























Praat met enigiemand in KI, analise of datawetenskap, en hulle sal vir jou sê sintetiese data is die toekoms. Maar vra hulle wat hulle bedoel met "sintetiese data," en jy sal baie verskillende antwoorde kry. Dit is omdat sintetiese data nie net een ding is nie - dit is 'n breë kategorie met veelvuldige gebruiksgevalle en definisies. En daardie dubbelsinnigheid maak gesprekke verwarrend.
So, kom ons sny deur die geraas. In sy kern werk sintetiese data volgens twee sleuteldimensies. Die eerste is 'n spektrum wat wissel van die invul van ontbrekende data in 'n bestaande datastel tot die generering van heeltemal nuwe datastelle. Die tweede onderskei tussen intervensies op die roudatavlak versus intervensies op die insigte- of uitkomstevlak.
Stel jou hierdie afmetings voor as asse op 'n grafiek. Dit skep vier kwadrante, wat elkeen 'n ander tipe sintetiese data verteenwoordig: data-imputasie, gebruikerskepping, insigtemodellering en vervaardigde uitkomste . Elkeen dien 'n eiesoortige funksie, en as jy in enige hoedanigheid met data werk, moet jy die verskil ken.

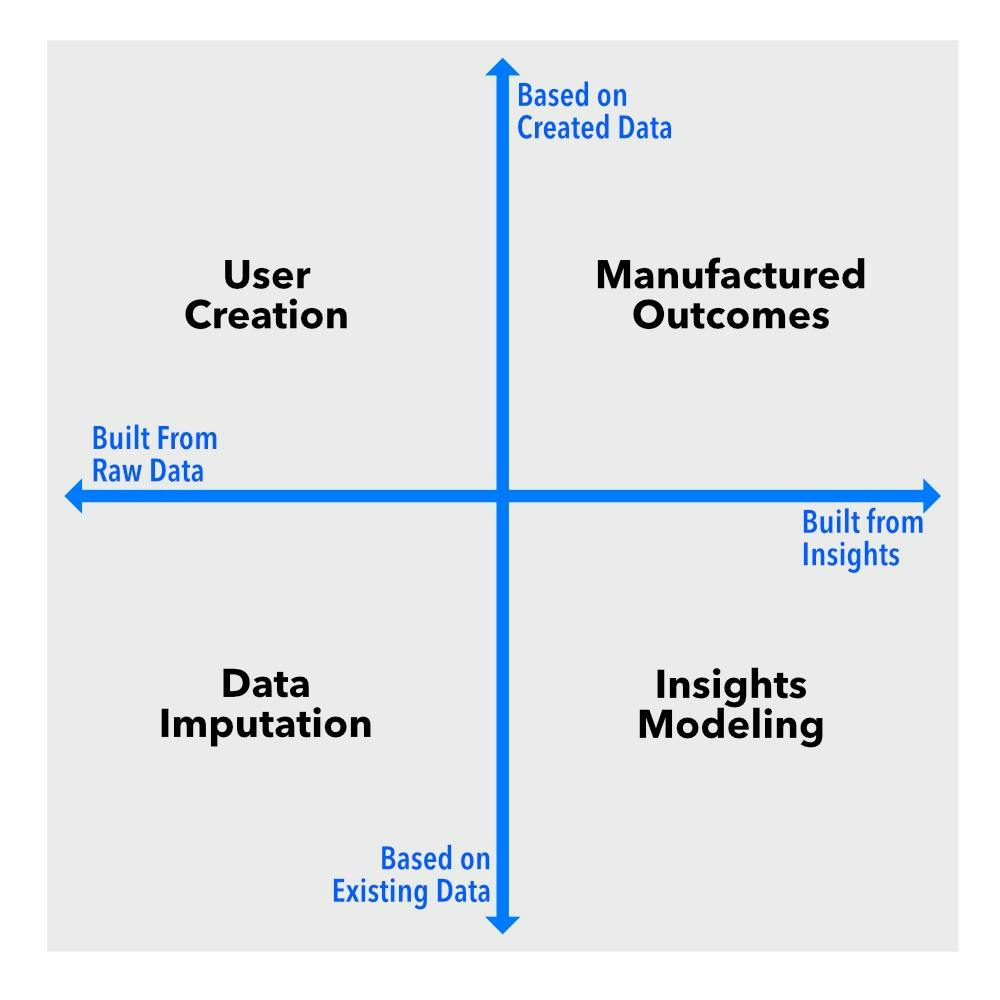
Data-imputasie: Vul die spasies in
Terwyl sommige kan argumenteer dat data-toerekening nie werklik sintetiese data is nie, het moderne toerekeningstegnieke verder ontwikkel as eenvoudige gemiddelde of mediaanvervanging. Vandag maak gevorderde toerekening gebruik van masjienleer en generatiewe KI-modelle, wat die gegenereerde waardes meer gesofistikeerd en kontekstueel relevant maak as ooit tevore.
Data-imputasie sit op die kruising van ontbrekende data en rou data-intervensie . Dit beteken ons werk met bestaande datastelle wat leemtes het, en ons doel is om geloofwaardige waardes te genereer om dit te voltooi. Anders as ander soorte sintetiese data, gaan toerekening nie oor die skep van heeltemal nuwe inligting nie – dit gaan daaroor om onvolledige data meer bruikbaar te maak.
Voorbeeld: 'n Marknavorsingsfirma wat mediadoeltreffendheidstudies doen, kan leemtes in sy gehoorreaksiedata hê as gevolg van ontbrekende opname-antwoorde. In plaas daarvan om onvolledige datastelle weg te gooi, kan toerekeningstegnieke – soos statistiese modellering of masjienleer – realistiese skattings genereer, wat verseker dat ontleders steeds betekenisvolle insigte uit die data kan put.
Gebruikerskepping: Valse mense, regte insigte
Gebruikerskepping lê tussen nuwe datagenerering en rou data-intervensie . In plaas daarvan om bestaande data te wysig, vervaardig hierdie benadering heeltemal nuwe gebruikersprofiele en -gedrag. Dit is veral nuttig wanneer werklike gebruikerdata nie beskikbaar is nie, sensitief is of kunsmatig geskaal moet word.
Gebruikerskepping is 'n speletjie-wisselaar om produkte te toets, sekuriteit te verbeter en KI-modelle op te lei.
Voorbeeld: 'n Stroomdiens kan sintetiese gebruikersprofiele skep om sy aanbevelingsenjin te toets sonder om werklike klantdata bloot te stel. Kuberveiligheidsfirmas doen dieselfde om aanvalscenario's te simuleer en bedrogopsporingstelsels op te lei.
Insigte-modellering: patrone sonder die privaatheidsrisiko's
Insights-modellering werk by die kruising van bestaande data en intervensie op die insigte-vlak . In plaas daarvan om rou datapunte te manipuleer, skep dit datastelle wat die statistiese eienskappe van werklike data bewaar sonder om werklike rekords bloot te lê. Dit maak dit ideaal vir privaatheidsensitiewe toepassings.
Insights-modellering stel navorsers ook in staat om insigte van voorafbestaande datastelle te skaal, veral wanneer die insameling van grootskaalse data onprakties is. Dit is algemeen in bemarkingsnavorsing, waar data-insameling omslagtig en duur kan wees. Hierdie benadering vereis egter 'n stewige grondslag van werklike opleidingsdata.
Voorbeeld: 'n Marknavorsingsfirma wat kopietoetsing uitvoer, kan insigmodellering gebruik om sy normatiewe databasis te skaal. In plaas daarvan om uitsluitlik op ingesamelde opname-antwoorde staat te maak, kan die firma sintetiese insigte-modelle genereer wat patrone uit bestaande normatiewe data ekstrapoleer. Dit stel handelsmerke in staat om kreatiewe prestasie teen 'n breër, meer voorspellende datastel te toets sonder om voortdurend nuwe opname-antwoorde in te samel.
Vervaardigde uitkomste: Wanneer die data nog nie bestaan nie
Vervaardigde uitkomste sit aan die uiterste punt van beide nuwe datagenerering en insig-vlak intervensie . Hierdie benadering behels die generering van heeltemal nuwe datastelle van nuuts af om omgewings of scenario's te simuleer wat nog nie bestaan nie, maar noodsaaklik is vir KI-opleiding, modellering en simulasies.
Soms bestaan die data wat jy nodig het eenvoudig nie - of is dit te duur of gevaarlik om in die regte wêreld in te samel. Dit is waar vervaardigde uitkomste inkom. Hierdie proses genereer heeltemal nuwe datastelle, dikwels om KI-stelsels op te lei in omgewings wat moeilik is om te repliseer.
Voorbeeld: Selfbesturende motormaatskappye genereer sintetiese padscenario's—soos 'n voetganger wat skielik jaywalking—om hul KI op te lei op seldsame maar kritieke situasies wat dalk nie dikwels in werklike rymateriaal verskyn nie.
Risiko's en oorwegings van sintetiese data
Alhoewel sintetiese data kragtige oplossings bied, is dit nie sonder risiko's nie. Elke tipe sintetiese data het sy eie uitdagings wat datakwaliteit, betroubaarheid en etiese gebruik kan beïnvloed. Hier is 'n paar belangrike bekommernisse om in gedagte te hou:
- Vooroordeelvoortplanting: As die onderliggende data wat gebruik word vir toerekening, insigmodellering of vervaardigde uitkomste vooroordeel bevat, kan daardie vooroordele versterk of selfs versterk word.
- Gebrek aan werklike verteenwoordigendheid: Gebruikerskepping en datavervaardiging kan data genereer wat realisties lyk, maar nie daarin slaag om die nuanses van werklike gebruikersgedrag of marktoestande vas te lê nie.
- Oorpas en vals vertroue: Insights-modellering, wanneer dit onbehoorlik toegepas word, kan data skep wat te nou in lyn is met die opleidingstel, wat lei tot misleidende gevolgtrekkings.
- Regulerende en etiese bekommernisse: Privaatheidswette soos GDPR en CCPA is steeds van toepassing op sintetiese data as dit omgekeerd ontwerp kan word om werklike individue te identifiseer.
Sleutelvrae om te vra wanneer sintetiese data evalueer word
Oorweeg hierdie vrae om te verseker dat sintetiese data aan kwaliteitstandaarde voldoen:
- Wat is die bron van die oorspronklike data? Om die grondslag van sintetiese data te verstaan, help om potensiële vooroordele en beperkings te assesseer.
- Hoe is die sintetiese data gegenereer? Verskillende metodes - masjienleer, statistiese modelle of reëlgebaseerde stelsels - beïnvloed die betroubaarheid van sintetiese data.
- Handhaaf die sintetiese data die statistiese integriteit van werklike data? Maak seker dat die gegenereerde data soortgelyk optree as werklike data sonder om dit bloot te dupliseer.
- Kan die sintetiese data geoudit of bekragtig word? Betroubare sintetiese data moet valideringsmeganismes in plek hê.
- Voldoen dit aan regulatoriese en etiese riglyne? Net omdat data sinteties is, beteken dit nie dat dit vrygestel is van privaatheidsregulasies nie.
- Is daar 'n proses om die onderliggende datamodelle op te dateer? Sintetiese data is net so goed soos die werklike data waarop dit gebaseer is. Om 'n proses te verseker vir die voortdurende opdatering van die grondslagdatastel voorkom dat modelle verouderd raak en nie in lyn is met huidige neigings nie.
Om dit toe te draai
Sintetiese data is 'n breë term, en as jy in KI, analise of enige data-gedrewe veld werk, moet jy duidelik wees oor watter soort jy te doen het. Vul jy ontbrekende data in (toerekening), skep toetsgebruikers (gebruikerskepping), genereer anonieme patrone (insigtemodellering), of bou splinternuwe datastelle van nuuts af (vervaardigde uitkomste)?
Elkeen van hierdie speel 'n ander rol in hoe ons data gebruik en beskerm, en om dit te verstaan is die sleutel tot die neem van ingeligte besluite in die vinnig ontwikkelende wêreld van KI en datawetenskap. So volgende keer as iemand die term "sintetiese data" rondgooi, vra hulle: Watter soort?








