





















2020'de pek çok insan pandemik hobiler edindi; bunlar, tecrit nedeniyle kısıtlanırken kendilerini tam güçle hayata geçirebilecekleri şeylerdi. Ben ev bitkilerini seçtim.
Pandemiden önce evimde zaten küçük bir çocuk odası vardı. Dürüst olmak gerekirse o zaman bile her gün her bitkiyle ilgilenmek çok iş gerektiriyordu. Hangisinin sulanması gerektiğini görmek, hepsinin doğru miktarda güneş ışığı aldığından emin olmak, onlarla konuşmak… #justHouseplantThings.
Evde daha fazla vakit geçirmek bitkilerime daha fazla yatırım yapabileceğim anlamına geliyordu. Ve ben de bunu yaptım; zamanım, çabam ve param. Evimde birkaç düzine ev bitkisi var; hepsinin isimleri, kişilikleri var (en azından ben öyle düşünüyorum) ve hatta bazılarının pörtlek gözleri bile var. Bütün gün evdeyken bu elbette iyiydi, ama hayat yavaş yavaş normale döndükçe kendimi zor bir durumda buldum: Artık bitkilerimi takip edecek kadar zamanım yoktu. Bir çözüme ihtiyacım vardı. Bitkilerimi izlemenin, onları her gün manuel olarak kontrol etmekten daha iyi bir yolu olmalıydı.


Apache Kafka®'ya girin. Gerçekten başka bir hobi edinme isteğim devreye giriyor: donanım projeleri.
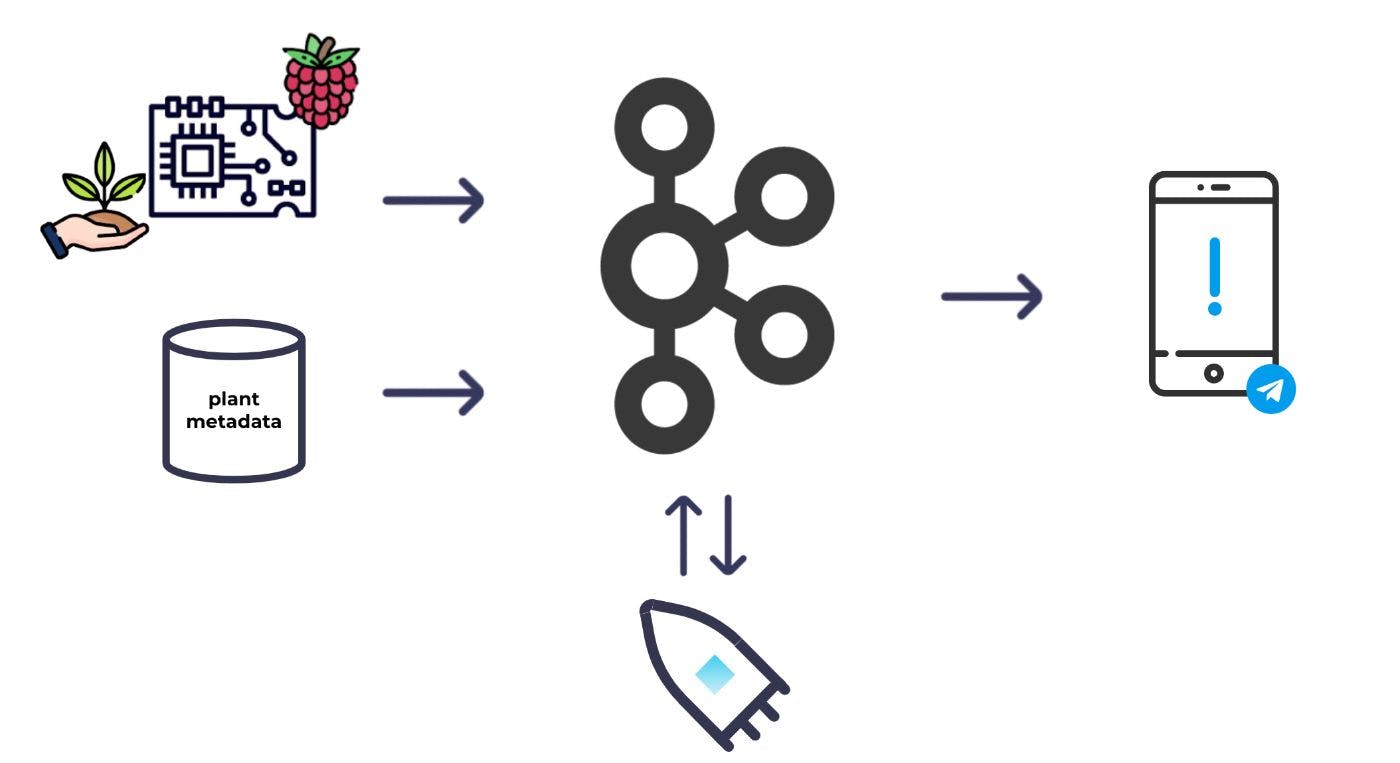
Raspberry Pi kullanarak bir proje geliştirmek için her zaman bir bahane istedim ve bunun benim şansım olduğunu biliyordum. Bitkilerimi izleyebilecek ve bir an sonra değil, yalnızca bakıma ihtiyaç duyduklarında beni uyarabilecek bir sistem kurardım. Ve Kafka'yı omurga olarak kullanırdım.
Bu aslında çok faydalı bir projeye dönüştü. Bu, yaşadığım çok gerçek bir sorunu çözdü ve bana, ev bitkileri takıntımı, sonunda Kafka'yı evde kullanma konusundaki kaşıntılı arzumla birleştirme şansı verdi. Tüm bunlar, herkesin kendi başına uygulayabileceği, kolay ve erişilebilir bir donanım projesinde düzgün bir şekilde bir araya getirildi.
Eğer siz de benim gibiyseniz ve yalnızca evinizi otomatik hale getirerek çözebileceğiniz bir ev bitkisi probleminiz varsa veya benim gibi olmasanız bile yine de içine dalacağınız harika bir proje istiyorsanız, bu blog yazısı tam size göre .
Hadi kollarımızı sıvayalım ve ellerimizi kirletelim!
Tohumların ekimi
İlk önce bu projeden neyi başarmak istediğimi anlamak için oturdum. Sistemin ilk aşamasında bitkilerimin nem seviyelerini takip edebilmek ve onlar hakkında uyarılar alabilmek çok faydalı olacaktı; sonuçta bitkilerimin bakımının en çok zaman alan kısmı hangisine bakılması gerektiğine karar vermekti. Eğer bu sistem bu karar verme sürecinin üstesinden gelebilseydi, çok zaman kazanırdım!
Yüksek düzeyde, hayal ettiğim temel sistem şu:


Toprağa bazı nem sensörleri yerleştirir ve bunları Raspberry Pi'ye bağlardım; Daha sonra düzenli olarak nem ölçümleri alıp bunları Kafka'ya atabilirim. Hangi bitkilerin sulanması gerektiğine karar vermek için nem ölçümlerine ek olarak her bitki için bazı meta verilere de ihtiyacım vardı. Meta verileri de Kafka'ya üretirdim. Kafka'daki her iki veri kümesiyle veri kümelerini birbiriyle birleştirip zenginleştirmek ve hangi bitkilerin sulanması gerektiğini hesaplamak için akış işlemeyi kullanabilirim. Oradan bir uyarıyı tetikleyebilirim.
Bir dizi temel gereksinimi belirledikten sonra donanım ve montaj aşamasına geçtim.
Bir şeylerin sapını almak
Kendine saygısı olan birçok mühendis gibi ben de donanım aşamasına tonlarca Google'da arama yaparak başladım. Bu projenin başarılı olmasını sağlayacak tüm parçaların mevcut olduğunu biliyordum, ancak bu benim fiziksel bileşenlerle ilk çalışmam olduğundan, kendimi tam olarak neye bulaştırdığımı bildiğimden emin olmak istedim.
İzleme sisteminin asıl amacı bana bitkilerin ne zaman sulanması gerektiğini söylemekti, dolayısıyla bir tür nem sensörüne ihtiyacım olduğu açıktı. Toprak nem sensörlerinin çeşitli şekil ve boyutlarda bulunduğunu, analog veya dijital bileşenler olarak mevcut olduğunu ve nemi ölçme biçimlerinin farklılık gösterdiğini öğrendim. Sonunda bu I2C kapasitif sensörlere karar verdim. Donanıma yeni başlayan biri için harika bir seçenek gibi görünüyorlardı: Kapasitif sensörler olarak dirençli tabanlı olanlardan daha uzun ömürlüydüler, analogdan dijitale dönüşüm gerektirmiyorlardı ve hemen hemen tak-çalıştır özelliğindeydiler. oynamak. Üstelik ücretsiz olarak ateş ölçümleri sunuyorlardı.
Bir kenar: Merak edenler için I2C, Inter-Entegre Devre anlamına geliyor. Bu sensörlerin her biri benzersiz bir adres üzerinden iletişim kurar; bu nedenle, her sensörden veri alabilmek için, kullandığım her sensörün benzersiz adresini ayarlayıp takip etmem gerekiyor; bu, daha sonra aklımda tutmam gereken bir şey.
Sensörlere karar vermek fiziksel kurulumumun en büyük parçasıydı. Donanım konusunda yapılması gereken tek şey Raspberry Pi'yi ve birkaç parça ekipmanı ele geçirmekti. Daha sonra sistemi kurmaya başlamakta özgürdüm.
Aşağıdaki bileşenleri kullandım:
- Ahududu Pi 4 Model B
- Yarım boyutlu Breadboard PCB
- Kapasitif Toprak Nemi Sensörleri
- JST Hatve Konnektör Kiti
- 4 telli şerit tel
- Kıvırıcılar, tel sıyırıcılar, lehim, havya (hepsi garajımda rahatlıkla buldum)


Topraktan yukarıya…
Bu projenin kolay ve yeni başlayanlar için uygun olmasını istesem de, mümkün olduğunca fazla kablolama ve lehimleme yapmak için kendimi zorlamak da istedim. Benden önce gelenleri onurlandırmak için bu montaj yolculuğuna bir takım teller, bir kıvırıcı ve bir hayalle çıktım. İlk adım, dört sensörü devre tahtasına bağlamak ve ayrıca devre tahtasını Raspberry Pi'me bağlamak için yeterli şerit tel hazırlamaktı. Kurulumdaki bileşenler arasında boşluk bırakmak için 24 inçlik uzunluklar hazırladım. Her bir kablonun soyulması, kıvrılması ve bir JST konektörüne (sensörleri devre tahtasına bağlayan teller için) veya dişi bir sokete (Raspberry Pi'nin kendisine bağlanmak için) takılması gerekiyordu. Ancak elbette zamandan, emekten ve gözyaşından tasarruf etmek istiyorsanız, kendi kablolarınızı kıvırmamanızı ve önceden hazırlanmış kabloları satın almanızı öneririm.
Bir kenara: Sahip olduğum ev bitkilerinin sayısı göz önüne alındığında, izleme kurulumumda kullanılacak sensörlerin sayısı keyfi olarak düşük görünebilir. Daha önce de belirtildiği gibi bu sensörler I2C cihazları olduğundan, ilettikleri her türlü bilgi benzersiz bir adres kullanılarak gönderilecektir. Bununla birlikte, satın aldığım toprak nemi sensörlerinin tümü aynı varsayılan adresle gönderiliyor; bu, aynı cihazın birden fazlasını kullanmak istediğiniz bunun gibi kurulumlar için sorunlu. Bunu aşmanın iki ana yolu var. İlk seçenek cihazın kendisine bağlıdır. Benim özel sensörümün arkasında iki adet I2C adres atlama kablosu vardı ve bunların herhangi bir kombinasyonunu lehimlemek, I2C adresini 0x36 ile 0x39 arasında değiştirebileceğim anlamına geliyordu. Toplamda dört benzersiz adresim olabilir, dolayısıyla son kurulumda kullandığım dört sensör olabilir. Cihazların adresleri değiştirmek için fiziksel bir yolu yoksa ikinci seçenek, bilgileri yeniden yönlendirmek ve bir multipleks kullanarak proxy adresleri ayarlamaktır. Donanım konusunda yeni olduğum göz önüne alındığında, bunun bu özel projenin kapsamı dışında olduğunu hissettim.
Sensörleri Raspberry Pi'ye bağlamak için kabloları hazırladıktan sonra, tek bir sensörden okumaları toplamak için bir test Python betiği kullanarak her şeyin doğru şekilde kurulduğunu doğruladım. Daha fazla güvence sağlamak için geri kalan üç sensörü de aynı şekilde test ettim. Çapraz kabloların elektronik bileşenleri nasıl etkilediğini ve bu sorunların hata ayıklamasının ne kadar zor olduğunu ilk elden bu aşamada öğrendim.
Kablolama nihayet çalışır durumda olduğundan, tüm sensörleri Raspberry Pi'ye bağlayabildim. Tüm sensörlerin Raspberry Pi'deki aynı pinlere (GND, 3V3, SDA ve SCL) bağlanması gerekiyordu. Her sensörün benzersiz bir I2C adresi vardır, dolayısıyla hepsi aynı kablolar üzerinden iletişim kurmasına rağmen yine de belirli sensörlerin adreslerini kullanarak veri alabiliyorum. Tek yapmam gereken, her sensörü devre tahtasına bağlamak ve ardından devre tahtasını Raspberry Pi'ye bağlamaktı. Bunu başarmak için, bir miktar kalan tel kullandım ve devre tahtasının sütunlarını lehim kullanarak bağladım. Daha sonra sensörleri kolayca takabilmek için JST konektörlerini doğrudan devre tahtasına lehimledim.
Breadboard'u Raspberry Pi'ye bağladıktan, sensörleri dört tesise yerleştirdikten ve test komut dosyası aracılığıyla tüm sensörlerden verileri okuyabildiğimi doğruladıktan sonra, verileri Kafka'ya üretmeye başlayabilirim.
Gerçek kekik verileri
Raspberry Pi kurulumu ve tüm nem sensörleri beklendiği gibi çalıştığından, bazı verileri aktarmaya başlamak için Kafka'yı karışıma dahil etme zamanı gelmişti.
Tahmin edebileceğiniz gibi Kafka'ya herhangi bir veri yazabilmem için önce bir Kafka kümesine ihtiyacım vardı. Bu projenin yazılım bileşenini olabildiğince hafif ve kurulumu kolay hale getirmek istediğim için Kafka sağlayıcım olarak Confluent Cloud'u kullanmayı tercih ettim. Bunu yapmak, herhangi bir altyapı kurmama veya yönetmeme gerek kalmaması ve Kafka kümemin, kurulumdan birkaç dakika sonra hazır olması anlamına geliyordu.
Bu proje için neden Kafka'yı kullanmayı seçtiğimi de belirtmekte fayda var, özellikle de MQTT'nin sensörlerden IoT verilerinin akışı için az çok fiili standart olduğu göz önüne alındığında. Hem Kafka hem de MQTT, pub/alt tarzı mesajlaşma için tasarlandı, dolayısıyla bu açıdan benzerler. Ancak bunun gibi bir veri akışı projesi oluşturmayı planlıyorsanız MQTT yetersiz kalacaktır. Akış işlemeyi, veri kalıcılığını ve aşağı akış entegrasyonlarını yönetmek için Kafka gibi başka bir teknolojiye ihtiyacınız var. Sonuç olarak MQTT ve Kafka birlikte gerçekten iyi çalışıyorlar . Projemin IoT bileşeni için Kafka'nın yanı sıra kesinlikle MQTT'yi de kullanabilirdim. Bunun yerine Raspberry Pi üzerinde doğrudan Python üreticisiyle çalışmaya karar verdim. Bununla birlikte, IoT'den ilham alan herhangi bir proje için MQTT ve Kafka'yı kullanmak istiyorsanız MQTT Kafka Kaynak Bağlayıcısını kullanarak MQTT verilerinizi Kafka'ya aktarabileceğinizden emin olabilirsiniz.
Verileri ayıklamak
Herhangi bir veriyi harekete geçirmeden önce, Kafka konumla ilgili mesajları nasıl yapılandırmak istediğime karar vermek için bir adım geri gittim. Özellikle bunun gibi hack projeleri için, hiçbir endişe duymadan bir Kafka konusuna veri göndermeye başlamak kolaydır; ancak verilerinizi konular arasında nasıl yapılandıracağınızı, hangi anahtarı kullanacağınızı ve veriler arasında nasıl yapacağınızı bilmek önemlidir. alanlardaki türler.
O halde konulara başlayalım. Bunlar nasıl görünecek? Sensörler nemi ve sıcaklığı yakalama yeteneğine sahipti; bu okumalar tek bir konuya mı yoksa birden fazla konuya mı yazılmalıydı? Bitkinin sensöründen hem nem hem de sıcaklık değerleri aynı anda alındığı için bunları aynı Kafka mesajında bir arada sakladım. Bu iki bilgi birlikte bu projenin amaçları doğrultusunda bir bitki okumasını oluşturdu. Hepsi aynı okuma konusuna girecekti.
Sensör verilerine ek olarak, sensörün izlediği bitki türü ve sıcaklık ve nem sınırlarını içeren ev bitkisi meta verilerini depolamak için bir konuya ihtiyacım vardı. Bu bilgi, veri işleme aşamasında bir okumanın ne zaman bir uyarıyı tetiklemesi gerektiğini belirlemek için kullanılacaktır.
İki konu oluşturdum: houseplants-readings ve houseplants-metadata . Kaç bölüm kullanmalıyım? Her iki konu için de, Confluent Cloud'da, bu yazının yazıldığı sırada altı olan varsayılan bölüm sayısını kullanmaya karar verdim. Bu doğru numara mıydı? Evet ve hayır. Bu durumda, uğraştığım veri hacminin düşük olması nedeniyle konu başına altı bölüm fazla olabilir, ancak daha sonra bu projeyi daha fazla tesise genişletmem durumunda altı bölüme sahip olmak iyi olacak .
Bölümlerin yanı sıra, dikkat edilmesi gereken bir diğer önemli yapılandırma parametresi de ev bitkileri konusunda etkinleştirdiğim günlük sıkıştırmadır. Olayların "okumalar" akışının aksine, "meta veriler" konusu referans verilerini veya meta verileri içerir. Sıkıştırılmış bir konu içinde tutarak, verilerin asla eskimemesini ve belirli bir anahtar için her zaman bilinen son değere erişebilmenizi sağlarsınız (hatırlıyorsanız anahtar, her ev bitkisi için benzersiz bir tanımlayıcıdır).
Yukarıdakilere dayanarak, hem okumalar hem de ev bitkisi meta verileri için iki Avro şeması yazdım (okunabilirlik için burada kısaltılmıştır).
Okuma şeması
{ "doc": "Houseplant reading taken from sensors.", "fields": [ {"name": "plant_id", "type": "int"}, {"name": "timestamp", "logicalType": "timestamp-millis", "type": "long"}, {"name": "moisture", "type": "float"}, {"name": "temperature", "type": "float"} ], "name": "reading", "namespace": "com.houseplants", "type": "record" }Houseplant meta veri şeması
{ "doc": "Houseplant metadata.", "fields": [ {"name": "plant_id", "type": "int"}, {"name": "scientific_name", "type": "string"}, {"name": "common_name", "type": "string"}, {"name": "given_name", "type": "string"}, {"name": "temperature_threshold_low", "type": "float"}, {"name": "temperature_threshold_high", "type": "float"}, {"name": "moisture_threshold_low", "type": "float"}, {"name": "moisture_threshold_high", "type": "float"} ], "name": "houseplant", "namespace": "com.houseplants", "type": "record" }
Daha önce Kafka'yı kullandıysanız konu sahibi olmanın ve mesaj değerlerinizin neye benzediğini bilmenin sadece ilk adım olduğunu biliyorsunuzdur. Her mesaj için anahtarın ne olacağını bilmek de aynı derecede önemlidir. Hem okumalar hem de meta veriler için kendime bu veri kümelerinin her birinin bir örneğinin ne olacağını sordum, çünkü Kafka'da bir anahtarın temelini oluşturması gereken varlık örneğidir. Okumalar tesis başına alındığından ve meta veriler tesis başına atandığından, her iki veri kümesinin varlık örneği ayrı bir tesisti. Her iki konunun mantıksal anahtarının bitkiye dayanmasına karar verdim. Her tesise sayısal bir kimlik atardım ve bu numaranın hem okuma mesajları hem de meta veri mesajları için anahtar olmasını sağlardım.
Bu konuda doğru yolda gittiğimi bilmenin getirdiği biraz kendini beğenmiş tatmin duygusuyla, dikkatimi sensörlerimden gelen verileri Kafka konularına aktarmaya çevirebildim.
Mesajları geliştirmek
Verileri sensörlerimden Kafka'ya göndermeye başlamak istedim. Birinci adım confluent-kafka Python kütüphanesini Raspberry Pi'ye kurmaktı. Oradan, sensörlerimden gelen okumaları yakalamak ve verileri Kafka'da üretmek için bir Python betiği yazdım.
Sana bu kadar kolay olduğunu söylesem inanır mısın? Yalnızca birkaç satır kodla sensör verilerim, aşağı yönlü analizlerde kullanılmak üzere bir Kafka konusuna yazılıyor ve burada kalıcı hale getiriliyordu. Hala bunu düşündükçe biraz başım dönüyor.


Kafka'daki sensör okumaları sayesinde artık herhangi bir alt analiz gerçekleştirmek için ev bitkisi meta verilerine ihtiyacım vardı. Tipik veri hatlarında, bu tür veriler ilişkisel bir veritabanında veya başka bir veri deposunda bulunur ve Kafka Connect ve bunun için mevcut birçok bağlayıcı kullanılarak alınır.
Kendime ait harici bir veritabanı oluşturmak yerine meta verilerim için kalıcı depolama katmanı olarak Kafka'yı kullanmaya karar verdim. Yalnızca bir avuç bitkiye ait meta verilerle, verileri başka bir Python betiği kullanarak doğrudan Kafka'ya manuel olarak yazdım.
Sorunun kökü
Verilerim Kafka'da; şimdi gerçekten ellerimi kirletmenin zamanı geldi. Ama önce bu projeyle neyi başarmak istediğime tekrar bakalım. Genel amaç, bitkilerimin sulanması gerektiğini belirten düşük nem değerlerine sahip olduğunda bir uyarı göndermektir. Okuma verilerini meta verilerle zenginleştirmek için akış işlemeyi kullanabilir ve ardından uyarılarımı yönlendirmek için yeni bir veri akışı hesaplayabilirim.
Verileri minimum kodlamayla işleyebilmek için bu hattın veri işleme aşamasında ksqlDB kullanmayı tercih ettim. Confluent Cloud ile birlikte ksqlDB'nin kurulumu ve kullanımı kolaydır; verilerinizi yüklemeye ve işlemeye başlamak için bir uygulama bağlamı sağlamanız ve basit bir SQL yazmanız yeterlidir.
Giriş verilerini tanımlama
Verileri işlemeye başlamadan önce, çalışılabilmesi için veri kümelerimi ksqlDB uygulaması içinde bildirmem gerekiyordu. Bunu yapmak için öncelikle verilerimin iki birinci sınıf ksqlDB nesnesinden hangisinin ( TABLE veya STREAM temsil edilmesi gerektiğine karar vermem ve ardından mevcut Kafka konularına işaret etmek için bir CREATE ifadesi kullanmam gerekiyordu.
Ev bitkisi okuma verileri ksqlDB'de bir STREAM olarak temsil edilir; temel olarak Kafka konusuyla tamamen aynıdır (yalnızca eklenen değişmez olaylar dizisi) ama aynı zamanda bir şema ile. Oldukça uygun bir şekilde şemayı daha önce tasarlayıp bildirmiştim ve ksqlDB onu doğrudan Şema Kayıt Defterinden alabilir:
CREATE STREAM houseplant_readings ( id STRING KEY ) WITH ( kafka_topic='houseplant-readings', format='AVRO', partitions=4 );
Kafka konusu üzerinden oluşturulan akışla, aşağıdaki gibi basit bir ifade kullanarak verileri keşfetmek için standart SQL'i sorgulamak ve filtrelemek için kullanabiliriz:
SELECT plant_id, moisture FROM HOUSEPLANT_READINGS EMIT CHANGES;


Ev bitkisi meta verilerinin biraz daha dikkate alınması gerekiyor. Kafka konusu olarak depolanırken (tıpkı okuma verileri gibi), mantıksal olarak farklı bir veri türüdür; durumu. Her bitkinin bir adı, bir konumu vb. vardır. Bunu sıkıştırılmış bir Kafka konusunun içinde saklıyoruz ve ksqlDB'de bir TABLE olarak temsil ediyoruz. Bir tablo, tıpkı normal bir RDBMS'de olduğu gibi, bize belirli bir anahtarın mevcut durumunu anlatır. KsqlDB burada şemanın kendisini Şema Kaydı'ndan alırken, hangi alanın tablonun birincil anahtarını temsil ettiğini açıkça belirtmemiz gerektiğini unutmayın.
CREATE TABLE houseplant_metadata ( id INTEGER PRIMARY KEY ) WITH ( kafka_topic='houseplant-metadata', format='AVRO', partitions=4 );Verileri zenginleştirin
Her iki veri seti de ksqlDB uygulamamda kayıtlıyken, bir sonraki adım houseplant_readings houseplants tablosunda yer alan meta verilerle zenginleştirmektir. Bu, ilgili tesis için hem okuma hem de meta verileri içeren yeni bir akış (Kafka konusuyla desteklenen) oluşturur:
Zenginleştirme sorgusu aşağıdakine benzer:
CREATE STREAM houseplant_readings_enriched WITH ( kafka_topic='houseplant-readings-enriched', format='AVRO', partitions=4 ) AS SELECT r.id AS plant_id, r.timestamp AS ts, r.moisture AS moisture, r.temperature AS temperature, h.scientific_name AS scientific_name, h.common_name AS common_name, h.given_name AS given_name, h.temperature_low AS temperature_low, h.temperature_high AS temperature_high, h.moisture_low AS moisture_low, h.moisture_high AS moisture_high FROM houseplant_readings AS r LEFT OUTER JOIN houseplants AS h ON houseplant_readings.id = houseplants.id PARTITION BY r.id EMIT CHANGES;
Ve bu sorgunun çıktısı şöyle olacaktır:


Olay akışında uyarı oluşturma
Bu makalenin başlangıcını düşündüğünüzde, tüm bunların asıl amacının bana bir bitkinin ne zaman sulanması gerekebileceğini söylemek olduğunu hatırlayacaksınız. Elimizde bir nem (ve sıcaklık) okuma akışı var ve bize her bitkinin nem seviyesinin sulamaya ihtiyaç duyduğunu gösterebileceği eşiği söyleyen bir tablomuz var. Peki düşük nem uyarısının ne zaman gönderileceğini nasıl belirleyebilirim? Peki bunları ne sıklıkla göndereceğim?
Bu soruları yanıtlamaya çalışırken sensörlerim ve onların ürettiği veriler hakkında birkaç şey fark ettim. Öncelikle beş saniyelik aralıklarla veri topluyorum. Her düşük nem ölçümü için bir uyarı gönderecek olsaydım, telefonumu uyarılarla doldururdum; bu hiç iyi değil. En fazla saatte bir uyarı almayı tercih ederim. Verilerime bakarken fark ettiğim ikinci şey, sensörlerin mükemmel olmadığıydı; düzenli olarak yanlış düşük veya yanlış yüksek okumalar görüyordum, ancak zaman içindeki genel eğilim bitkinin nem seviyesinin düşeceği yönündeydi.
Bu iki gözlemi birleştirerek, belirli bir 1 saatlik süre içinde, 20 dakikalık düşük nem okuması görürsem bir uyarı göndermenin muhtemelen yeterli olacağına karar verdim. Her 5 saniyede bir okuma, saatte 720 okuma demektir ve… burada biraz matematik yaparsak, bu, bir uyarı göndermeden önce 1 saatlik süre içinde 240 düşük okuma görmem gerektiği anlamına gelir.
Şimdi yapacağımız şey, her 1 saatlik dönemde tesis başına en fazla bir olayı içerecek yeni bir akış oluşturmaktır. Bunu aşağıdaki sorguyu yazarak başardım:
CREATE TABLE houseplant_low_readings WITH ( kafka_topic='houseplant-low-readings', format='AVRO', partitions=4 ) AS SELECT plant_id, given_name, common_name, scientific_name, CONCAT(given_name, ' the ', common_name, ' (', scientific_name, ') is looking pretty dry...') AS message, COUNT(*) AS low_reading_count FROM houseplant_readings_enriched WINDOW TUMBLING (SIZE 1 HOURS, GRACE PERIOD 30 MINUTES) WHERE moisture < moisture_low GROUP BY plant_id, given_name, common_name, scientific_name HAVING COUNT(*) > 240 EMIT FINAL;
İlk olarak pencereli toplamayı fark edeceksiniz. Bu sorgu, çakışmayan 1 saatlik pencereler üzerinde çalışarak, belirli bir pencere içinde tesis kimliği başına verileri toplamamı sağlıyor. Oldukça basit.
Zenginleştirilmiş okuma akışındaki nem okuma değerinin söz konusu tesis için düşük nem eşiğinden düşük olduğu satırları özel olarak filtreliyor ve sayıyorum. Bu sayı en az 240 ise, uyarının temelini oluşturacak bir sonuç yayınlayacağım.
Ancak bu sorgunun sonucunun neden bir tabloda olduğunu merak ediyor olabilirsiniz. Bildiğimiz gibi akışlar bir veri varlığının az çok eksiksiz geçmişini temsil ederken tablolar belirli bir anahtar için en güncel değeri yansıtır. Bu sorgunun aslında gizli bir durum bilgisi olan akış uygulaması olduğunu unutmamak önemlidir. Mesajlar temeldeki zenginleştirilmiş veri akışı üzerinden akarken, eğer söz konusu mesaj filtre gerekliliğini karşılıyorsa, 1 saatlik pencere içinde söz konusu tesis kimliği için düşük okumaların sayısını artırırız ve bunu bir durum dahilinde takip ederiz. Ancak bu sorguda gerçekten önemsediğim şey, toplamanın nihai sonucudur; belirli bir anahtar için düşük okuma sayısının 240'ın üzerinde olup olmadığı. Bir masa istiyorum.
Bir yandan: Bu ifadenin son satırının 'EMIT FINAL' olduğunu fark edeceksiniz. Bu ifade, akış uygulamasından her yeni satır aktığında potansiyel olarak bir sonuç çıktısı almak yerine, bir sonuç yayınlanmadan önce pencerenin kapanmasını bekleyeceğim anlamına gelir.
Bu sorgunun sonucu, belirli bir saatlik pencerede belirli bir tesis kimliği için tam istediğim gibi en fazla bir uyarı mesajı çıktısı vereceğim.
Dallanma
Bu noktada ksqlDB tarafından doldurulan ve bir bitkinin uygun ve tutarlı bir şekilde düşük nem seviyesine sahip olduğu mesajını içeren bir Kafka konusu vardı. Peki bu verileri aslında Kafka'dan nasıl alabilirim? Benim için en uygun şey bu bilgiyi doğrudan telefonumdan almak olacaktır.
Burada tekerleği yeniden icat edecek değildim, bu yüzden Kafka konusundaki mesajları okumak ve telefona uyarı göndermek için Telegram botu kullanmayı açıklayan bu blog yazısından yararlandım. Blogda belirtilen süreci takip ederek bir Telegram botu oluşturdum ve telefonumda o botla bir konuşma başlattım, bu konuşmanın benzersiz kimliğini ve botumun API anahtarını not ettim. Bu bilgiyle, botumdan telefonuma mesaj göndermek için Telegram sohbet API'sini kullanabilirim.
Bu iyi hoş da, uyarılarımı Kafka'dan Telegram botuma nasıl aktarırım? Kafka konusundaki uyarıları tüketecek ve her mesajı Telegram sohbet API'si aracılığıyla manuel olarak gönderecek özel bir tüketici yazarak mesaj göndermeyi başlatabilirim. Ama bu fazladan iş gibi görünüyor. Bunun yerine, aynı şeyi yapmak için tam olarak yönetilen HTTP Sink Connector'ı kullanmaya karar verdim, ancak kendime ait herhangi bir ek kod yazmadan.
Birkaç dakika içinde Telegram Botum harekete geçmeye hazırdı ve botla aramda özel bir sohbet açıldı. Sohbet kimliğini kullanarak artık doğrudan telefonuma mesaj göndermek için Confluent Cloud'daki tam olarak yönetilen HTTP Sink Bağlayıcısını kullanabiliyordum.
Tam konfigürasyon şuna benziyordu:
{ "name": "HttpSinkConnector_Houseplants_Telegram_Bot", "config": { "topics": "houseplant-low-readings", "input.data.format": "AVRO", "connector.class": "HttpSink", "name": "HttpSinkConnector_Houseplants_Telegram_Bot", "kafka.auth.mode": "KAFKA_API_KEY", "http.api.url": "https://api.telegram.org/**********/sendMessage", "request.method": "POST", "headers": "Content-Type: application/json", "request.body.format": "string", "batch.max.size": "1", "batch.prefix": "{\"chat_id\":\"********\",", "batch.suffix": "}", "regex.patterns": ".*MESSAGE=(.*),LOW_READING_COUNT=(.*)}.*", "regex.replacements": "\"text\":\"$1\"", "regex.separator": "~", "tasks.max": "1" } }


Konektörü piyasaya sürdükten birkaç gün sonra bitkimin sulanması gerektiğini bildiren çok faydalı bir mesaj aldım. Başarı!


Yeni bir sayfa açmak
Bu projenin ilk aşamasını tamamladığımdan bu yana yaklaşık bir yıl geçti. Bu süre zarfında izlediğim tüm bitkilerin mutlu ve sağlıklı olduğunu bildirmekten mutluluk duyuyorum! Artık bunları kontrol etmek için fazladan zaman harcamam gerekmiyor ve yalnızca akış veri hattım tarafından oluşturulan uyarılara güvenebiliyorum. Ne kadar serin?


Bu projeyi oluşturma süreci ilginizi çektiyse, kendi akış veri hattınızı oluşturmaya başlamanızı öneririm. İster gerçek zamanlı boru hatlarını kendi hayatınıza dahil etmek ve inşa etmek için kendinize meydan okumak isteyen deneyimli bir Kafka kullanıcısı olun, ister Kafka'da tamamen yeni olan biri olun, size bu tür projelerin tam size göre olduğunu söylemek için buradayım.









