुछ ऐसा होगा:


घटनाओं की एक धारा पर अलर्ट बनाना
इस लेख की शुरुआत पर विचार करते हुए, आपको याद होगा कि इस सब का पूरा बिंदु मुझे यह बताना था कि पौधे को कब पानी देने की आवश्यकता हो सकती है। हमारे पास नमी (और तापमान) रीडिंग की एक धारा है, और हमारे पास एक तालिका है जो हमें उस सीमा को बताती है जिस पर प्रत्येक पौधे की नमी का स्तर संकेत कर सकता है कि उसे पानी की आवश्यकता है। लेकिन मैं यह कैसे निर्धारित करूं कि कम नमी का अलर्ट कब भेजा जाए? और कितनी बार मैं उन्हें भेजूं?
उन सवालों के जवाब देने की कोशिश में, मैंने अपने सेंसर और उनके द्वारा पैदा किए जा रहे डेटा के बारे में कुछ बातें देखीं। सबसे पहले, मैं पाँच-सेकंड के अंतराल पर डेटा कैप्चर कर रहा हूँ। अगर मुझे हर कम नमी पढ़ने के लिए अलर्ट भेजना होता, तो मैं अपने फोन को अलर्ट से भर देता - यह अच्छा नहीं है। मैं हर घंटे में अधिकतम एक बार अलर्ट प्राप्त करना पसंद करूंगा। दूसरी बात जो मैंने अपने डेटा को देखने में महसूस की, वह यह थी कि सेंसर सही नहीं थे- मैं नियमित रूप से झूठी कम या झूठी उच्च रीडिंग देख रहा था, हालांकि समय के साथ सामान्य प्रवृत्ति यह थी कि पौधे की नमी का स्तर कम हो जाएगा।
उन दो अवलोकनों को मिलाकर, मैंने तय किया कि दी गई 1 घंटे की अवधि के भीतर, यदि मैं 20 मिनट की कम नमी वाली रीडिंग देखता हूं तो शायद अलर्ट भेजना काफी अच्छा होगा। हर 5 सेकंड में एक बार पढ़ने पर, यह एक घंटे में 720 रीडिंग है, और... यहाँ थोड़ा सा गणित कर रहे हैं, इसका मतलब है कि मुझे अलर्ट भेजने से पहले 1 घंटे की अवधि में 240 कम रीडिंग देखने की आवश्यकता होगी।
तो अब हम क्या करेंगे एक नई धारा का निर्माण करेंगे जिसमें प्रति पौधे प्रति 1 घंटे की अवधि में अधिकतम एक घटना होगी। मैंने निम्नलिखित प्रश्न लिखकर इसे हासिल किया:
CREATE TABLE houseplant_low_readings WITH ( kafka_topic='houseplant-low-readings', format='AVRO', partitions=4 ) AS SELECT plant_id, given_name, common_name, scientific_name, CONCAT(given_name, ' the ', common_name, ' (', scientific_name, ') is looking pretty dry...') AS message, COUNT(*) AS low_reading_count FROM houseplant_readings_enriched WINDOW TUMBLING (SIZE 1 HOURS, GRACE PERIOD 30 MINUTES) WHERE moisture < moisture_low GROUP BY plant_id, given_name, common_name, scientific_name HAVING COUNT(*) > 240 EMIT FINAL;
सबसे पहले चीज़ें, आप विंडो किए गए एकत्रीकरण को देखेंगे। यह क्वेरी नॉन-ओवरलैपिंग 1-घंटे की विंडो पर काम करती है, जिससे मुझे दी गई विंडो के भीतर प्रति प्लांट आईडी डेटा एकत्र करने की अनुमति मिलती है। बहुत सीधा।
मैं विशेष रूप से समृद्ध रीडिंग स्ट्रीम में पंक्तियों को फ़िल्टर और गिन रहा हूं जहां नमी पढ़ने का मूल्य उस संयंत्र के लिए कम नमी सीमा से कम है। यदि वह गिनती कम से कम 240 है, तो मैं एक परिणाम का उत्पादन करूँगा जो एक चेतावनी का आधार बनेगा।
लेकिन आप सोच रहे होंगे कि इस क्वेरी का रिजल्ट टेबल में क्यों है। ठीक है, जैसा कि हम जानते हैं, धाराएँ किसी डेटा इकाई के कमोबेश पूर्ण इतिहास का प्रतिनिधित्व करती हैं, जबकि तालिकाएँ किसी दी गई कुंजी के लिए सबसे अद्यतित मान दर्शाती हैं। यह याद रखना महत्वपूर्ण है कि यह क्वेरी वास्तव में कवर के तहत एक स्टेटफुल स्ट्रीमिंग एप्लिकेशन है। चूंकि संदेश अंतर्निहित समृद्ध डेटा स्ट्रीम के माध्यम से प्रवाहित होते हैं, यदि वह विशेष संदेश फ़िल्टर आवश्यकता को पूरा करता है, तो हम 1-घंटे की अवधि के भीतर उस प्लांट आईडी के लिए कम रीडिंग की संख्या बढ़ाते हैं और राज्य के भीतर इसका ट्रैक रखते हैं। हालांकि, इस प्रश्न में मुझे वास्तव में क्या परवाह है, एकत्रीकरण का अंतिम परिणाम है - चाहे किसी कुंजी के लिए कम रीडिंग की गिनती 240 से ऊपर हो। मुझे टेबल चाहिए।
एक तरफ: आप देखेंगे कि उस कथन की अंतिम पंक्ति `EMIT FINAL` है। इस वाक्यांश का अर्थ है कि, स्ट्रीमिंग एप्लिकेशन के माध्यम से हर बार एक नई पंक्ति प्रवाहित होने पर परिणाम को संभावित रूप से आउटपुट करने के बजाय, मैं तब तक प्रतीक्षा करूँगा जब तक परिणाम उत्सर्जित होने से पहले विंडो बंद नहीं हो जाती।
इस क्वेरी का नतीजा यह है कि, एक विशिष्ट एक घंटे की विंडो में दिए गए प्लांट आईडी के लिए, मैं जितना चाहता था, उतना ही एक चेतावनी संदेश आउटपुट करूंगा।
विस्तार करना
इस बिंदु पर, मेरे पास ksqlDB द्वारा पॉप्युलेट किया गया एक काफ्का विषय था जिसमें एक संदेश था जब एक पौधे में उचित और लगातार कम नमी का स्तर होता है। लेकिन मैं वास्तव में इस डेटा को काफ्का से कैसे प्राप्त करूं? मेरे लिए सबसे सुविधाजनक बात यह होगी कि मैं यह जानकारी सीधे अपने फोन पर प्राप्त कर लूं।
मैं यहां पहिए को फिर से शुरू करने वाला नहीं था, इसलिए मैंने इस ब्लॉग पोस्ट का लाभ उठाया, जिसमें काफ्का विषय से संदेशों को पढ़ने और फोन पर अलर्ट भेजने के लिए टेलीग्राम बॉट का उपयोग करने का वर्णन किया गया है। ब्लॉग द्वारा उल्लिखित प्रक्रिया का पालन करते हुए, मैंने एक टेलीग्राम बॉट बनाया और अपने बॉट के लिए एपीआई कुंजी के साथ उस बातचीत की विशिष्ट आईडी को ध्यान में रखते हुए अपने फोन पर उस बॉट के साथ बातचीत शुरू की। उस जानकारी के साथ, मैं अपने बॉट से अपने फ़ोन पर संदेश भेजने के लिए टेलीग्राम चैट एपीआई का उपयोग कर सकता था।
यह ठीक है और अच्छा है, लेकिन मैं काफ्का से अपने टेलीग्राम बॉट में अपने अलर्ट कैसे प्राप्त करूं? मैं एक बेस्पोक उपभोक्ता लिखकर संदेश भेजने का आह्वान कर सकता हूं जो काफ्का विषय से अलर्ट का उपभोग करेगा और प्रत्येक संदेश को टेलीग्राम चैट एपीआई के माध्यम से मैन्युअल रूप से भेजेगा। लेकिन यह अतिरिक्त काम जैसा लगता है। इसके बजाय, मैंने इसी काम को करने के लिए पूरी तरह से प्रबंधित HTTP सिंक कनेक्टर का उपयोग करने का फैसला किया, लेकिन अपना खुद का कोई अतिरिक्त कोड लिखे बिना।
कुछ ही मिनटों में, मेरा टेलीग्राम बॉट कार्रवाई के लिए तैयार था, और मेरे और बॉट के बीच एक निजी चैट खुली थी। चैट आईडी का उपयोग करके, अब मैं सीधे अपने फोन पर संदेश भेजने के लिए कंफ्लुएंट क्लाउड पर पूरी तरह से प्रबंधित HTTP सिंक कनेक्टर का उपयोग कर सकता हूं।
पूरा कॉन्फ़िगरेशन इस तरह दिखता था:
{ "name": "HttpSinkConnector_Houseplants_Telegram_Bot", "config": { "topics": "houseplant-low-readings", "input.data.format": "AVRO", "connector.class": "HttpSink", "name": "HttpSinkConnector_Houseplants_Telegram_Bot", "kafka.auth.mode": "KAFKA_API_KEY", "http.api.url": "https://api.telegram.org/**********/sendMessage", "request.method": "POST", "headers": "Content-Type: application/json", "request.body.format": "string", "batch.max.size": "1", "batch.prefix": "{\"chat_id\":\"********\",", "batch.suffix": "}", "regex.patterns": ".*MESSAGE=(.*),LOW_READING_COUNT=(.*)}.*", "regex.replacements": "\"text\":\"$1\"", "regex.separator": "~", "tasks.max": "1" } }


कनेक्टर लॉन्च करने के कुछ दिनों बाद, मुझे एक बहुत ही उपयोगी संदेश प्राप्त हुआ, जिसमें मुझे बताया गया कि मेरे पौधे को पानी देने की आवश्यकता है। सफलता!


एक नया पत्ता पलटना
मुझे इस परियोजना के शुरुआती चरण को पूरा किए लगभग एक साल हो चुका है। उस समय में, मुझे यह बताते हुए खुशी हो रही है कि जिन पौधों की मैं निगरानी कर रहा हूं वे सभी खुश और स्वस्थ हैं! मुझे अब उन पर जाँच करने में कोई अतिरिक्त समय नहीं लगाना है, और मैं अपने स्ट्रीमिंग डेटा पाइपलाइन द्वारा उत्पन्न अलर्ट पर विशेष रूप से भरोसा कर सकता हूँ। वह कितना शांत है?


यदि इस परियोजना के निर्माण की प्रक्रिया में आपको दिलचस्पी है, तो मैं आपको प्रोत्साहित करता हूं कि आप अपनी स्वयं की स्ट्रीमिंग डेटा पाइपलाइन शुरू करें। चाहे आप एक अनुभवी काफ्का उपयोगकर्ता हों, जो अपने जीवन में रीयल-टाइम पाइपलाइनों को बनाने और शामिल करने के लिए खुद को चुनौती देना चाहते हैं, या कोई ऐसा व्यक्ति जो काफ्का के लिए पूरी तरह से नया है, मैं यहां आपको बता रहा हूं कि इस प्रकार की परियोजनाएं आपके लिए हैं।








