Makipag-usap sa sinuman sa AI, analytics, o data science, at sasabihin nila sa iyo na ang synthetic data ay ang hinaharap. Ngunit tanungin sila kung ano ang ibig nilang sabihin sa "synthetic data," at makakakuha ka ng kakaibang mga sagot. Iyon ay dahil ang sintetikong data ay hindi lamang isang bagay—ito ay isang malawak na kategorya na may maraming mga kaso ng paggamit at mga kahulugan. At ang kalabuan na iyon ay ginagawang nakalilito ang mga pag-uusap.
Kaya, itigil na natin ang ingay. Sa kaibuturan nito, gumagana ang sintetikong data sa dalawang pangunahing dimensyon. Ang una ay isang spectrum mula sa pagpuno ng nawawalang data sa isang umiiral na dataset hanggang sa pagbuo ng mga ganap na bagong dataset. Tinutukoy ng pangalawa ang mga interbensyon sa antas ng raw data kumpara sa mga interbensyon sa antas ng mga insight o resulta.
Isipin ang mga sukat na ito bilang mga palakol sa isang tsart. Lumilikha ito ng apat na kuwadrante, bawat isa ay kumakatawan sa ibang uri ng sintetikong data: data imputation, paggawa ng user, pagmomodelo ng mga insight, at mga ginawang resulta . Naghahain ang bawat isa ng natatanging function, at kung nagtatrabaho ka sa data sa anumang kapasidad, kailangan mong malaman ang pagkakaiba.

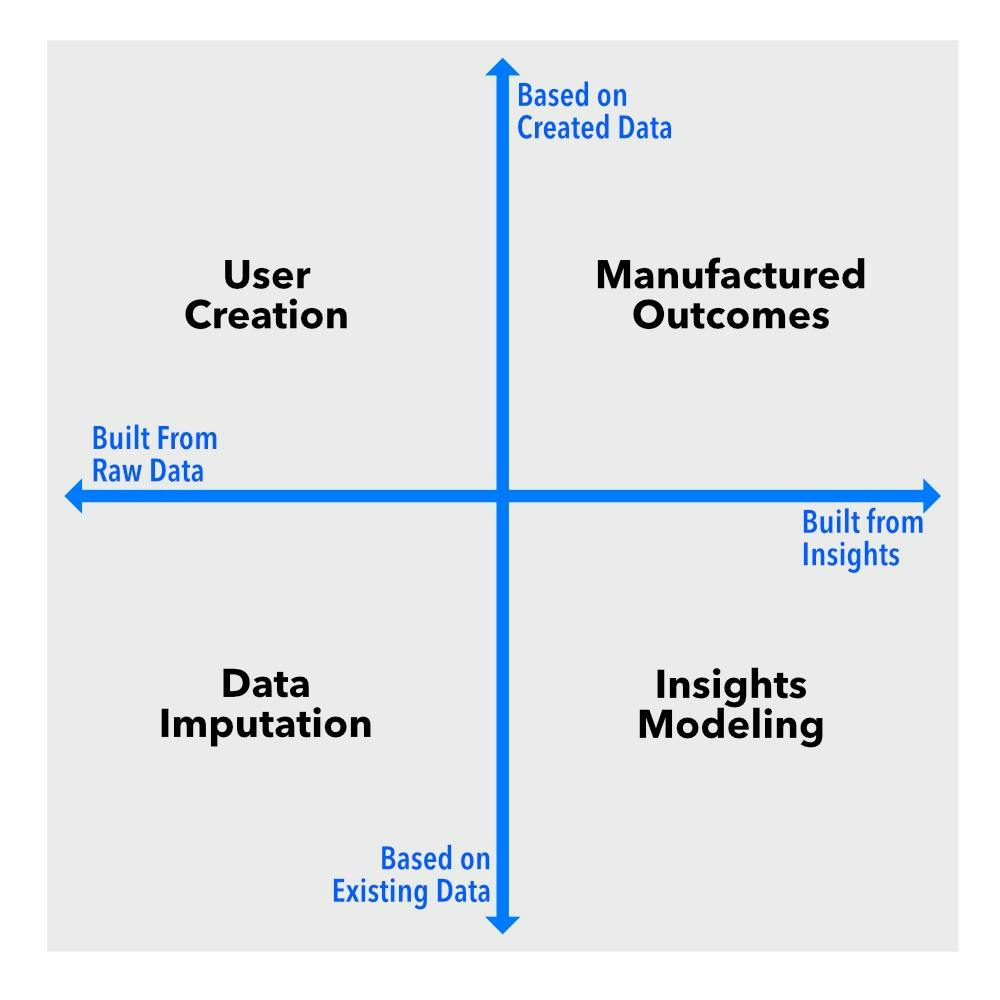
Data Imputation: Pagpuno sa mga Blangko
Bagama't maaaring magtaltalan ang ilan na ang data imputation ay hindi tunay na sintetikong data, ang mga modernong imputation technique ay umunlad na lampas sa simpleng mean o median substitution. Sa ngayon, ginagamit ng advanced imputation ang machine learning at generative AI models, na ginagawang mas sopistikado at may kaugnayan sa konteksto ang mga nabuong value kaysa dati.
Ang data imputation ay nakaupo sa intersection ng nawawalang data at raw data intervention . Nangangahulugan ito na nakikipagtulungan kami sa mga umiiral nang dataset na may mga gaps, at ang aming layunin ay bumuo ng mga makatotohanang halaga upang makumpleto ang mga ito. Hindi tulad ng iba pang uri ng synthetic na data, ang imputation ay hindi tungkol sa paglikha ng ganap na bagong impormasyon—ito ay tungkol sa paggawa ng hindi kumpletong data na mas magagamit.
Halimbawa: Ang isang market research firm na nagsasagawa ng mga pag-aaral sa pagiging epektibo ng media ay maaaring may mga gaps sa data ng pagtugon ng audience nito dahil sa mga nawawalang tugon sa survey. Sa halip na itapon ang mga hindi kumpletong dataset, ang mga diskarte sa imputation—gaya ng statistical modeling o machine learning—ay maaaring makabuo ng mga makatotohanang pagtatantya, na tinitiyak na ang mga analyst ay makakakuha pa rin ng makabuluhang mga insight mula sa data.
Paglikha ng User: Mga Pekeng Tao, Mga Tunay na Insight
Ang paglikha ng user ay nasa pagitan ng bagong data generation at raw data intervention . Sa halip na baguhin ang kasalukuyang data, ang diskarteng ito ay gumagawa ng ganap na bagong mga profile at pag-uugali ng user. Ito ay partikular na kapaki-pakinabang kapag ang totoong data ng user ay hindi available, sensitibo, o kailangang gawing artipisyal.
Ang paggawa ng user ay isang game-changer para sa pagsubok ng mga produkto, pagpapabuti ng seguridad, at pagsasanay sa mga modelo ng AI.
Halimbawa: Maaaring lumikha ang isang serbisyo ng streaming ng mga synthetic na profile ng user upang subukan ang engine ng rekomendasyon nito nang hindi inilalantad ang totoong data ng customer. Ganoon din ang ginagawa ng mga kumpanya ng cybersecurity upang gayahin ang mga senaryo ng pag-atake at sanayin ang mga sistema ng pagtuklas ng panloloko.
Pagmomodelo ng Mga Insight: Mga Pattern na Walang Mga Panganib sa Privacy
Gumagana ang pagmomodelo ng mga insight sa intersection ng kasalukuyang data at interbensyon sa antas ng mga insight . Sa halip na manipulahin ang mga hilaw na punto ng data, lumilikha ito ng mga dataset na nagpapanatili ng mga istatistikal na katangian ng real-world na data nang hindi inilalantad ang mga aktwal na talaan. Ginagawa nitong perpekto para sa mga application na sensitibo sa privacy.
Nagbibigay-daan din ang pagmomodelo ng mga insight sa mga mananaliksik na sukatin ang mga insight mula sa mga dati nang dataset, lalo na kapag hindi praktikal ang pangangalap ng malakihang data. Ito ay karaniwan sa pananaliksik sa marketing, kung saan ang pangongolekta ng data ay maaaring maging mahirap at magastos. Gayunpaman, ang diskarteng ito ay nangangailangan ng matatag na pundasyon ng data ng pagsasanay sa totoong mundo.
Halimbawa: Maaaring gumamit ng pagmomodelo ng mga insight ang isang market research firm na nagsasagawa ng copy testing upang sukatin ang normative database nito. Sa halip na umasa lamang sa mga nakolektang tugon sa survey, maaaring makabuo ang kumpanya ng mga modelo ng synthetic na insight na nag-extrapolate ng mga pattern mula sa kasalukuyang normative data. Nagbibigay-daan ito sa mga brand na subukan ang creative performance laban sa mas malawak, mas predictive na dataset nang hindi patuloy na kumukuha ng mga bagong tugon sa survey.
Mga Ginawang Resulta: Kapag Wala Pa Ang Data
Ang mga ginawang resulta ay nasa pinakadulo ng parehong bagong pagbuo ng data at interbensyon sa antas ng mga insight . Kasama sa diskarteng ito ang pagbuo ng mga ganap na bagong dataset mula sa simula upang gayahin ang mga kapaligiran o mga senaryo na wala pa ngunit mahalaga para sa pagsasanay, pagmomodelo, at simulation ng AI.
Minsan, ang data na kailangan mo ay wala lang—o masyadong mahal o mapanganib na kolektahin sa totoong mundo. Doon papasok ang Mga Manufactured Outcomes. Ang prosesong ito ay bumubuo ng mga ganap na bagong dataset, kadalasan upang sanayin ang mga AI system sa mga kapaligiran na mahirap kopyahin.
Halimbawa: Ang mga kumpanya ng self-driving na kotse ay bumubuo ng mga sintetikong sitwasyon sa kalsada—tulad ng isang pedestrian na biglang nag-jaywalk—upang sanayin ang kanilang AI sa mga bihira ngunit kritikal na sitwasyon na maaaring hindi madalas na lumabas sa real-world na footage sa pagmamaneho.
Mga Panganib at Pagsasaalang-alang ng Synthetic Data
Bagama't ang synthetic na data ay nagbibigay ng mahuhusay na solusyon, ito ay walang panganib. Ang bawat uri ng synthetic na data ay may sariling mga hamon na maaaring makaapekto sa kalidad ng data, pagiging maaasahan, at etikal na paggamit. Narito ang ilang pangunahing alalahanin na dapat tandaan:
- Pagpapalaganap ng Bias: Kung ang pinagbabatayan na data na ginamit para sa imputation, pagmomodelo ng mga insight, o Mga Ginawa na Kinalabasan ay naglalaman ng bias, ang mga bias na iyon ay maaaring palakasin o palakihin pa.
- Kakulangan ng Real-World Representativeness: Ang paggawa ng user at paggawa ng data ay maaaring makabuo ng data na mukhang makatotohanan ngunit nabigong makuha ang mga nuances ng aktwal na gawi ng user o mga kundisyon sa merkado.
- Overfitting at False Confidence: Ang pagmomodelo ng mga insight, kapag hindi wastong inilapat, ay maaaring lumikha ng data na masyadong malapit sa set ng pagsasanay, na humahantong sa mga mapanlinlang na konklusyon.
- Mga Alalahanin sa Regulatoryo at Etikal: Nalalapat pa rin ang mga batas sa privacy tulad ng GDPR at CCPA sa synthetic na data kung maaari itong i-reverse-engineered upang matukoy ang mga tunay na indibidwal.
Mga Pangunahing Tanong na Itatanong Kapag Sinusuri ang Synthetic Data
Upang matiyak na ang synthetic na data ay nakakatugon sa mga pamantayan ng kalidad, isaalang-alang ang mga tanong na ito:
- Ano ang pinagmulan ng orihinal na data? Ang pag-unawa sa pundasyon ng sintetikong data ay nakakatulong sa pagtatasa ng mga potensyal na bias at limitasyon.
- Paano nabuo ang sintetikong data? Ang iba't ibang paraan—machine learning, statistical models, o rule-based system—ay nakakaapekto sa pagiging maaasahan ng synthetic na data.
- Pinapanatili ba ng synthetic na data ang istatistikal na integridad ng real-world na data? Tiyakin na ang nabuong data ay kumikilos nang katulad ng aktwal na data nang hindi lamang ito dinu-duplicate.
- Maaari bang ma-audit o ma-validate ang sintetikong data? Ang maaasahang sintetikong data ay dapat na mayroong mga mekanismo sa pagpapatunay.
- Sumusunod ba ito sa mga alituntunin sa regulasyon at etikal? Dahil lang sa synthetic ang data, hindi ito nangangahulugang exempt ito sa mga regulasyon sa privacy.
- Mayroon bang proseso para i-update ang mga pinagbabatayan na modelo ng data? Ang synthetic na data ay kasing ganda lang ng real-world na data kung saan ito nakabatay. Ang pagtiyak ng isang proseso para sa patuloy na pag-update ng foundational dataset ay pumipigil sa mga modelo na maging lipas na sa panahon at hindi umaayon sa mga kasalukuyang trend.
Binabalot Ito
Ang synthetic na data ay isang malawak na termino, at kung nagtatrabaho ka sa AI, analytics, o anumang field na hinihimok ng data, kailangan mong maging malinaw sa kung anong uri ang iyong pakikitungo. Pinupuunan mo ba ang nawawalang data (imputation), gumagawa ng mga pansubok na user (gumawa ng user), bumubuo ng mga hindi nakikilalang pattern (pagmomodelo ng mga insight), o gumagawa ng mga bagong-bagong dataset mula sa simula (mga ginawang resulta)?
Ang bawat isa sa mga ito ay gumaganap ng iba't ibang papel sa kung paano namin ginagamit at pinoprotektahan ang data, at ang pag-unawa sa mga ito ay susi sa paggawa ng matalinong mga desisyon sa mabilis na umuusbong na mundo ng AI at data science. Kaya sa susunod na may mag-isip tungkol sa terminong "synthetic data," tanungin sila: Aling uri?